A Complete Guide to Spherical Equivariant Graph Transformers
Abstract: Spherical equivariant graph neural networks (EGNNs) provide a principled framework for learning on three-dimensional molecular and biomolecular systems, where predictions must respect the rotational symmetries inherent in physics. These models extend traditional message-passing GNNs and Transformers by representing node and edge features as spherical tensors that transform under irreducible representations of the rotation group SO(3), ensuring that predictions change in physically meaningful ways under rotations of the input. This guide develops a complete, intuitive foundation for spherical equivariant modeling - from group representations and spherical harmonics, to tensor products, Clebsch-Gordan decomposition, and the construction of SO(3)-equivariant kernels. Building on this foundation, we construct the Tensor Field Network and SE(3)-Transformer architectures and explain how they perform equivariant message-passing and attention on geometric graphs. Through clear mathematical derivations and annotated code excerpts, this guide serves as a self-contained introduction for researchers and learners seeking to understand or implement spherical EGNNs for applications in chemistry, molecular property prediction, protein structure modeling, and generative modeling.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is a friendly, step‑by‑step guide to a special kind of AI model that understands 3D shapes—especially molecules and proteins—even when you rotate or move them. These models are called spherical equivariant graph neural networks (EGNNs) and SE(3)/SO(3) Transformers. The goal is to teach you how to build neural networks that make predictions that stay physically correct when you spin a molecule around, because in the real world, a molecule’s properties don’t change just because you turned it.
What questions is it trying to answer?
In simple terms, the guide answers:
- How can we build AI models that “see” a 3D object the same way no matter how it’s rotated or moved?
- How do we represent 3D information so the model transforms it correctly under rotation?
- How do we design “filters” and “attention” that respect the laws of physics (like rotational symmetry)?
- How can we put all of this together into practical architectures—like Tensor Field Networks and SE(3)-Transformers—with working code for real datasets (like molecules in QM9)?
How do they approach the problem?
The paper builds up the whole toolkit, from basic ideas to full models, with math intuition and annotated PyTorch/DGL code. Here are the main ideas, with everyday analogies:
Invariance vs. equivariance (spot-the-pattern vs. follow-the-rotation)
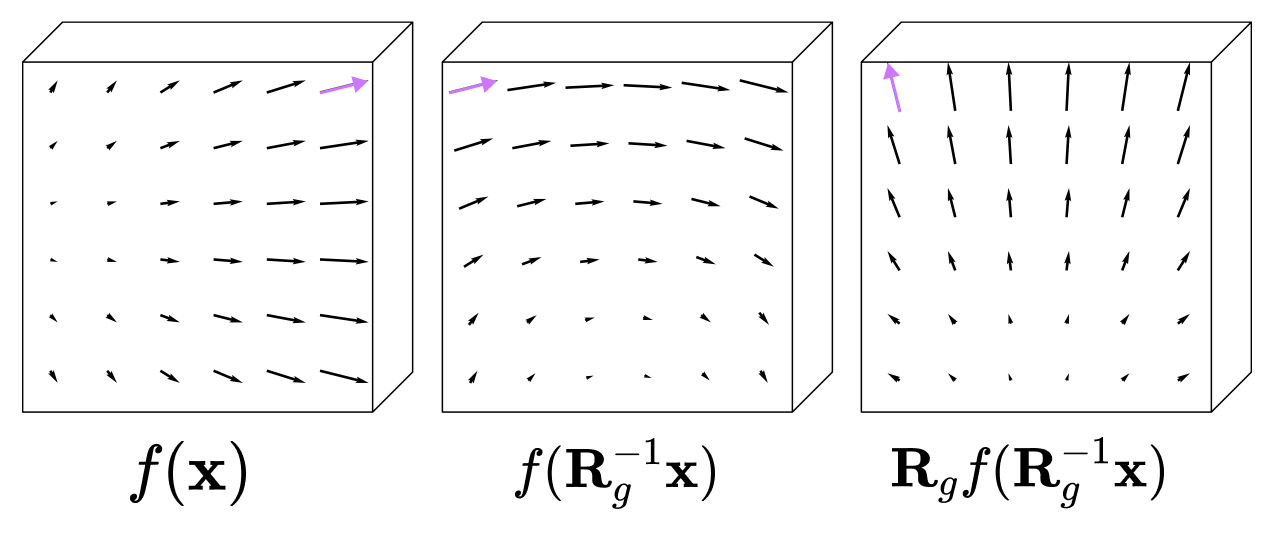
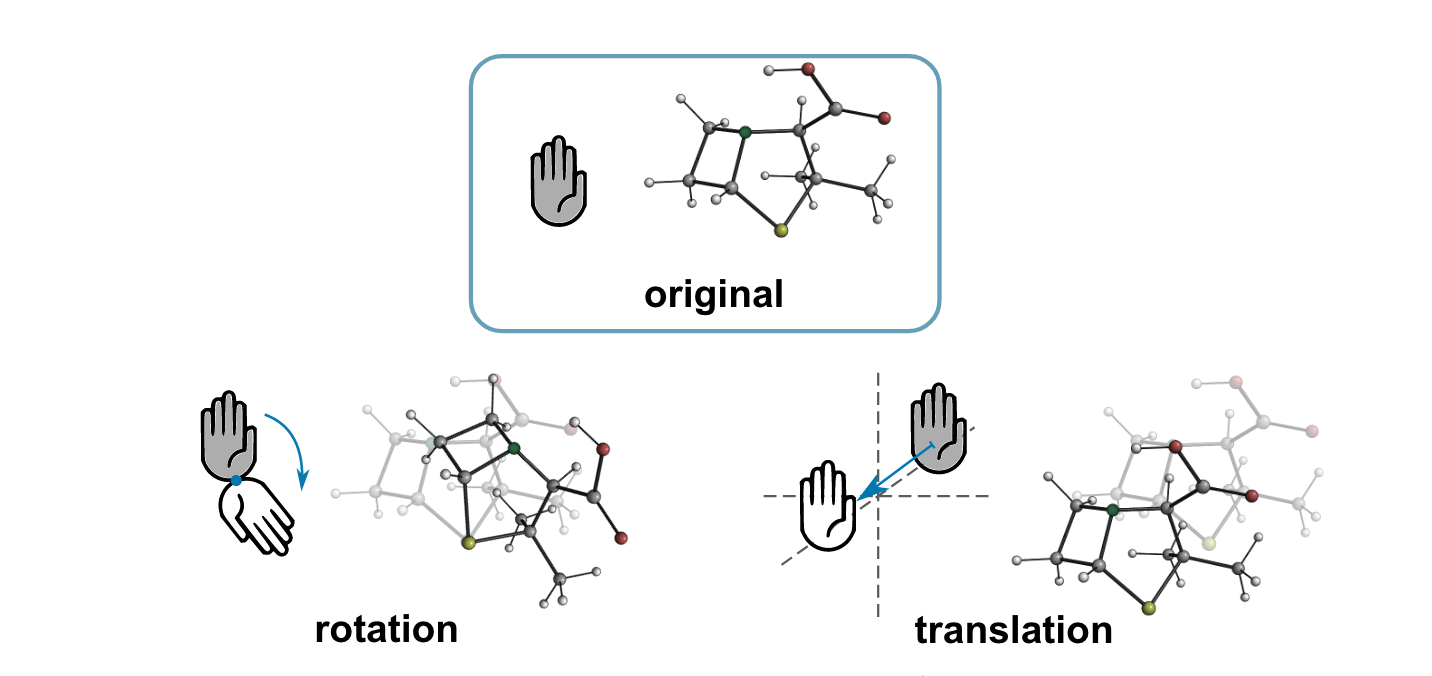
- Invariant: A function gives the same answer no matter how you rotate or move the input. Example: a molecule’s total energy shouldn’t change if you spin the molecule. Think: a snowflake is still a snowflake after you turn it.
- Equivariant: If you rotate the input, the output rotates in a matching way. Example: a force vector pointing “east” should rotate to “north” if you rotate the molecule 90°. Think: a weather vane turns as the wind changes—direction changes in a predictable way.
Groups and rotations (legal moves)
- SO(3) is the set of all 3D rotations—the “legal moves” for spinning an object in space.
- SE(3) adds translations (moving without rotating). Molecules don’t care where they are in space—only how their parts are arranged relative to each other.
Spherical tensors (standard building blocks for rotation)
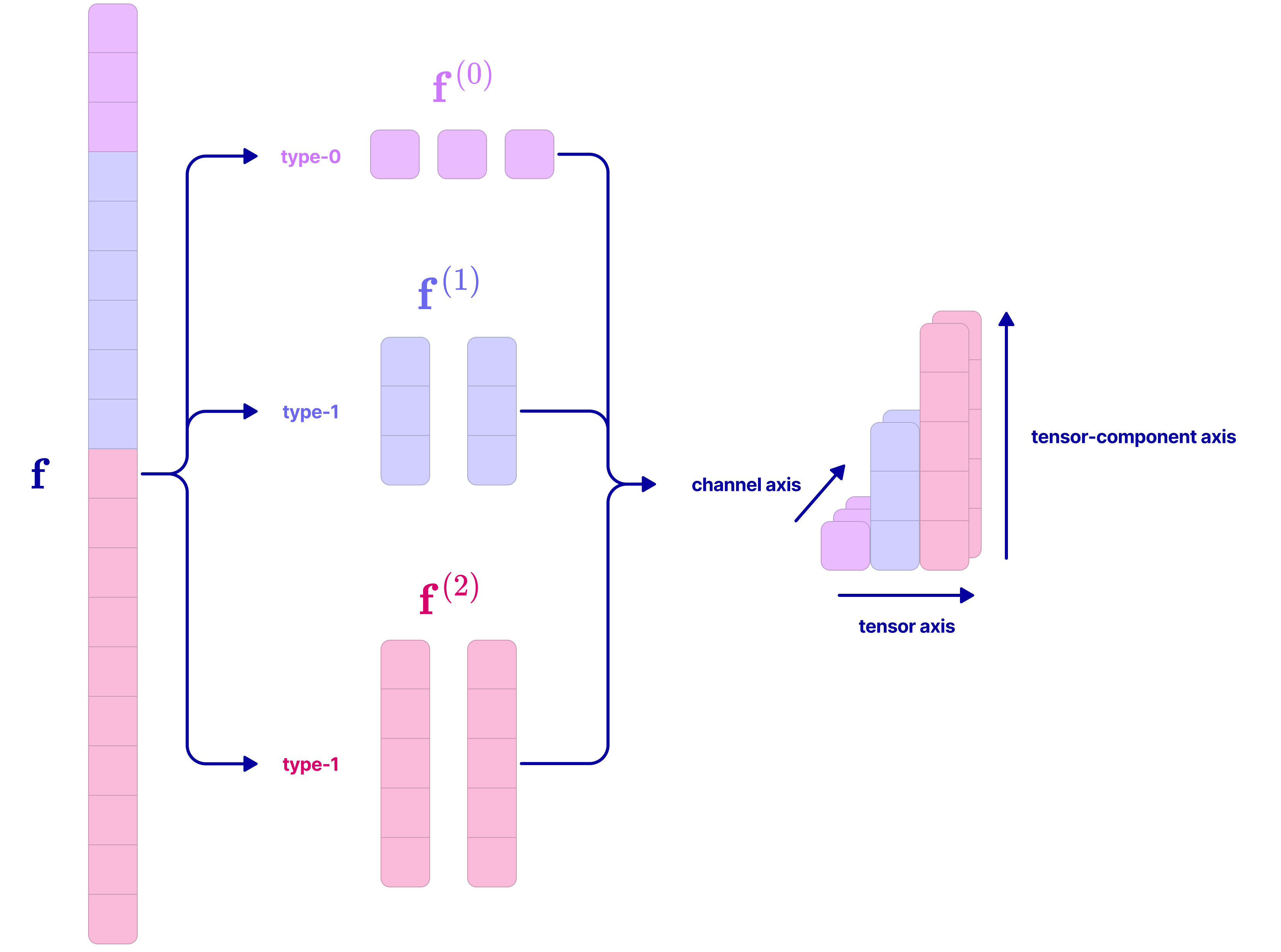
- Regular 3D vectors and higher‑order features can be broken into “standard pieces” that rotate in well‑defined ways. These pieces are called spherical tensors of different “degrees” (0, 1, 2, …).
- Degree 0: scalars (don’t change when you rotate)
- Degree 1: 3D vectors (rotate like arrows)
- Higher degrees: more complex patterns
Analogy: Like sorting Lego bricks by shape so you know exactly how each shape behaves when you twist it.
Spherical harmonics (patterns on a globe)
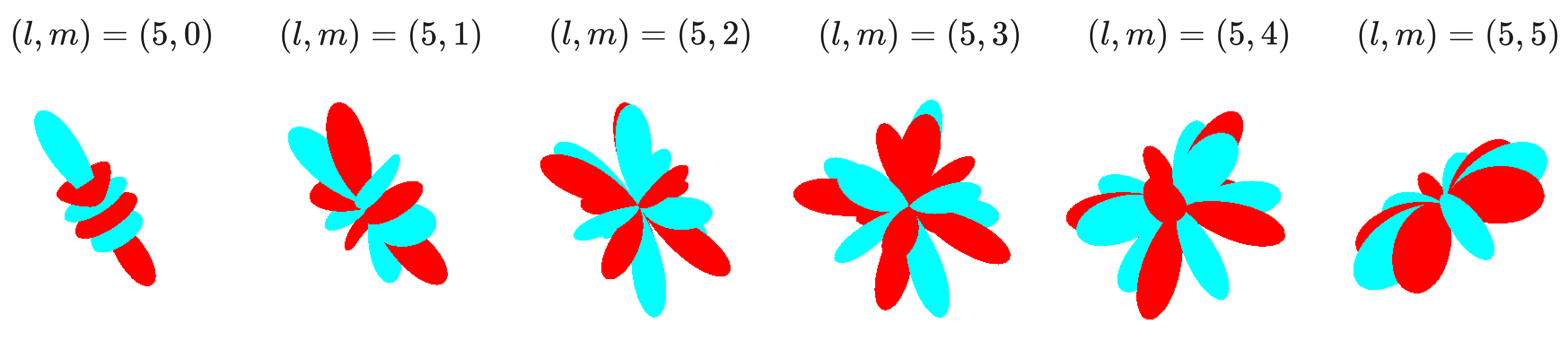
- Spherical harmonics are like a set of patterns painted on a globe—waves that wrap around the sphere. They help turn directions (like the direction from one atom to another) into numbers that change in exactly the right way when you rotate the globe.
- Low “degree” harmonics capture smooth, broad patterns; higher degrees capture finer, sharper details.
Analogy: Like using bass and treble in music—low degrees are bass notes, high degrees are treble details.
Wigner‑D matrices (rotation dials)
- These are the precise “turning knobs” that describe how each spherical tensor rotates. Apply the right matrix, and your features rotate correctly.
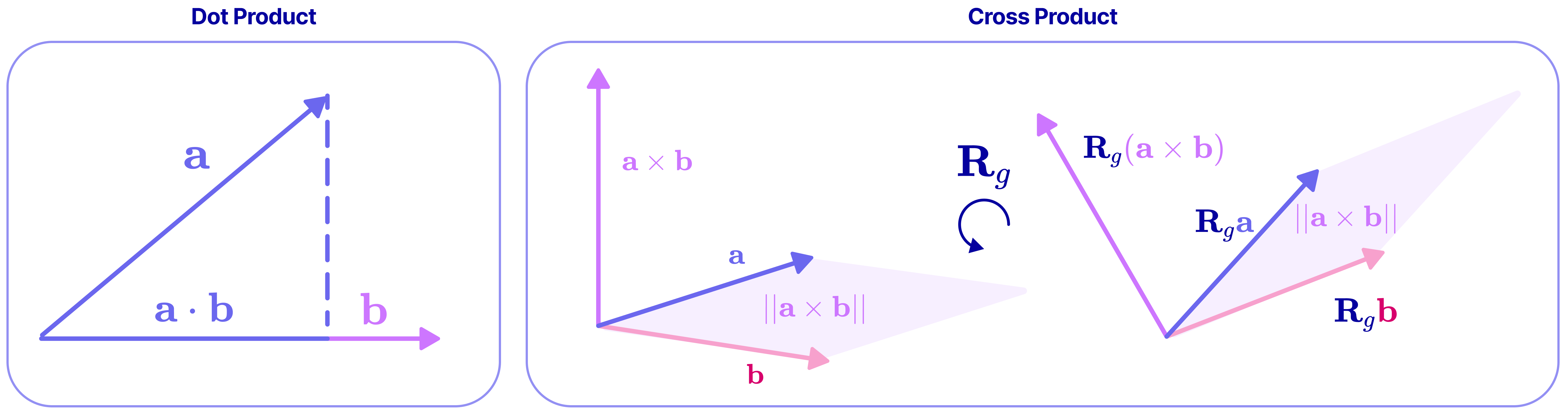
Tensor products and Clebsch–Gordan (mixing and re‑sorting information)
- Sometimes you need to combine two features (say, two vectors). The tensor product is how you “mix” them.
- After mixing, you “sort” the result back into the standard spherical pieces using Clebsch–Gordan coefficients.
Analogy: Mix two colors of paint (tensor product), then separate the mix into a palette of basic colors (decomposition) so you still know how each part behaves under rotation.
Equivariant kernels and message passing (3D‑aware filters)
- In image CNNs, filters detect patterns anywhere in the image. Here, kernels are like 3D filters that detect patterns regardless of how the 3D object is rotated.
- The paper shows how to build these kernels from:
- Direction on the sphere (using spherical harmonics)
- Distance between atoms (using learnable “radial” functions)
- Proper mixing rules (using tensor products and Clebsch–Gordan)
- These kernels let nodes (atoms) pass messages to their neighbors in a way that’s consistent with physics.
Tensor Field Networks and SE(3)-Transformers (putting it all together)
- Tensor Field Networks (TFNs): Do equivariant message passing using the kernels above.
- SE(3)-Transformers: Bring in attention (queries/keys/values), but make it physics‑aware:
- Attention scores are invariant (don’t change if you rotate the molecule)
- Value updates are equivariant (rotate appropriately with the input)
- The paper explains how to construct queries, keys, and values as spherical tensors so attention stays rotation‑correct.
From data to graphs (and code)
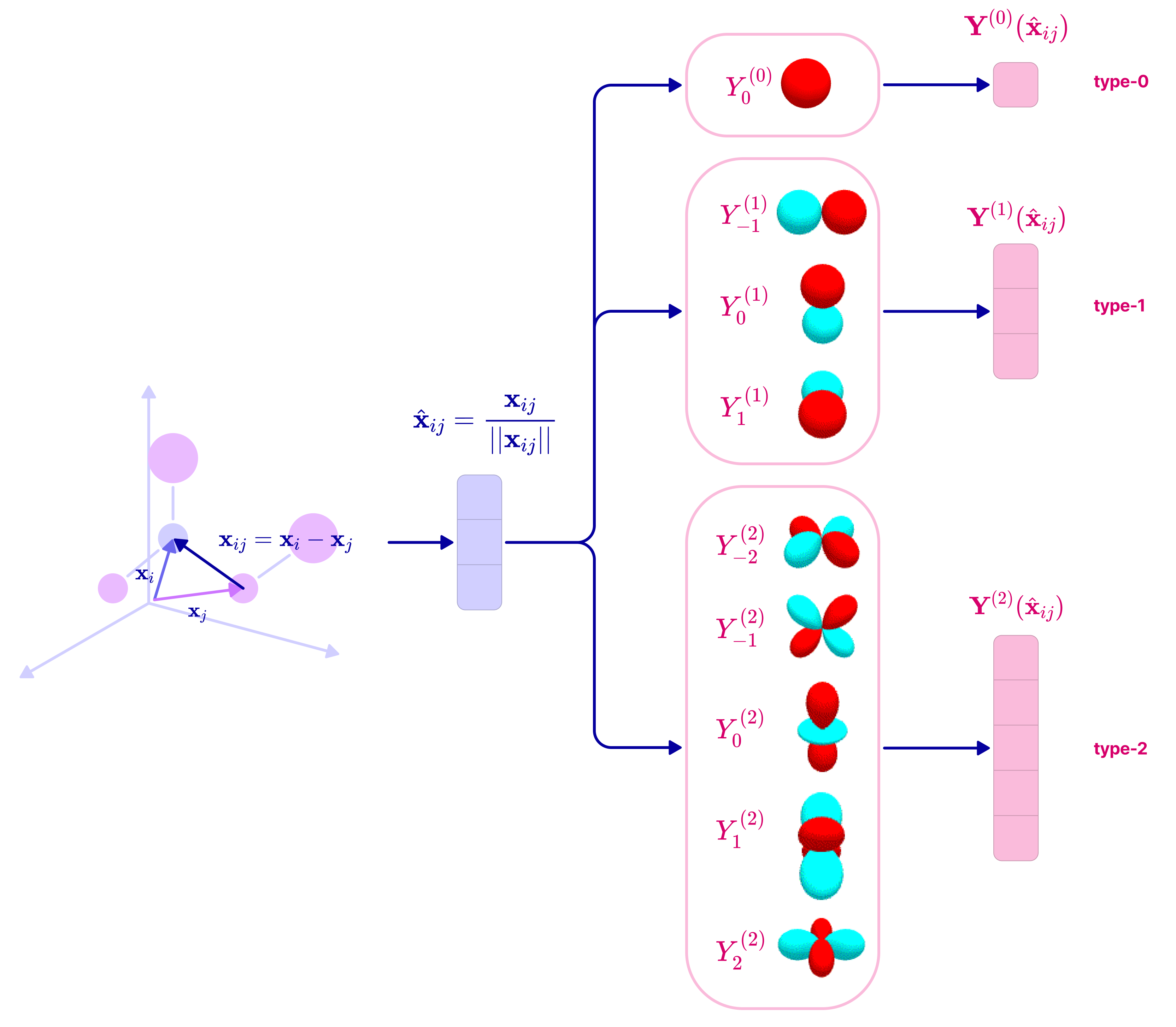
- Start with a 3D point cloud (atoms with positions and features).
- Build a graph: nodes are atoms, edges connect nearby atoms; each edge has a direction (displacement vector), a distance, and a unit direction.
- Implement with PyTorch and DGL (Deep Graph Library), with code that mirrors the math.
What are the main takeaways?
- It’s a complete, intuitive roadmap: from the math (groups, spherical harmonics, Wigner‑D, tensor products) to practical architectures (TFN and SE(3)-Transformer) and working code.
- You learn how to design 3D “filters” and attention that respect rotation, so the model doesn’t get confused when molecules are turned.
- You don’t need to train on lots of randomly rotated copies of the same molecule—equivariance is built in.
- The guide shows how to apply these models to real molecular data (like the QM9 dataset) for tasks such as predicting molecular properties.
Why does this matter?
- Better science: Predictions stay physically meaningful when you rotate molecules. That’s closer to how nature works.
- Improved performance: Models generalize better, need less data augmentation, and often learn faster.
- Real‑world uses:
- Chemistry and drug discovery: predict molecular properties more reliably.
- Protein design: understand how parts of a protein interact in 3D.
- Generative modeling: design new molecules or materials with desired properties.
- Broader impact: Any 3D task that involves rotations—like robotics, physics simulations, or 3D vision—can benefit from these ideas.
In short, the paper teaches you how to build neural networks that “think in 3D” the way physics does—so when you spin the world, the math spins with it, and the answers still make sense.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved by the paper and could guide future research:
- Scope beyond SO(3): How to extend the presented framework to O(3) (parity/reflection) and full E(3) equivariance when tasks are parity-sensitive (e.g., chirality, pseudoscalars) or require reflection symmetry handling?
- Practical handling of chirality: What architectural or representation changes are needed to predict properties that flip under inversion (e.g., optical activity), and how should parity-odd irreps be incorporated in practice?
- Numerical stability at high degree l: What are stable, efficient algorithms for computing and differentiating high-order Wigner-D matrices and spherical harmonics (real or complex) during training, especially near angular singularities and for large l?
- Truncation error from finite l_max: How does the choice of maximum degree l_max and multiplicities per degree affect approximation error, sample complexity, and generalization, and are there principled criteria for choosing l_max per task?
- Radial basis design: What are the comparative effects of different radial bases (e.g., RBF, Bessel, learned splines), cutoff strategies, and normalization on accuracy, stability, and data efficiency across tasks?
- Scalability and complexity: What are the exact time/memory complexities of TFN/SE(3)-Transformer layers as functions of N (nodes), E (edges), l_max, and channel multiplicities, and which optimizations (kernel fusion, caching, sparsity) yield best trade-offs?
- Large biomolecular systems: How do these models scale to long proteins, complexes, or dense solvent environments, and what graph sparsification or hierarchical strategies are needed to keep performance and memory feasible?
- Hierarchical/multiscale modeling: How to design equivariant pooling, coarsening, or hierarchical attention that preserves equivariance while enabling long-range reasoning and multiscale protein modeling?
- Long-range interactions and PBCs: How to integrate periodic boundary conditions, minimum-image conventions, and long-range electrostatics (e.g., Ewald/PME) into equivariant message passing without breaking equivariance?
- Edge construction sensitivity: How do neighbor selection methods (radius vs kNN), dynamic neighbor updates, and density variations impact performance and equivariance; can adaptive or learned neighborhood schemes be made equivariant and stable?
- Non-geometric categorical features: What are best practices for incorporating discrete chemistry (bond orders, aromaticity, residue types) into equivariant pipelines while retaining symmetry properties?
- Message-passing depth vs expressivity: What are the expressivity limits (e.g., many-body interactions, higher-order correlations) of finite-depth, finite-l architectures, and how do depth, width, and l_max trade off against over-smoothing or oversquashing?
- Universal approximation guarantees: Do SE(3)-Transformers (with finite l_max and standard nonlinearities) enjoy universal approximation for relevant invariant/equivariant function classes; if so, under what conditions?
- Nonlinearities for tensor features: Which equivariant nonlinearities (gated, norm-based, higher-order couplings) perform best across degrees and tasks, and what are their stability trade-offs?
- Attention design choices: How do different designs for invariant attention scores (e.g., which scalar combinations are used) and value updates from higher-degree channels affect expressivity and robustness?
- Training energy/force consistency: How to enforce conservative force learning (forces as gradients of predicted energy) in equivariant Transformers, and what losses/architectures ensure physical consistency?
- Uncertainty quantification: How to obtain calibrated uncertainties and physically meaningful confidence estimates in equivariant models (e.g., Bayesian layers, ensembling) without violating symmetry constraints?
- Noise and missing data: How robust are these models to coordinate noise, missing atoms/residues, alternate conformations, or unresolved regions, and what equivariant imputation/denoising strategies are effective?
- Temporal/dynamical extensions: How to extend these models to spatio-temporal equivariance (SE(3) × R), incorporate time-reversal symmetries, or learn stable dynamical systems for MD simulations?
- Generative modeling specifics: What are best practices for equivariant generative models (diffusion/flows) in terms of score parameterization per degree, noise schedules, and sampling schemes that preserve symmetries?
- Interpretability of learned filters: How can learned spherical filters and attention patterns be visualized and related to physical interactions (e.g., orbital-like patterns, angular preferences) in a way that aids scientific insight?
- Benchmarks beyond QM9: How do the methods perform on larger and more diverse datasets (proteins, complexes, materials with PBCs, reaction pathways), and what standardized benchmarks and protocols are needed?
- Domain adaptation and transfer: How well do equivariant features transfer across chemical domains (small molecules → proteins → materials), and which pretraining tasks retain physically meaningful representations?
- Hardware and software optimization: Which implementation strategies (custom CUDA kernels, e3nn vs DGL vs PyTorch Geometric, mixed precision) deliver the best speed/memory balance for high-degree, multi-channel models?
- Automatic architecture selection: Can we develop principled or automated procedures (e.g., NAS) to allocate channels per degree, choose l_max, and select interaction blocks based on task/dataset characteristics?
- Unit handling and normalization: What normalization schemes (distance scaling, unit standardization) minimize numerical issues and improve cross-dataset generalization without undermining physical meaning?
- Reflection on real vs complex harmonics: When (if ever) do complex spherical harmonics offer tangible advantages (e.g., numerical stability, expressivity) over real harmonics in deep learning applications?
- Evaluation of equivariance in practice: How to rigorously test and monitor equivariance during training (e.g., numerical drift, float precision issues), and what tolerances are acceptable per application?
- Combining with sequence/context: How to fuse SE(3)-equivariant structure modules with sequence LLMs or other modalities while preserving geometric symmetries and avoiding frame leakage?
- Handling heterogeneous graphs: What architectural patterns best support multiple node/edge types with different physical transformations, ensuring consistent equivariance across heterogeneous interactions?
- Regularization for high-degree channels: Which regularizers (spectral norm, coefficient decay per degree, angular frequency penalties) mitigate overfitting or numerical instabilities at large l?
- Data augmentation interplay: Does augmentation (e.g., rotations, reflections, perturbations) remain beneficial for robustness in already-equivariant models, and under what regimes does it help or harm?
- Readout design for different targets: What are optimal invariant/equivariant readout heads for scalar, vector, and higher-rank tensor targets, and how should they be calibrated to physical units and constraints?
Practical Applications
Below is an application-focused synthesis of the paper’s contributions on spherical equivariant graph transformers (TFN/SE(3)-Transformer), mapping their methods and insights to real-world uses, sectors, and deployment considerations.
Immediate Applications
The following use cases can be deployed now, leveraging existing libraries (e.g., e3nn, DGL, PyTorch), open datasets (e.g., QM9), and established workflows in cheminformatics and computational physics.
- Molecular property prediction for virtual screening (Healthcare, Materials; Industry/Academia)
- What: Train SE(3)-Transformers on 3D molecular graphs to predict formation energies, dipole moments, HOMO/LUMO gaps, partial charges, polarizabilities, and simple reactivity proxies without rotational data augmentation.
- Tools/workflows: Datasets like QM9/MD17, featurization with RDKit + neighbor graphs, PyTorch + DGL or PyG, e3nn for spherical harmonics/irreps; model cards including invariance/equivariance tests; plug into screening pipelines (e.g., DeepChem, KNIME nodes).
- Assumptions/dependencies: High-quality 3D conformers; appropriate l_max and cutoff radii; numerical stability of higher-degree spherical harmonics; GPU resources; careful handling of multiple conformers per ligand.
- Learned interatomic potentials for molecular dynamics acceleration (Energy, Materials, Pharma; Industry/Academia)
- What: Use equivariant message passing to learn force fields (energies/forces) for MD (e.g., NequIP-style potentials), accelerating ab initio simulations by orders of magnitude while preserving rotational physics.
- Tools/workflows: ASE/LAMMPS/OpenMM integration; active learning loops (on-the-fly DFT label queries); precompute radial basis + spherical harmonic bases; model validation via conservation tests and extrapolation monitoring.
- Assumptions/dependencies: Reliable DFT/CC reference data; out-of-distribution detection; careful cutoff and neighbor list handling; periodic boundary handling (requires E(3) + PBC support).
- Protein structure feature learning and geometric reasoning (Healthcare; Academia/Industry)
- What: Use SE(3)-Transformers to encode residue/atom graphs for tasks like side-chain packing, rotamer scoring, local structure classification, motif detection, and micro-environment property prediction.
- Tools/workflows: PDB-derived graphs (Cα or all-atom), local kNN edges with displacement features, downstream integration with Rosetta/PyRosetta, use e3nn for type-k features and equivariant layers.
- Assumptions/dependencies: Accurate experimental structures or reliable predicted models; appropriate granularity (residue vs all-atom); careful handling of symmetry and chain breaks.
- Protein–ligand pose scoring and refinement (Healthcare; Industry/Academia)
- What: Equivariant attention for binding pose ranking, rescoring, and local pose refinement; robust to arbitrary rotation of complex.
- Tools/workflows: Docking pipelines (e.g., AutoDock, GNINA) with post hoc SE(3)-Transformer rescoring; message passing across protein–ligand interface; plug-ins for workflow engines (e.g., Nextflow, Snakemake).
- Assumptions/dependencies: Sufficient training data with labeled poses/affinities; efficient batching of large complexes; heavy-atom type diversity.
- Rotation-robust 3D perception for point clouds (Software/Robotics; Industry)
- What: Apply equivariant attention/message passing to object classification/segmentation in LiDAR/3D scanning where orientation variance is high (e.g., drones, warehouse robots).
- Tools/workflows: Graph construction on point clouds (radius/kNN), spherical harmonics for local directions, deployment in ROS/RViz pipelines; quantization-aware training for edge inference.
- Assumptions/dependencies: Real-time constraints (O(N·k) neighborhood ops); careful l_max choice to balance accuracy/latency; sensor noise and sparsity.
- Robust 3D CAD feature recognition and metrology (Manufacturing; Industry)
- What: Orientation-agnostic detection of geometric features (holes, fillets, ribs) and tolerance deviations in 3D meshes using equivariant kernels.
- Tools/workflows: Convert CAD/mesh to graph via mesh adjacency; fine-tune SE(3)-Transformers for defect detection; integrate with PLM/QA tools.
- Assumptions/dependencies: Mesh quality manifoldness; handling of scale/units; class imbalance in defect data.
- Physics-informed surrogate modeling (Aero/Auto/ChemE; Academia/Industry)
- What: Build fast, rotation-consistent surrogates of localized 3D physics (e.g., flow around components, localized stress, EM field features) using equivariant kernels as inductive biases.
- Tools/workflows: FEM/CFD local patches to graphs; couple with radial basis functions; uncertainty quantification and sensitivity analyses.
- Assumptions/dependencies: Good coverage of operative regimes; consistency with governing equations (may need additional constraints); unit/scale normalization.
- Education and training in geometric deep learning (Education; Academia)
- What: Adopt the paper’s derivations and annotated code to teach irreps, spherical harmonics, Clebsch–Gordan, and equivariant attention; build course modules/lab assignments.
- Tools/workflows: e3nn tutorials, DGL notebooks, QM9 labs; automatic checks for equivariance; student exercises on implementing basis kernels.
- Assumptions/dependencies: GPU access for students; scaffolded math prerequisites; maintained library versions (DGL/PyTorch).
- Reproducible benchmarking and ablations for 3D ML (Policy/Academia/Industry)
- What: Establish baselines that explicitly test SO(3) invariance/equivariance, report l_max, basis choices, and neighbor radii; reduce reliance on data augmentation.
- Tools/workflows: Shared evaluation harness for rotated inputs; published configs and seeds; model cards detailing symmetry tests.
- Assumptions/dependencies: Community buy-in; standardized datasets and loaders; versioned dependencies to ensure reproducibility.
- Structure-aware molecular generative modeling components (Healthcare/Materials; Academia/Industry)
- What: Plug equivariant encoders/decoders into 3D diffusion or autoregressive generators for small molecules (conformer-aware) and fragments.
- Tools/workflows: Conditional generation (scaffolds/pharmacophores); combine sequence-level models with 3D equivariant modules; evaluation via docking/MD.
- Assumptions/dependencies: Robust 3D evaluation metrics; avoidance of mode collapse; reliable conformer generation for training data.
Long-Term Applications
These use cases may require further research, scaling, engineering, or integration with broader systems (e.g., wet-lab loops, domain-specific constraints, or real-time guarantees).
- End-to-end protein design with fully equivariant backbones (Healthcare; Industry/Academia)
- What: Joint sequence–structure generation and evaluation loops where equivariant attention handles orientation-agnostic constraints, side-chain packing, and binding-site shaping.
- Tools/products: Design studio platforms integrating SE(3)-Transformers with sequence models and differentiable docking; automated design-test cycles.
- Assumptions/dependencies: Reliable wet-lab validation; multi-objective optimization (stability, expression, immunogenicity); scalable training on large structural corpora.
- Universal atomistic foundation models (Materials/Energy/Healthcare; Industry/Academia)
- What: Pretrained equivariant models spanning chemistry domains (small molecules, materials, proteins) transferable across tasks (property prediction, forces, reactivity).
- Tools/products: Foundation checkpoints with adapters; inference APIs; on-device fine-tuning for enterprise datasets.
- Assumptions/dependencies: Massive curated multi-domain 3D datasets; cross-domain tokenization of chemical/biological context; efficient training of high l_max.
- Autonomous closed-loop discovery platforms (Healthcare/Materials; Industry)
- What: Equivariant predictors guide synthesis and high-throughput experiments; active learning selects next experiments; models remain rotation-consistent across instruments.
- Tools/workflows: ELN/LIMS integration, robotics interfaces, uncertainty-aware selection policies; continuous retraining with new 3D data.
- Assumptions/dependencies: Robust lab automation; real-time data ingestion; governance for model updates and IP/data security.
- Real-time, hardware-efficient 3D perception via equivariant transformers (Robotics/AR/VR; Industry)
- What: Orientation-robust perception on embedded hardware for drones, wearables, and autonomous platforms with energy-efficient equivariant attention.
- Tools/products: Compilers for irreps-aware kernels; approximate spherical harmonics; pruning/quantization toolchains.
- Assumptions/dependencies: Dedicated kernels for tensor products and Clebsch–Gordan ops; strict latency budgets; co-design of model and hardware.
- Equivariant surrogates for quantum chemistry workflows (Energy/Materials/Pharma; Industry/Academia)
- What: Replace expensive geometry optimization steps and property evaluations with equivariant surrogates integrated inside DFT/CC pipelines.
- Tools/workflows: Hybrid QM/ML stacks with trust-region monitoring; batch screening at scale (catalysts, electrolytes).
- Assumptions/dependencies: Tight error bounds and certified uncertainty; robust extrapolation detection; periodicity/symmetry group extensions.
- Cryo-EM map interpretation and integrative modeling (Healthcare; Academia)
- What: Use equivariant attention to fuse 3D density maps and atomic graphs for model building/refinement robust to map orientation.
- Tools/workflows: Integration with Phenix/CCP-EM; equivariant encoders for local density patches; pose-consistent refinement loops.
- Assumptions/dependencies: High-resolution maps; noise-robust training; data sharing and standards.
- Safety, standards, and policy for symmetry-aware ML in regulated domains (Policy; Regulators/Industry)
- What: Formalize tests for invariance/equivariance in model validation; reporting standards for symmetry assumptions and basis choices in submissions (e.g., drug/device).
- Tools/workflows: Compliance checklists; standardized test batteries for rotated inputs; documentation templates.
- Assumptions/dependencies: Interagency working groups; community consensus; mapping to existing regulatory frameworks.
- Consumer 3D creation and scanning apps with built-in symmetry priors (Daily life/Software; Industry)
- What: Improved robustness in mobile 3D scanning, photogrammetry, and object capture to arbitrary device orientations, leading to cleaner meshes and consistent features.
- Tools/products: SDKs with equivariant feature extractors; plugins for popular 3D tools (Blender, Unity) to stabilize geometry processing.
- Assumptions/dependencies: Efficient on-device implementations; adaptation to varying sensor modalities; user privacy and data policy.
Notes on cross-cutting assumptions and dependencies
- Data quality and coverage: Reliable 3D structures (crystal, cryo-EM, predicted), force labels for potentials, and realistic conformer ensembles are critical.
- Computational tractability: Higher l_max and dense neighborhoods improve fidelity but raise memory/latency; kernel fusion and basis precomputation help.
- Numerical stability: Spherical harmonics and Clebsch–Gordan operations at higher degrees require care (normalization, recursion, precision).
- Symmetry alignment: Models assume SO(3) rotational symmetry; for periodic crystals or lattice symmetries, extend to E(3)+PBC or crystallographic groups.
- Integration and governance: For regulated or high-stakes uses, include uncertainty quantification, invariance/equivariance tests, and change-control processes.
Glossary
- Associated Legendre polynomial (ALP): A family of functions derived from Legendre polynomials that encode the polar dependence of spherical harmonics and incorporate order m via derivatives and a sine factor. "The function dependent on is the associated Legendre polynomial (ALP) with degree and order m given by the following equation:"
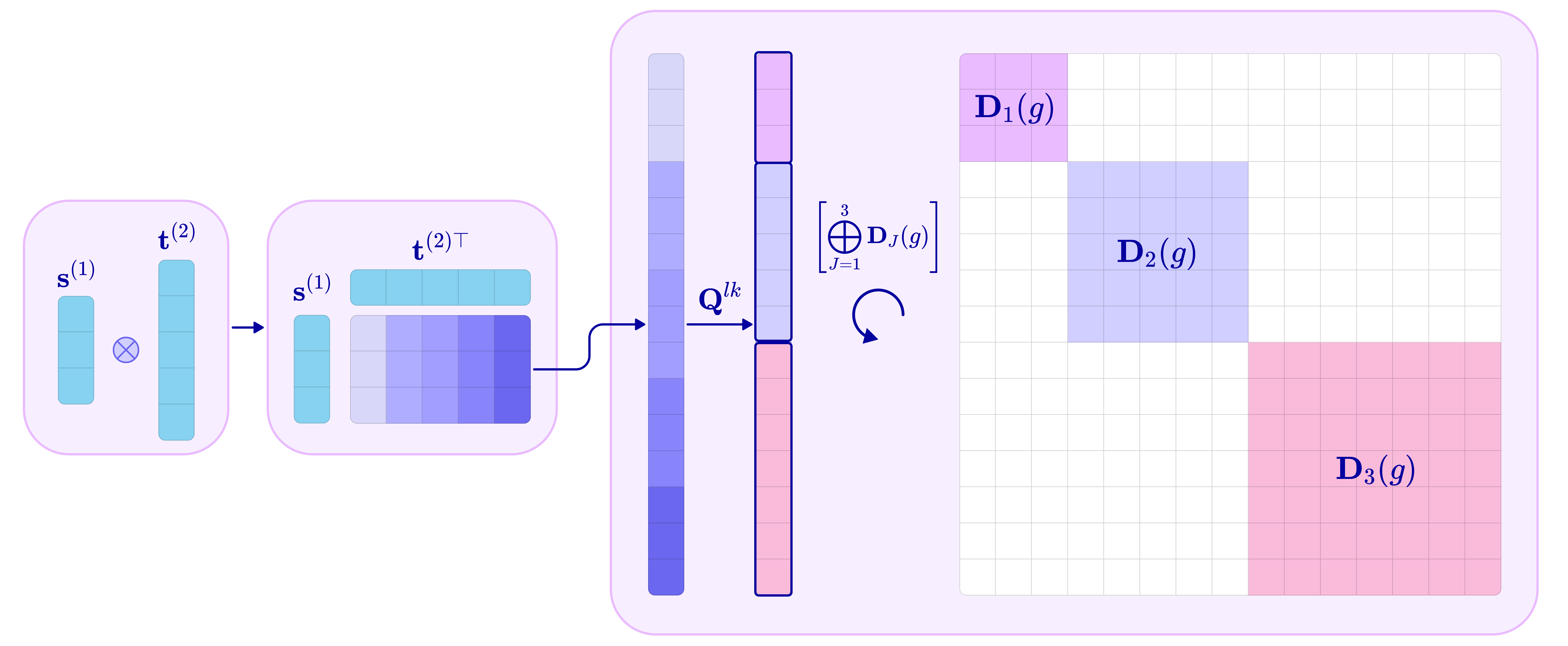
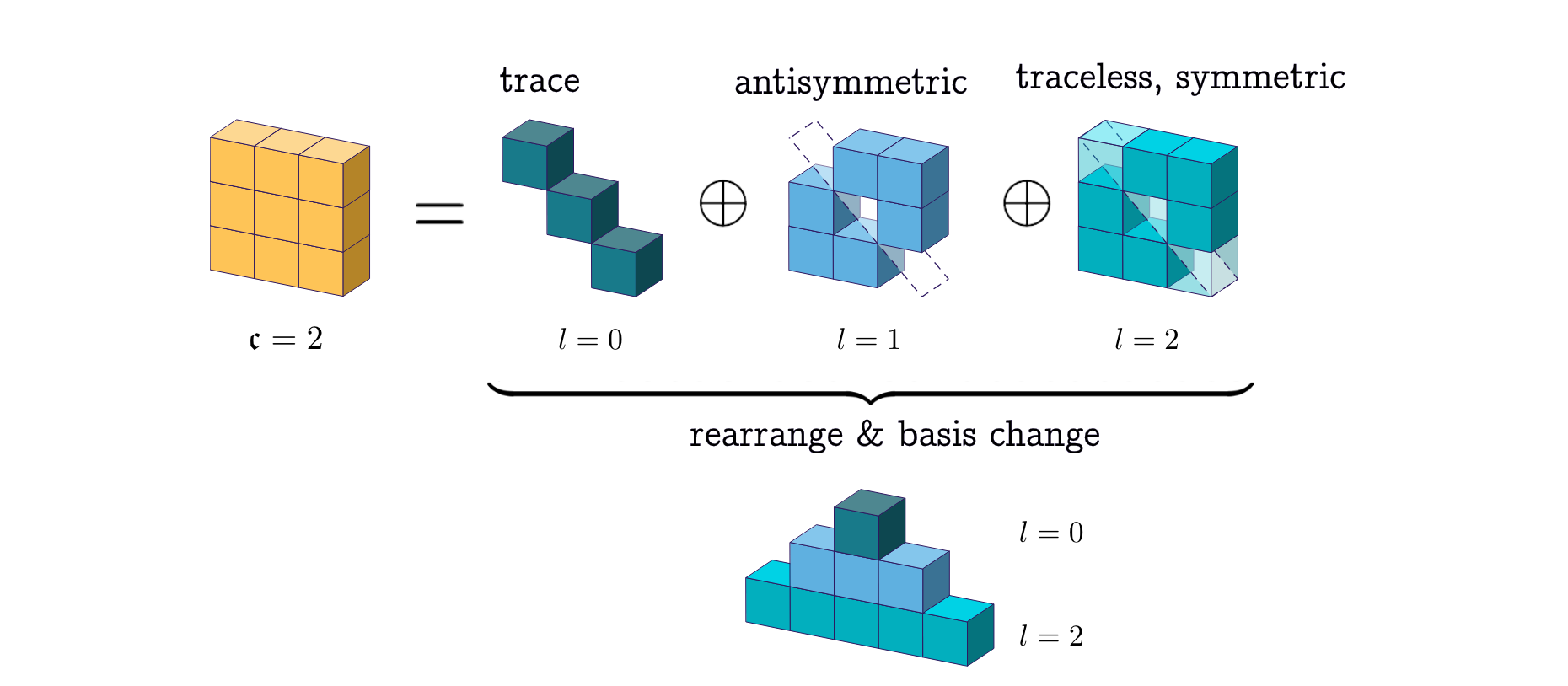
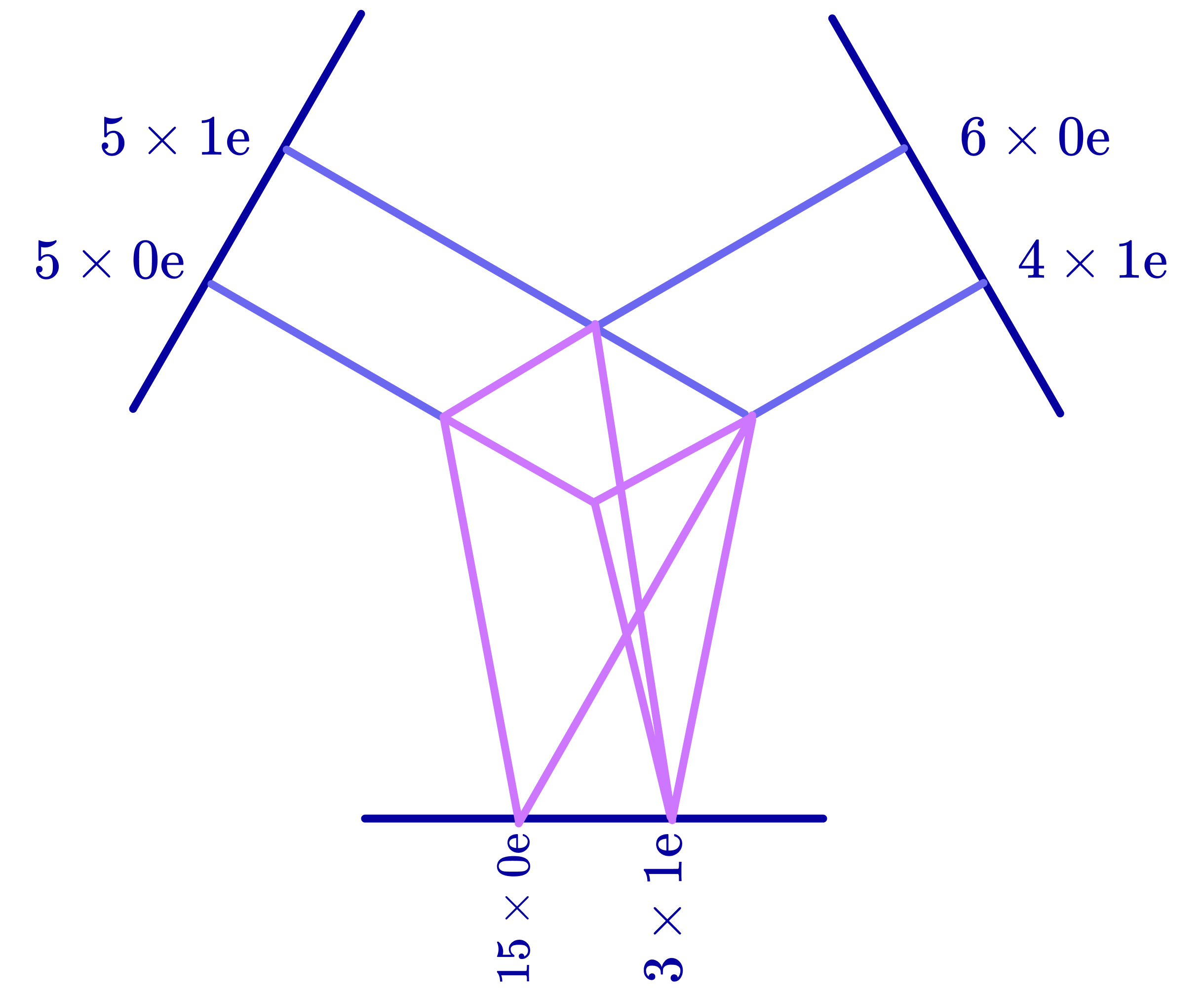
- Clebsch–Gordan decomposition: A procedure from representation theory/quantum mechanics that decomposes the tensor product of two irreducible representations into a direct sum of irreducibles, used to build equivariant operations. "from group representations and spherical harmonics, to tensor products, ClebschâGordan decomposition, and the construction of SO(3)-equivariant kernels."
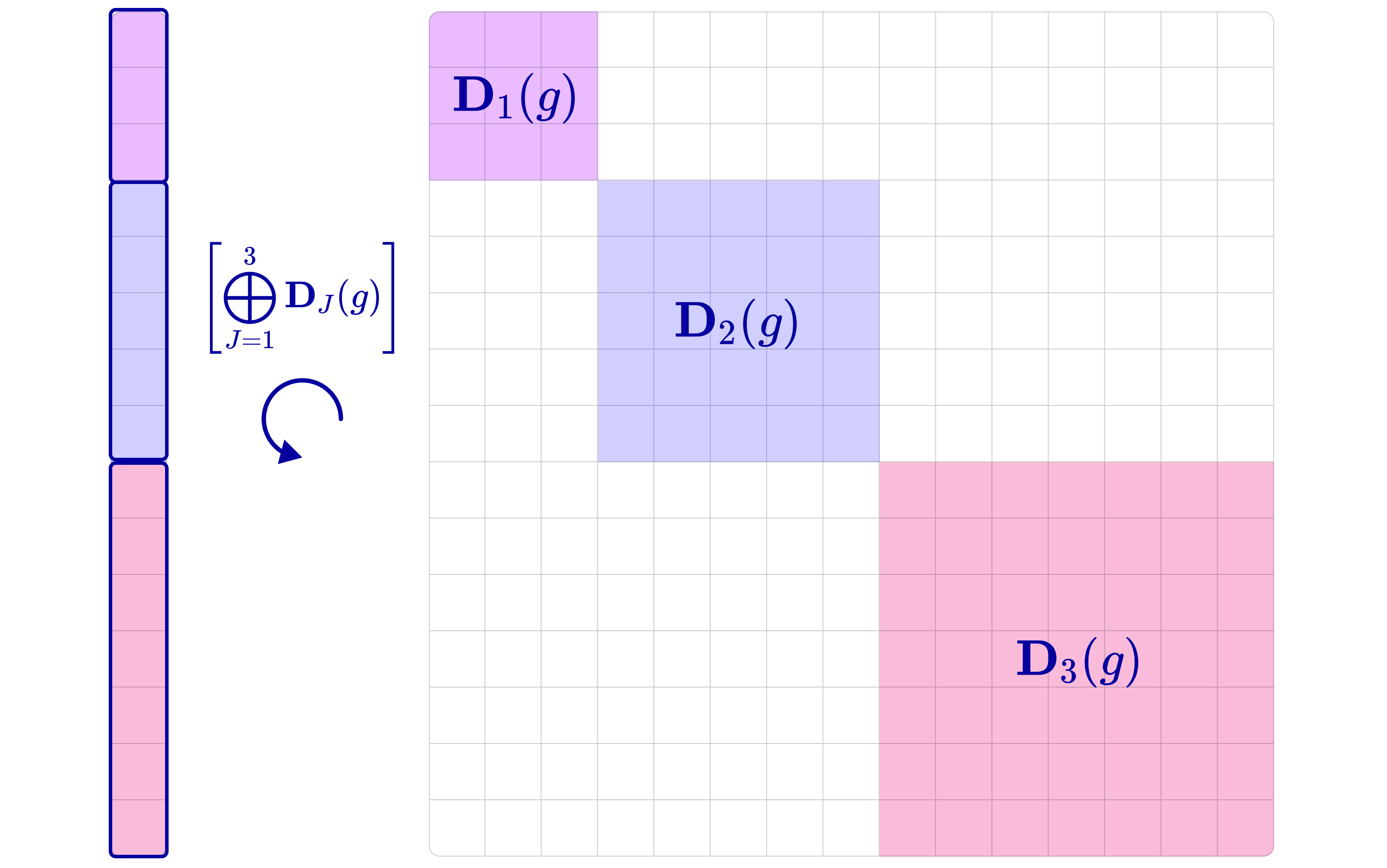
- Direct sum: An operation (denoted ⊕) that combines representations into a block-diagonal representation acting independently on each component. "All group representations can be decomposed into the direct sum (concatenation of matrices along the diagonal) of irreps."
- Equivariant Graph Neural Network (EGNN): A graph neural architecture whose outputs transform predictably under group actions (e.g., rotations), ensuring physical consistency for 3D data. "Spherical equivariant graph neural networks (EGNNs) provide a principled framework for learning on three-dimensional molecular and biomolecular systems, where predictions must respect the rotational symmetries inherent in physics."
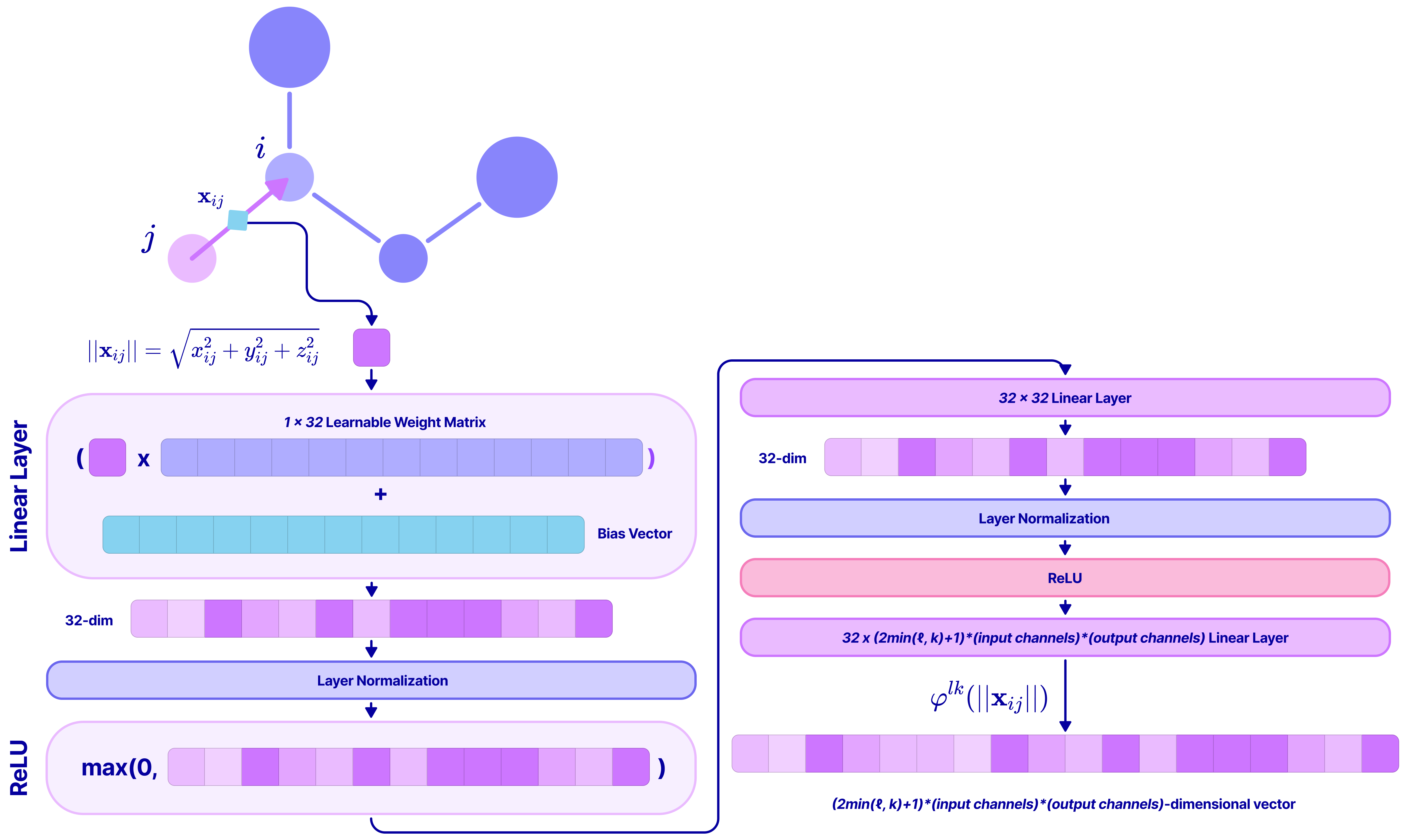
- Equivariant kernel: A learnable operator (filter) designed so that rotating the input rotates the output in a corresponding way, preserving equivariance. "Section \ref{sec:3} derives the SO(3)-equivariant kernel by combining spherical harmonics, ClebschâGordan decomposition, and learnable radial functions, forming the basis for all rotation-equivariant message-passing layers."
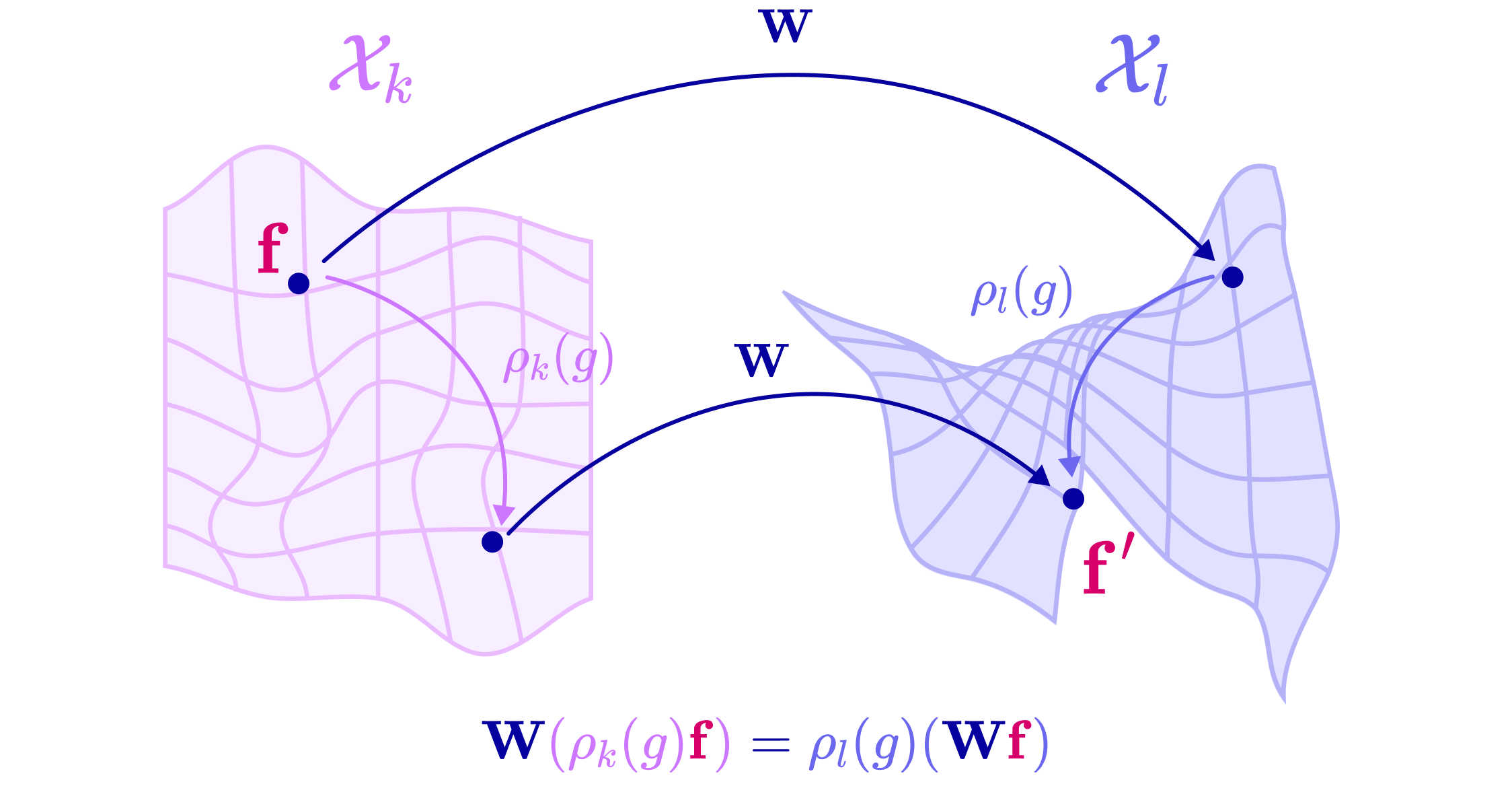
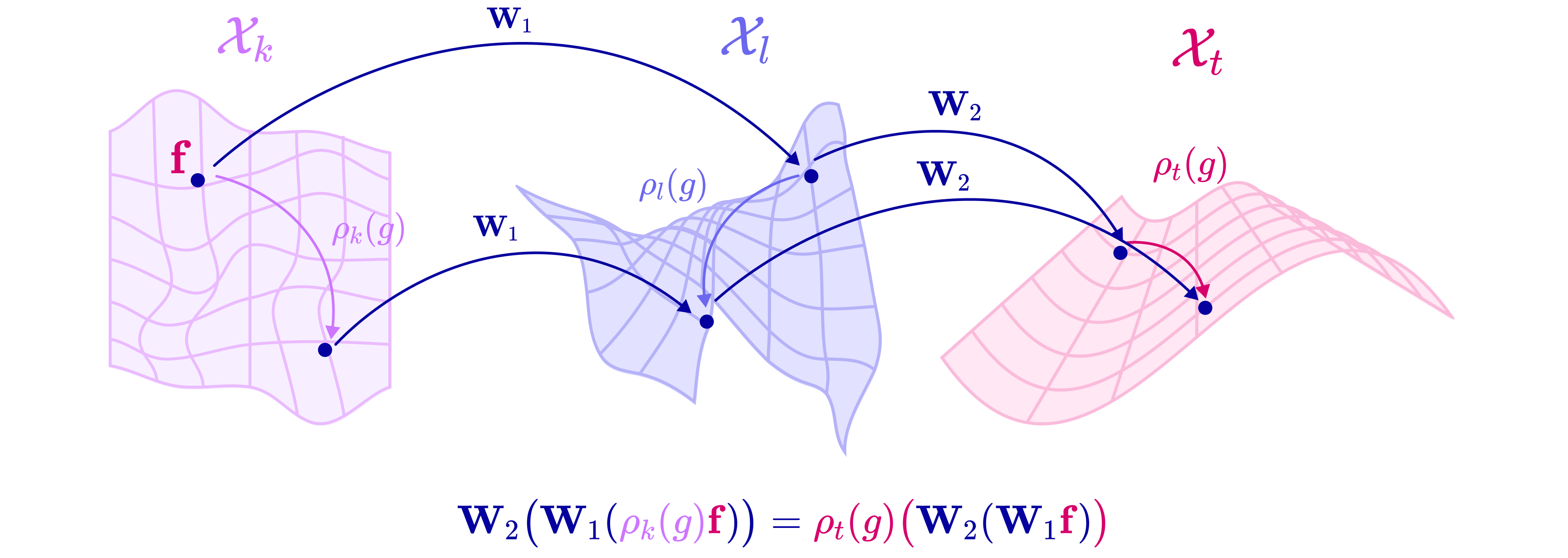
- Equivariance: A symmetry property where applying a transformation to the input results in a corresponding transformation of the output. "When a function produces a predictable transformation of the original output as a direct consequence of a transformation on the input (i.e., translation or rotation), it preserves equivariance."
- Group homomorphism: A structure-preserving map between groups that translates group elements into linear operators while respecting composition. "A group representation is generated via a group homomorphism that takes a group as input and outputs a set of matrices corresponding to each group element while preserving the function of the binary operator:"
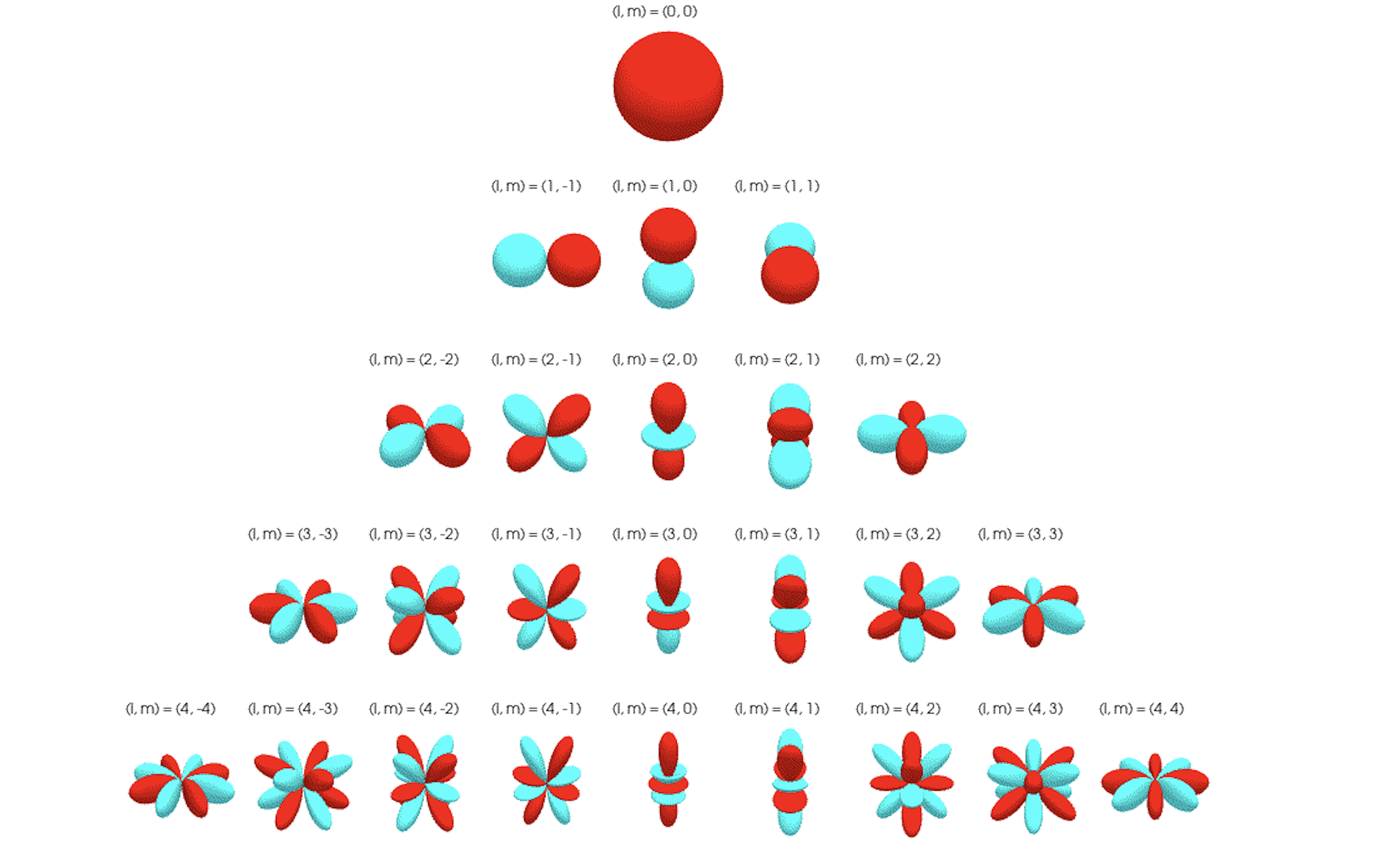
- Irreducible representation (irrep): A minimal, non-decomposable representation of a group that serves as a building block for all representations. "These building blocks are called irreducible representations (irreps) of SO(3), which is a subset of rotation matrices that can be used to construct larger rotation matrices that operate on higher-dimensional tensors."
- Kronecker delta: A discrete function δ that equals 1 when its indices are equal and 0 otherwise; used to express orthogonality conditions. "The integral of the product of spherical harmonics over the unit sphere (inner product) is equal to the product of two Kronecker deltas , which is equal to 1 if or , and zero otherwise."
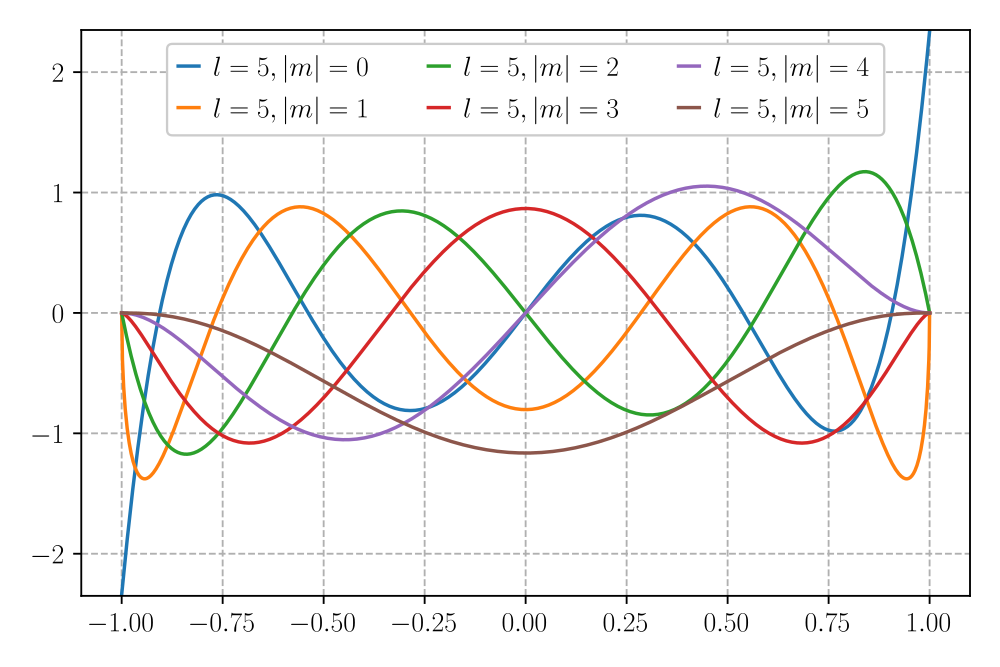
- Legendre polynomial: Orthogonal polynomials on [-1,1] that form the basis for spherical harmonics' polar dependence. "In the equation above, denotes the Legendre polynomial with maximum degree ."
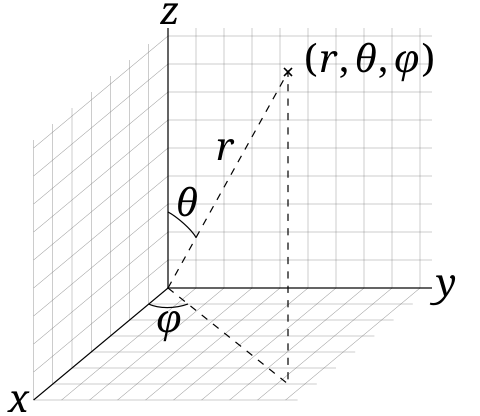
- Magnetic quantum number: The integer m specifying the projection of angular momentum along a chosen axis, indexing spherical harmonic components. "The dimensions correspond to the possible magnetic quantum numbers, which have integer values ranging from to (denoted with the letter ) and are equal to the projected angular momentum on the -axis relative to an external magnetic field."
- Orbital angular momentum operator: Quantum mechanical operators ( and ) whose eigenfunctions on the sphere are spherical harmonics, with quantized eigenvalues. "Spherical harmonics are eigenfunctions of the orbital angular momentum operators and that act on electron wavefunctions."
- Permutation equivariance: The property that permuting node indices permutes outputs correspondingly (or yields invariance), central in GNN design. "Functions in geometric GNNs should satisfy three types of equivariance in 3D: permutation equivariance, translation equivariance, and rotation equivariance."
- Point convolution: A continuous convolution applied over points in space (e.g., a point cloud), often implemented via kernels on coordinates. "Representing graphs as continuous functions facilitates continuous convolutions that are applied to every point in space, also known as point convolutions."
- SE(3) (Special Euclidean Group): The group of all 3D rigid motions (rotations and translations). "The Special Euclidean Group in 3D, known as the SE(3) group, is the set of all rigid 3D transformations, including rotations and translations."
- SE(3)-Transformer: A transformer architecture that enforces SE(3) symmetry, enabling equivariant attention and message updates on 3D graphs. "Building on this foundation, we construct the Tensor Field Network and SE(3)-Transformer architectures and explain how they perform equivariant message-passing and attention on geometric graphs."
- SO(3) (Special Orthogonal Group): The group of all 3D rotations, often the target symmetry for equivariant models. "We will focus on the subset of SE(3) called the Special Orthogonal Group in 3D, known as the SO(3) group, which is the set of all 3D rotations."
- Spherical harmonics: Orthonormal basis functions on the sphere that map directions to components transforming under SO(3) irreps. "Spherical harmonics represent a complete and orthonormal basis for rotations in SO(3)."
- Spherical tensor: A tensor that transforms directly under a single SO(3) irrep (type-l), avoiding the need for change of basis. "There is a special subset of tensors called spherical tensors that transform directly under the irreps of SO(3) without the need for a change in basis."
- Tensor Field Network (TFN): A neural architecture that uses SO(3)-equivariant kernels for message passing on geometric graphs. "Section \ref{sec:4} explains how Tensor Field Networks implement equivariant message-passing and self-interaction using the kernels developed earlier, serving as a foundational architecture for spherical EGNNs."
- Tensor product: A bilinear operation that combines two tensors into a higher-order tensor, later decomposed into irreps for equivariant processing. "The tensor product is a bilinear and equivariant operation that combines two spherical tensors to produce a higher-dimensional tensor."
- Wigner-D matrix: The matrix representation of an SO(3) irrep for a given degree l, governing how type-l spherical tensors rotate. "The type- irrep is a set of matrices called Wigner-D matrices that rotate a type- spherical tensor by an element ."
Collections
Sign up for free to add this paper to one or more collections.