- The paper introduces SIGMA, an AI-powered training stack that overcomes reliability and stability challenges in distributed training on immature hardware.
- The methodology integrates the Lucia Training Platform and Framework to perform proactive node validation, automated fault remediation, and AI-driven diagnostics.
- It demonstrates the successful, stable training of a 200B-parameter MoE model on 2,048 accelerators with significant reductions in downtime and improved utilization.
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Introduction
The paper "SIGMA: An AI-Empowered Training Stack on Early-Life Hardware" (2512.13488) presents a rigorously engineered solution to the reliability, stability, and efficiency challenges inherent in scaling distributed training on early-life AI accelerators. The authors introduce the Sigma stack, which integrates the Lucia Training Platform (LTP) and Lucia Training Framework (LTF) to manage the failures and instability endemic to immature hardware deployments, while providing robust automation, AI-driven diagnostics, and scalable model training capabilities. Notably, Sigma demonstrates the first stable training of a 200B-parameter MoE model on 2,048 accelerators with sustained high utilization and efficiency.
Systemic Challenges in Early-Life Accelerators
Large-scale distributed training on early-life hardware is hindered by elevated disruption rates, undefined failure modes, numerical inconsistencies, and substantial efficiency fluctuations. The authors provide empirical disruption distributions from production-scale deployments, revealing high frequencies and unpredictable time-to-failure for large jobs:
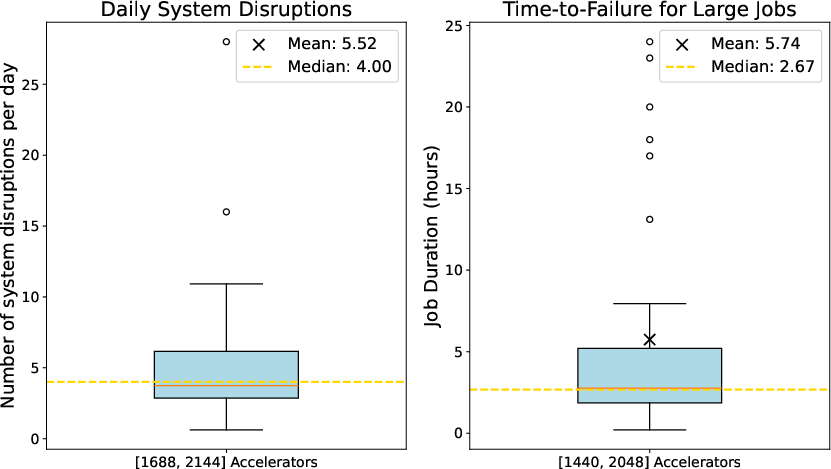
Figure 1: The distribution of daily system disruption counts and time-to-failure for large jobs on early-life AI accelerators highlights pervasive instability.
An additional dimension of complexity arises from the continuous emergence of new, undefined system disruptions, with error types varying significantly by platform and lacking actionable telemetry in many cases:
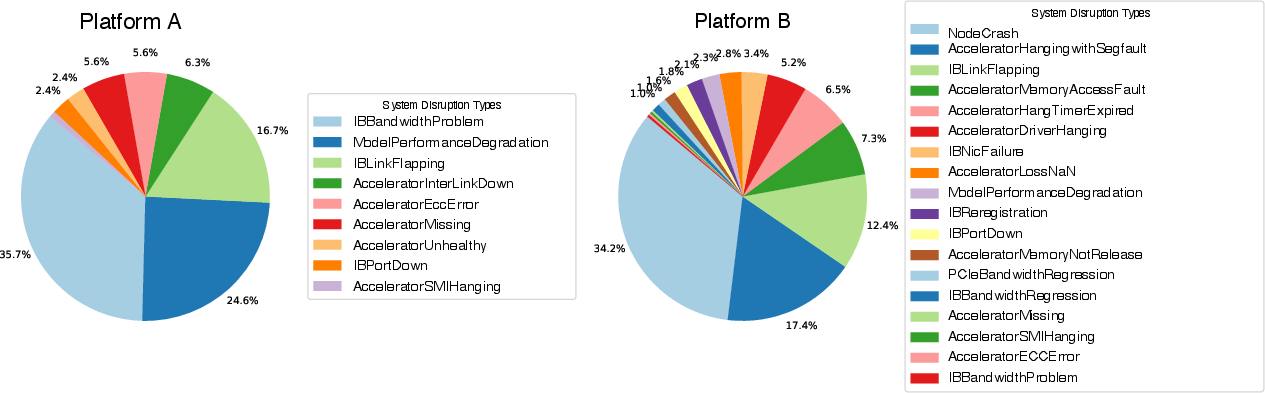
Figure 2: Disruption categories and failure type distributions diverge substantially across AI platforms, with early-life systems exhibiting a higher rate of undefined errors.
LTP offers an AI-powered management layer designed to maximize reliability and accelerator utilization. The core design mandates proactive node health validation, rapid automated detection, and job recovery cycles, plus full-lifecycle remediation of faulty nodes via direct API integration with cluster management and repair workflows.
During the observation window, automated validation and recovery decreased average job downtime from 2.5 hours to under 10 minutes. Automated node remediation accelerated node recycling by over an order of magnitude, with the system achieving up to 94.45% effective utilization and 98.3% cluster availability with measurable cost and time reductions.
Crucially, LTP integrates an LLM-driven, multi-layer fault management architecture: real-time telemetry aggregation, anomaly detection, and isolation (with LLMs as expert agents driving pattern search, hypothesis testing, and diagnosis), and automated rule generation for encoding newly discovered anomalies into the platform's detection and remediation pipeline.
Addressing Stability: Proactive Validation, Recipe Robustness, and MoE Diagnostics
Stability failures in training can be attributed to both hardware/software stack bugs and subtle errors in the training recipe, including initialization, loss design, and numerics. The framework highlights frequent cases where delayed detection of silent divergence leads to multi-day analysis and significant wasted training. The authors provide examples of loss trajectories demonstrating delayed instability detection and the subsequent impact of intervention:
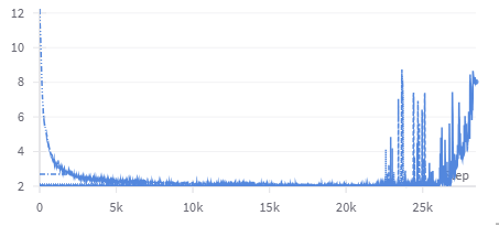
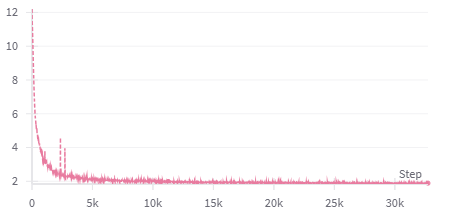
Figure 3: Per-step loss curves for a Sigma-V2 model before and after a model/recipe design correction. Spikes and divergence are visible prior to the fix.
Numerical validation is formalized as a pre-flight check, enforcing operator-wise cosine similarity and gradient checks with established baselines, identifying implementation and kernel divergences in critical modules.
The most interesting analytic result is the correlation of MoE parameter norm profiles with model stability. Across various open-sourced models, the average norm of MoE parameters exhibits a monotonically increasing pattern through the depth of the network:
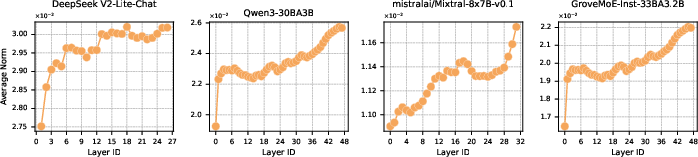
Figure 4: Layerwise MoE parameter average norm profiles for successful, open-sourced models showing a consistent increase with layer depth.
Conversely, early signs of collapse are detected when the profile develops a so-called “valley” (suppression of norms in intermediate layers), which advances as training continues and ultimately signals impending failure:
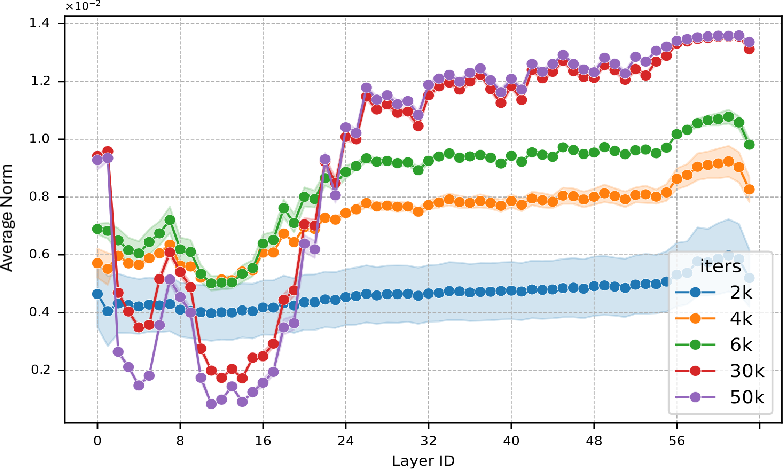
Figure 5: Evolution of MoE parameter average norm in a crashed model displays a characteristic “valley” prior to instability and divergence.
This “parameter norm shape” diagnostic enables collapse detection thousands of iterations prior to observed divergence, allowing for preemptive intervention, loss function redesign, and initialization policy changes.
Enhancing Efficiency: AI-Assisted Noise Analysis and Parallelism Tuning
End-to-end training throughput is heavily impacted by local disruptions and non-trivial communication-serialization stragglers. By leveraging LLMs to analyze straggler sources, two high-impact cases were diagnosed: lazy OS page-cache invalidation and Python GC scheduling, both of which were mitigated with targeted adjustments, resulting in an increase in effective throughput and a one order of magnitude reduction in throughput variance.
Parallel scaling is addressed systematically through small-scale combinatorial search and analysis across expert, pipeline, tensor, and microbatch parallelism dimensions. Hardware and software-specific bandwidth and communication topology constraints are empirically identified. Optimal settings (e.g., TP=1, EP=8, balanced pipeline) are determined, then validated in live, large-scale deployments.
Model Training Results and Empirical Evaluation
Sigma-MoE, a 200B-parameter MoE variant, was successfully trained for 75 days with only a single (promptly resolved) instability episode. The application of collapse pre-diagnostics and tuning approaches enabled the selection of Gaussian initialization, demonstrably smoother loss curves, and reduced gradient norm spikes:
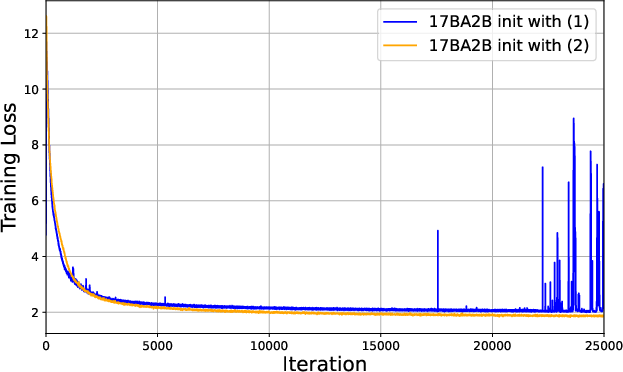
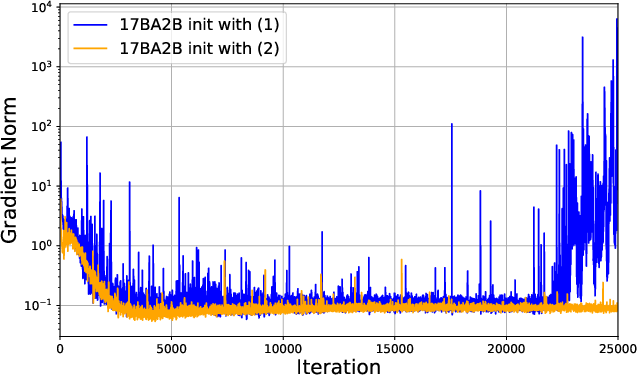
Figure 6: Training loss and gradient norms under different initialization policies. Gaussian initialization yields stable loss and reduced norm spikes.
Performance on challenging general and reasoning benchmarks places Sigma-MoE on par with established state-of-the-art dense and MoE LLMs (DeepSeek V2, Qwen2.5, LLaMA-3.1), with especially strong results in coding reasoning (57.9% pass@1 on HumanEval) and advanced mathematics (54.6% on MATH).
AI-Augmented Operations: Companion and LLM-Powered Fault Isolation
LTP’s Companion module introduces a multi-tier, chatbot-driven natural language interface for both users and administrators, automating common diagnostic, health tracking, and query operations with high accuracy (rising from 45.6% to 87.8%). Underlying LLM agents expedite anomaly analysis, rule generation, real-time fault localization, and provide a scalable path for continuously updating reliability logic in response to novel system failures.
Theoretical and Practical Implications
Sigma demonstrates that with appropriate architectural, analytic, and AI-driven interventions, large-scale distributed training on emerging accelerator platforms can reach reliability and performance characteristics near those of mature environments within months. The parameter-norm diagnostic for MoE pretraining establishes a new practical tool for the early detection of latent instability, and the integration of LLM-based telemetry analysis and feedback guards against the high cost of undefined system failures.
The modular, two-layer system design—partitioning infrastructure/automation and training/recipes—fosters maintainability, rapid deployment, and effective response to evolving hardware and software stacks. The system’s AI-based recovery and fault detection layers enable substantial operational efficiencies and cost reductions.
Future developments are likely to further integrate online learning for both failure signature acquisition and adaptive efficiency optimization, as well as broader application to even more heterogeneous or experimental hardware environments.
Conclusion
SIGMA constitutes a rigorously validated, open-source training stack that resolves the core challenges of reliability, stability, and efficiency in large-scale distributed training on early-life accelerators. The empirical results provide compelling evidence that direct platform and recipe-level interventions can support stable, highly efficient training of state-of-the-art models under realistic resource constraints, while LLM-driven diagnosis and automation expedite the path to operational readiness and scalability.

