- The paper introduces FuXi-γ, a novel framework that uses exponential-power temporal encoding to model user preference decay.
- It employs a diagonal-sparse positional mechanism to prune redundant attention, reducing computational overhead up to 74.56%.
- Empirical results show significant improvements in recommendation accuracy and speed, with up to 6.18x faster inference compared to baselines.
FuXi-γ: An Efficient Framework for Sequential Recommendation with Exponential-Power Temporal Encoding and Diagonal-Sparse Positional Mechanism
Introduction
Sequential recommendation aims to model user interests evolving over time by leveraging sequential interactions, with accuracy and computational efficiency paramount for real-world deployment. State-of-the-art Transformer-based sequential recommenders increasingly leverage generative, autoregressive architectures but often suffer from inefficiency due to irregular memory access in temporal encoding and the quadratic complexity of dense attention, especially on long sequences. The FuXi-γ framework proposes two principal innovations to address these challenges: (1) an exponential-power temporal encoder operationalized through a tunable exponential decay inspired by the Ebbinghaus forgetting curve, and (2) a diagonal-sparse positional mechanism that prunes superfluous attention via semi-structured block sparsity. Together, these innovations yield improved recommendation quality and enable substantial speedups during both training and inference.
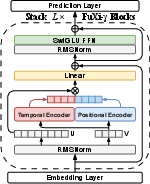
Figure 1: Overall architecture of FuXi-γ highlighting the dual-channel structure and its integration of exponential-power temporal encoding and diagonal-sparse positional pruning.
Methodology
Exponential-Power Temporal Encoder
Temporal dynamics are essential for reflecting user preference decay. Traditional bucket-based temporal encoders (e.g., T5-style log-binning) suffer from discontinuous, non-contiguous memory access and lead to significant computation bottlenecks. FuXi-γ replaces these with a fully matrix-based approach:
Let Ti,j be the absolute time difference between items i and j, the temporal attention is computed as:
Atsi,j=α⋅γ∣ti−tj∣β
where γ∈(0,1) is a decay hyperparameter controlling the rate of interest attenuation, and α,β are learnable parameters governing intensity and nonlinearity, respectively. This parameterization can smoothly interpolate between aggressively short-range and broad long-term memory, matching behavioral patterns across domains.
A significant hardware-aligned optimization is made via explicit float32 pre-conversion of the temporal distance matrix, thereby avoiding implicit type casts and improving synchronization with hardware accelerators. This results in an additional 12–15% runtime speedup and reduced memory footprint.
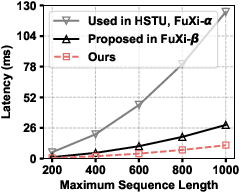
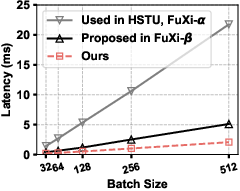
Figure 2: Efficiency comparison of temporal encoders under varying sequence lengths and batch sizes; exponential-power encoding achieves lowest latency and best hardware compatibility.
Diagonal-Sparse Positional Mechanism
While temporal and absolute positional encodings are present, relative positional encodings still provide complementary order information. Naive incorporation, however, introduces dense attention matrices of O(n2) complexity, with high redundancy in typical long-sequence recommendation. FuXi-γ addresses this by:
- Block-level division: Partition the positional attention map into s×s blocks.
- Importance scoring: Using the persymmetry (Toeplitz) property, only blocks along the leftmost column are scored, with absolute weight sums serving as proxies for block utility.
- Diagonal-sliding selection: The least important diagonals are pruned, and this mask is propagated across the whole attention map.
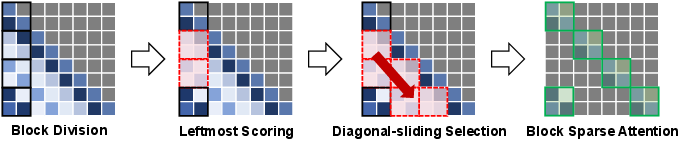
Figure 3: Illustration of diagonal-sparse positional mechanism for sequence length n=8, stride s=2, and pruning ratio τ=50%.
This diagonal-sparse pattern is both hardware-friendly and effective—pruning up to 74.56% of positional computation at minimal impact to accuracy.
Empirical Results
Recommendation Accuracy
Comprehensive evaluation on four datasets (MovieLens-1M, MovieLens-20M, KuaiRand, and a large-scale industrial music dataset) validates FuXi-γ's superiority:
- On the industrial dataset, FuXi-γ achieves 25.06% HR@10 and 42.86% NDCG@10 improvements over the strongest autoregressive baseline.
- Under 8-layer models, FuXi-γ surpasses competitive methods by a margin of 3.79% in HR@10 and 4.46% in NDCG@10, with enhanced results under deeper scaling.
Computational Efficiency
- FuXi-γ exhibits 4.74× (training) and 6.18× (inference) speedup over comparable autoregressive models on long sequences.
- Efficiency advantages scale with sequence length due to streamlined architectures and elimination of bucket-based memory fragmentation.
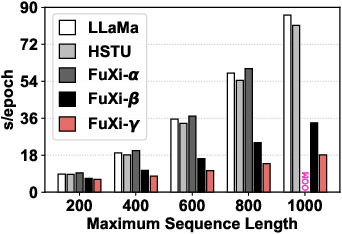
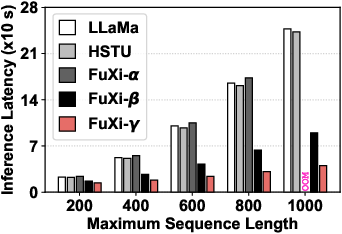
Figure 4: Overall efficiency performance comparison, showing FuXi-γ's consistent improvement as sequence length increases.
Temporal Encoder Analysis
The exponential-power temporal encoder yields:
- 11× speedup vs. bucket-based encoders at sequence length 1000.
- Markedly improved learning of both short-term and long-term dependencies, as shown by smoother, cognitively-consonant temporal decay (supported quantitatively in ablation).
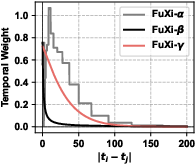
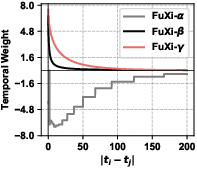
Figure 5: Visualization comparison of temporal encoders, revealing continuous and flexible decay in FuXi-γ over previous bucket and inverse-proportion approaches.
Ablation demonstrates the critical contribution of the temporal encoder, with the model's performance significantly degrading when this component is removed.
Robustness & Generalization
- FuXi-γ demonstrates resilience for cold-start users, fresh items, and long-tail distributions.
- Diagonal-sparse mechanism allows up to 60% block pruning with retention of >98.9% accuracy; FLOPs are proportionally reduced.
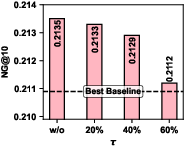
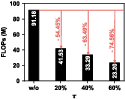
Figure 6: Impact of pruning ratio τ on ML-20M, showing minor accuracy loss and major FLOP reduction as sparsity increases.
Implications and Future Directions
FuXi-γ presents several substantial implications for the sequential recommendation landscape:
- Hardware-Aligned AI: By constraining computation to pure matrix operations and structured sparsity, the framework sets a new standard for hardware utilization and energy/performance efficiency.
- Modeling Flexibility: The tunable exponential-power kernel adapts to varying temporal patterns across domains, broadening the applicability of autoregressive recommenders.
- Scalable, Practical Deployment: The ability to retain state-of-the-art accuracy under aggressive pruning regimes enables cost-effective deployment in latency-critical settings.
Potential future research avenues include expanding the model to encompass multi-behavior and cross-domain histories, investigating further structured pruning in additional channels, and aligning the diagonal-sparse paradigm with emerging efficient attention mechanisms.
Conclusion
FuXi-γ substantially advances sequential recommendation by coupling cognitive-theory-inspired temporal encoding with a rigorously hardware-optimized, diagonal-sparse positional mechanism. Both theoretically and empirically, the framework achieves strong gains in recommendation effectiveness and efficiency. These architectural innovations lay a promising foundation for future work in deployable, scalable, and cognitively-plausible sequential recommender systems.
Reference: "FuXi-γ: Efficient Sequential Recommendation with Exponential-Power Temporal Encoder and Diagonal-Sparse Positional Mechanism" (2512.12740).