- The paper proposes a selective imputation method using data-driven informativeness scores to determine safe imputations for missing multi-view data.
- It leverages a variational autoencoder with a mixture-of-Gaussians prior and product-of-experts aggregation for robust latent representation learning.
- Empirical results show significant improvements in clustering accuracy and robustness under high missing rates compared to traditional imputation methods.
Motivation and Context
Incomplete multi-view clustering (IMC) remains a challenging unsupervised setting, particularly given the prevalence of missing and unbalanced views in real-world datasets. The two dominant solution paradigms—imputation-based and imputation-free—each face significant limitations. Indiscriminate imputation introduces noise and bias when support is insufficient, while imputation-free techniques lose efficacy as missingness rises due to lack of cross-view complementarity. The paper "Simple Yet Effective Selective Imputation for Incomplete Multi-view Clustering" (2512.10327) directly addresses this central trade-off by proposing an informativeness-based selective imputation strategy, ISMVC, which only imputes missing positions with strong evidential support.
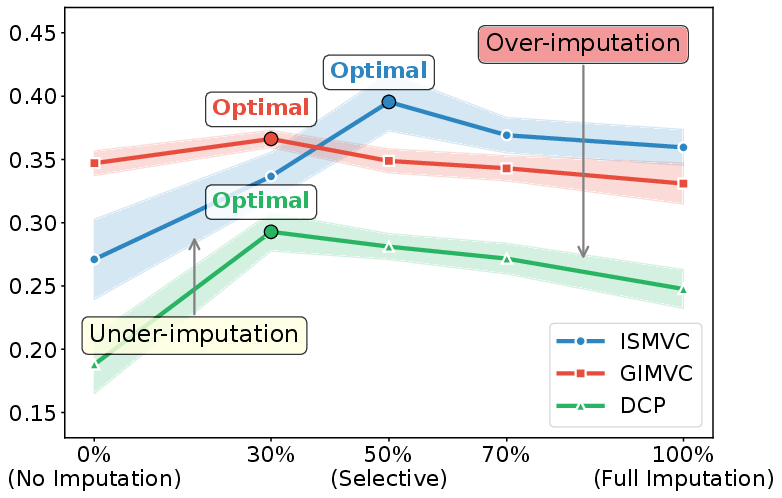
Figure 1: Clustering accuracy peaks when partially imputing well-supported positions, while full or no imputation leads to suboptimal results.
The empirical motivation is clear: optimal clustering accuracy is achieved not by imputing all missing positions, nor by completely skipping imputation, but by selectively imputing only those missing entries with sufficient information support. This is validated in diverse scenarios where the selection ratio is directly correlated with clustering accuracy, especially under high missing rates.
Methodological Contributions
ISMVC introduces two principal advances: position-level informativeness assessment and distribution-level uncertainty modeling within a variational inference framework.
Rather than designing the selection mechanism around training dynamics or model feedback, ISMVC defines an explicit, data-driven informativeness metric for each missing position that fuses intra-view sample similarity and inter-view consistency.
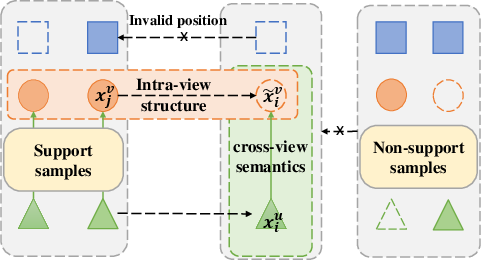
Figure 2: When deciding whether to impute x~iv, ISMVC evaluates both intra-view and cross-view support, ensuring that only positions with sufficient evidence are imputed.
Support set construction strictly includes only those samples that share the missing view and at least one co-observed view with the target. The informativeness score incorporates:
- Intra-view similarity via normalized distance in representation space.
- Cross-view consistency estimated using canonical correlation analysis (CCA) on latent embeddings.
- Support set sample weighting based on neighborhood structure and view correlation.
The final information score for a missing position is a weighted sum of similarity and view-correlation values, with imputation performed only if this score surpasses a data-dependent threshold.
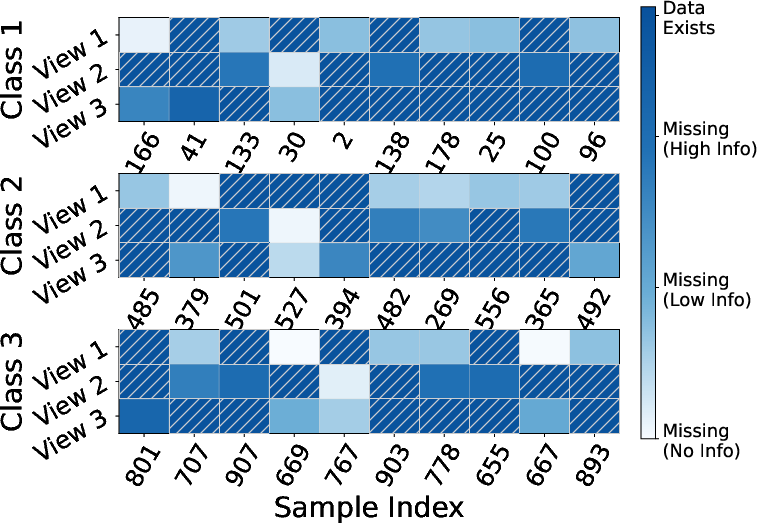
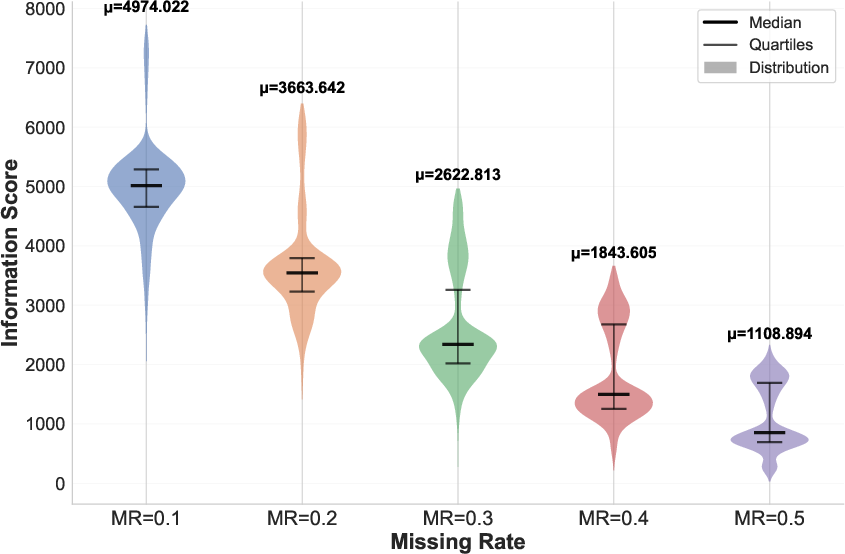
Figure 3: Informativeness score visualization on Scene-15; deeper blue indicates higher information support, with score distribution becoming increasingly bimodal and polarized as missingness increases.
Distribution-Level Selective Imputation
The ISMVC framework is instantiated using a multi-view variational autoencoder (VAE) with a mixture-of-Gaussians prior. Posterior aggregation for latent representations uses the Product-of-Experts (PoE) approach across views, while missing posteriors are selectively imputed at the distributional parameter level. Imputation uses k-nearest latent neighbors, weighting by 2-Wasserstein distance, and uncertainty is explicitly modeled with an additional variance term derived from posterior parameter variability among neighbors.
This contrasts with many extant approaches, which impute raw features or rely on complex model-specific procedures. By operating in the latent distributional space, ISMVC both stabilizes the posterior and allows the downstream clustering assignment to be more robust against unreliable imputations.
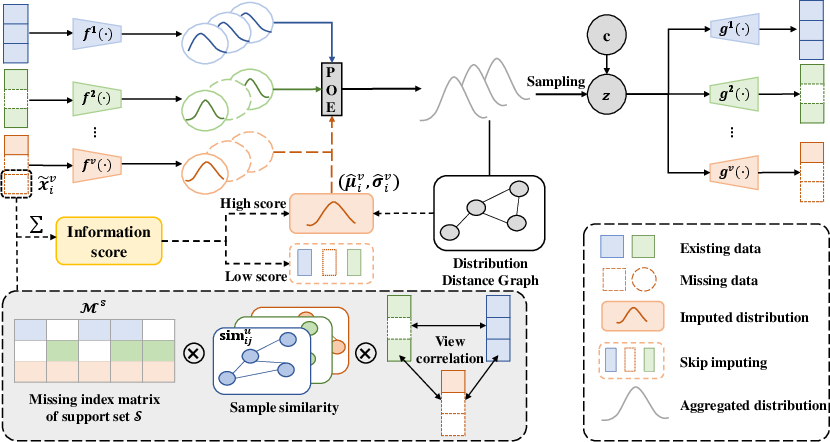
Figure 4: Overview of the ISMVC framework: an informativeness-based selection mechanism scores missing positions and imputes only when evidence is sufficient, with downstream clustering performed using the shared latent representation.
Empirical Evaluation
ISMVC is evaluated against the state-of-the-art over four benchmark datasets under unbalanced, realistic missing scenarios, comparing with both imputation-based and imputation-free methods as well as solutions employing model-driven cautious imputation.
- Overall performance: ISMVC achieves consistently higher accuracy, NMI, and ARI across all datasets and missing rates, frequently exceeding the best baseline by substantial margins, while also exhibiting minimal degradation as missingness increases (see results in Figure 5).
- Robustness: Selective imputation prevents the collapse observed in imputation-free methods at high missing rates and avoids the bias accumulation of indiscriminate imputation methods.
- Selection sensitivity: Ablations varying the selective imputation threshold demonstrate that the optimal clustering performance tracks the informativeness score threshold, with aggressive filling leading to performance declines under high missingness.
- Generality: The Informativeness-Based Selective Imputation (IBSI) module can be seamlessly deployed as a plug-in with both imputation-free and complete-sample-only baselines, yielding significant improvements with only marginal computational overhead (see Figures 7, 8).
- Interpretability: Visualization of position-level scores and their distributions exposes clear colocation between high informativeness and improved cluster assignments. Unimodal-to-bimodal transitions reveal distinct regimes of imputation reliability as missing rates increase.
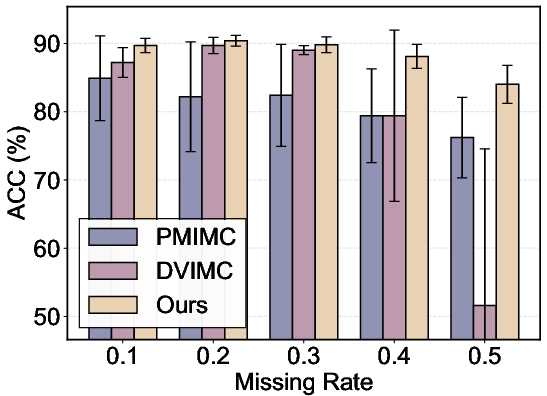
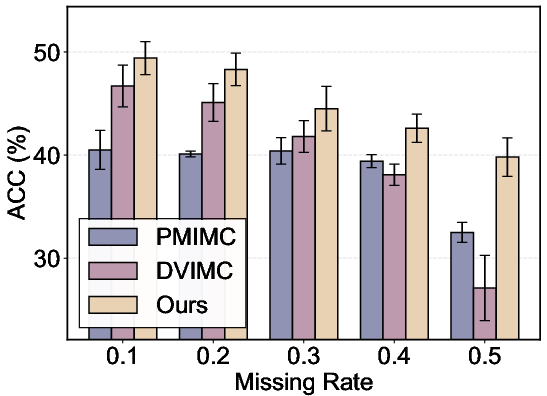
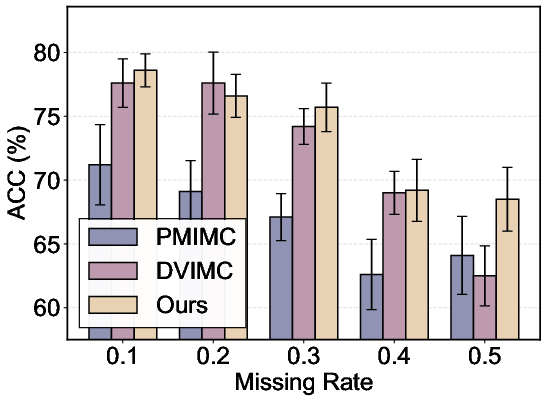
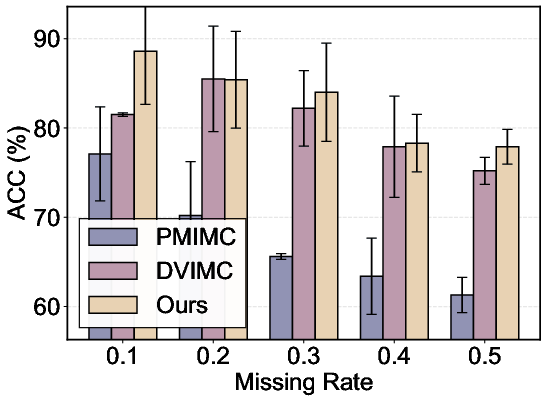
Figure 5: Bar charts of accuracy under increasing missing rates across four datasets, demonstrating the consistent superiority and robustness of ISMVC.
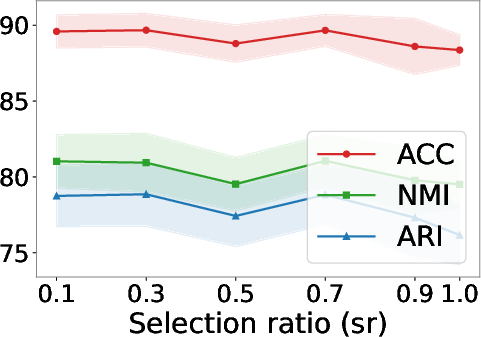
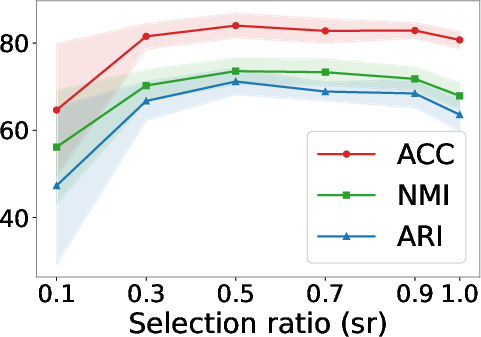
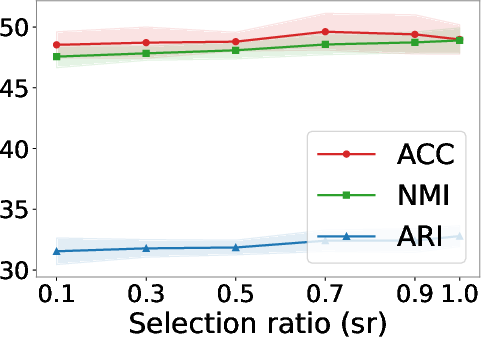
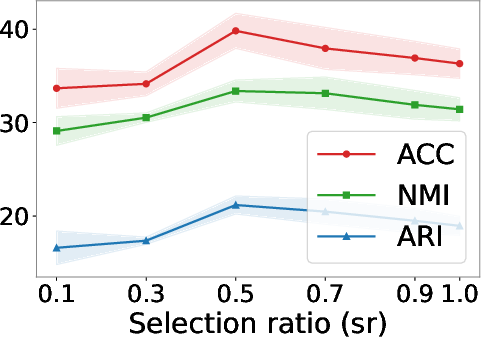
Figure 6: Selection ratio experiments under different missing rates reveal the trade-off between imputation coverage and noise as missing increases.
Practical and Theoretical Implications
ISMVC reifies robust IMC using a model-agnostic, lightweight, data-level strategy, alleviating the reliance on model-specific training feedback, and is well suited to large-scale or resource-constrained deployments. By prioritizing evidence-supported imputation and modeling epistemic uncertainty directly, the method avoids overconfidence and bias, particularly critical under highly unbalanced view missingness. The plug-in nature and distributional approach provide straightforward extensibility to a wide spectrum of multi-view clustering frameworks.
From a theoretical perspective, the informativeness score formalizes the longstanding intuition that only certain missing data instances are safe for imputation. ISMVC’s explicit uncertainty estimation integrates naturally with Bayesian methods, and its position-level granularity enables more nuanced handling than previous instance- or view-level approaches.
Future Directions
The informativeness-driven mechanism and latent-distribution-level imputation proposed in ISMVC suggest several promising research avenues:
- Integrating more sophisticated similarity and correlation metrics, including mutual information and alignment-based measures, to further refine support estimation.
- Extending selective imputation strategies to more complex downstream tasks, e.g., multi-view semi-supervised learning or active clustering.
- Leveraging ISMVC’s uncertainty estimates for outlier detection and active data acquisition in real-world incomplete multi-modal systems.
- Generalizing the selection mechanism to temporal or sequential multi-view data, where support sets may evolve dynamically.
- Investigating joint learning of the informativeness threshold and imputation networks in an end-to-end fashion.
Conclusion
ISMVC represents a principled, selective approach for incomplete multi-view clustering, balancing imputation utility and risk through explicit informativeness quantification and uncertainty modeling in a VAE framework. Extensive evidence demonstrates that partial, evidence-driven imputation is superior to both complete and null imputation, particularly for complex, unbalanced, and highly missing real-world datasets. The method’s plug-in capability and negligible computational cost further underscore its practical utility for robust multi-view learning systems.
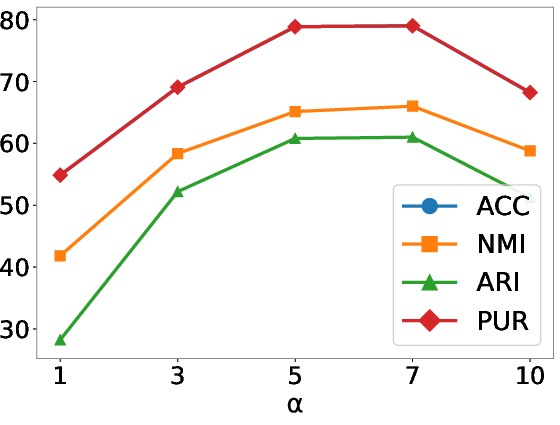
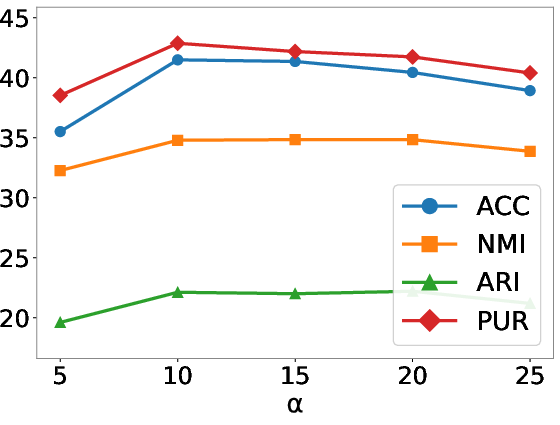
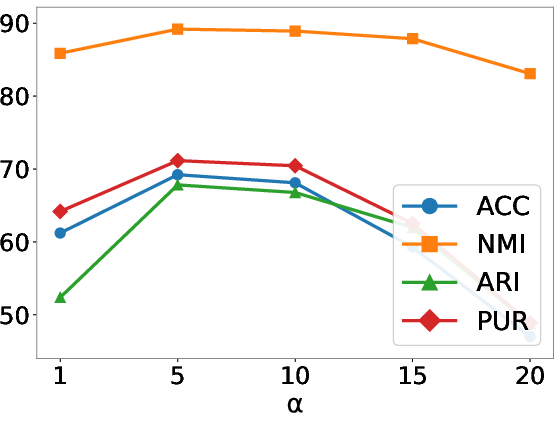
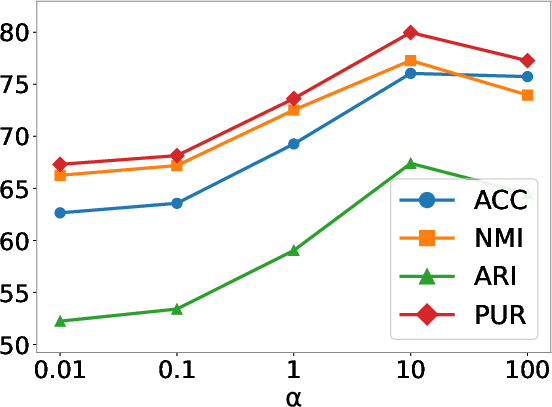
Figure 7: Parameter sensitivity analysis for the balancing coefficient α controlling the trade-off between reconstruction and posterior coherence across four datasets.
References:
C. Xu et al., "Simple Yet Effective Selective Imputation for Incomplete Multi-view Clustering" (2512.10327)