VLIC: Vision-Language Models As Perceptual Judges for Human-Aligned Image Compression
Abstract: Evaluations of image compression performance which include human preferences have generally found that naive distortion functions such as MSE are insufficiently aligned to human perception. In order to align compression models to human perception, prior work has employed differentiable perceptual losses consisting of neural networks calibrated on large-scale datasets of human psycho-visual judgments. We show that, surprisingly, state-of-the-art vision-LLMs (VLMs) can replicate binary human two-alternative forced choice (2AFC) judgments zero-shot when asked to reason about the differences between pairs of images. Motivated to exploit the powerful zero-shot visual reasoning capabilities of VLMs, we propose Vision-LLMs for Image Compression (VLIC), a diffusion-based image compression system designed to be post-trained with binary VLM judgments. VLIC leverages existing techniques for diffusion model post-training with preferences, rather than distilling the VLM judgments into a separate perceptual loss network. We show that calibrating this system on VLM judgments produces competitive or state-of-the-art performance on human-aligned visual compression depending on the dataset, according to perceptual metrics and large-scale user studies. We additionally conduct an extensive analysis of the VLM-based reward design and training procedure and share important insights. More visuals are available at https://kylesargent.github.io/vlic





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making image files smaller without making them look bad to people. The authors build a new compression system (called VLIC) that asks a smart AI that understands pictures and language (a Vision-LLM, or VLM) to judge which compressed image looks closer to the original. Then, the compressor learns from those judgments to produce results that people prefer.
What questions did the researchers ask?
- Can a Vision-LLM (like Gemini 2.5-Flash) judge which of two images looks more like the original in the same way humans do, even without extra training?
- If yes, can we use those judgments to train an image compressor to keep the parts people care about most (like faces and text) while still making files small?
- Will this approach work better than using standard “similarity scores” that don’t perfectly match human taste?
How did they do it?
Here’s the approach in everyday terms, with simple explanations of technical ideas:
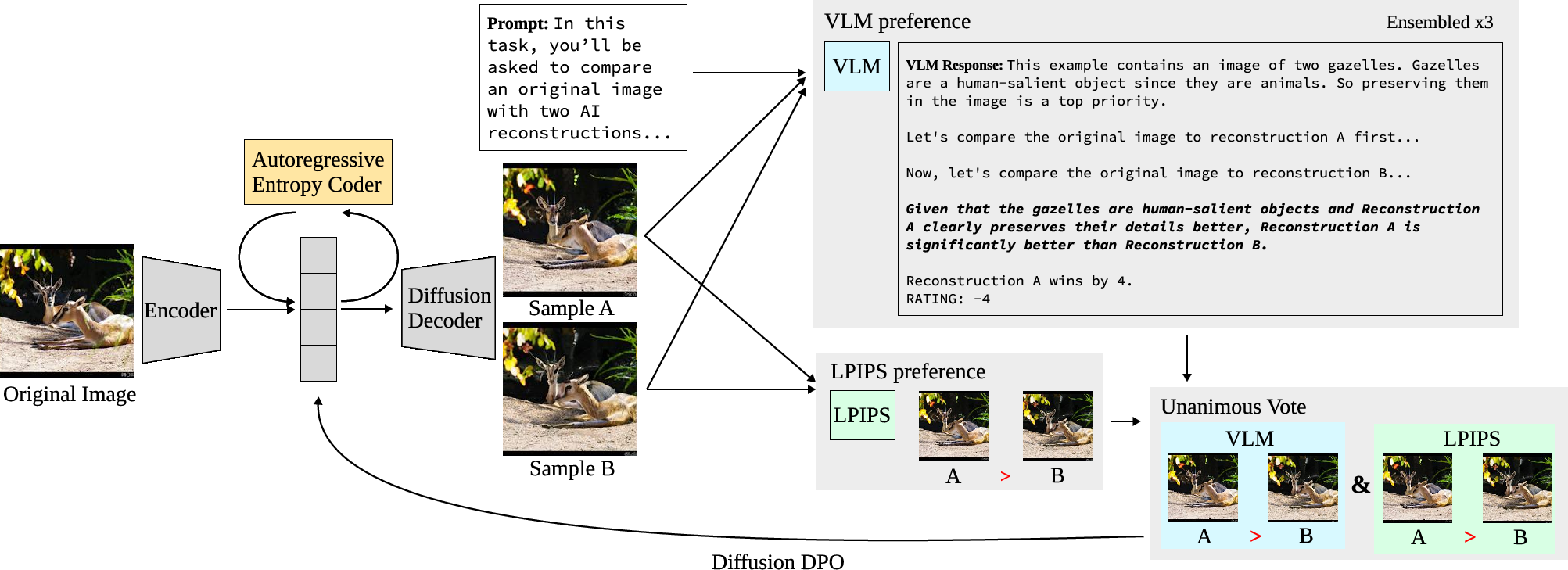
Step 1: Build a smart compressor
- Think of compression like packing your clothes into a suitcase: you want to fit everything but keep the important items in good shape.
- The compressor has two parts:
- An encoder that turns the image into a short “code” (like a list of tokens).
- A decoder that uses that code to recreate the image.
- Their decoder is a “diffusion model,” which you can imagine as a careful painter that starts with a fuzzy picture and gradually adds detail until it looks like the original. This type of model is good at creating realistic textures and fine details.
- They use “quantization” (FSQ) to turn image features into discrete tokens (like a simplified alphabet for images), and later “entropy coding” (like zipping a file) to make the final data even smaller.
Step 2: Ask a VLM to be the judge
- The system makes two slightly different reconstructions of the same image.
- A Vision-LLM (Gemini 2.5-Flash) is shown: 1) the original image, 2) reconstruction A, 3) reconstruction B.
- The VLM explains what it sees and then gives a score for which reconstruction is closer to the original, like a referee in a game.
- Because AIs can sometimes be inconsistent, the authors use three smart tricks to make the judgment more reliable:
- Reverse the order (A vs. B, then B vs. A) and combine the results.
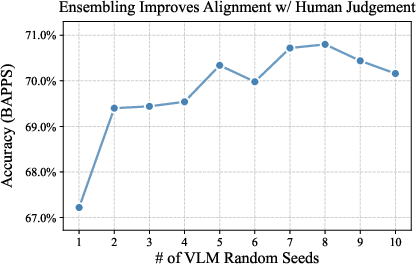
- Ask the VLM multiple times with different random seeds (like getting multiple referee opinions) and vote.
- Only train on pairs where the VLM and a standard metric (LPIPS, an automatic “looks similar” score) agree, and skip confusing cases.
Step 3: Train by preferences (Diffusion DPO)
- The compressor learns using “preferences” instead of a single score. This method is called Direct Preference Optimization (DPO) for diffusion models.
- In simple terms: when the VLM says “A looks better than B,” the model is nudged to make future reconstructions more like A and less like B.
- This helps the model align with what humans actually prefer, not just what a math formula says.
Step 4: Make files extra small
- After tokens are produced, they train a small language-like model that predicts the next token well. This lets them compress the token sequence efficiently using arithmetic coding (similar to how zip files work).
- Result: smaller files, still pleasing to the eye.
What did they find?
Here are the main results and why they matter:
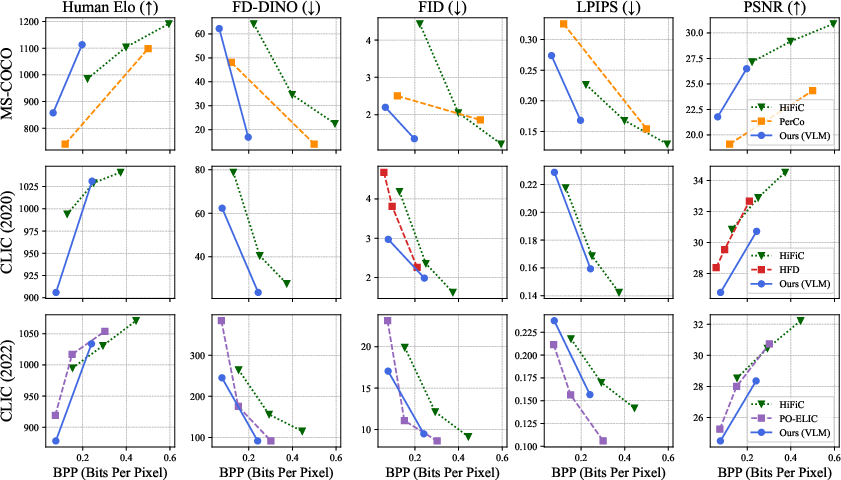
- A VLM can “zero-shot” (without extra training) replicate human judgments in standard tests where people choose which image looks closer to the original (called 2AFC). This is surprising and powerful: it means we can use VLMs as stand-in human judges.
- Training the compressor with VLM preferences improves visual quality according to human-aligned metrics and large user studies. In many cases, their system (VLIC) matched or beat strong baselines.
- VLIC did especially well on images with human-relevant details (like faces and text), which people notice most.
- Combining VLM judgments with the LPIPS metric was better than using either alone. The ensemble made training more stable and results more reliable.
- There’s a trade-off: scores like PSNR (a math-based pixel difference measure) can go down even when human preference goes up. This is expected, because what humans like isn’t always the same as what these old metrics reward.
- More VLM “votes” (self-ensembling) made judgments more consistent, especially when the two reconstructions were very similar.
Why it matters
- Better compression saves storage space and internet bandwidth, making websites faster and cheaper to run—without making images look worse to people.
- Using VLMs as “perception judges” can reduce the need to collect huge amounts of human rating data and train specialized metrics. As VLMs get better over time, compressors trained this way can get better too.
- Keeping human-important details (like readable text and natural-looking faces) can improve user experience across social media, streaming, and photo apps.
- Limitations to keep in mind:
- VLM judgments can be noisy when images are very similar, so the ensemble tricks are important.
- The method depends on having access to a good VLM, and querying it costs time and compute.
- Performance can vary across datasets (for example, VLIC didn’t always beat every competitor on every set).
In short, this paper shows a practical way to train image compressors to match what people actually care about, by letting a general-purpose vision-language AI serve as the judge.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper that future work can directly address.
- Reliance on a single proprietary VLM (Gemini 2.5-Flash): reproducibility and generalization to other VLMs (e.g., GPT-4o, Claude, LLaVA, IDEFICS) are untested; quantify performance variance across models, versions, and access modalities (cloud vs. on-device).
- Prompt sensitivity is not studied: how do different prompt templates, reasoning styles (chain-of-thought vs. concise), and instruction framing affect reward consistency, bias, and alignment to human judgment?
- Reward binarization discards signal: the VLM rating in [−5, 5] is reduced to a sign; investigate probabilistic preference modeling (e.g., Bradley–Terry, Thurstone) or calibrated score-to-probability mappings to exploit richer supervision.
- Unreported acceptance rate for the “unanimous VLM+LPIPS” filter: measure how many pairs are discarded, how acceptance varies with BPP, and how this affects sample efficiency and convergence.
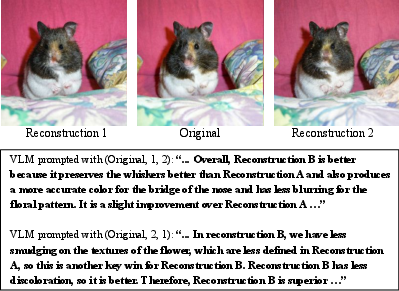
- Lack of systematic noise quantification: provide statistics on VLM self-consistency (order invariance), inter-seed agreement, and error modes, especially on near-identical reconstructions; probe failure distributions by content type (text, faces, fine textures).
- Over-optimization (“reward hacking”) risk is not evaluated: assess whether post-trained models exploit VLM-specific biases (e.g., over-sharpening, saturation) by validating on held-out human studies where the VLM is not consulted and on anti-reward tests designed to reveal biases.
- Latency and cost of VLM queries are not reported: measure wall-clock overhead and compute budgets for online preference sampling; compare online vs. offline preference datasets under equal budgets and propose budget-aware training protocols.
- Distilling the VLM reward into a small, local, reproducible judge is not explored: evaluate trainable surrogate reward models (e.g., CLIP-like or IQA networks) that retain VLM alignment but reduce training/inference costs and privacy risks.
- Privacy/security implications of sending original images to external VLM services are not addressed: propose privacy-preserving or on-device alternatives and analyze data governance constraints for real-world deployment.
- Only two operating points (0.07 and 0.21 bpp) are tested: provide full rate–distortion curves, variable-rate training, and adaptive bit allocation strategies; analyze stability of DPO across rates.
- End-to-end rate accounting is unclear: clarify and report BPP after the autoregressive entropy coder (not just pre-entropy FSQ), and compare against standard codecs (JPEG, WebP, AVIF, JPEG XL) on both rate and perceptual quality.
- Decoding speed and resource use of the diffusion decoder are unreported: benchmark reconstruction latency, energy, and memory vs. GAN-based baselines (e.g., HiFiC) and classical codecs; study speed–quality trade-offs (e.g., fewer denoising steps).
- Tiled inference artifacts are not quantified: measure seam/tiling artifacts at high resolutions, and evaluate blending or multi-patch consistency strategies; include perceptual and task-level metrics on full-resolution images (not only crops).
- Stochastic decoding raises determinism concerns: quantify variability across seeds for the same latent code (e.g., text legibility variance); propose deterministic decoding modes or consensus strategies for user-facing compression.
- No content-specific perceptual evaluation: include targeted metrics for faces (face verification accuracy), text (OCR word accuracy, legibility scores), and fine patterns (aliasing/moire measures) to validate claims about human-relevant artifacts.
- Domain robustness is untested: evaluate on non-natural domains (medical, satellite, line drawings, UI screenshots, comics) and assess generalization and failure modes under distribution shift.
- Video compression is not studied: extend VLM-based preference alignment to temporal consistency, motion artifacts, and rate control across frames; investigate video-specific preference schemes and metrics.
- DPO hyperparameters and training choices lack ablation: report sensitivity to KL weight β, SNR weighting ω(λ_t), number of preference pairs per buffer, and frequency of buffer refresh; compare DDPO vs. alternative preference RL methods (e.g., DRDPO, GRPO with n>2).
- The co-training with flow matching is not analyzed: quantify how λ_Flow affects stability, convergence, and final perceptual quality; explore schedules for mixing DDPO and base losses.
- Architectural choices (FSQ vs. LFQ) are changed without quantitative comparison: ablate the impact of tokenizer choice, codebook size, and token sequence length on rate and perceptual fidelity; test hyperprior or channel-wise entropy models vs. autoregressive transformers.
- The autoregressive entropy coder’s contribution is unmeasured: report perplexity, compression gains over FSQ alone, and the trade-offs between transformer complexity and decoding speed; compare against established learned entropy models.
- Human studies lack demographic and context detail: report rater demographics, expertise, device/monitor setups, and crop-selection protocols; analyze inter-rater agreement by content type and provide confidence intervals for Elo scores.
- Crop-based evaluation may miss global artifacts: complement crop metrics with full-image assessments and saliency-aware cropping to capture large-scale structure errors and layout inconsistencies.
- Metric selection could bias conclusions: go beyond LPIPS and FD-DINO to include DISTS, DREAMSIM, MUSIQ, and task-based metrics; provide correlation analyses between metrics and human Elo per dataset.
- Using LPIPS both in training and as part of reward/evaluation risks circularity: favor metrics uncorrelated with LPIPS for validation, or design train–test metric separation to reduce evaluation bias.
- Failure analysis is anecdotal: provide a taxonomy of VLM judgment failures and quantitative rates, including order sensitivity, hallucinated differences, text misreadings, and small artifact prioritization; test mitigation strategies beyond self-ensembling (e.g., contrastive visual grounding, masked comparison).
- Online preference sampling benefits are asserted but not quantified: directly compare online vs. offline preference pipelines under matched compute and sample budgets; analyze sample-efficiency gains and stability.
- Generalization across image resolutions is underexplored: train at higher base resolutions and compare against tiling-based inference; assess whether higher-resolution training reduces artifacts and improves text/face fidelity.
- Reproducibility is limited by extreme compute (256 TPUv4) and proprietary components: publish code, prompts, buffers, and seeds; propose lower-compute recipes (fewer steps/seeds) with quantified degradation to enable broader adoption.
- Potential social biases in VLM judgment are not assessed: audit whether VLM preferences systematically favor certain styles, demographics, or cultural artifacts (e.g., skin tones, scripts); incorporate fairness checks in human studies and reward design.
- Stability over VLM version drift is unknown: analyze how changing VLM versions affects reward calibration and post-trained model behavior; propose version-robust preference pipelines or re-calibration procedures.
- Theoretical grounding of applying DPO to diffusion autoencoders is limited: formalize the objective’s properties (e.g., bias, variance under noisy preferences), convergence guarantees, and conditions under which preference alignment preserves rate–distortion optimality.
Practical Applications
Below is an overview of practical applications that follow from the paper’s core findings: VLMs can act as reliable, zero-shot perceptual judges of visual similarity, and their judgments can be used to post-train diffusion autoencoder-based image compression systems (VLIC) via Diffusion DPO to better match human preferences.
Immediate Applications
These applications can be piloted or deployed now with engineering integration and standard productization effort.
- Bold use case: Human-aligned web and mobile image compression at low bitrates
- Sectors: Software/Internet, Media/CDN, Publishing, News
- What: Replace or complement existing web image pipelines (e.g., JPEG/AVIF/WebP/WebP2) with a VLIC-based codec for thumbnails, hero images, and galleries, optimizing for human-perceived quality (faces, text, textures) at low BPP.
- Potential tools/products/workflows: VLIC Codec SDK (server-side encoder + client/server decoder), CDN plugin or edge function to re-encode assets on-the-fly, A/B testing harness using FD-DINO/Elo, tiling-based high-res inference pipeline.
- Assumptions/dependencies: Acceptable decode latency (diffusion decoding is heavier than traditional codecs), tiled inference quality is adequate for target content, server or device GPU/accelerator availability, fallback to standard codecs where needed, legal/IP considerations for learned codecs.
- Bold use case: Messaging and social media “data-saver” image mode
- Sectors: Consumer apps, Telecom
- What: Integrate VLIC into chat and social apps for low-bandwidth sharing that preserves readability of text and faces while reducing data.
- Potential tools/products/workflows: App-integrated decoder (mobile GPU/NPU acceleration), adaptive bitrate controller, user-facing “perceptual quality” toggle.
- Assumptions/dependencies: On-device inference performance and battery impact are acceptable; content policy allows generative decoders; privacy constraints if server-side encoding is used.
- Bold use case: E-commerce image pipelines that preserve product details and text
- Sectors: Retail/E-commerce
- What: Re-encode product images (labels, SKU text, fine textures) with VLIC to maintain shopper-relevant details at lower bitrates, improving page speed and conversion.
- Potential tools/products/workflows: Batch re-encoder integrated with CMS/PIM, automated quality gate using VLM+LPIPS unanimity checks, monitoring dashboard (FD-DINO, Elo).
- Assumptions/dependencies: Strong guardrails to avoid hallucinating or altering product-critical details; legal requirements for fidelity in product representation.
- Bold use case: Map tiles, scanned documents, and slide images for education and knowledge platforms
- Sectors: Education, Productivity/Knowledge, GIS
- What: Use VLIC to compress map tiles and document images while preserving text legibility and visually important regions.
- Potential tools/products/workflows: Tile server integration, OCR-aware QA using VLM judge for legibility checks, progressive loading with perceptual prioritization.
- Assumptions/dependencies: Generative decoders must not introduce text errors that could mislead users or degrade OCR; QA thresholds enforced via VLM+LPIPS.
- Bold use case: Perceptual QA and model selection without human studies
- Sectors: R&D (industry/academia), Codec vendors, Imaging teams
- What: Use the paper’s VLM reward design (self-ensembling, order-reversal checks, LPIPS unanimity) as a zero-shot evaluator to rank candidate codecs or post-training variants, reducing reliance on costly human 2AFC studies.
- Potential tools/products/workflows: “Perceptual Judge Service” with cached VLM responses, prompt pack and evaluation scripts, Elo aggregation pipeline.
- Assumptions/dependencies: Access to a capable VLM; prompt stability; cost and latency of VLM queries; privacy safeguards for image data.
- Bold use case: Turnkey training recipe for human-aligned learned codecs
- Sectors: Academia, AI/ML research labs, Codec startups
- What: Adopt the VLIC + Diffusion DPO post-training recipe to align existing diffusion autoencoders to human preferences on custom domains (e.g., artwork, UI screenshots).
- Potential tools/products/workflows: Training pipeline (JAX/TPU or PyTorch/GPU), asynchronous VLM-in-the-loop preference collection, entropy coder over FSQ tokens, tiling inference utilities.
- Assumptions/dependencies: Compute availability (the paper used substantial TPU resources), dataset coverage for target domain, VLM licensing and cost, careful reward design to reduce noise.
- Bold use case: Sustainability initiatives via perceptual-first compression
- Sectors: Policy (sustainability), Media/CDN, Public sector websites
- What: Reduce bandwidth and energy usage while keeping human-perceived quality high; pilot procurement guidelines that consider perceptual metrics (Elo/FD-DINO) in addition to PSNR/SSIM.
- Potential tools/products/workflows: Reporting dashboard linking bitrate reduction to energy/carbon estimates, policy-aligned QA protocol with human-correlated metrics.
- Assumptions/dependencies: Stakeholder acceptance of perceptual over pixel fidelity for web imagery; clear measurement protocols; stakeholder education on trade-offs.
Long-Term Applications
These opportunities likely require further research, scaling, standardization, or engineering for reliability, cost, and speed.
- Bold use case: Human-aligned video compression with VLM-in-the-loop rewards
- Sectors: Streaming/OTT, Video conferencing, Robotics/teleoperation, Surveillance
- What: Extend VLM-judged preference alignment to video codecs (temporal consistency, motion artifacts, faces/text over time).
- Potential tools/products/workflows: Video diffusion decoders, temporal preference models, batched VLM judgment with self-ensembling across frames, agentic training loops (DDPO/RL variants).
- Assumptions/dependencies: Efficient temporal VLM rewards, significantly faster inference, reliability under motion/scene cuts, privacy/compliance for video data.
- Bold use case: Region-of-interest and semantic bit-allocation
- Sectors: E-commerce, Education, GIS, UX/UI delivery
- What: Use VLMs to detect human-salient content (faces, text, diagrams) and allocate more bits locally while compressing background textures more aggressively.
- Potential tools/products/workflows: Semantic guidance maps for decoders, joint ROI detection + compression pipelines, controllable decoding APIs.
- Assumptions/dependencies: Accurate, low-latency semantic detection; guardrails to avoid over-smoothing non-ROI regions; consistent results across content diversity.
- Bold use case: Privacy-preserving or on-device perceptual judges
- Sectors: Consumer devices, Enterprise, Regulated industries
- What: Distill VLM-based reward into smaller local models or learned perceptual metrics to avoid sending images to external APIs; enable on-device post-training/evaluation.
- Potential tools/products/workflows: Distillation to compact judges, federated/privacy-preserving training, hardware-accelerated judging on NPUs.
- Assumptions/dependencies: Sufficient fidelity of distilled judges; hardware support; policy/compliance requirements.
- Bold use case: Standardization of learned perceptual codecs and evaluation
- Sectors: Standards bodies (ISO/IEC, ITU-T), Browser vendors, CDN ecosystem
- What: Develop bitstream specs, decoder compliance tests, and evaluation protocols that include human-correlated metrics (Elo/FD-DINO) and VLM-in-the-loop assessment guidance.
- Potential tools/products/workflows: Reference decoders, conformance tests, open evaluation suites with VLM-guarded prompts and self-ensembling.
- Assumptions/dependencies: Broad ecosystem buy-in; long cycles for standardization; reproducible VLM behavior across model versions.
- Bold use case: Safety-critical and regulated imaging after rigorous validation
- Sectors: Healthcare (telemedicine previews/non-diagnostic), AEC, Legal archiving
- What: Use perceptual compression for previews, triage, or non-diagnostic sharing where human interpretability matters but exact pixels are not required; strictly avoid hallucinations that could mislead.
- Potential tools/products/workflows: Dual-path storage (lossless for archive + perceptual previews), domain-specific reward models, strict QA gates and audit logs.
- Assumptions/dependencies: Clinical and legal validation; clear labeling of perceptually compressed images; robust failure-mode analyses.
- Bold use case: Content-aware CDNs that re-encode assets per device/context
- Sectors: Media/CDN, ISPs, Mobile OEMs
- What: Agentic systems that automatically choose encoding parameters based on device capabilities, network conditions, and content semantics, targeting human-aligned quality.
- Potential tools/products/workflows: Policy controllers, device profiles, real-time quality probes, continuous QoE optimization loops.
- Assumptions/dependencies: Real-time inference efficiency; robust telemetry; interoperability with existing caches/CDNs.
- Bold use case: Cross-modal and mixed-content compression
- Sectors: Productivity (slides, mixed media), Education, Enterprise collaboration
- What: Jointly compress text+image content where VLMs can understand semantic importance (charts, annotations, screenshots) and preserve it.
- Potential tools/products/workflows: Multimodal tokenizers, text-preservation constraints, hybrid raster/vector packaging.
- Assumptions/dependencies: Strong multimodal reward functions; standardized containers; accurate preservation of textual semantics.
- Bold use case: General “VLM-as-a-judge” alignment for image enhancement tasks
- Sectors: Imaging (super-resolution, denoising, inpainting), Creative tools, AR/VR
- What: Apply the paper’s DDPO + VLM preference alignment recipe to other generative imaging tasks to maximize human-perceived fidelity.
- Potential tools/products/workflows: Task-specific prompts and reward templates, self-ensembling and unanimity checks, deployment dashboards with human-correlated metrics.
- Assumptions/dependencies: Task-tailored prompting reliability; avoidance of reward hacking; compute budgets for iterative post-training.
- Bold use case: Energy-aware networking and policy at scale
- Sectors: Policy, Telecom, Sustainability
- What: Institute network-level policies that prefer perceptually aligned compression for non-critical imagery to reduce energy use without impairing user experience.
- Potential tools/products/workflows: Policy playbooks, measurement frameworks linking bitrate to energy/carbon, public-sector website optimization programs.
- Assumptions/dependencies: Stakeholder consensus on acceptable fidelity, transparent measurement and reporting, governance for content categories.
Notes on feasibility across applications
- Compute and latency: Diffusion decoding is heavier than traditional codecs; practical deployment may require GPU/TPU/NPUs and optimized runtimes.
- Training scale and cost: The reference training used large-scale accelerators; smaller teams may rely on fine-tuning or model distillation.
- VLM access and privacy: Cloud VLM calls raise cost and privacy concerns; self-ensembling multiplies cost. Distilled or local judges mitigate this.
- Reliability guardrails: The paper’s mitigation strategies (order reversal, multi-seed self-ensembling, LPIPS unanimity) are critical to reduce noisy or hallucinated judgments.
- Domain and resolution shifts: Models trained at 256×256 with tiled inference must be validated on target resolutions/content to avoid artifacts.
- Legal/regulatory: For domains requiring exact fidelity (news archiving, legal records, diagnostics), generative perceptual codecs may need strict constraints or be limited to previews.
Glossary
- 2AFC: Two-Alternative Forced Choice; a binary human judgment setup where raters choose which of two options is closer to a reference. "binary human two-alternative forced choice (2AFC) judgments"
- Adam: A stochastic optimization algorithm commonly used to train neural networks. "with Adam~\cite{kingma2014adam} learning rate ."
- Arithmetic coding: A lossless entropy coding technique that compresses data based on symbol probability. "we use it to compress the latent code via arithmetic coding, similar to prior work \cite{deletang2024language}."
- Autoregressive transformer: A transformer model that predicts the next token conditioned on previous ones, used here as an entropy coder. "The entropy coder takes the form of a simple autoregressive transformer over the 1-dimensional latent sequence."
- BAPPS: A dataset for perceptual image similarity judgments used to benchmark models against human assessments. "namely on BAPPS \cite{kettunen2019elpips}"
- bfloat16 precision: A reduced-precision floating-point format that speeds up training while maintaining numerical stability. "with bfloat16 precision."
- Bits per pixel (BPP): A measure of compression rate indicating how many bits are used to represent each pixel. "at various bits per pixel (bpp)."
- Classifier-free guidance: A diffusion sampling technique that improves conditional generation by mixing conditional and unconditional predictions. "implement classifier-free guidance by dropping out the discrete latent code of the time"
- DALL-E crop protocol: A standardized cropping method for preparing images for evaluation. "using the DALL-E crop protocol following common practice"
- Denoising Diffusion Policy Optimization: A reinforcement learning method for aligning diffusion models with non-differentiable rewards. "Denoising Diffusion Policy Optimization \cite{black2023training}"
- Direct Preference Optimization (DPO): A training objective that aligns generative models to pairwise preferences without learning a value function. "Direct Preference Optimization (DPO) \cite{Rafailov2023dpo}"
- Diffusion autoencoder: An autoencoder architecture whose decoder is a diffusion model, enabling stochastic reconstructions from discrete latents. "VLIC is a diffusion autoencoder"
- Diffusion DPO: The adaptation of DPO to diffusion models to optimize them using preference data. "via Diffusion DPO~\cite{wallace2023diffusion}"
- DISTS: A perceptual image quality metric that unifies structure and texture similarity. "DISTS~\cite{ding2020dists}"
- DRAFT: A method for fine-tuning diffusion models directly on differentiable reward signals. "Differentiable techniques include DRAFT~\cite{clark2023draft}"
- DreamSim: A learned perceptual metric focused on semantic, high-level visual similarity. "DreamSim~\cite{fu2023dreamsim}"
- E-LPIPS: An ensemble variant of LPIPS aimed at robust perceptual similarity estimation. "E-LPIPS~\cite{kettunen2019elpips}"
- Elo: A rating system aggregating pairwise human comparisons to produce a global quality ranking. "Finally, we compute human Elo via large-scale user studies."
- Entropy coder: A learned or engineered module that compresses discrete tokens using probabilistic modeling. "We further compress the discrete tokens from FSQ via a secondary entropy coder, which is trained separately."
- Factorized entropy model: An entropy model that assumes independence between channels or symbols for efficient coding. "particularly if a factorized entropy model is used \cite{minnen2020channel, he2022poelic}."
- FD-DINO: A distributional image quality metric based on DINO features, often more predictive of human judgments than FID. "FD-DINO \cite{stein2023exposing}"
- FID: Fréchet Inception Distance; a distributional metric measuring similarity between sets of images. "FID \cite{heusel2017gans}"
- Finite Scalar Quantization (FSQ): A discretization scheme that maps continuous values to a finite set of scalar levels. "we use finite scalar quantization (FSQ) \cite{Mentzer2023FSQ}"
- Flow matching: A training objective that learns a velocity field to match the probability flow between data and noise in diffusion/flow models. "We additionally co-train with the original flow matching training loss"
- FlowMo: A diffusion autoencoder baseline focused on mode-seeking tokenization, used as the base architecture. "based on FlowMo \cite{sargent2025flowmodemodeseekingdiffusion}"
- GRPO: A preference-optimization technique akin to contrastive RL where winning samples are contrasted against losing ones. "which is similar to GRPO~\cite{shao2024deepseekmath} with ."
- HFD: A diffusion-based image compression approach using score-based generative models. "HFD~\cite{hoogeboom2023hfd}"
- HiFiC: A GAN-based high-fidelity learned image compression method. "HiFiC \cite{mentzer2020high}"
- LPIPS: Learned Perceptual Image Patch Similarity; a neural metric correlating with human visual similarity judgments. "LPIPS \cite{zhang2018unreasonable}"
- Lookup-Free Quantization (LFQ): A quantization method that avoids codebook lookups common in VQ-VAE-style models. "lookup-free quantization \cite{Yu2023LFQ}"
- MS-COCO: A large-scale dataset of common objects used for benchmarking image compression. "on MS-COCO~\cite{lin2014microsoft}"
- PerCo: A generative compression method targeting perceptual fidelity at ultra-low bitrates. "We compare our approach with HiFiC and PerCo on MS-COCO~\cite{lin2014microsoft}."
- PO-ELIC: A perception-oriented efficient learned image coding method. "PO-ELIC \cite{he2022poelic}"
- Preference buffer: A rolling dataset of sampled reconstructions and their pairwise preferences used for online training. "sampling a preference buffer of approximately $2,560$ examples every 250 steps"
- PSNR: Peak Signal-to-Noise Ratio; a pixel-wise distortion metric that often poorly correlates with perceived visual quality. "Historically, visual quality has been assessed via classical metrics such as PSNR and SSIM~\cite{wang2004ssim}."
- Rectified flow: A framework that learns straightened data generation paths via velocity fields, improving diffusion training. "rectified flow framework \cite{liu2022flow, Lipman2022Flow}"
- Self-ensembling: Aggregating multiple VLM judgments (seeds/orders) to reduce noise and improve reliability. "Most helpful is self-ensembling, \ie, computing the reward as the majority vote of multiple captioning requests to the VLM"
- SNR-dependent weighting factor: A training weight that scales contributions based on signal-to-noise ratio at timestep t. "and an SNR-dependent weighting factor."
- SSIM: Structural Similarity Index; a classical image quality metric focusing on luminance, contrast, and structure. "PSNR and SSIM~\cite{wang2004ssim}"
- TPUv4: A generation of Google’s Tensor Processing Units used for large-scale model training. "Training was completed on 256 TPUv4."
- Tiled inference: Inference strategy that processes images in tiles to handle variable or high resolutions. "we use a tiled inference procedure similar to prior work \cite{hoogeboom2023hfd}"
- VADER: A method for aligning diffusion models using reward gradients for video generation. "Differentiable techniques include DRAFT~\cite{clark2023draft} and VADER~\cite{prabhudesai2024video}"
- Vision-LLM (VLM): A multimodal model that reasons over images and text, here used as a perceptual judge. "Vision-LLMs (VLMs) are effective zero-shot perceptual judges of visual similarity"
- v-parameterization: A diffusion model output parameterization that predicts velocity v rather than noise ε. "which is by default in -parameterization~\cite{salimans2022progressive} in our case"
- Zero-shot: Performing a task without task-specific training, leveraging general reasoning capabilities. "zero-shot when asked to reason about the differences between pairs of images."
Collections
Sign up for free to add this paper to one or more collections.