Natural Geometry of Robust Data Attribution: From Convex Models to Deep Networks
Published 9 Dec 2025 in cs.LG and math.OC | (2512.09103v1)
Abstract: Data attribution methods identify which training examples are responsible for a model's predictions, but their sensitivity to distributional perturbations undermines practical reliability. We present a unified framework for certified robust attribution that extends from convex models to deep networks. For convex settings, we derive Wasserstein-Robust Influence Functions (W-RIF) with provable coverage guarantees. For deep networks, we demonstrate that Euclidean certification is rendered vacuous by spectral amplification -- a mechanism where the inherent ill-conditioning of deep representations inflates Lipschitz bounds by over $10{,}000\times$. This explains why standard TRAK scores, while accurate point estimates, are geometrically fragile: naive Euclidean robustness analysis yields 0\% certification. Our key contribution is the Natural Wasserstein metric, which measures perturbations in the geometry induced by the model's own feature covariance. This eliminates spectral amplification, reducing worst-case sensitivity by $76\times$ and stabilizing attribution estimates. On CIFAR-10 with ResNet-18, Natural W-TRAK certifies 68.7\% of ranking pairs compared to 0\% for Euclidean baselines -- to our knowledge, the first non-vacuous certified bounds for neural network attribution. Furthermore, we prove that the Self-Influence term arising from our analysis equals the Lipschitz constant governing attribution stability, providing theoretical grounding for leverage-based anomaly detection. Empirically, Self-Influence achieves 0.970 AUROC for label noise detection, identifying 94.1\% of corrupted labels by examining just the top 20\% of training data.
The paper introduces a unified framework using the Natural Wasserstein metric to certify robustness in data attribution across convex and deep networks.
It reveals that spectral amplification in deep networks inflates Euclidean Lipschitz constants, necessitating a geometric reweighting approach.
Empirical results demonstrate up to 76× sensitivity reduction and effective anomaly detection with high AUROC by leveraging self-influence scores.
Certified Robust Data Attribution: Bridging Convex Models and Deep Networks
Introduction
The paper "Natural Geometry of Robust Data Attribution: From Convex Models to Deep Networks" (2512.09103) proposes a unified framework for certified robustness in data attribution, addressing both convex models and deep neural networks. The authors focus on influence estimation—the attribution of model predictions to specific training points—delivering a geometric and distributionally robust analysis that exposes fundamental limitations of existing methods and proposes principled remedies. Central to the work is the identification and resolution of the "spectral amplification" barrier, which renders naive Lipschitz certification vacuous in deep networks due to the severe ill-conditioning of learned feature representations. The framework leverages Wasserstein distributionally robust optimization (DRO) and introduces the Natural Wasserstein metric, grounded in the feature geometry induced by the model, to yield the first nontrivial certifications of influence stability in deep networks.
Fragility of Influence Attribution and Motivation for Robustness
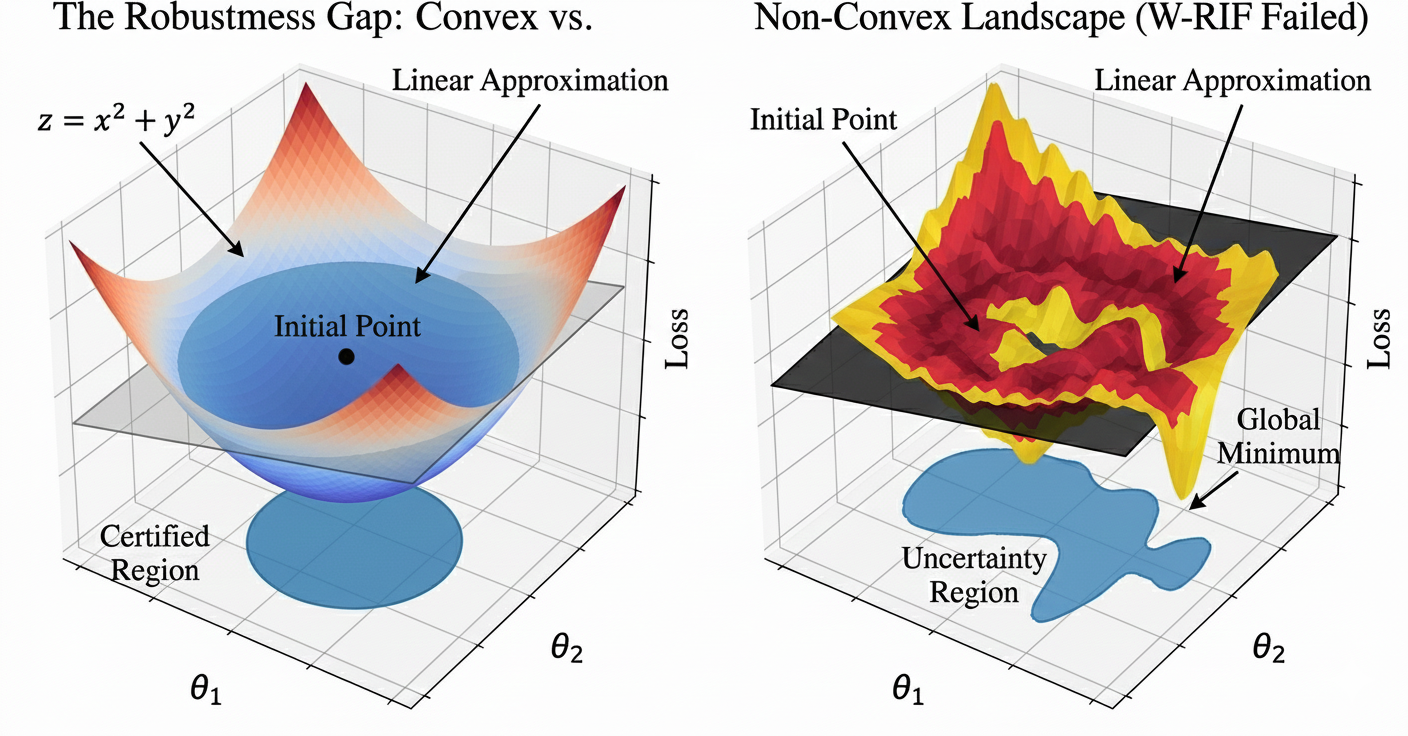
Influence functions and their scalable derivatives (e.g., TracIn, TRAK) have become critical tools for auditing and interpreting model behavior, yet their empirical reliability is undermined by sensitivity to small distributional perturbations. In both convex and non-convex regimes, perturbations in the training set can cause large, unpredictable shifts in influence rankings, complicating debugging and fair data valuation. While in convex optimization the loss landscape is well-behaved and distributional perturbations lead to smoothly varying solutions, deep networks introduce non-convexity and ill-conditioning, making linear approximations unreliable (Figure 1).
Figure 1: The geometry of convex vs. non-convex optimization landscapes and the effect of perturbations on certified robustness.
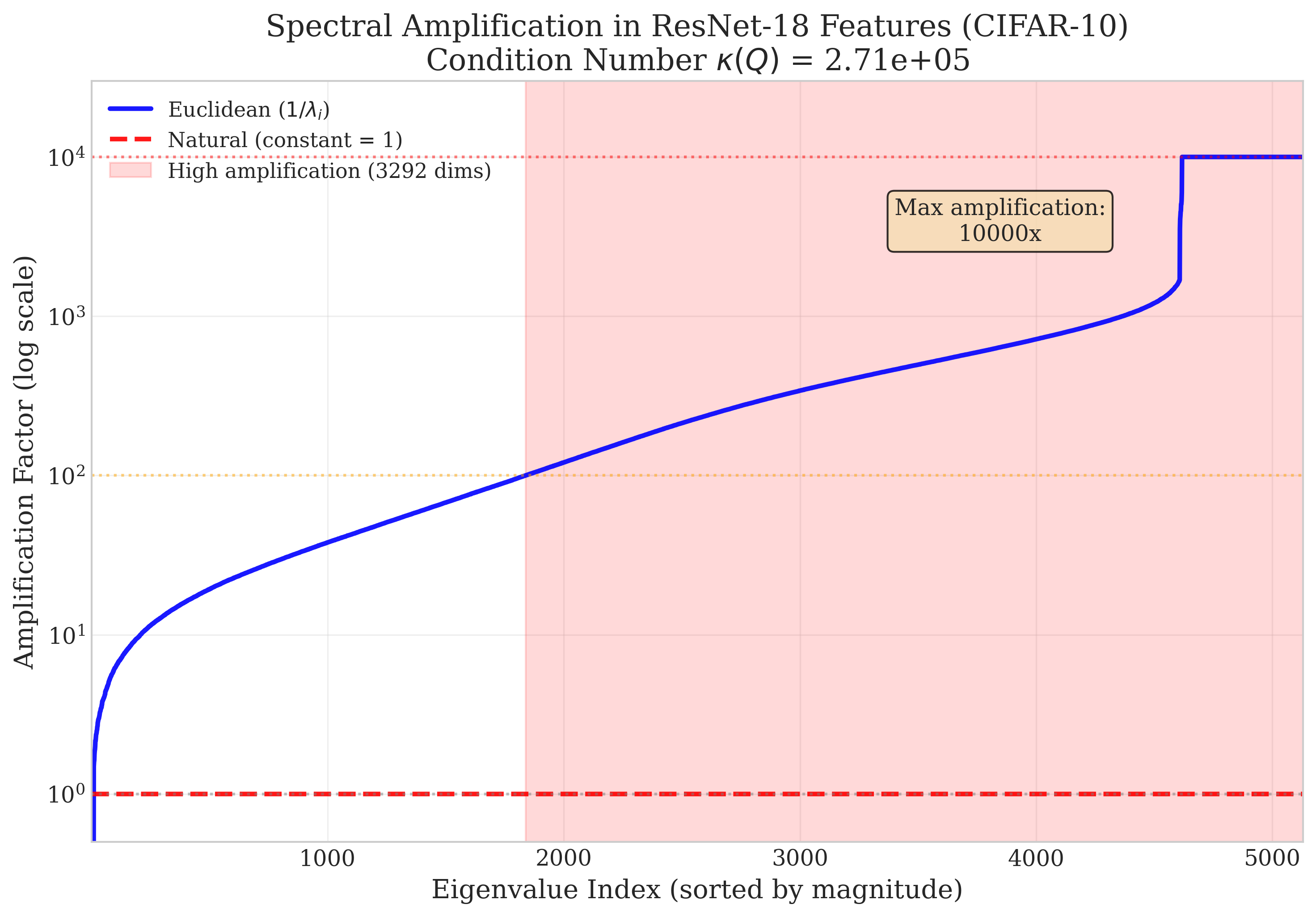
This fragility is theoretically characterized by the amplification of perturbations through the smallest eigenvalues of the feature covariance, making influence scores especially susceptible to noise or training set shifts in low-variance directions (Figure 2).
Figure 2: Illustrates the impact of spectral amplification on feature geometry; deep network features can have highly ill-conditioned covariance, inflating Lipschitz constants by orders of magnitude.
Robust Influence Functions for Convex Models
The paper provides a formal construction of Wasserstein-Robust Influence Functions (W-RIF) for convex models. By casting influence as a functional of the empirical distribution, the authors derive exact sensitivity kernels that capture changes in both the Hessian and gradient as the distribution is perturbed. The certified robust interval for each influence estimate is computed via duality arguments in the Wasserstein-1 metric, with closed-form expressions for the attainable range as a function of a computed Lipschitz constant. The method is validated to achieve tight coverage of true leave-one-out effects and to be computationally efficient when compared to naïve retraining.
The Spectral Amplification Barrier in Deep Networks
When generalizing to deep networks, the authors expose a critical failure mode: Euclidean-based certification yields intervals so large as to be vacuous. The crux of the problem is spectral amplification: the Euclidean Lipschitz constant for attribution scales as 1/λmin of the feature covariance Q, often resulting in factors exceeding 104 in practical models (e.g., ResNet-18 on CIFAR-10). This geometric mismatch is rigorously analyzed, showing that any perturbation along nearly null directions of Q is vastly amplified in the inverse, rendering Euclidean-based robustness analysis fundamentally unsuitable for neural architectures (Figure 2, Figure 3).
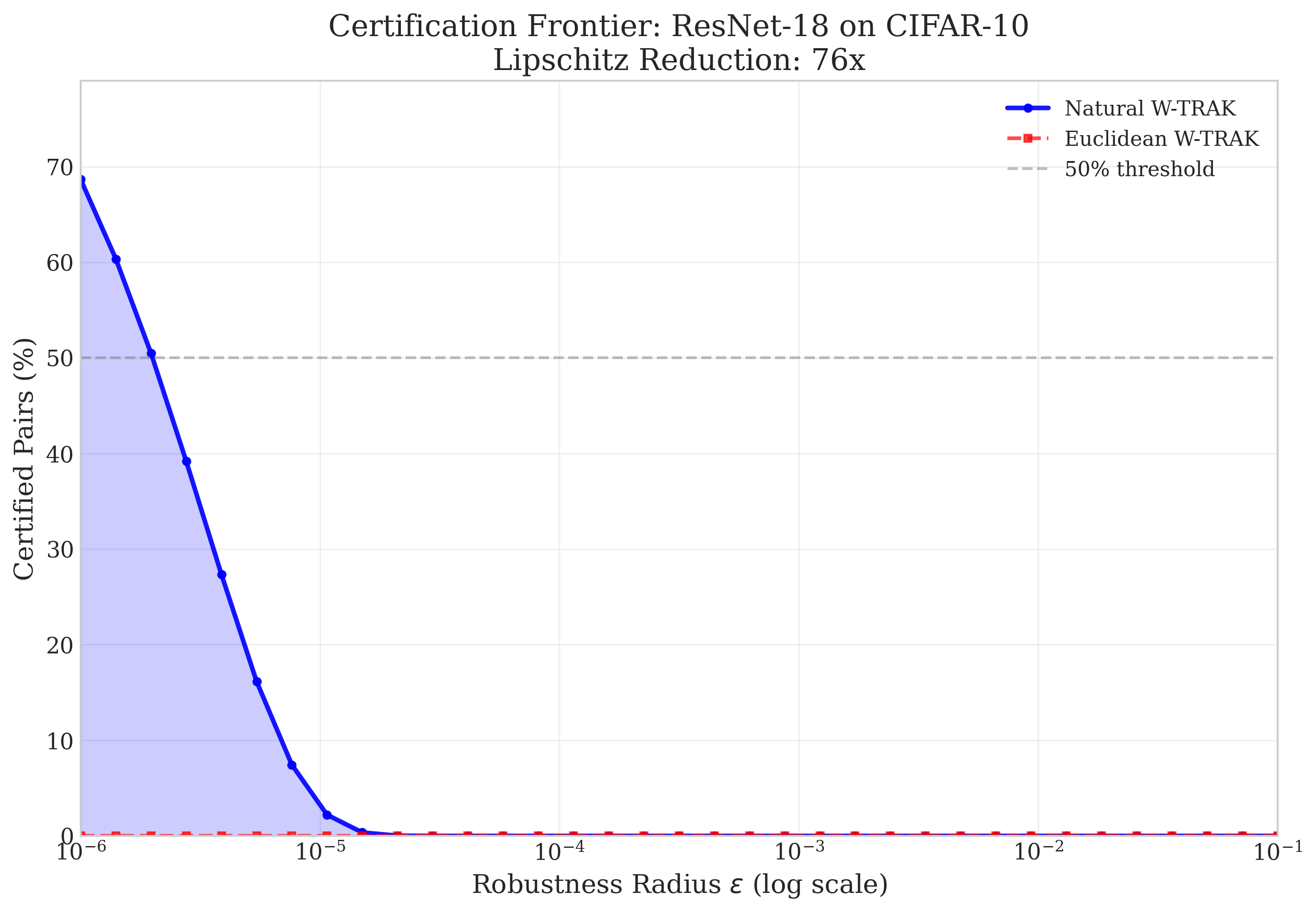
Figure 3: The certification frontier comparing Natural and Euclidean geometry. Natural W-TRAK allows nonvacuous certification of most ranking pairs, while Euclidean-based analysis cannot certify any.
Natural Wasserstein Metric: Geometric Alignment for Robust Certification
The main technical contribution of the paper is the proposal of the Natural metric: a Mahalanobis distance in feature space induced by the inverse of the feature covariance. This metric aligns the geometry of the uncertainty set with the sensitivity of the attribution functional, exactly counteracting the ill-conditioning effects of Q−1. Perturbations are naturally reweighted so that those corresponding to low-variance directions are penalized more heavily, neutralizing the effect of spectral amplification. Robust intervals computed under this metric are tight and interpretable, ensuring that certified stability is not an artifact of the feature space but a property of both the model and the data.
The authors formalize the Natural W-TRAK interval and analytically show that the ratio between Euclidean and Natural Lipschitz constants scales as κ(Q), with κ(Q) as the condition number of the feature covariance. Empirical evaluation shows up to 76× reduction in sensitivity, resulting in over two-thirds of ranking pairs being nonvacuously certifiable (Table 1, Figure 3).
Self-Influence as a Theoretically Justified Outlier and Instability Signal
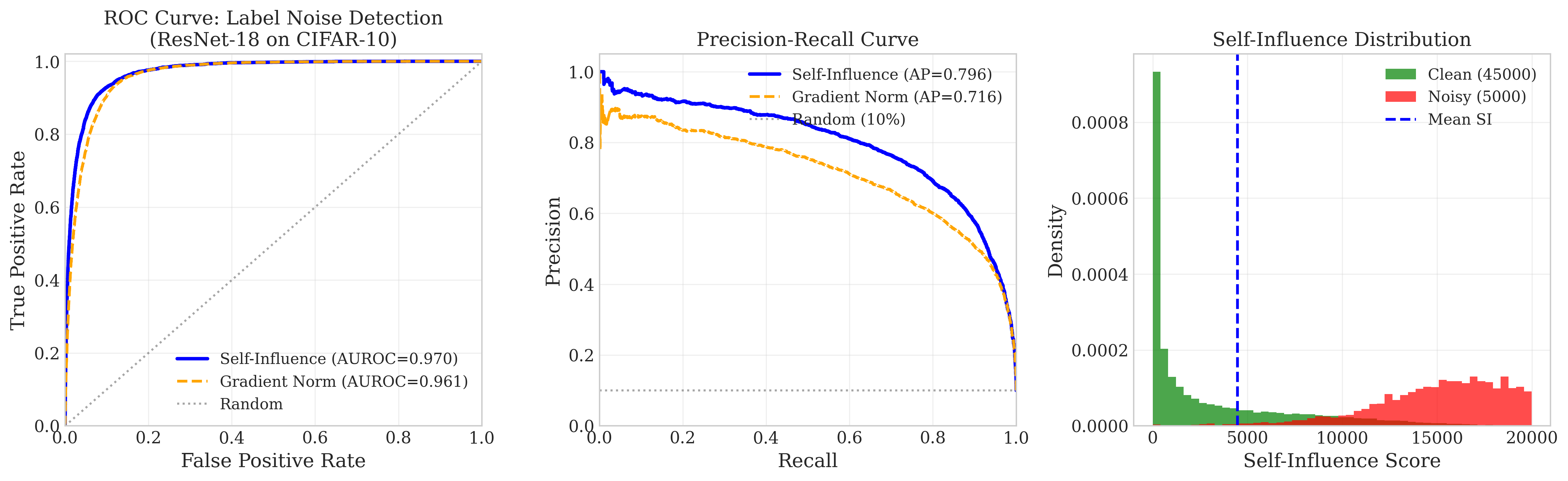
A significant finding is the theoretical grounding of Self-Influence (the leverage score ϕ(z)⊤Q−1ϕ(z)) as the precise Lipschitz constant that governs the stability of influence assignments under Wasserstein perturbations. High self-influence indicates geometric instability—points that are intrinsically difficult to certify as robust contributors to model predictions. This connection justifies the empirical use of leverage and influence for anomaly and noise detection. Empirical analysis on CIFAR-10, with 10% label noise, shows that Self-Influence achieves an AUROC of 0.970 for anomaly detection and recovers 94.1% of corrupted labels by thresholding on the top 20% of self-influence scores (Figure 4).
Figure 4: Self-Influence serves as a highly effective, theoretically grounded anomaly detector for mislabeled or corrupted training points.
Out-of-Distribution Behavior and Effectiveness
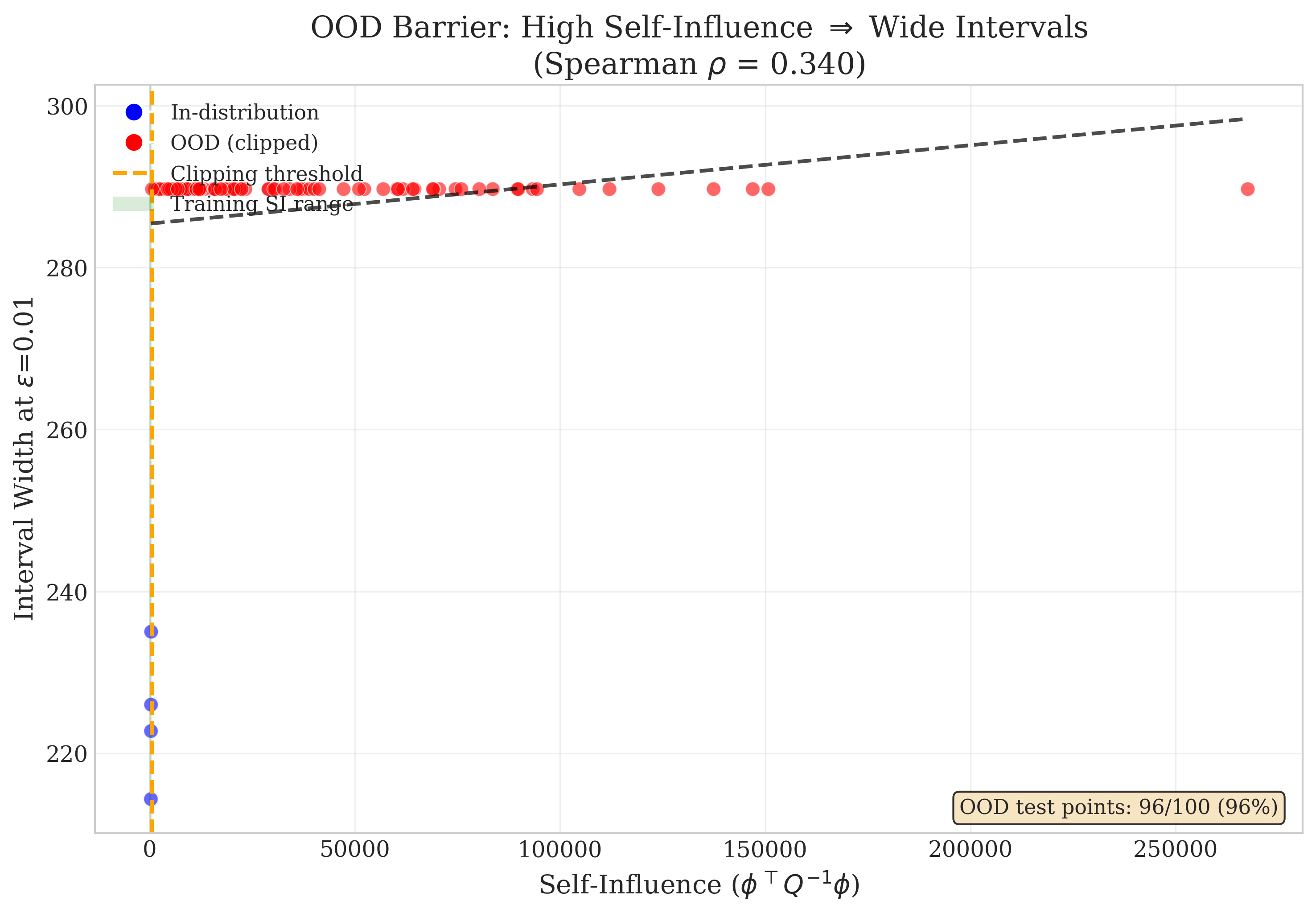
The framework also highlights inherent instability of influence for OOD points, demonstrated by inflated self-influence scores (Figure 5). This property is advantageous for practitioners—it provides a diagnostic for the reliability of data attribution in regions poorly covered by the training set.
Figure 5: Self-Influence scores signal OOD distance and the inherent instability of attribution for OOD queries.
Empirical Validation and Scaling
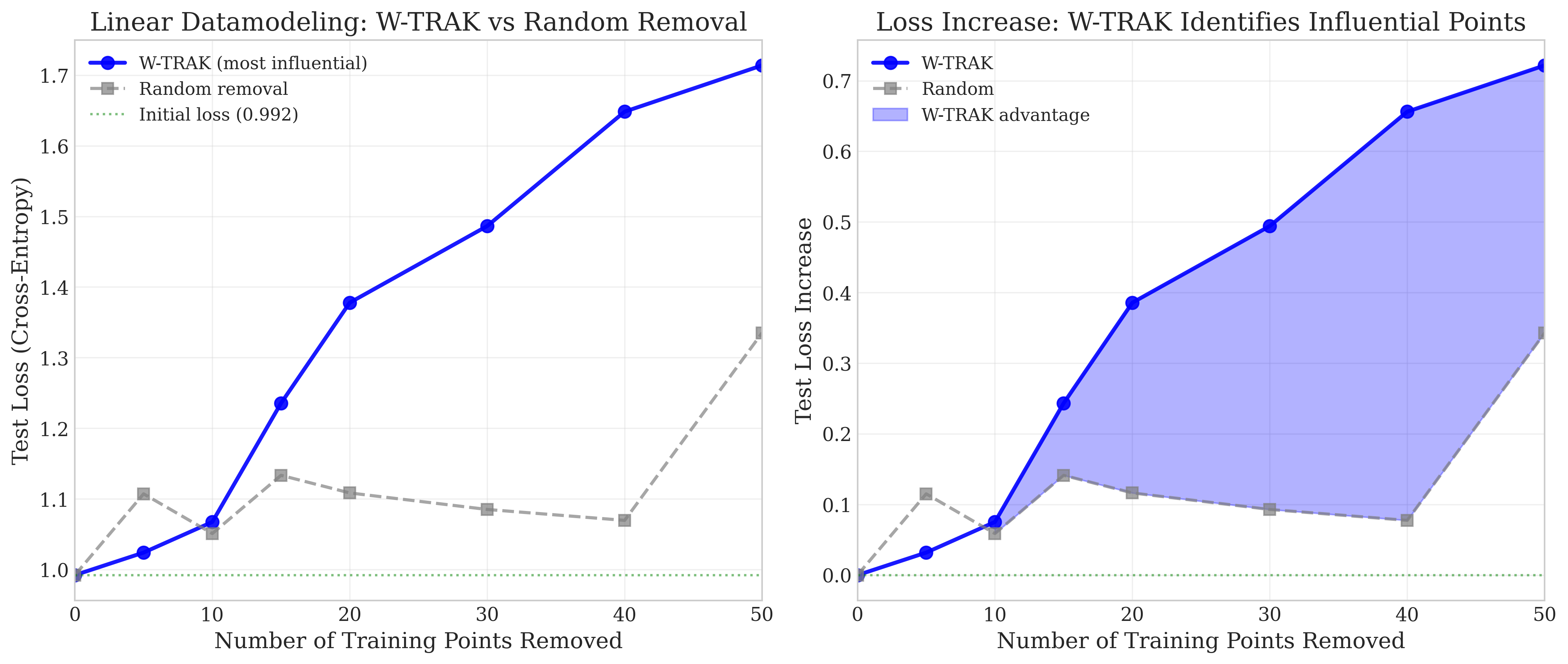
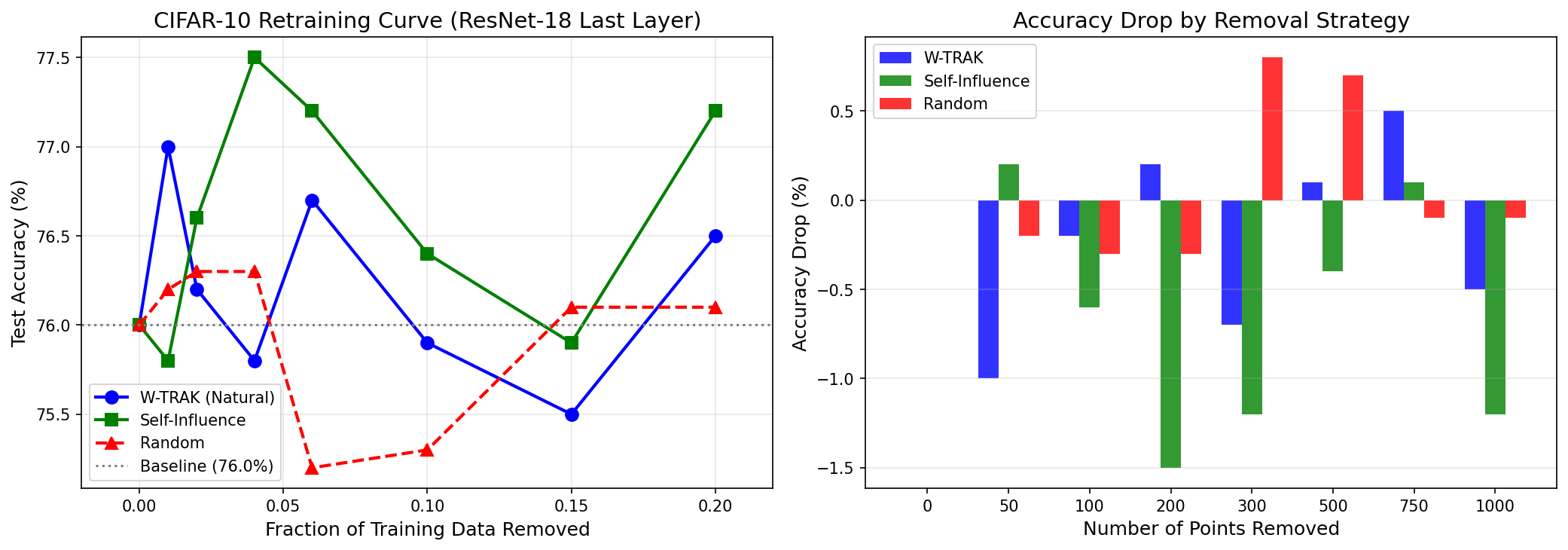
Across datasets, the method is validated not only via analytic robustness guarantees and anomaly detection but also by demonstrating that removal of high-W-TRAK points (those most certified to contribute to model predictions) systematically increases error rates in simple settings (Figure 6). On complex datasets (CIFAR-10), the removal of high-influence points often stabilizes accuracy, consistent with the notion that these points are outliers or mislabeled (Figure 7).
Figure 6: Removing W-TRAK-identified points increases test loss much faster than random removal in linear settings, validating accurate identification of influential examples.
Figure 7: In complex regimes, the removal of high-influence points stabilizes accuracy, suggesting that they often represent outliers or hard examples.
Implications and Future Directions
This work demonstrates the critical importance of geometric alignment in robust attribution. By realizing certified attribution intervals that are both feasible to compute and tight even in high-capacity neural networks, the framework has strong ramifications for data valuation, trustworthy auditing, and robust model deployment. Theoretical implications extend to bridging robust statistics and deep learning via DRO and data geometry. Practically, the method enables certified data debugging, reliable unlearning, and principled anomaly detection.
Future work may extend certification to more general attribution methods, handle large-scale models via low-rank or random projection schemes for Q−1, or explore adaptive metrics that account for non-stationary data at inference time.
Conclusion
The introduction of the Natural Wasserstein metric for influence certification resolves the fundamental instability introduced by spectral amplification in deep networks, yielding the first nontrivial certified robustness bounds for neural data attribution. The approach also justifies and strengthens the connection between leverage-based anomaly detection and theoretical robustness, opening new directions for both theoretical inquiry and practical reliability in model interpretation and data valuation.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.