- The paper presents a novel depth-aware augmentation method that enhances face detection by integrating semantic and 3D geometric reasoning.
- It employs multimodal background retrieval, occlusion-aware segmentation with SAM3, and depth-guided sliding-window placement for realistic composites.
- Results show up to a 2.6 mAP improvement on the WIDER Face dataset, outperforming standard augmentation techniques like Cutout and CutMix.
Depth-Copy-Paste: Multimodal and Depth-Aware Compositing for Robust Face Detection
Introduction and Motivation
The paper presents Depth-Copy-Paste (DCP), a data augmentation framework addressing the constraints of traditional copy-paste techniques for face detection. Copy-paste augmentation has been widely adopted for enriching datasets, but standard pipelines frequently suffer from semantic mismatch, occlusion artifacts, and geometric inconsistency, especially in person-centric scenes where context and depth ordering are fundamental for realism. DCP integrates multimodal background retrieval and depth-aware compositing to generate physically consistent and diverse training samples, enhancing the robustness of downstream face detectors.
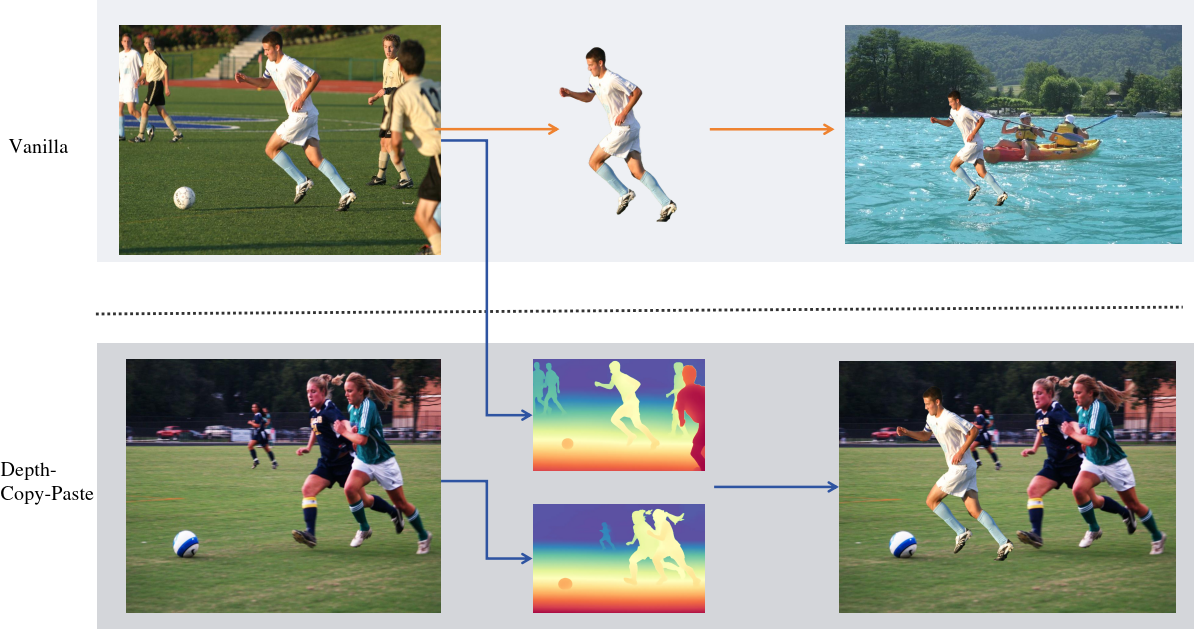
Figure 1: Depth-Copy-Paste produces visually realistic and geometrically plausible composites compared to vanilla copy-paste, which yields unrealistic artifacts due to geometric inconsistency.
Methodology
The DCP pipeline consists of three principal modules: multimodal background retrieval, occlusion-aware foreground extraction, and depth-guided placement. The overall approach ensures both semantic coherence and geometric plausibility when synthesizing training data.
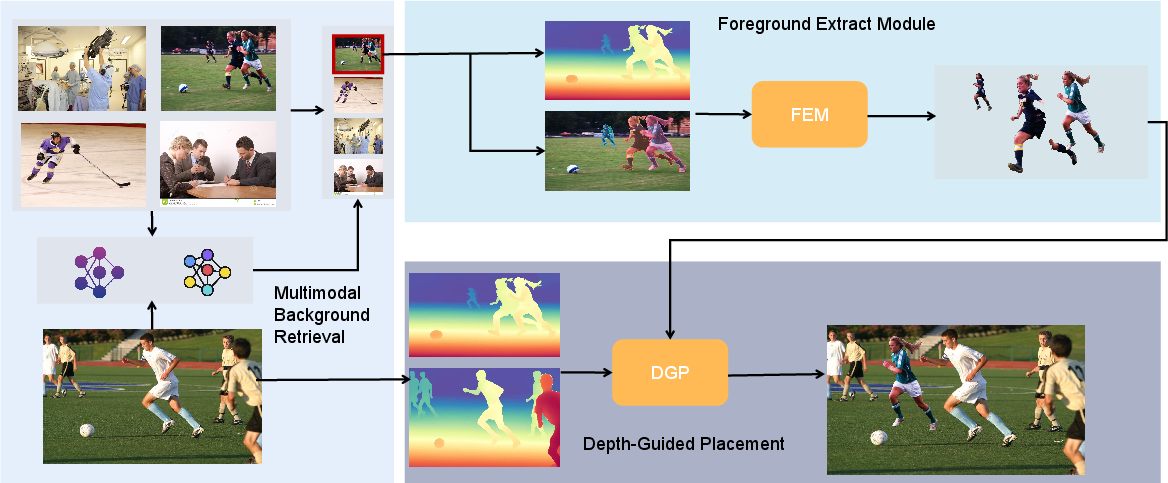
Figure 2: The pipeline includes BLIP/CLIP-based multimodal background retrieval, SAM3 and Depth-Anything for foreground extraction, and depth-guided sliding-window compositing for geometric consistency.
Multimodal Background Retrieval
Given a foreground instance, BLIP generates a descriptive caption encapsulating high-level scene and facial attributes. CLIP then encodes both the textual and visual information of the foreground and potential backgrounds. A fused similarity metric between visual and textual embeddings retrieves semantically and contextually aligned background candidates. This mechanism mitigates domain gaps and avoids implausible composites prevalent in naive random sampling.
DCP addresses the common issue of copying occluded or non-visible regions by integrating SAM3 segmentation for mask generation with Depth-Anything for pixel-wise depth estimation. Local depth consistency analysis isolates the non-occluded regions, and masks are refined by intersecting segmentation and depth-based visibility. This dual-filtering process minimizes the presence of artifacts such as missing facial regions or floating occluders.
Depth-Guided Placement
To ensure scale and depth continuity, normalized depth maps of both foreground and selected background are computed. A sliding-window search is performed across candidate background regions, leveraging mean and variance alignment of depth distributions, as well as local smoothness constraints to avoid cluttered boundaries. The final placement maximizes a unified placement score composed of depth-level deviation, variance, and smoothness penalties, producing composites that are both scale-aligned and seamlessly integrated.
Experimental Results
Quantitative Evaluation
The method is evaluated on WIDER Face, covering a wide range of occlusion and environmental complexity. The ablation studies and comparative experiments consistently demonstrate that DCP yields significant performance gains over baselines and alternative augmentation strategies.
- Across seven different face detection architectures, including RetinaFace and DSFD, incorporating 30-50% DCP-generated samples improves mAP by up to 2.6 points compared to the real-data-only baseline.
- DCP outperforms Cutout, CutMix, and random copy-paste methods by up to 1.3 mAP on the most challenging "Hard" subset, highlighting the advantage of multimodal and geometric reasoning.
- The analysis reveals an optimal ratio of synthetic augmentation: excessive synthetic content (>70%) slightly reduces accuracy, indicating a saturation threshold and the ongoing importance of real-world diversity.
Component Analysis
- Multimodal background retrieval fusing BLIP and CLIP improves mAP by +0.024 and +0.019 on Medium and Hard subsets over single-modality retrieval, establishing the necessity of joint semantic and appearance alignment.
- Combining SAM3 segmentation with depth-based visibility masks yields 0.788 mAP on Hard, outperforming all foreground extraction baselines.
Implications and Future Directions
The proposed DCP compositing approach is model-agnostic and easily extensible to other object classes and detection paradigms. Its integration of semantic and depth-based constraints provides a generic framework for robust synthetic data generation, suitable for applications requiring physical realism—such as autonomous driving, crowd analysis, and advanced instance segmentation. Potential extensions include:
- Adapting DCP for temporal consistency, enabling video-level augmentation for tracking and action recognition tasks.
- Integration with generative architectures (e.g., diffusion models) to further alleviate boundary artifacts and enhance composite realism.
- Data-driven learning of multimodal fusion weights and adaptive placement scoring, moving beyond manually-tuned hyperparameters.
Conclusion
Depth-Copy-Paste establishes a robust augmentation methodology that effectively mitigates the weaknesses of traditional copy-paste augmentation. By leveraging multimodal retrieval and depth-aware operations, DCP produces visually and geometrically plausible composites that significantly improve the generalization of face detection models, particularly in challenging occluded and complex environments. The presented results and analyses substantiate the claim that harmonizing semantic understanding and 3D reasoning is essential for high-quality synthetic data generation in computer vision.