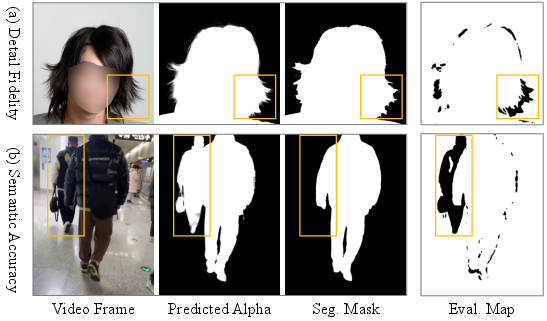
- The paper introduces a Matting Quality Evaluator (MQE) that dynamically guides both online training and offline data fusion.
- It demonstrates significant improvements in semantic accuracy, boundary fidelity, and temporal robustness across multiple benchmarks.
- The study scales video matting using a dual-branch annotation strategy to create the large-scale VMReal dataset with 28K clips and 2.4M frames.
MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator
Introduction
MatAnyone 2 introduces a unified framework for scaling video matting (VM) models through a learned Matting Quality Evaluator (MQE), addressing core limitations in prior approaches regarding the realism, scale, and annotation quality of available VM datasets. The combination of MQE-based online training guidance, automated dual-branch annotation for data curation, and a reference-frame training strategy collectively enables substantial improvements in semantic accuracy, boundary fidelity, and temporal robustness.
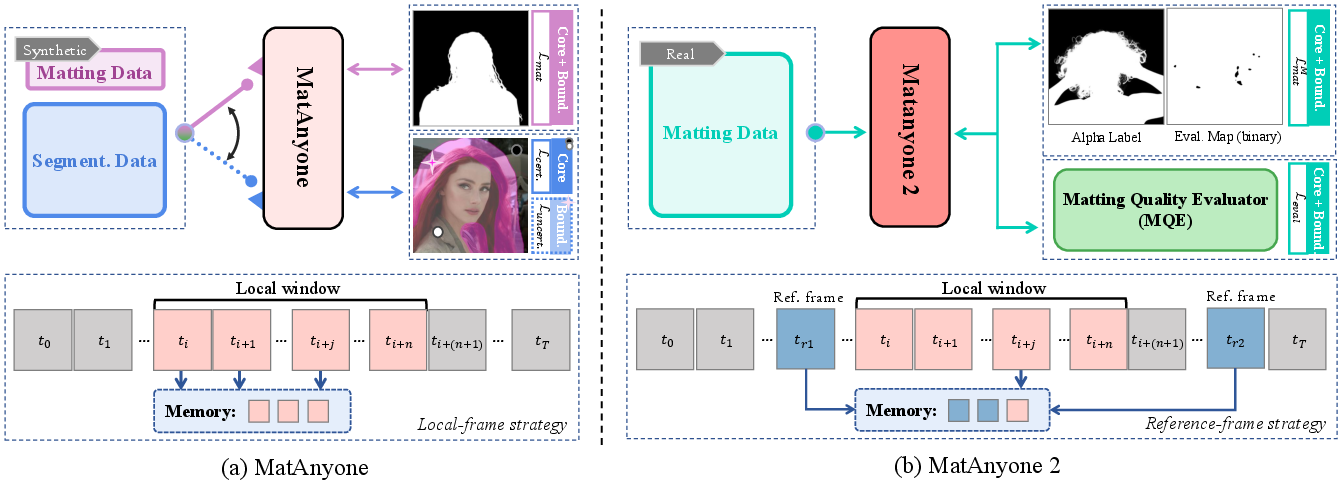
Figure 1: Comparison of MatAnyone and MatAnyone 2. The new model leverages MQE-based loss, online/offline quality assessment, and an expanded real-world dataset (VMReal) to remedy the boundary blurring, segmentation-like artifacts, and limited temporal range in MatAnyone.
Limitations of Prior Video Matting Paradigms
Previous VM methods relied primarily on synthetic data with limited diversity and imperfect compositing, or on segmentation-based supervision. Synthetic datasets, such as VM800, are orders of magnitude smaller and less scene-diverse than large-scale video object segmentation (VOS) datasets, resulting in a domain gap that hinders generalization to challenging, real-world scenarios.
Incorporating segmentation priors—either via pretraining or joint training—ameliorates core-region semantic instability but leaves boundary regions weakly supervised, especially when semantic and detail requirements diverge. This frequently results in “segmentation-like” mattes lacking fine structure, visible as indistinct hair strands, poor temporal consistency, or false positives in complex environments.
The Matting Quality Evaluator (MQE): Online and Offline Scaling
MatAnyone 2’s central contribution is the Matting Quality Evaluator, a discriminator for matting quality that produces a pixel-wise binary evaluation map distinguishing reliable from erroneous alpha matte regions. The MQE is constructed as a segmentation model using DINOv3 encoders for high-fidelity feature extraction, trained with errors detected using reference alpha mattes and standard metrics (MAD, Grad), and addressing class imbalance with focal and dice losses.
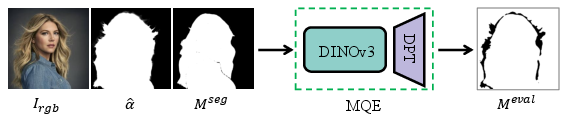
Figure 2: Given an input tuple of video frame Irgb, predicted matte, and segmentation mask, MQE outputs a pixel-wise map of reliable and erroneous regions.
MQE enables two scaling mechanisms:
VMReal: Large-Scale, High-Quality Real-World Matting Data
Leveraging the dual-branch annotation pipeline and MQE-based quality fusion, MatAnyone 2 constructs VMReal: a large-scale, annotated, real-world video matting dataset (28K clips, 2.4M frames), far surpassing previous resources in scale and diversity. This dataset covers a broad range of human appearance, lighting, motion, and challenging environmental conditions.
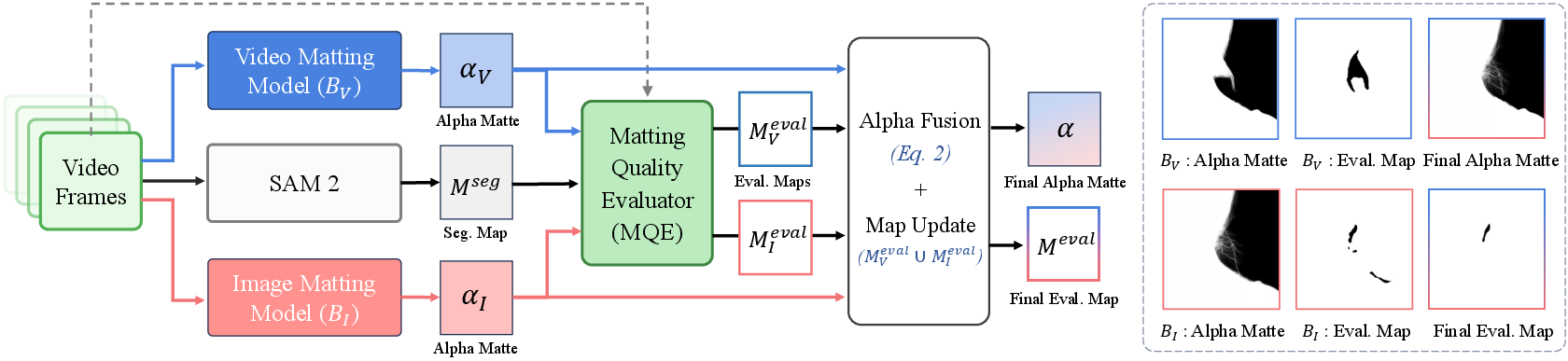
Figure 4: The dual-branch annotation pipeline merges semantic stability (video branch) with high-fidelity detail (image branch) using MQE-driven fusion, populating VMReal with both high-quality alpha mattes and reliability maps.

Figure 5: VMReal includes diverse, challenging cases (close-ups, motion, low-light), with alpha mattes and evaluation maps for robust, detailed model supervision.
The annotation process mitigates the limitations of each branch: video matting models provide temporal consistency but lack fine detail at boundaries, while image matting models offer sharp details but temporally unstable semantics. The fusion enabled by MQE allows scaling to millions of annotated frames with both qualities preserved.

Figure 6: The annotation fusion process replaces erroneous boundary regions from video matting with reliable details from the image branch, as flagged by MQE, achieving matting annotations that are both temporally coherent and detail-preserving.
Reference-Frame Strategy for Large Appearance Variation
To further address large intra-video appearance changes (e.g., new body parts or objects appearing in long sequences), MatAnyone 2 introduces a reference-frame memory mechanism. This expands the model's temporal context by sampling distant frames outside local mini-batch windows while employing random dropout augmentation to prevent memorization, supporting the learning of long-range correspondences without excessive GPU memory overhead.

Figure 7: The reference-frame strategy enables correct matting of previously unseen regions in long videos, where baseline models fail to adapt.

Figure 8: MatAnyone 2’s robustness to unseen body parts and handheld object appearance in extended clips exceeds baseline models.
Empirical Results
Comprehensive benchmarks on both synthetic (VideoMatte, YouTubeMatte) and real-world datasets (CRGNN) demonstrate superiority across all canonical matting metrics: mean absolute difference (MAD), mean squared error (MSE), gradient error (Grad), connectivity (Conn), and temporal stability (dtSSD). The approach consistently outperforms existing auxiliary-free, diffusion-based, and mask-guided models, including RVM, GVM, AdaM, FTP-VM, MaGGIe, and the original MatAnyone.
Key empirical findings:
- Reductions of 27.1% in Grad and 22.4% in Conn over the previous best mask-guided methods.
- Across real-world CRGNN benchmarks, lowest error rates in all metrics, indicating strong generalization.
- Qualitative results validate improved detail, robustness to lighting/hair motion, and semantic segmentation in challenging settings.

Figure 9: On unconstrained real-world video input, MatAnyone 2 consistently yields finer detail and more accurate semantics compared to leading alternative methods.

Figure 10: Additional qualitative evidence of improved detail, boundary quality, and semantic stability, especially under adverse or complex conditions.
Theoretical and Practical Implications
Theoretical Impact:
MQE reframes matting supervision as a dynamic, adaptive quality-assessment problem—enabling scalable training, reliable data fusion, and annotation without manual ground-truth mattes. This paradigm may generalize to other ill-posed, boundary-sensitive pixel prediction tasks, suggesting future avenues for learned evaluators to replace or augment hand-crafted loss functions and dataset curation strategies.
Practical Applications:
The resulting unified approach provides production-quality matting for visual effects, real-time video editing, and AR/VR with minimal manual annotation effort. The large-scale VMReal resource directly benefits commercial and open-source development of VM and segmentation models.
Future Directions
- Iterative, closed-loop refinement of the annotation/data pipeline: enhanced matting models can be leveraged to progressively improve dataset quality, creating a positive feedback loop between data and model.
- Extending the MQE approach to other video layer/separation problems (e.g., optical flow, video segmentation) where ground-truth label scarcity is an issue.
- Exploration of transformer/diffusion-based matting models using the combination of VMReal and MQE-driven supervision to push boundary detail and temporal stability even further.
Conclusion
MatAnyone 2 establishes a new paradigm for large-scale, high-fidelity video matting by unifying dynamic, learned quality evaluation, automated hybrid annotation, and long-range data-efficient training. The approach addresses key failures of prior work (domain gap, poor boundaries, weak supervision) and provides both theoretical and practical foundation for scaling up video matting and related dense prediction tasks. The creation of the VMReal dataset is likely to be a catalyst for further advances in this area.