Published 12 Dec 2025 in stat.ME and stat.ML | (2512.11761v1)
Abstract: Data integration is essential across diverse domains, from historical records to biomedical research, facilitating joint statistical inference. A crucial initial step in this process involves merging multiple data sources based on matching individual records, often in the absence of unique identifiers. When the datasets are networks, this problem is typically addressed through graph matching methodologies. For such cases, auxiliary features or covariates associated with nodes or edges can be instrumental in achieving improved accuracy. However, most existing graph matching techniques do not incorporate this information, limiting their performance against non-identifiable and erroneous matches. To overcome these limitations, we propose two novel covariate-assisted seeded graph matching methods, where a partial alignment for a set of nodes, called seeds, is known. The first one solves a quadratic assignment problem (QAP) over the whole graph, while the second one only leverages the local neighborhood structure of seed nodes for computational scalability. Both methods are grounded in a conditional modeling framework, where elements of one graph's adjacency matrix are modeled using a generalized linear model (GLM), given the other graph and the available covariates. We establish theoretical guarantees for model estimation error and exact recovery of the solution of the QAP. The effectiveness of our methods is demonstrated through numerical experiments and in an application to matching the statistics academic genealogy and the collaboration networks. By leveraging additional covariates, we achieve improved alignment accuracy. Our work highlights the power of integrating covariate information in the classical graph matching setup, offering a practical and improved framework for combining network data with wide-ranging applications.
The paper introduces a covariate-enhanced graph matching framework that leverages auxiliary node and edge information to overcome non-identifiability in traditional methods.
It develops and analyzes two algorithms, CovQAP and CovNeigh, offering theoretical guarantees on error decay and exact recovery under proper seed conditions.
Empirical evaluations on simulated and real-world academic networks validate significant improvements in matching accuracy over classical approaches.
Covariate-Assisted Graph Matching: A Technical Summary
Problem Statement and Motivation
The paper "Covariate-assisted graph matching" (2512.11761) addresses the fundamental problem of aligning two graphs when auxiliary node and edge covariate information is available, and partial vertex correspondence is known via seeds. Classical graph matching relies solely on adjacency structure, which is limiting when non-identifiability arises due to isomorphic substructures or lack of distinguishing connectivity. The integration of covariates—attributes or features on nodes and/or edges—offers a promising channel to significantly improve alignment accuracy, especially in heterogeneous and error-prone contexts typical in real-world data integration.
The motivating application is the statistical alignment of academic genealogy and collaboration networks in the field of statistics, both comprising thousands of nodes with diverse edge semantics (academic lineage versus coauthorship). The incorporation of covariates such as institution, country, and graduation year, in addition to network structure, transforms the alignment task into a more robust data fusion pipeline, enabling joint downstream statistical analyses.
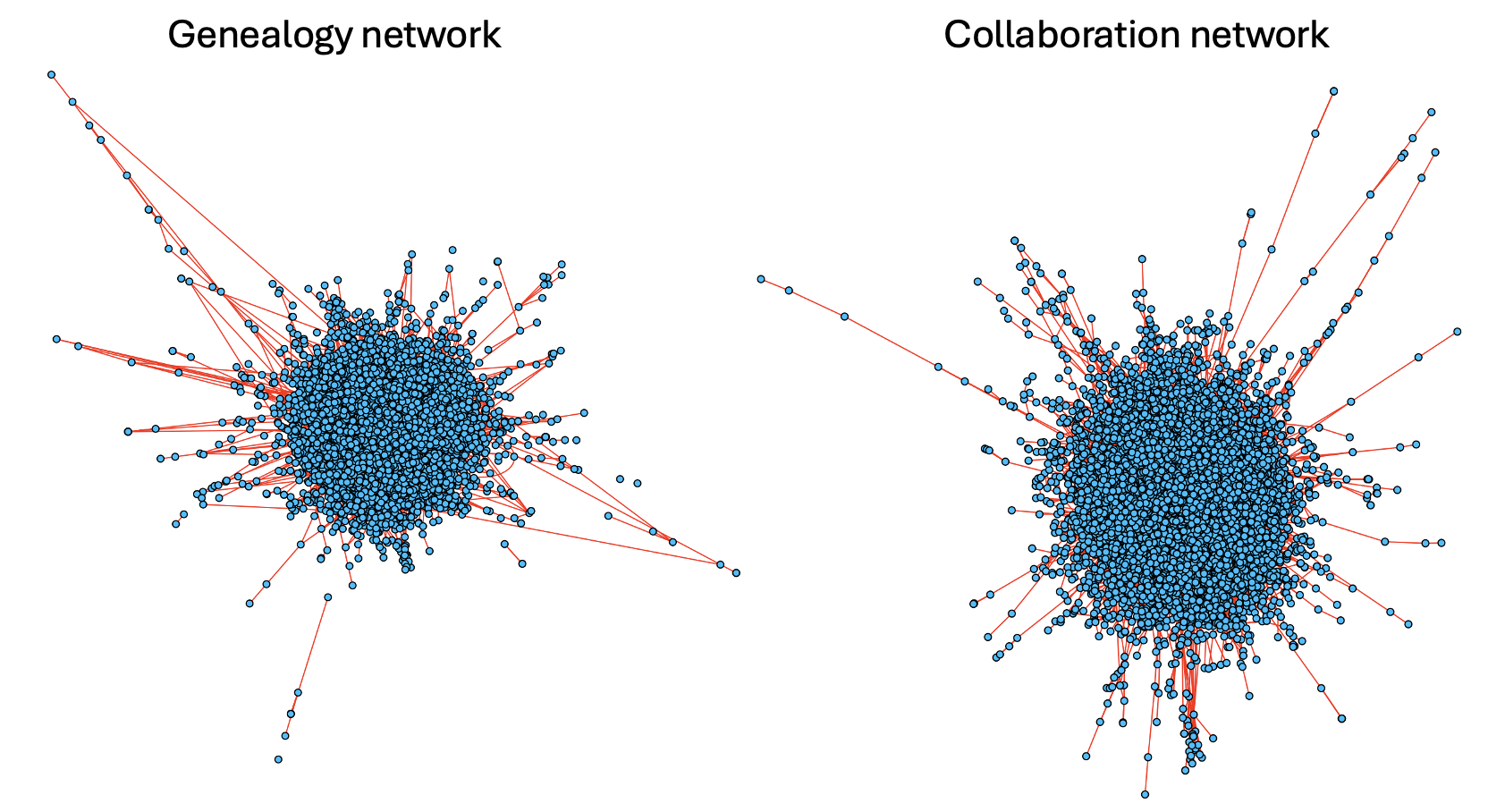
Figure 1: Visualization of the genealogy network (left, advisor-advisee) and the collaboration network (right, coauthorship) for 8,627 statisticians; highlighting the cross-network alignment challenge.
Methodological Contributions
The authors formalize a conditional framework wherein the adjacency matrix of the "target" graph is modeled via a generalized linear model (GLM), conditional on the "source" graph and the associated covariates. The setting assumes two n-vertex undirected graphs, A and B, with A accompanied by covariates Y (edge) and Z (node). The observed B is subject to an unknown permutation Q∗ on the non-seed nodes, B=Q∗BQ∗T.
where g is an appropriate link function and h(⋅,⋅) encodes pairwise node-covariate transformations (e.g., indicator for co-institution, absolute year difference).
The partial alignment via seeds (S) enables fitting θ∗ through likelihood maximization on the corresponding submatrices, yielding an estimator P for P on the full vertex set. This yields two operational algorithms:
CovQAP: Solves a seeded Quadratic Assignment Problem (QAP) using P as a surrogate for the expected adjacency of B,
Q=argQ∈Πn:QS,S=Ismin∥P−QBQT∥F2
providing global alignment at the cost of significant computational resources.
CovNeigh: Exploits only the local neighborhoods of seeds, converting the problem into a seeded linear assignment (solved in polynomial time), matching the unseeded nodes by minimizing distances between their covariate-based connection signatures to seeds.
Theoretical Results
Rigorous statistical guarantees are provided under the model:
Estimation Error: Under regularity and identifiability conditions (bounded Hessian eigenvalues, covariate norms, strong convexity of GLM), the maximum entry-wise error maxi,j∣Pij−Pij∣ decays as OP(logs/(Ls1/2s)) (Theorem 1), where s=∣S∣.
Exact Recovery: Under natural signal strength assumptions (sufficient edge density, distinguishability in P, no automorphisms aside from the identity, etc.) and an information-theoretic lower bound on seeds, the solution Q recovers the true permutation Q∗ with high probability (Theorem 2). Notably, the required s scales as s≍n in Erdős–Rényi regimes of practical interest.
Numerical and Empirical Evaluation
Simulations
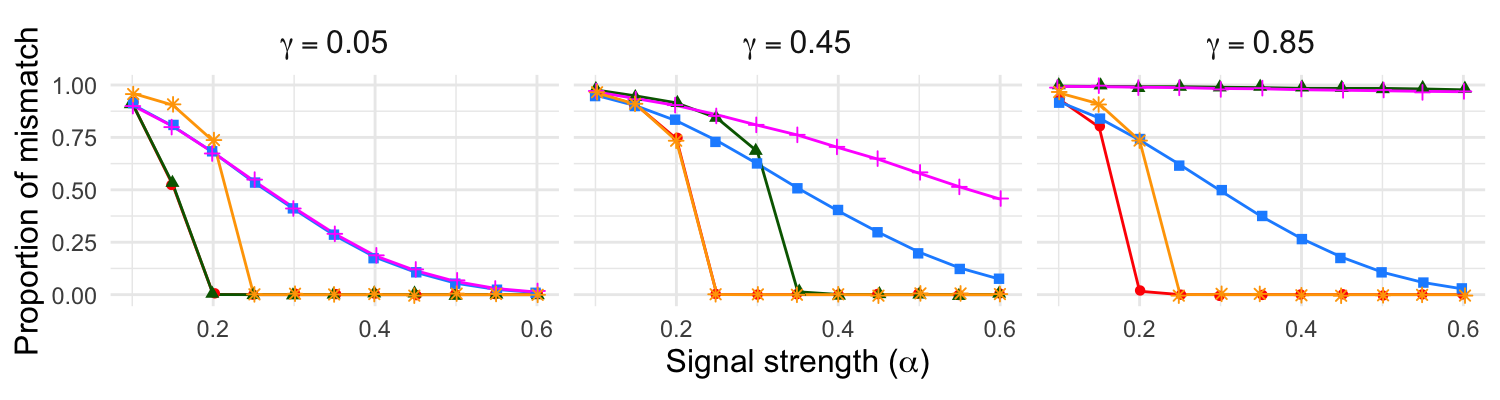
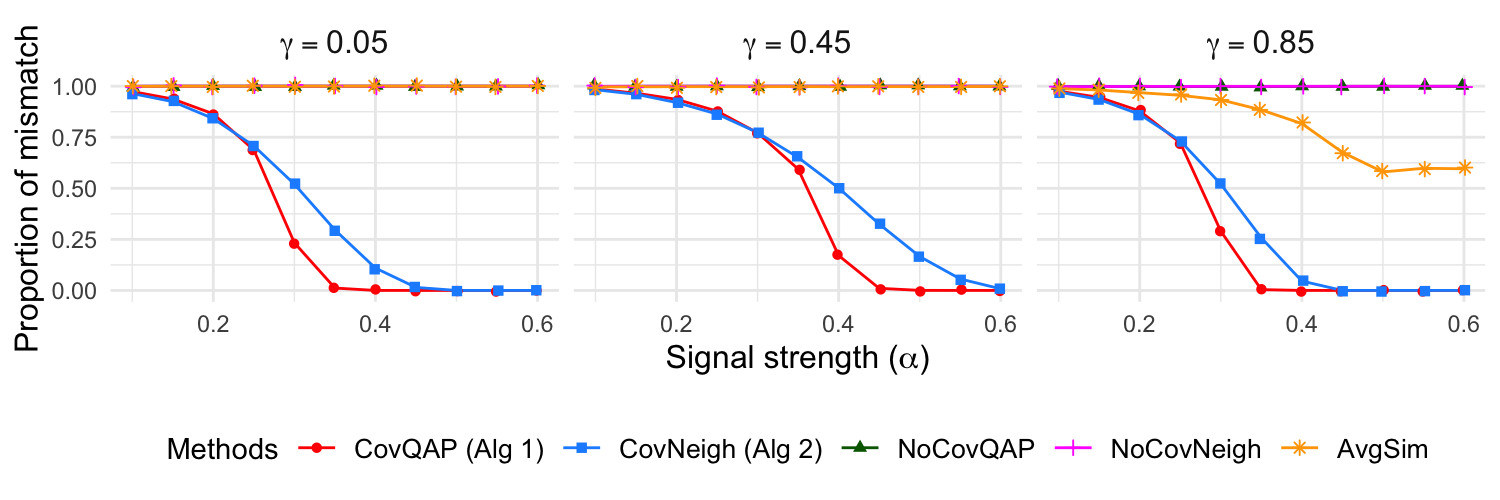
The authors conduct extensive experiments under planted permutation Erdős–Rényi models with auxiliary binary covariates, varying signal-to-noise and covariate influence parameters. Performance is evaluated as the proportion of mis-matched vertices, compared to classical methods (seeded QAP and LAP without covariates, and naive attribute averaging).
Figure 2: Proportion of mismatches versus signal strength α and covariate effect γ for 100 seeds; CovQAP and CovNeigh outperform baselines as covariates become informative.
Key findings:
When covariate effect is concordant with network structure, naive averaging performs competitively, but CovQAP and CovNeigh consistently achieve lower error rates as γ increases.
When network and covariate signals are in opposition, classical methods degenerate to random matching, while covariate-assisted algorithms retain accuracy, validating the theoretical claims under structural heterogeneity.
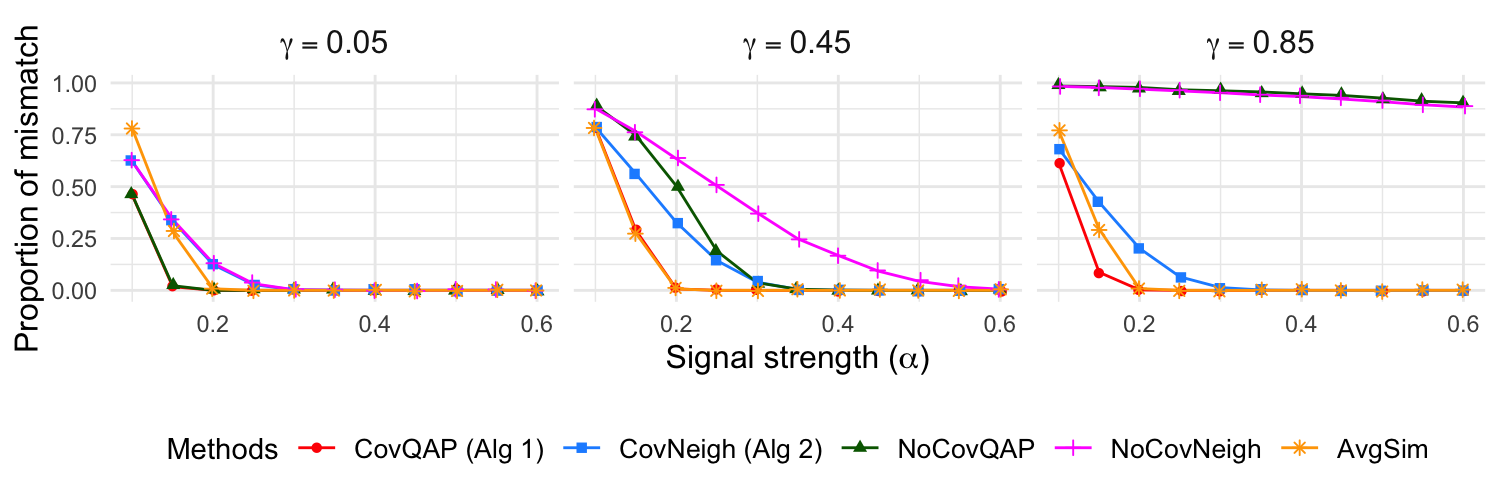
Figure 3: Proportion of mismatches under increased seed count (250/500); improved matching aligns with theoretical scaling of estimation error with s.
Increasing seed numbers directly improves matching accuracy, particularly for the local algorithm.
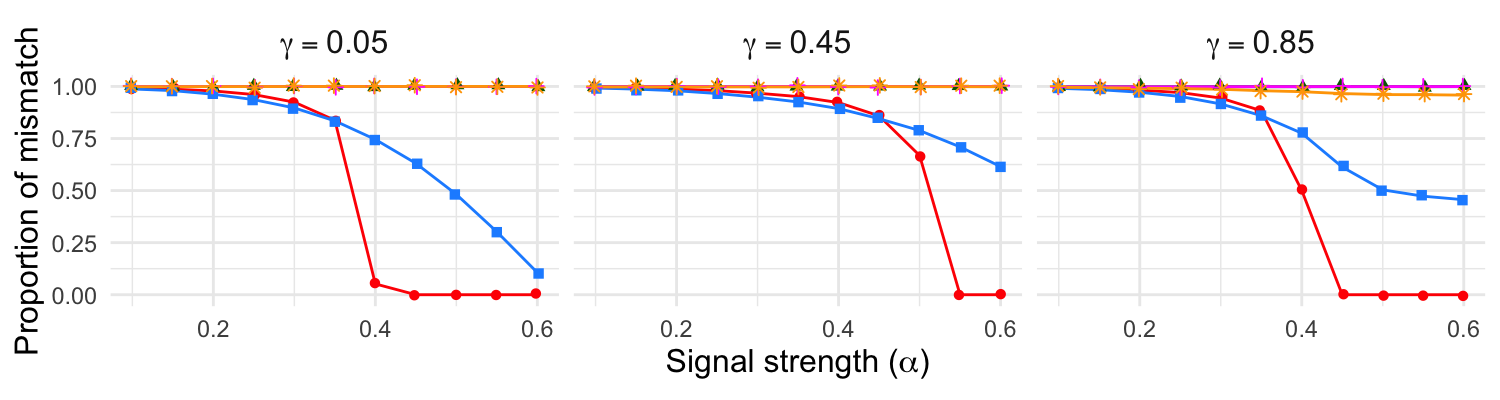
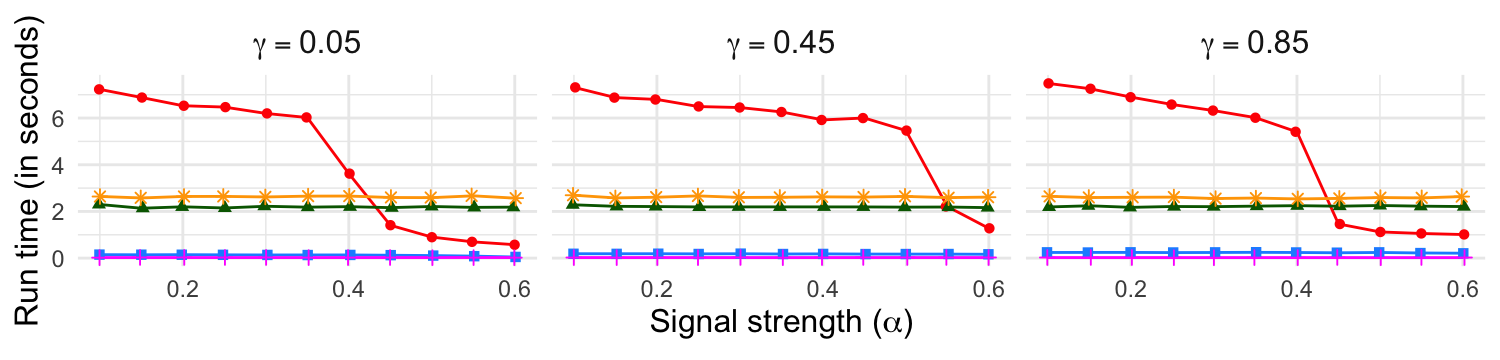
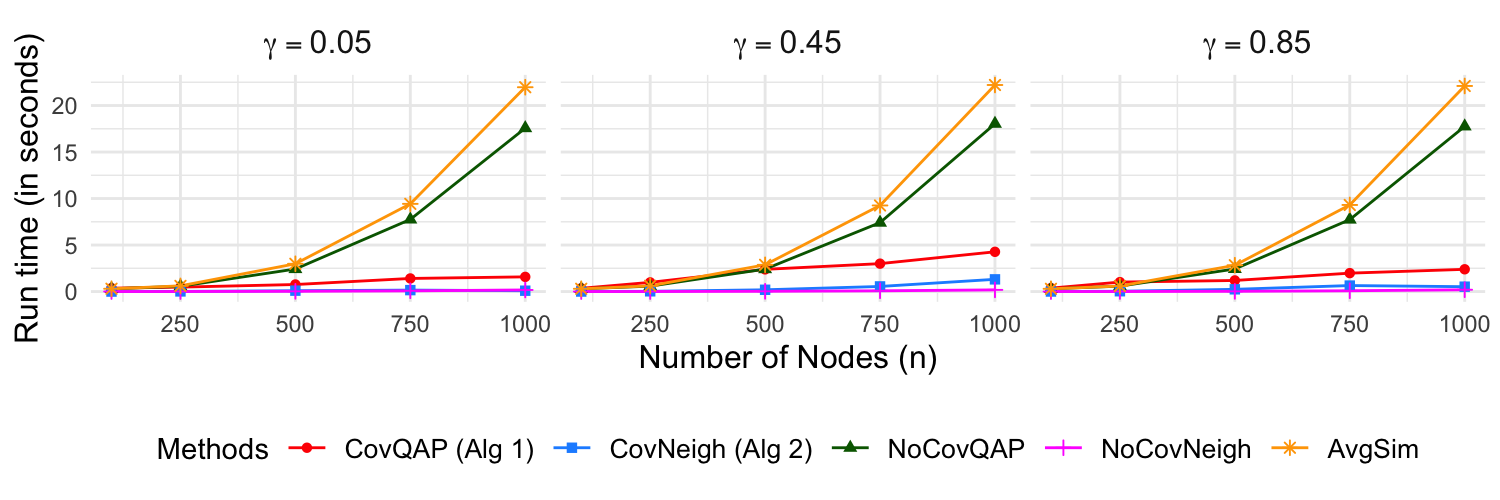
Figure 4: Computational time (seconds) versus signal strength and graph size; CovNeigh offers substantial computational gains over CovQAP.
Neighborhood-based methods are much more scalable, with CovNeigh orders of magnitude faster than seeded QAP variants, albeit with mild degradation in accuracy.
Real Data: Academic Genealogy and Collaboration Networks
The methods are validated on the joint alignment of 8,627-node genealogy and collaboration networks (Figure 1), with covariates capturing institutional, geographic, academic kinship, and temporal features.
Inclusion of covariates yields statistically significant improvements in matching rates: CovQAP and CovNeigh outperform their no-covariate analogues by 2.4–5.2% on average.
Regression coefficients align with sociological expectations: advisor-student pairs, shared institutions/countries, and small year gaps all positively predict collaboration.
The pipeline flexibly accommodates alternative machine learning prediction methods (e.g., random forests) for estimating P, with nonparametric models yielding competitive performance.
Implications and Extensions
The framework demonstrates that integrating attribute information in graph matching is not only practically advantageous but also theoretically tractable under realistic regimes, provided a minimal number of seeds and model flexibility. The conditional modeling approach generalizes both classical QAP-based matching and recent seeded percolation/attribute-based heuristics.
On the practical side, the results enable robust network integration in data fusion applications, enhancing downstream statistical power in fields as diverse as computational social science, bibliometrics, and biology. On the theoretical side, the methods present a bridge between parametric network regression, combinatorial optimization, and high-dimensional inference.
Limitations include the requirement of seed knowledge (which may be relaxed in more ambitious joint estimation frameworks at higher computational cost), as well as the lack of explicit modeling of node-level latent structure (e.g., blockmodels, latent space embeddings), which may further improve accuracy when available.
The methodology generalizes naturally to graphs of unequal size via padding or partial assignment formulations, and to more sophisticated learning procedures for the GLM step (e.g., regularization, deep learning). Future development of computationally efficient approximate-QAP relaxations that retain recovery guarantees under this augmented statistical setting is a promising avenue.
Conclusion
This paper establishes a unified and tractable framework for seeded graph matching augmented by covariate information. Through both theoretical analysis and empirical validation, it demonstrates that covariate integration—coupled with seeds—yields improved match accuracy, robust to signal heterogeneity, while flexible enough to incorporate advanced prediction methods. The results encourage the explicit use of auxiliary attributes in network alignment tasks, with broad ramifications for real-world data integration.