- The paper introduces BiCo, a one-shot method that binds visual concepts to prompt tokens, achieving state-of-the-art performance in cross-modal composition.
- It employs a hierarchical binder structure with a Diversify-and-Absorb Mechanism and Temporal Disentanglement Strategy to improve concept-token mapping.
- Experimental results demonstrate superior concept preservation and motion realism across diverse image and video compositions compared to existing methods.
Composing Concepts from Images and Videos via Concept-Prompt Binding: An Expert Review
Introduction and Motivation
The paper "Composing Concepts from Images and Videos via Concept-prompt Binding" (2512.09824) addresses the challenge of visual concept composition—the synthesis of coherent outputs by integrating disparate elements from images and videos. While diffusion-based generative models exhibit strong capabilities in concept grounding and customization, prior approaches struggle with decoupling complex concepts, such as those affected by occlusion and temporal changes, and with flexible cross-modal (image/video) concept fusion. Existing methods predominantly rely on LoRA adapters or embedding-based selection, which lack precise control, especially for non-object or style concepts and compositional operations involving both images and videos.
To surmount these limitations, the paper introduces BiCo, a novel one-shot method that binds visual concepts to corresponding prompt tokens, enabling flexible and precise composition through prompt manipulation without mask inputs. The architecture leverages a hierarchical binder structure for cross-attention conditioning in Diffusion Transformers, a Diversify-and-Absorb Mechanism (DAM) for improved concept-token mapping, and a Temporal Disentanglement Strategy (TDS) to facilitate compatibility between static and dynamic visual inputs.
Methodological Framework
BiCo Architecture Overview
BiCo operationalizes concept binding by attaching light-weight, learnable binder modules to the prompt tokens of a DiT-based text-to-video diffusion model. These binders encode the correspondence between visual concepts and textual tokens via a cross-attention-based mechanism, achieved through one-shot training.
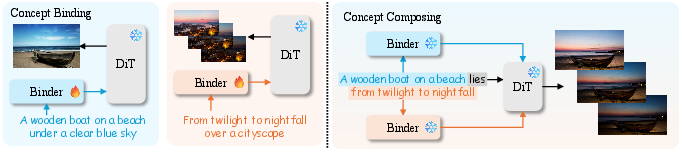
Figure 1: BiCo overview—visual concepts are bound to prompt tokens, which are then composed via corresponding adapters for flexible multi-source generation.
During inference, designated prompt tokens corresponding to various concepts are passed through their respective binders to generate an updated prompt, serving as the DiT model’s conditioning input. This enables precise control over which visual attributes—be they objects, styles, or motions—are integrated from different sources.
Hierarchical Binder Structure
To capture the diverse behavior of DiT blocks during denoising, binders are hierarchically organized, comprising a global binder for overall association and per-block binders for block-specific conditioning. Each binder is realized as an MLP with residual connections and a zero-initialized scaling factor to stabilize learning. For video inputs, a dual-branch structure incorporating separate spatial and temporal MLPs decouples concept learning along both dimensions, and a two-stage inverted training regime prioritizes optimization under high-noise (less informative) conditions for improved robustness.
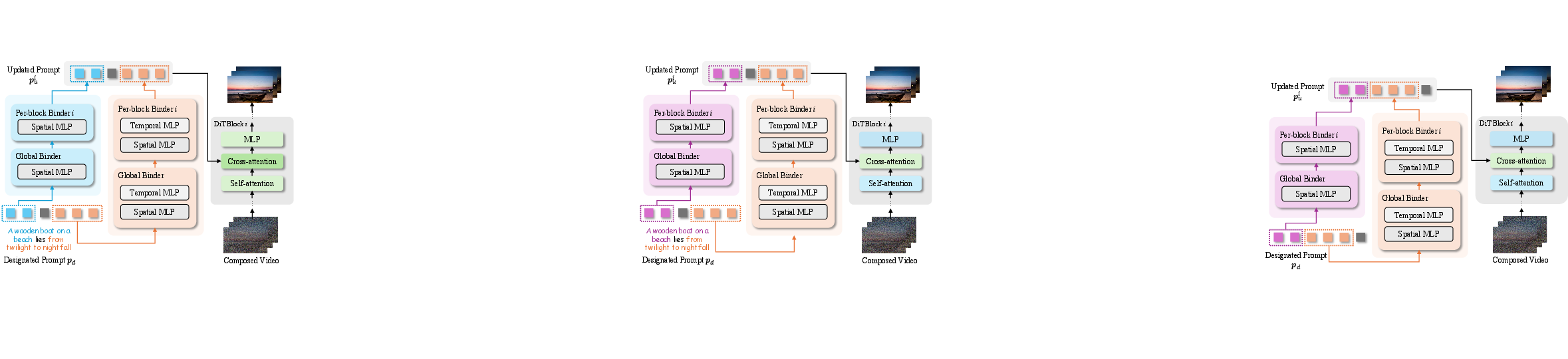
Figure 2: Hierarchical binder structure—global and per-block binders, with dual-branch handling for spatiotemporal separation in video concepts.
DAM: Diversify-and-Absorb Mechanism
Establishing accurate token-concept correspondence is non-trivial in one-shot settings. The DAM utilizes large vision-LLMs (VLMs) to automatically extract key spatial and temporal concepts from the input, diversifying prompts while anchoring essential concepts. To suppress concept-irrelevant details in token binding, a learnable absorbent token is introduced; it absorbs residual visual information during training but is discarded during composition, constraining generation to desired concepts only.
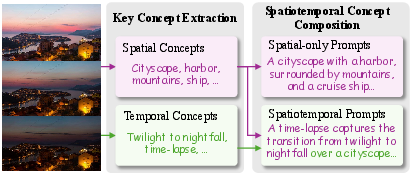
Figure 3: DAM—VLM extracts and diversifies spatial and temporal concepts for improved concept-token mapping.
Temporal Disentanglement Strategy
TDS resolves the domain shift between static images and videos by decoupling spatial and temporal concept learning. Training proceeds in two phases: first, binders are trained on static frames for spatial concepts; second, a dual-branch binder with an additional temporal gating module is trained on full video sequences using both spatial and temporal concepts. Weights are inherited across stages, mitigating catastrophic forgetting and enhancing token-concept alignment for cross-modal composition.
Experimental Validation
Comparative Analysis
BiCo is benchmarked against four representative methods (Textual Inversion, DreamBooth-LoRA, DreamVideo, DualReal), each adapted to a consistent T2V backbone for fair assessment. On 40 compositional cases sampled from DAVIS and internet sources, quantitative metrics (CLIP-T, DINO-I) and human evaluations (concept preservation, prompt fidelity, motion quality) demonstrate that BiCo achieves state-of-the-art performance across all axes.

Figure 4: Qualitative comparison—BiCo delivers high-fidelity compositional generation, accurately preserving and combining concepts compared to baselines.
Notably, BiCo outperforms DualReal by a significant margin in subjective overall quality (+54.67%), and uniquely supports non-object concepts, multi-concept extraction, arbitrary modality input, and prompt-driven composition.
Ablations and Component Analysis
Comprehensive ablations illustrate the contributions of each architectural element. Hierarchical binders substantially enhance per-block concept retention. DAM’s prompt diversification and absorbent token yield marked improvements in concept-token disambiguation. TDS further improves compatibility and detail preservation in cross-modal compositions, while inverted training stabilizes optimization and bolsters final quality outcomes.

Figure 5: Component case study—visual inputs (above) and composed outputs (below), revealing the additive benefits of hierarchical binders, DAM, absorbent tokens, and TDS.
Qualitative Results and Applications
BiCo generalizes beyond basic concept transfer, supporting complex compositions (styles, motions), multi-concept scenarios, and flexible prompt-controlled fusion. Visual results exhibit high consistency with source content and prompt instructions.

Figure 6: Diverse qualitative results—BiCo excels across style transfer, motion synthesis, and multi-concept assembly in both image and video domains.
Beyond compositional synthesis, BiCo lends itself to tasks such as concept decomposition and text-guided editing. Selective retention or modification of specific tokens enables versatile content manipulation, applicable to single or multi-modal inputs.
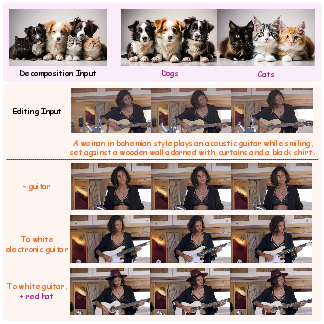
Figure 7: Extended applications—BiCo enables targeted decomposition (e.g., extracting all dogs from a multi-animal scene) and fine-grained text-guided editing.
Limitations and Future Directions
BiCo currently treats all prompt tokens equally during composition, whereas token importance is unevenly distributed—subject and motion tokens are typically more critical than function words. This uniform weighting can lead to concept drift, such as failure to reproduce atypical visual elements (Figure 8), or erroneous semantic reasoning in complex tasks. Future directions include adaptive token prioritization and integration of advanced VLM reasoning mechanisms to refine captioning and compositional logic.

Figure 8: Failure cases—token-equal weighting causes color drift and incorrect object reasoning (e.g., unnatural limb additions).
Conclusion
BiCo represents a technically rigorous advancement in concept-prompt binding for visual content composition. Its hierarchical binder architecture, DAM, and TDS collectively enable simultaneous extraction and integration of arbitrary concepts across modalities without explicit mask inputs or extensive retraining. Empirical validation underscores its superiority in concept fidelity, prompt-following, and motion realism, with direct applicability to creative synthesis, video editing, and concept decomposition. Continued research on token-adaptive composition and reasoning-enriched prompting is warranted to further enhance control and reliability in multi-concept visual generation.