- The paper proposes a decentralized forward-backward algorithm that eliminates the need for cocoercivity while enabling locally tunable, heterogeneous step sizes.
- The method leverages an extragradient approach with local resolvent evaluations to secure faster convergence in distributed monotone inclusion problems.
- Numerical experiments show significant acceleration and reduced memory overhead in applications such as robust least squares and zero-sum games.
Decentralised Forward-Backward Algorithms with Network-Independent Heterogeneous Step Sizes
Problem Context and Motivation
The paper addresses distributed monotone inclusion problems of the form:
find z∈H such that 0∈i=1∑N(Ai+Bi)(z),
where H is a real Hilbert space, Ai are maximally monotone (set-valued), and Bi are monotone and Li-Lipschitz. Such problems appear in distributed optimization, min-max games, and aggregative Nash equilibria, with agents linked via a communication graph and each controlling separate Ai,Bi.
Standard distributed approaches (e.g., PG-EXTRA) impose restrictive assumptions: cocoercive Bi, homogeneous and graph-dependent step sizes, and tight bounds on step sizes requiring knowledge of global or spectral graph properties. The authors systematically identify three persistent drawbacks in the literature:
- Cocoercivity requirement: Imposes strict structure on Bi, limiting applicability—especially for saddle operators arising in min-max settings.
- Homogeneous step sizes: Agents must use a common step size dictated by the worst local curvature, thus unable to exploit local geometry.
- Graph-dependent step bounds: Upper bounds depend on graph topology, complicating decentralized implementation.
The paper’s objective is to construct a fully decentralised forward-backward type algorithm resolving all three drawbacks: no cocoercivity assumptions, heterogeneous, network-independent step sizes, and localizable updates and parameter selection.
Algorithm Design and Analysis
The proposed method is an extragradient-type decentralised forward-backward algorithm, generalizing the primal-dual and NIDS schemes using recent advances in operator splitting. The algorithm iteratively updates each agent’s local primal and dual variables, using only local evaluation of potentially set-valued resolvent steps and monotone Bi, along with communication with immediate neighbors.
Key update structure for the agent block-variables xk,yk,zk,vk:
- Agent i computes vik=2Bi(yik)−Bi(yik−1), leveraging the extragradient.
- New block zik+1 is computed via local aggregation and step-size-weighted corrections involving only local and neighbor variables.
- Each agent solves a local monotone inclusion for the next prox/forward step: xik+1=JαiAi(zik+1).
Step size αi for agent i is subject only to αi<1/(8Li), requiring no graph information. The consensus mechanism leverages a mixing matrix W, but the convergence proof and bound do not depend on W's spectrum.
The technical convergence analysis is built upon backward-forward-reflected-backward operator splitting, ensuring weak convergence of sequences to consensus and to a solution of the monotone inclusion under only the standard monotonicity assumptions. The step size condition is determined locally from Li, and a distributed protocol (over local neighborhoods) can compute the necessary auxiliary parameter β. This enables entirely local step size selection and update computation.
Crucially, the update point for the forward evaluation is chosen as yk, distinct from xk, differing from prior art and critical for the convergence analysis. The proof constructs an appropriate product-space monotone inclusion to which the splitting method applies.
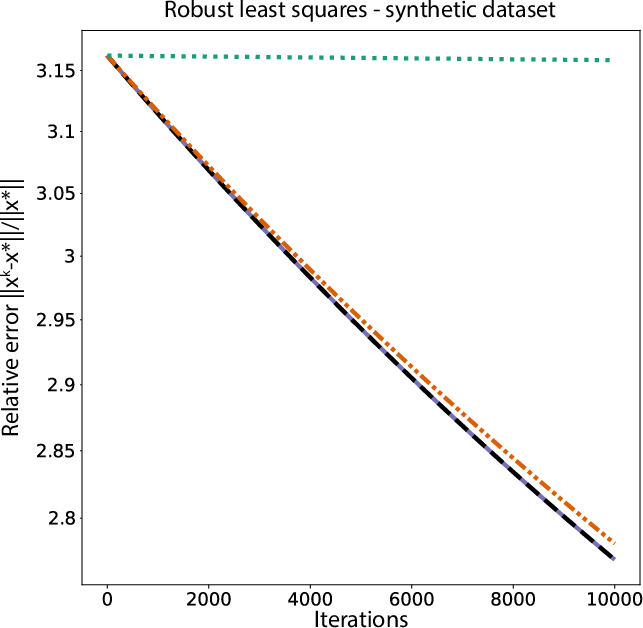
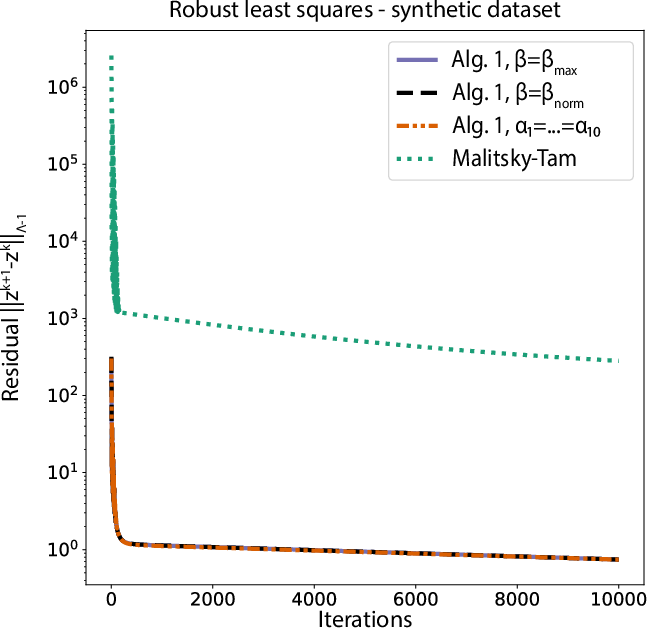
Figure 1: Relative error of the proposed algorithm and classical competitor versus iterations in robust least squares; note superior rate across graph-independent heterogeneous and homogeneous step size variants.
Numerical Results
The authors deploy their method on several representative distributed monotone inclusion problems:
- Robust least squares: Partitioned least squares across agents, robustified against vector-valued noise.
- Zero-sum matrix games: Decentralized computation of Nash equilibria in bilinear games.
Experimental setup incorporates various graph topologies (cycle, barbell, grid), with all agents starting from randomized (or zero) initializations. The key metrics are relative error (distance to consensus/optimal solution) and normalized residuals.
Strong numerical results:
- The algorithm achieves substantially faster convergence—often orders-of-magnitude in error reduction—than previous methods, confirmed across structures, datasets, and both homogeneous and heterogeneous step sizes.
- Allowing heterogeneous local step sizes yields further acceleration, especially when Li varies across agents (e.g., in bifurcated matrix games with high local curvature disparity).
- Crucially, removing graph dependency from the step size bound (relative to, e.g., [malitsky_tam_minmax]) allows for much more aggressive steps and significantly improved practical rates.
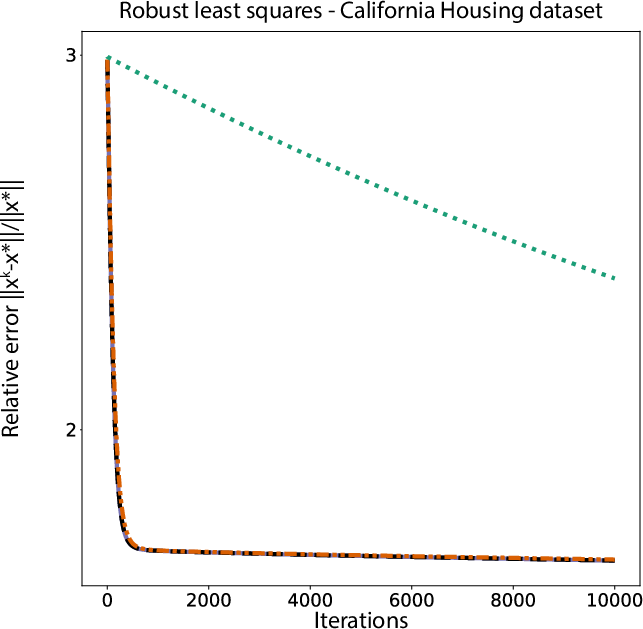
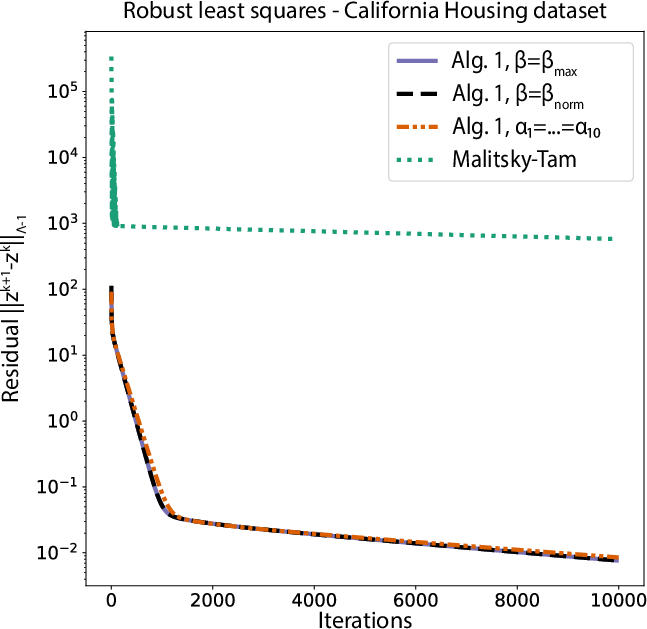
Figure 2: Normalized residuals versus iterations for robust least squares—proposed algorithm achieves lower stationary error levels consistently across step size regimes.
A further variant for aggregative games is derived, enabling block-memory reduction via variable structure exploiting the problem's summation form (substantially reducing per-agent memory for certain graph classes). This is validated in virtual power plant coordination with coupling constraints, confirming efficiency and scalability.
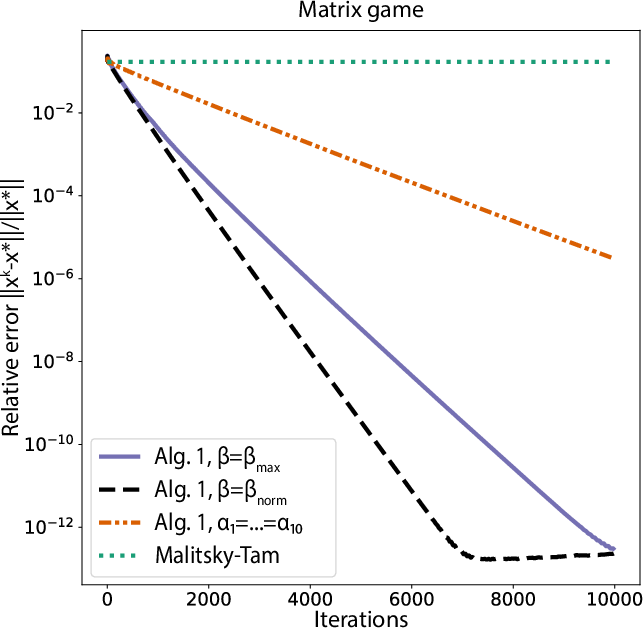
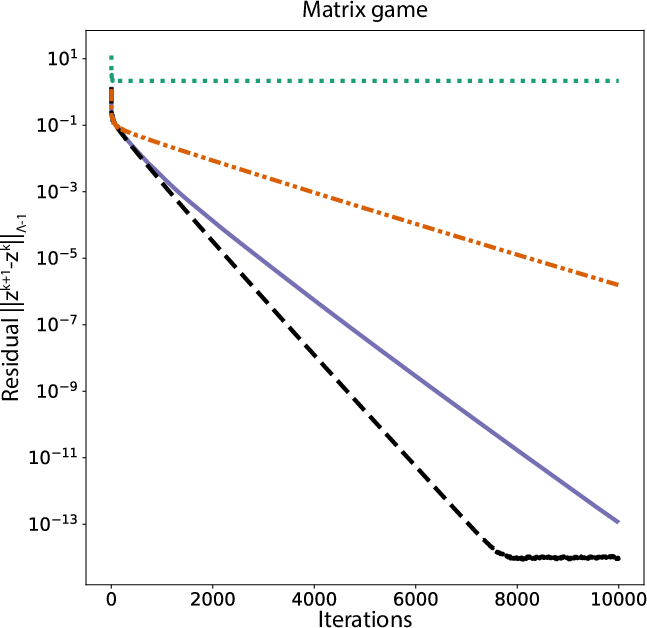
Figure 3: Relative errors versus iterations in zero-sum matrix games—heterogeneous step sizes (network independent) significantly outperform both homogeneous and classical approaches.
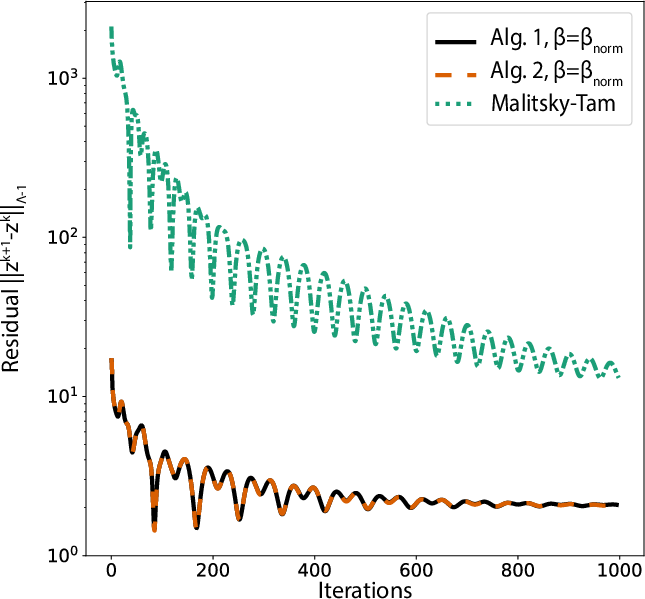
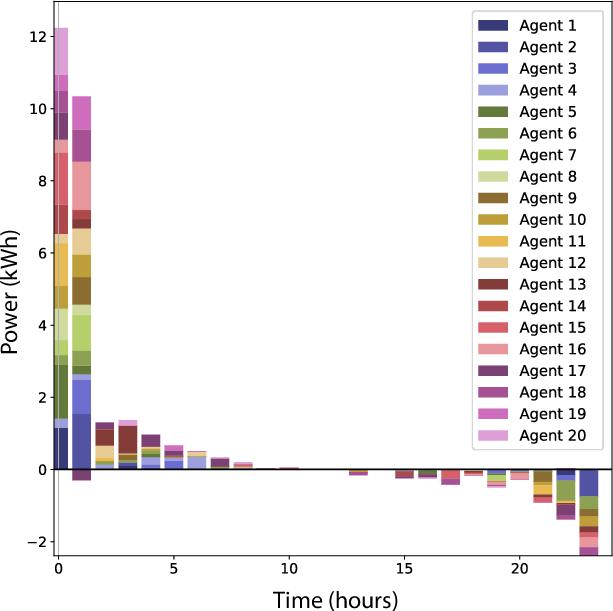
Figure 4: Normalised residuals versus iterations in zero-sum matrix games, reaffirming the method’s fast convergence and practical accuracy.
Theoretical and Practical Implications
The results have significant theoretical consequences:
- First coincident resolution: This is the first approach in the general monotone inclusion setting (beyond simple convex minimization or variation inequality) to enable all three desiderata: removal of cocoercivity, full heterogeneity, and network-independence.
- New operator splitting constructions: The convergence proof relies on advanced reflected/backward-forward operator theory, opening the door to variants and further generalizations (e.g., operator compositions, time-varying networks, or stochastic approximations).
- Implications for distributed game theory: Decentralised Nash computation for aggregative or min-max structures is rendered practical at scale—agents utilize only local data and neighbor information, yet can each leverage maximal local curvature.
On the practical side, the reduction in step size conservatism and memory overhead translates into direct gains in wall-clock and communication efficiency—critical for large-scale agent networks (e.g., federated learning, decentralized market clearing, or smart grids).
Prospective Extensions and Research Directions
Future work can focus on loosening the global Lipschitz assumption on Bi, analyzing performance for time-varying and directed communication graphs, or extending to asynchronous update models. Other natural questions include variance reduction for stochastic settings, integration with privacy-preserving protocols, and coordination under communication failures.
Conclusion
The paper delivers a comprehensive algorithmic and theoretical framework for distributed monotone inclusion solving, with locally tunable, network-independent heterogeneous agent step sizes. Backed by rigorous convergence guarantees and compelling empirical evidence in min-max and aggregative settings, the proposed approach represents a significant advance in decentralised convex and monotone optimization. The separation of algorithmic performance from network spectral properties marks an important milestone for fully local autonomous agent optimization.
References:
Tam, M.K., Timms, L., Zhang, L. "A decentralised forward-backward-type algorithm with network-independent heterogenous agent step sizes" (2512.12502)