- The paper shows that aggressive quantization, especially below 2 bits, reduces membership inference vulnerability by up to an order of magnitude compared to full precision.
- It systematically evaluates leading PTQ methods (AdaRound, BRECQ, and OBC) on image datasets using state-of-the-art LiRA metrics to measure privacy leakage.
- The study introduces decoupled quantization—quantizing only the last layer at higher precision—to recover accuracy while still mitigating privacy risks.
Evaluating the Privacy-Utility Trade-off of Post-Training Quantization via Membership Inference
Overview and Motivation
This paper provides a comprehensive, systematic investigation of the privacy implications of post-training quantization (PTQ) in deep neural networks, specifically analyzing how quantization at varying bit-widths influences the vulnerability of models to membership inference attacks (MIAs). The study targets leading PTQ algorithms—AdaRound, BRECQ, and OBC—evaluated across a spectrum of precisions (4-bit, 2-bit, and 1.58-bit) on canonical image classification datasets (CIFAR-10, CIFAR-100, and TinyImageNet). Privacy leakage is assessed with a rigorous attack framework, including both online and offline variants of the state-of-the-art Likelihood Ratio Attack (LiRA).
The central claim is that aggressive quantization, notably at sub-2-bit levels, offers up to an order-of-magnitude reduction in MIA vulnerability compared to full-precision networks, albeit at the expense of model accuracy. The work further investigates precision decoupling in PTQ to recover some of the lost utility while controlling privacy–utility trade-offs.
Post-Training Quantization and Membership Inference
Post-training quantization is critical for resource-constrained inference, enabling direct quantization of pretrained models by reducing parameter precision, independent of retraining. The paper investigates three representative PTQ methods:
- AdaRound: Learns adaptive rounding decisions via layer-wise optimization to minimize output reconstruction error.
- BRECQ: Incorporates block-wise reconstruction and uses AdaRound as a quantization primitive to mitigate inter-layer quantization artifacts.
- OBC: Extends pruning-based methods to quantization by greedily minimizing quantization error through sequential parameter updates.
Membership inference attacks, and specifically LiRA, are leveraged to quantify privacy risks. LiRA employs shadow models to approximate the distribution of losses for member/non-member samples, providing a robust TPR@FPR metric for privacy evaluation.
Empirical Evaluation
Privacy and Utility Degradation with Bit-Width Reduction
Results consistently indicate that decreasing bit-width in PTQ yields substantial privacy gains, as quantized models resist LiRA attacks more effectively. This phenomenon is especially pronounced below 2 bits-per-weight. At 1.58 bits—a ternary quantization scheme inspired by recent advances in LLM quantization—[email protected]% FPR is suppressed by two orders of magnitude vis-à-vis full-precision baselines, although the concomitant utility loss is marked, especially on complex datasets such as TinyImageNet.
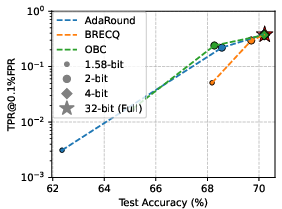
Figure 1: Privacy leakage of quantized models trained on CIFAR-100 under LiRA online attack; lower precision improves privacy protection, evaluated with [email protected]% FPR.
The privacy–utility trade-off is quantifiably linked to precision:
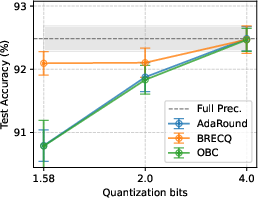
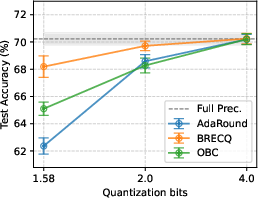
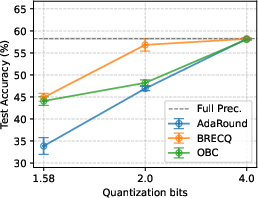
Figure 2: Test accuracy of models quantized with different PTQs at various bit-widths; accuracy significantly drops at 1.58-bit quantization.
For 4-bit quantization, most of the original accuracy is retained with negligible privacy benefit; only at 2-bit and lower do privacy improvements manifest sharply.
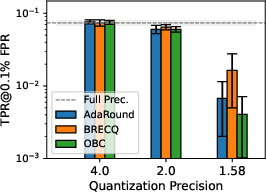
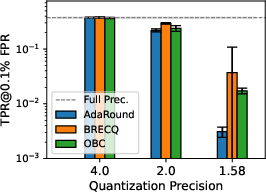
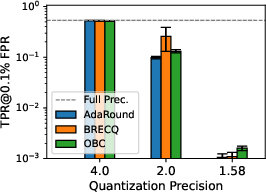
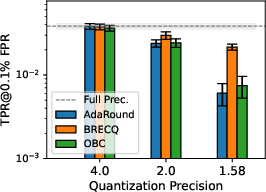
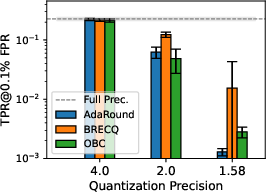
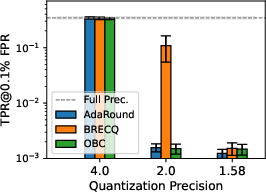
Figure 3: Privacy leakage of models quantized with different PTQs at various precision levels under LiRA online/offline attack; 1.58-bit consistently mitigates MIA, especially in more complex datasets.
Decoupled Quantization for Privacy-Utility Control
The paper proposes “decoupled quantization,” wherein only the last layer is quantized at higher precision (e.g., 8 bits) to recoup accuracy lost at 1.58-bit quantization, enabling fine-grained control over the privacy–utility axis. On TinyImageNet, this strategy recovers much of the original performance while maintaining substantial MIA resistance.
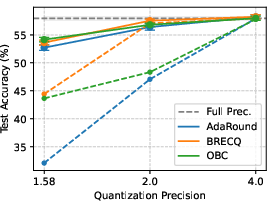
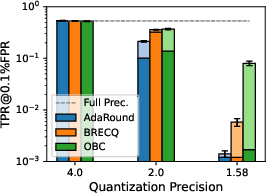
Figure 4: Decoupling the last layer to higher precision allows recovery of utility lost at 1.58 bits, at the cost of some privacy leakage increase.
Model-Agnostic Trends
The utility–privacy trend persists for architectures of varying depth and family, as demonstrated by applying OBC-based quantization to both ResNet18 and DenseNet121. Lower quantization tightens the privacy guarantee regardless of architectural complexity, but sensitivity to quantization can differ.
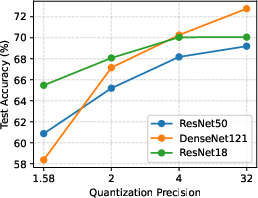
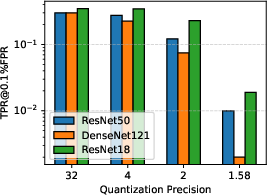
Figure 5: Utility and privacy trade-off is consistent across architectures quantized with OBC.
Variance and Robustness in Low-Bit PTQ
The analysis of 1.58-bit quantized models reveals that privacy leakage, as measured by [email protected]% FPR, can exhibit substantial variance, particularly for BRECQ. Some instantiations yield both higher accuracy and increased privacy leakage, underscoring the importance of repeated experimental runs for accurate assessment.
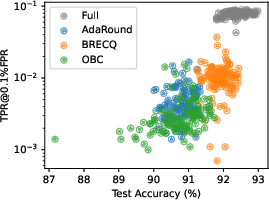
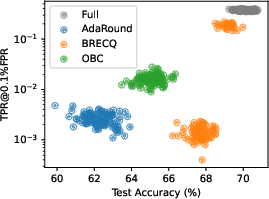
Figure 6: Distribution of utility and privacy for 1.58-bit quantized models; BRECQ achieves the best average but with considerable variance.
Implications and Future Directions
Practical Deployment
The findings are immediately relevant for edge AI deployment and regulated domains where privacy is paramount. System designers can employ extreme low-bit PTQ as a tunable knob, subject to utility constraints, without introducing the computational overhead and hyperparameter burden inherent to privacy-specific training approaches.
Theoretical and Methodological Extensions
This empirical demonstration motivates theoretical analysis of the mechanisms driving privacy enhancement through aggressive quantization—potentially via an information-theoretic or generalization perspective. Furthermore, combining quantization with established privacy defenses (e.g., DP-SGD or adversarial regularization) remains an open avenue for extending privacy protection.
The demonstrated generality across datasets and architectures suggests applicability beyond vision, potentially impacting privacy-aware deployment of quantized models in NLP or federated learning. Integrating quantization for activations and exploring joint training for quantization-aware privacy protection could further improve state-of-the-art techniques.
Conclusion
This work rigorously establishes that post-training quantization at sufficiently low bit-widths can offer substantial privacy leakage mitigation, as demonstrated by reduced success rates of state-of-the-art membership inference attacks, at the cost of reduced accuracy. Decoupled quantization strategies offer a promising vector to manage this trade-off for practical deployment scenarios. The results provide actionable insights for balancing efficiency, utility, and privacy in post-training quantized models, and lay the foundation for future research in quantization-driven privacy control.
Reference: "Bits for Privacy: Evaluating Post-Training Quantization via Membership Inference" (2512.15335).

