OmniPSD: Layered PSD Generation with Diffusion Transformer
Abstract: Recent advances in diffusion models have greatly improved image generation and editing, yet generating or reconstructing layered PSD files with transparent alpha channels remains highly challenging. We propose OmniPSD, a unified diffusion framework built upon the Flux ecosystem that enables both text-to-PSD generation and image-to-PSD decomposition through in-context learning. For text-to-PSD generation, OmniPSD arranges multiple target layers spatially into a single canvas and learns their compositional relationships through spatial attention, producing semantically coherent and hierarchically structured layers. For image-to-PSD decomposition, it performs iterative in-context editing, progressively extracting and erasing textual and foreground components to reconstruct editable PSD layers from a single flattened image. An RGBA-VAE is employed as an auxiliary representation module to preserve transparency without affecting structure learning. Extensive experiments on our new RGBA-layered dataset demonstrate that OmniPSD achieves high-fidelity generation, structural consistency, and transparency awareness, offering a new paradigm for layered design generation and decomposition with diffusion transformers.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces OmniPSD, an AI system that can create and edit Photoshop-style files (PSD) with multiple layers and real transparency. Unlike most AI image tools that only make flat, single-layer pictures, OmniPSD can:
- Turn a text prompt into a multi-layer PSD you can edit.
- Break a single, flattened image into separate, editable layers (like background, foreground objects, and text), keeping their transparent edges.
In short, it helps designers get AI-made images that are actually useful inside professional tools like Photoshop.
What questions did the researchers ask?
The paper focuses on two simple questions:
- Can an AI generate a PSD with multiple layers directly from text, instead of a flat image?
- Can an AI take a normal picture and separate it into the original layers, including transparent areas, so you can edit each element?
They also asked a practical question: how can the AI keep transparency accurate so that cut-outs, shadows, and soft edges look natural?
How did they do it?
The researchers combined three main ideas and tools. Here’s what they mean, explained in everyday language:
Key building blocks
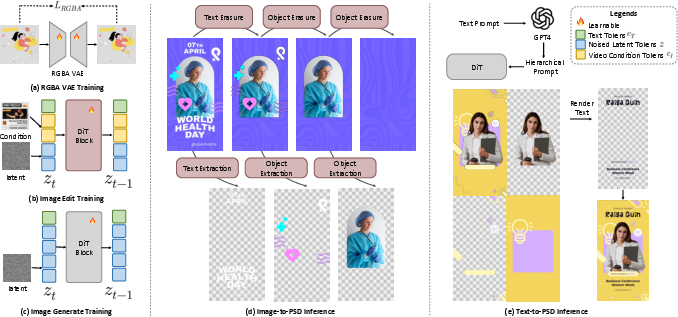
- Diffusion Transformer (the “artist”): Think of this as an AI painter that starts from random noise and gradually turns it into a detailed image by “cleaning up” the noise step by step. The “Transformer” part helps the AI pay attention to many parts of the image at once, keeping things consistent.
- RGBA and the alpha channel (how transparency works): RGBA images have four parts: Red, Green, Blue, and Alpha. The Alpha channel controls transparency—like how see-through a sticker is.
- VAE (a smart image zipper): A Variational Autoencoder (VAE) compresses images into a compact code and can also rebuild them back. Their special RGBA-VAE is trained to preserve transparency details (alpha) when compressing and decompressing images, which is crucial for layered editing.
Making a PSD from text (Text-to-PSD)
To generate layers that fit together, OmniPSD uses a clever trick:
- It lays out four related images on a single canvas in a 2×2 grid: the full poster, the foreground, the middle ground, and the background.
- Because they share one canvas, the AI can “look across” all four and learn how they match—like colors, positions, and which things sit in front of others.
- Then it decodes each piece with the RGBA-VAE to keep transparency accurate, so the layers are ready to be edited.
Think of this like placing four mini versions of your poster on a table so the AI can learn how the parts relate. This helps it make layers that feel like they belong together.
Breaking an image into layers (Image-to-PSD)
For a single flattened image (like a finished poster), OmniPSD “peels” it apart in steps:
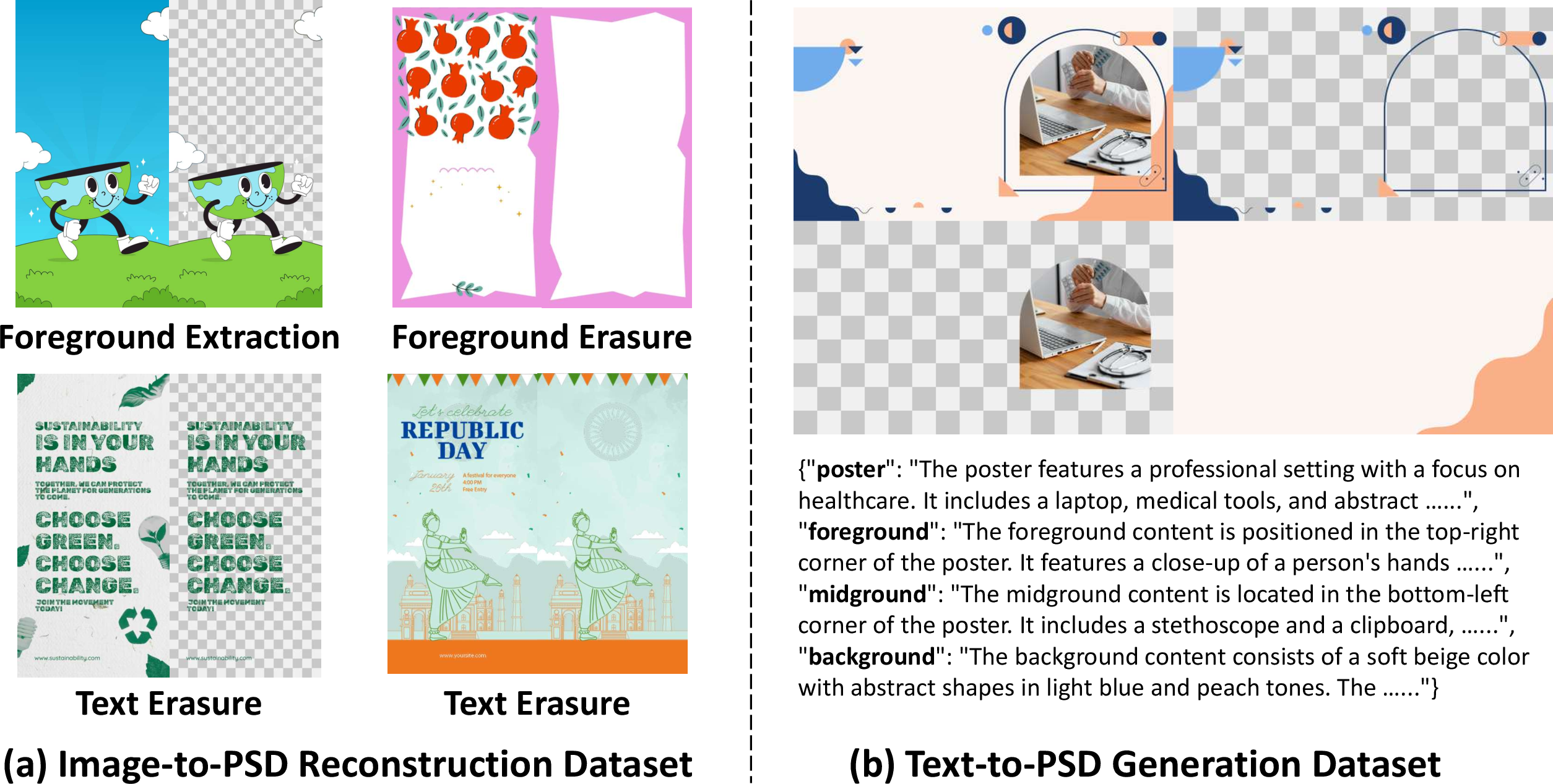
- Extract the text layer (reads what the text says and turns it into an editable text object with a matching font).
- Erase the text from the image and fix the background underneath, so it looks clean.
- Find and pull out foreground objects as separate transparent layers.
- Keep fixing the background as more foreground items are removed.
This is like peeling stickers off a poster one by one and repainting whatever was hidden under them, so each sticker becomes its own layer and the poster behind stays complete. Every piece is saved with proper transparency (RGBA), so edges and shadows look right.
Keeping transparency accurate
They trained a special RGBA-VAE on lots of design examples (not just regular photos), so it understands tricky transparency, like soft shadows, glow effects, and semi-transparent text. This helps avoid ugly halos and rough edges.
Data to teach the AI
They built a large “Layered Poster Dataset” of over 200,000 real PSD files with proper groups and layer info. This gave the AI many examples of how professional designs are structured, from text layers to complex backgrounds.
What did they find, and why does it matter?
Main results:
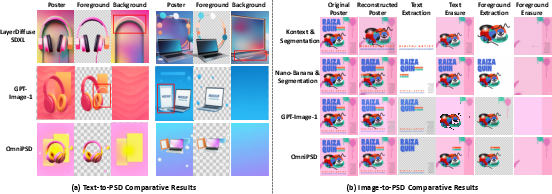
- The AI can generate layered PSDs directly from text, not just flat images.
- It can reconstruct editable layers from a single finished image—something previous systems didn’t really do.
- The layers have accurate transparency, clean edges, and good structure (foreground in front of background, text placed correctly).
- In tests, OmniPSD produced more realistic, more consistent results than other systems that attempt layered generation, and better reconstruction quality than tools that don’t truly model transparency.
Why it matters:
- Designers can get AI outputs that are actually usable in real workflows—edit text, move objects, tweak backgrounds—without starting from scratch.
- It saves time when reusing, reformatting, or updating designs (like making versions for different platforms or languages).
- It bridges creative generation (make new designs) with analytical reconstruction (take apart and edit existing designs).
What could this lead to?
- Faster design workflows: You could generate a poster with editable layers from a prompt, then change fonts, move elements, or swap backgrounds quickly.
- Better content reuse: Break existing images into clean assets you can remix, animate, or adapt to new layouts.
- Smarter design tools: Future apps could use this approach to turn flat images into editable documents automatically.
- More precise transparency in AI graphics: Accurate alpha handling helps with professional-quality effects like soft shadows, glow, and blending.
Overall, OmniPSD points to a future where AI-created images aren’t just “pretty pictures,” but fully editable, well-structured design files that fit right into how professionals actually work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following items summarize what remains missing, uncertain, or unexplored in the paper, organized to guide concrete follow-up research.
Data and benchmarking
- The Layered Poster Dataset’s licensing, consent, and redistribution status are not specified, leaving uncertainty about reproducibility and ethical use.
- Dataset composition and diversity are under-described (language/script coverage, font families, design genres beyond posters, complexity of layer counts, blending modes), limiting conclusions about generalizability.
- The dataset removes text layers for Text-to-PSD training, which may bias the model against learning text–background interplay and realistic layer occlusions; the impact of this design choice is not quantified.
- Layer annotations appear limited to RGBA PNGs and simple grouping (foreground/background/text); absence of ground-truth PSD features (layer styles, blending modes, adjustment layers, masks, groups) prevents evaluation of true PSD-level editability.
- No public benchmark protocol or standardized splits (train/val/test) are detailed; release plans, annotation schemas, and evaluation scripts are not provided, hindering community adoption and fair comparison.
- Image-to-PSD training relies on triplets with masks, but the source, quality, and ontology of masks (instance vs. semantic, tightness, occlusion handling) are not described; mask generation at inference is not formalized.
- The test sets (500 samples each) are relatively small and derived from the same domain; cross-domain and out-of-distribution benchmarks (e.g., non-poster graphics, UI, packaging, illustrations) are missing.
Method design and capabilities
- The 2×2 grid limits Text-to-PSD to a fixed number of layers (two foregrounds, one background); no mechanism is provided for variable layer counts, hierarchical groups, or dynamic layer discovery.
- Each grid quadrant reduces effective per-layer resolution (1/4 of 1024×1024); there is no analysis of resolution trade-offs or strategies for high-resolution posters common in professional workflows.
- Cross-layer reasoning is implicit via spatial self-attention over the grid; the lack of explicit cross-layer modules (e.g., occlusion-aware attention, relation heads) may constrain modeling of complex compositing and occlusions.
- The pipeline outputs RGBA raster layers; reconstruction of vector graphics (shapes, paths, icons) and PSD-native constructs (layer styles, blending modes like Multiply/Overlay, adjustment layers, smart objects) is not addressed.
- Image-to-PSD relies on an iterative “extract → erase” process but does not specify a stopping criterion, instance ordering policy, or robustness to heavy overlap/occlusions and semi-transparent elements.
- Foreground “salient region” detection at inference is mentioned but the detector/heuristic is not defined; failure modes when masks are inaccurate or missing are not analyzed.
- Text vectorization is handled via OCR and font retrieval; there is no support for stylized/curved/outlined text, gradient/texture fills, kerning/leading/tracking fidelity, or multi-script typography beyond OCR recognition.
- The font retrieval system’s coverage, accuracy, and handling of rare/custom/paid fonts are not reported; how the pipeline represents fallback fonts or substitutes for unavailable typefaces is unspecified.
- The RGBA-VAE models only alpha blending (RGBA), not PSD layer styles (shadows, glows, blending modes, layer masks); it remains unclear how soft shadows, halos, and non-linear blending are represented or reconstructed.
- LoRA adapters are trained per subtask (text/non-text extraction/erasure); scalability to broader edit types (effects removal, color grading, global adjustments) and maintenance of many adapters is not discussed.
- The method targets posters; applicability to other design media (social graphics, web/UI components, infographics) and to natural images is untested.
Evaluation and metrics
- Layer-level alpha accuracy and boundary quality are not directly evaluated; recomposition MSE/PSNR conflates correct compositing with potentially incorrect layer assignments. Alpha-specific metrics (e.g., boundary F-measure/IoU, matte SAD/Grad) are missing.
- Occlusion ordering, layer stacking correctness, and inter-layer consistency are not measured with dedicated metrics; GPT-4 judging is subjective and non-reproducible.
- No timing/throughput benchmarks (training/inference latency, memory footprint) are reported, making it hard to assess practicality for professional workflows.
- Editability is not objectively measured (e.g., designer task completion, time-to-edit, number of manual fixes needed per generated PSD).
- Comparisons for Image-to-PSD use ad hoc baselines; rigorous baselines combining SOTA segmentation/matting/inpainting pipelines or PSD parsing tools are absent, making “first” claims difficult to contextualize.
- Robustness tests are missing for challenging cases: dense text, heavy motion blur, semi-transparent overlays, complex shadows/glows, metallic/foil textures, perspective warps, and multilingual/stylized scripts.
- The user study (18 participants) lacks details on participant expertise (design professionals vs. lay users), tasks, inter-rater reliability, and statistical significance.
Generalization, robustness, and failure analysis
- Domain shift is not analyzed (e.g., performance on non-poster graphics or real-world photos); generalization across styles, layouts, and cultural scripts remains an open question.
- Failure cases and qualitative error taxonomy (mis-layering, alpha halos, text OCR/font mismatches, background inpainting artifacts) are not documented to guide targeted improvements.
- The approach assumes deterministic rectified flow; stability under different sampling schedules, noise levels, and guidance settings is not explored.
- The method’s reliance on hierarchical prompts (JSON per layer) raises questions about usability with free-form prompts or sparse instructions; prompt sensitivity and failure behavior are not studied.
- Safety and ethics considerations (copyright enforcement on trained fonts/assets, generating derivative PSDs from copyrighted works, watermark preservation, content moderation) are not addressed.
Reproducibility and deployment
- Code, models, and dataset release status are unclear; without open resources, results are difficult to reproduce and extend.
- Hyperparameters for RGBA-VAE retraining (loss weights, architectures, augmentation) and LoRA configurations beyond rank are not fully specified; ablations on these settings are limited.
- Integration with real PSD ecosystems (Photoshop/Photopea plug-ins, layer styles mapping, color management, ICC profiles) is not demonstrated, leaving practical adoption uncertain.
- No guidance is provided on scaling to production (distributed training, adapter management, caching pipelines) or on deploying interactive, user-in-the-loop workflows.
Extensions and scope
- Dynamic layer count, hierarchical grouping, and automatic discovery of semantic sublayers remain open (e.g., multiple foreground instances, effects layers, adjustment layers).
- Vector-native generation/decomposition (SVG/shape layers) is not explored; a unified raster–vector pipeline for design assets remains an open direction.
- Video or multi-page document support (layered sequences, temporal consistency, page masters) is not addressed.
- Learned reconstruction of PSD blending modes and layer styles (mapping from RGBA+effects back to editable PSD primitives) is an open research question.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging OmniPSD’s text-to-PSD generation, image-to-PSD decomposition, transparency-preserving RGBA-VAE, and OCR/font recovery pipeline.
- Marketing and Creative Agencies: Prompt-to-PSD generation for campaign assets
- Sectors: advertising, media, software
- Tools/workflows: Photoshop plugin or REST API that converts hierarchical prompts into multi-layer PSDs (background, foreground, text, effects) for fast iteration and A/B testing; batch generation of variants across channels
- Assumptions/dependencies: access to Flux-dev/Flux-Kontext weights; GPU inference; brand asset libraries (logos, palettes); human-in-the-loop QC
- E-commerce Product Imaging: Batch image-to-PSD decomposition for asset reuse
- Sectors: e-commerce, retail, software
- Tools/workflows: backend microservice to separate product RGBA from background, enabling clean re-composition on seasonal backdrops, promo banners, and marketplace-specific templates
- Assumptions/dependencies: reasonable product-background separation; sufficient resolution (≈1024×1024); scalable inference infrastructure
- Localization and Multilingual Design: Editable text restoration and re-rendering
- Sectors: localization, marketing, publishing
- Tools/workflows: OCR → font retrieval → vector text layer reconstruction; re-typeset with language-specific copy while preserving layout and typography in PSD
- Assumptions/dependencies: OCR accuracy for complex typography; font-library licensing; multilingual script coverage; layout QA
- Motion Graphics Preparation: PSD-to-After Effects compositing
- Sectors: media, post-production
- Tools/workflows: generate or decompose layers (background, foreground, text) for immediate import into AE; faster title packages, lower thirds, and broadcast graphics
- Assumptions/dependencies: consistent layer naming/metadata; export conventions; integration via scripts/plugins
- Digital Asset Management (DAM): Automated ingestion of flattened assets
- Sectors: enterprise software, content ops
- Tools/workflows: API that converts archived PNG/JPG posters into layered PSD with metadata (bounding boxes, stacking order) for future reuse and edits
- Assumptions/dependencies: PSD metadata mapping; storage for RGBA layers; governance on AI-modified content
- Game Development and UI Asset Pipelines: Transparent sprites and layered UI components
- Sectors: gaming, software, mobile apps
- Tools/workflows: text-to-PSD for sticker packs, icons, and UI overlays; image-to-PSD to cleanly extract assets from concept art for engine-ready RGBA sprites
- Assumptions/dependencies: domain fine-tuning for stylized art; consistent alpha boundaries; pipeline integration (Unity/Unreal)
- Design Education and Critique: Layer-aware analysis and assignments
- Sectors: education, HCI
- Tools/workflows: decompose exemplar posters to teach occlusion, hierarchy, and composition; generate layered assignments from prompts; structured feedback on layer coherence
- Assumptions/dependencies: curriculum integration; safe dataset for instruction; instructor oversight
- Small Business and Daily Use: Rapid flyers, menus, and social posts
- Sectors: SMB, creator tools
- Tools/workflows: lightweight desktop/web app to turn text prompts or inspirations into editable PSD templates (with separate text, foreground, background)
- Assumptions/dependencies: simplified UI; content quality guardrails; templating and brand presets
Long-Term Applications
These applications require further research, scaling, system integration, or standardization—particularly in vector-native output, video layers, personalization at ad-tech scale, and policy frameworks.
- Vector-Native Layer Generation: Editable SVG/AI layers instead of raster-only
- Sectors: design software, publishing, web
- Tools/workflows: integrate vector decoders to produce path-based layers for shapes, text, and logos; high-fidelity typography and scalable graphics
- Assumptions/dependencies: vector training data; hybrid raster–vector architectures; font licensing compliance
- Video-to-Layered Compositing: Temporal RGBA decomposition and generation
- Sectors: media, post-production
- Tools/workflows: extend RGBA-VAE and Flux-Kontext to video; generate/edit multi-frame layered sequences for motion graphics workflows
- Assumptions/dependencies: temporal consistency models; compute budgets; evaluation metrics for layered video
- Real-Time Personalization at Ad-Tech Scale
- Sectors: advertising technology, e-commerce
- Tools/workflows: dynamic prompt-to-PSD pipelines connected to product feeds, audience segments, and A/B infra; automatic variant testing and rollout
- Assumptions/dependencies: low-latency inference; budget management; governance for content safety and brand compliance
- AR/VR Overlay Generation: Transparent occlusion-aware assets
- Sectors: AR/VR, retail, events
- Tools/workflows: generate layered transparent overlays for AR signage, product try-ons, and event graphics; occlusion-consistent compositing with live scenes
- Assumptions/dependencies: real-time runtime; device-specific optimization; occlusion reasoning beyond posters
- Cultural Heritage and Document Restoration
- Sectors: archives, museums, publishing
- Tools/workflows: reconstruct layered designs from scans of vintage posters; recover text and separations for preservation and reprinting
- Assumptions/dependencies: domain adaptation to aged/scanned artifacts; noise removal; curation and provenance tracking
- Automated Brand Guardianship and Auditing
- Sectors: enterprise brand management, compliance
- Tools/workflows: detect and enforce brand rules (typefaces, spacing, color palettes) across generated/decomposed PSDs; automated review dashboards
- Assumptions/dependencies: rule engines; LLM-assisted layout reasoning; access to brand manuals and assets
- Provenance and Policy Standards for Layered AI Content
- Sectors: policy, standards, software
- Tools/workflows: embed C2PA-like provenance and watermarks in PSD layers; disclosures for AI-generated edits; audit trails across DAM systems
- Assumptions/dependencies: industry consortium buy-in; legal frameworks; standardized metadata schemas
- Edge/Mobile Creator Tools
- Sectors: mobile software, creator economy
- Tools/workflows: on-device text-to-PSD and image-to-PSD for quick edits; offline workflows for creators and field teams
- Assumptions/dependencies: model compression/quantization; energy-efficient inference; UI for small screens
- Marketplace and Template Ecosystems
- Sectors: e-commerce, SaaS
- Tools/workflows: curated marketplaces of AI-generated layered templates; user-tailorable PSD kits aligned with verticals (restaurants, events, real estate)
- Assumptions/dependencies: IP/licensing clarity; quality assurance; long-term maintenance of model/tags
- Cross-Domain Expansion to Packaging, UI/UX, and Technical Diagrams
- Sectors: manufacturing, software, education
- Tools/workflows: generate layered packaging mockups, UI banners, and infographics with editable layers; integrate with PLM or design systems
- Assumptions/dependencies: domain-specific datasets; vector-heavy output; regulation for labeling and accessibility (e.g., WCAG, FDA for health content)
Glossary
- Alpha channel: The fourth channel in RGBA images encoding per-pixel transparency. "OmniPSD is a Diffusion-Transformer framework that generates layered PSD files with transparent alpha channels."
- Alpha compositing: The process of combining images using their alpha (transparency) values. "introducing benchmarks that adapt standard RGB metrics to four-channel images via alpha compositing"
- Alpha matte: A grayscale transparency mask used to separate foreground from background. "decomposes a single image into depth layers, alpha mattes, or semantic regions"
- Alpha-aware latent representation: A latent encoding that explicitly preserves transparency information for RGBA data. "which enables alpha-aware latent representation shared across both pathways."
- Autoencoder (Variational Autoencoder): A generative model that encodes data into a latent space and decodes it back; a VAE adds probabilistic latent variables. "a unified variational autoencoder for RGBA image modeling."
- Background inpainting: Filling in occluded or missing background regions to restore a clean scene. "ensuring modular composability across text removal, object extraction, and background inpainting subtasks."
- CLIP Score: A metric that measures semantic alignment between images and text using CLIP embeddings. "For the Text-to-PSD task, we report layer-wise CLIP Score to assess semantic alignment between each generated layer and its textual prompt."
- Cross-attention: An attention mechanism allowing one set of tokens to attend to another, often used to condition images on text. "cross-attention-based prompt editing"
- Diffusion probabilistic models: Generative models that learn to reverse a noise process to synthesize data. "Diffusion probabilistic models have rapidly become the dominant paradigm for high-fidelity image synthesis"
- Diffusion Transformer (DiT): A transformer-based denoiser backbone used in diffusion models. "built upon the pretrained Diffusion Transformer (DiT) architecture."
- FID (Fréchet Inception Distance): A metric for visual realism comparing distributions of generated and real images. "FID is computed on each generated layer and composite output to measure visual realism."
- Flow field: A vector field describing continuous transformation in latent space during flow-based training or inference. "models the continuous transformation between \mathbf{z}0 and \mathbf{z}_1 as a flow field \mathbf{v}\theta(\mathbf{z}_t, t \mid \mathbf{z}_0)"
- Flow Matching: A training objective that aligns a learned flow with the true displacement between source and target distributions. "The training objective follows the standard Flow Matching Loss"
- Foreground erasure: Removing foreground content to reconstruct an occlusion-free background layer. "Foreground Erasure Model."
- Foreground extraction: Isolating and generating foreground elements as separate RGBA layers. "Foreground Extraction Model."
- Flux-dev: A text-to-image diffusion transformer used for creative synthesis within the Flux ecosystem. "Flux-dev, a text-to-image generator for creative synthesis"
- Flux-Kontext: An image-editing diffusion transformer enabling in-context refinement and reconstruction. "Flux-Kontext, an image editing model for in-context refinement and reconstruction."
- In-context learning: Conditioning a model on examples or structured inputs within the same forward pass to guide behavior. "through in-context learning."
- Inpainting modules: Components that fill in missing or occluded parts of an image. "inpainting modules"
- KL divergence: A measure of difference between probability distributions, used for latent regularization in VAEs. "\mathrm{KL}(q(z_{RGB}|\cdot)|p)"
- Latent space: The compressed representation space used by autoencoders or diffusion models. "encode and decode transparent images into a latent space that preserves alpha-channel information"
- Latent transparency: An additional learned latent offset encoding transparency without retraining the RGB backbone. "âlatent transparencyâ"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that adds low-rank adapters to pretrained models. "We adopted the LoRA fine-tuning strategy"
- LPIPS: A perceptual similarity metric comparing deep features between images. "Lower is better for MSE and LPIPS"
- Multi-Modal Attention (MMA): An attention mechanism that integrates multiple modalities (e.g., condition and target latents). "The transformer backbone applies Multi-Modal Attention (MMA)"
- OCR (Optical Character Recognition): Automatic recognition of text in images. "we reconstruct vector-text through a unified OCR--font-recovery--rendering pipeline."
- ODE-based formulations: Approaches that model diffusion as deterministic Ordinary Differential Equations for efficient sampling. "ODE-based formulations recast diffusion as learning continuous deterministic flows"
- Perceptual alignment: Ensuring generated outputs match reference images in high-level semantic features. "perceptual alignment, and latent regularization"
- PSNR (Peak Signal-to-Noise Ratio): A reconstruction quality metric measuring signal fidelity relative to noise. "higher is better for PSNR"
- PSD (Photoshop Document): A layered design file format used by Adobe Photoshop. "Layered design formats such as Photoshop (PSD) files are essential"
- RGBA: A four-channel image format containing Red, Green, Blue, and Alpha (transparency). "Generating transparent or layered RGBA content is crucial"
- RGBA-VAE: A variational autoencoder tailored to encode/decode RGBA images while preserving transparency. "An RGBA-VAE is employed as an auxiliary representation module to preserve transparency without affecting structure learning."
- SAM2 segmentation: A segmentation approach leveraging the SAM2 model to derive masks. "transparency masks are derived using SAM2 segmentation"
- Self-attention: An attention mechanism where tokens attend to each other within the same sequence for context. "Spatial self-attention over this grid lets layer tokens attend to the full-poster tokens"
- SSIM (Structural Similarity Index Measure): A metric assessing structural similarity between images. "higher is better for PSNR, SSIM"
- Transformer-based denoiser: A transformer architecture used as the noise-removal backbone in diffusion models. "Transformer-based denoisers have become the de facto backbone"
- U-Net-based denoiser: A U-Net architecture used for denoising in diffusion processes. "U-Net-based denoisers in pixel or latent space"
- Vector-graphic decoder: A component that outputs scalable vector graphics rather than raster pixels. "vector-graphic decoders for variable multi-layer layouts and object-level controllability"
Collections
Sign up for free to add this paper to one or more collections.