Luxical: High-Speed Lexical-Dense Text Embeddings
Abstract: Frontier LLM quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end LLM data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at https://github.com/datologyai/luxical.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Luxical, a fast way to turn text into numbers (called “embeddings”) that computers can use to sort, search, and organize massive amounts of writing from the web. The goal is to keep the flexibility of modern “dense” embeddings (good for many tasks) while being as speedy as older “lexical” methods (which are fast but limited). The team also releases a specific model called Luxical-One and shows it can be much faster than popular neural models while keeping similar quality for large-scale data organization.
What questions does the paper try to answer?
Here are the main questions the paper explores:
- Can we make text embeddings that are fast enough to use on billions of web pages, but still good enough for tasks like clustering, retrieval, and filtering?
- Can a small, efficient model learn to “think” about similarity like a big transformer model, without being slow?
- In real tasks—like finding matching documents or building cleaner training sets for LLMs—does Luxical give good results compared to popular baselines?
How does Luxical work? (Explained simply)
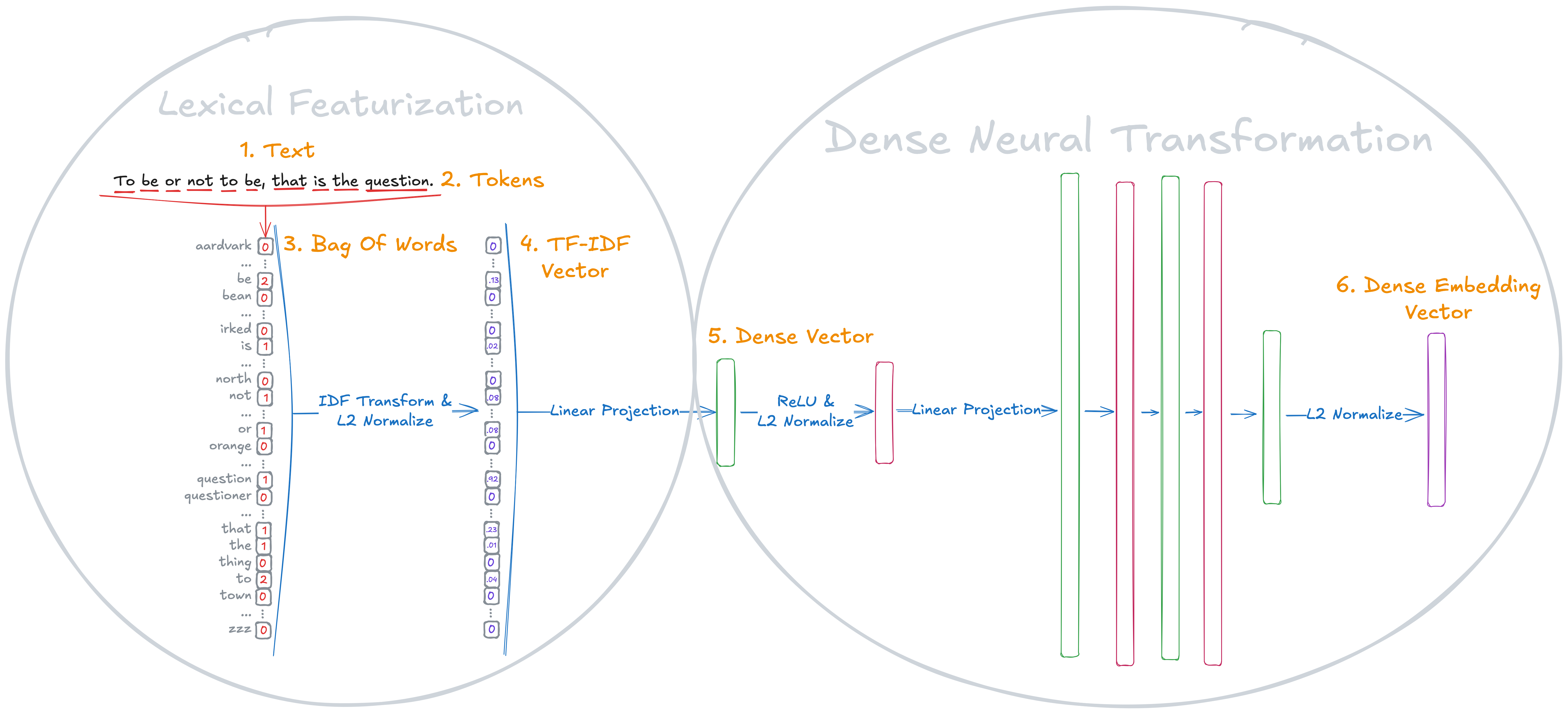
Think of Luxical as a three-step process that turns a document into a compact “meaning fingerprint” (a short list of numbers that captures what the text is about):
- Tokenize and count pieces of text:
- The text is broken into token pieces (like words or small word parts).
- It counts common patterns called “ngrams” (short sequences of tokens), especially 5-grams (chunks of five tokens).
- It uses TF–IDF weighting: Terms that are frequent in this document but rare across many documents get higher weight. A simple analogy: a unique word like “photosynthesis” says more about a science article than a super-common word like “the.”
- Make the features efficient:
- Because any single document uses only a tiny fraction of all possible ngrams, the feature vector is “sparse” (mostly zeros). Luxical exploits this sparsity to do fewer computations and run fast on CPUs.
- Turn sparse features into a dense embedding:
- A small neural network (an MLP with ReLU activations) compresses the sparse TF–IDF features into a short dense vector (the embedding).
- This vector is normalized so similar documents end up close together in this “embedding space.”
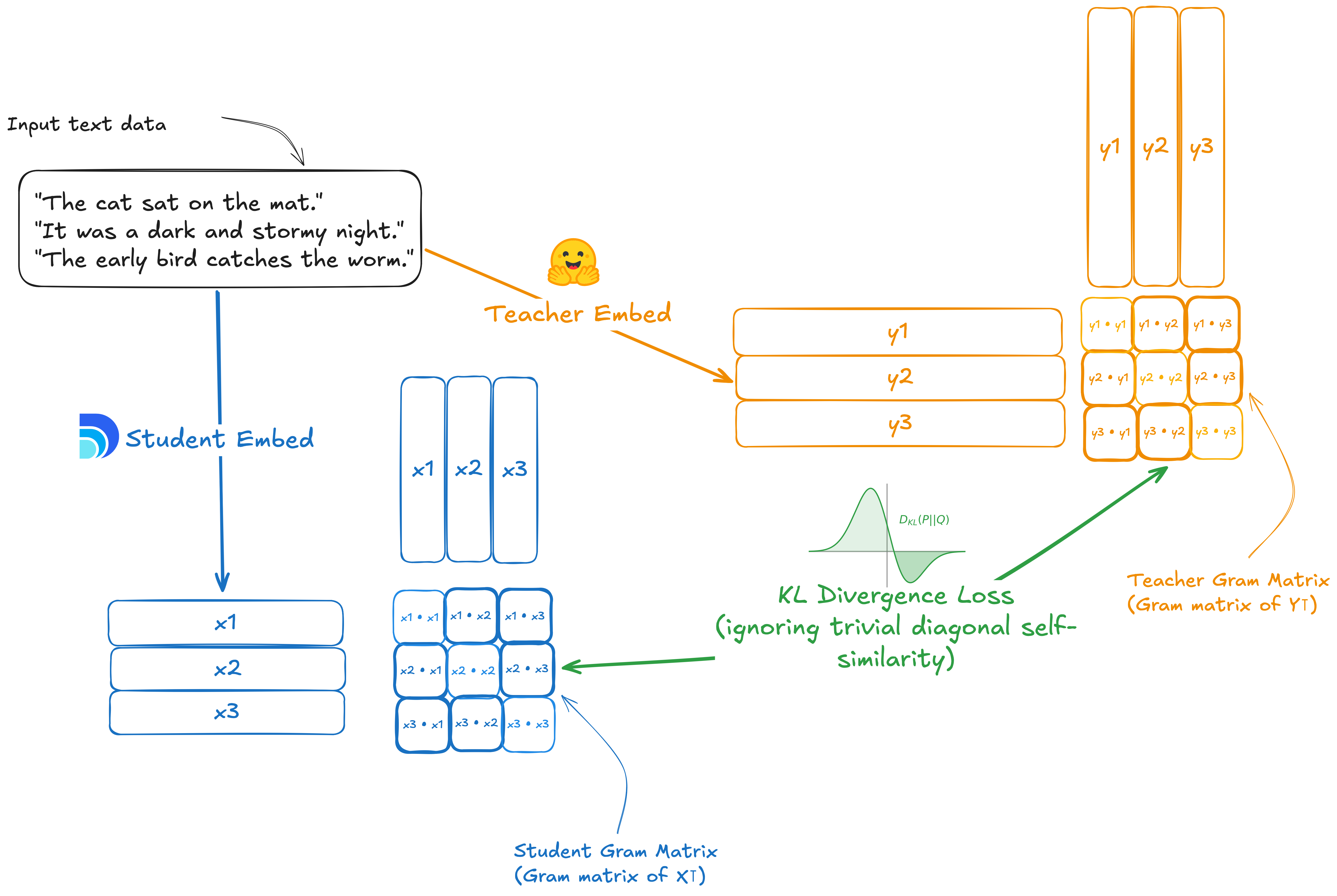
Training trick: distillation with similarity tables
- Luxical learns from a bigger, slower “teacher” model. For a batch of documents, both Luxical and the teacher produce embeddings.
- They build a “similarity table” (a Gram matrix) that shows how similar every document is to every other one in the batch.
- Luxical is trained to match the teacher’s similarity table. In everyday terms: Luxical learns the teacher’s sense of “what goes with what,” without needing to copy the teacher’s full complexity.
- A “temperature” setting smooths the similarity scores, making training more stable.
Engineering to make it fast:
- CPU-first design: optimized tokenization using a small Rust extension and PyArrow to avoid Python overhead.
- Efficient math with Numba for the sparse-to-dense step.
- In practice, tokenization is so fast that it becomes the main time cost; the neural part adds only a small overhead.
What did they find, and why does it matter?
The paper tests Luxical-One on two different types of tasks:
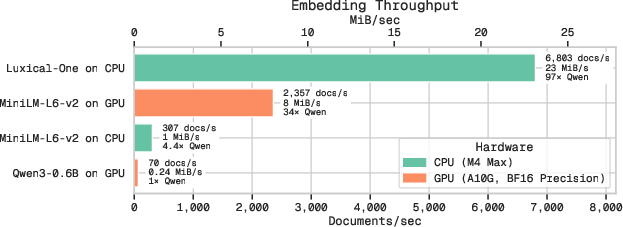
- Speed tests on 100,000 web documents:
- Luxical-One is dramatically faster—between 3x and 100x speedups compared to various transformer embedding models.
- Even GPU-accelerated transformer models are far slower than Luxical-One running on CPUs.
- This matters because real pipelines embed billions of documents once. Faster embedding saves a huge amount of compute time and money.
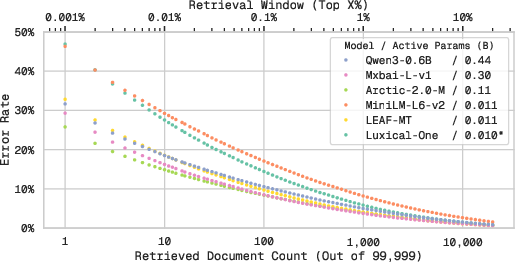
- Document-half matching (a clean retrieval test):
- Each web document is split into two halves; the goal is to find the matching half using embeddings.
- At strict top-1 ranking, big transformer models can do better. But as you allow a larger “top-k” window (e.g., top 10, top 100), Luxical-One catches up and beats small transformer baselines.
- This shows Luxical-One is good at “coarse” grouping: finding a reasonable set of close matches, which is exactly what many web-scale tasks need (like clustering and deduplication).
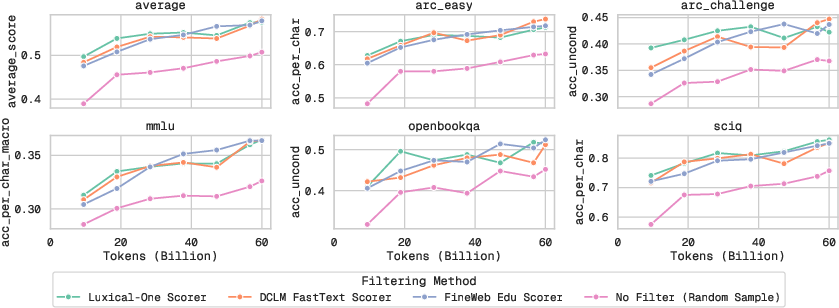
- Data curation for training LLMs (filtering high-quality text):
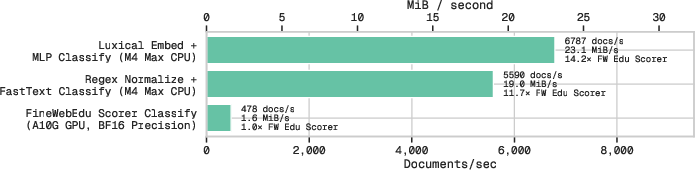
- They compare three ways to score and filter a huge web dataset down to a cleaner 10%:
- A transformer classifier (FineWeb-Edu): accurate but slow.
- A fast lexical classifier (FastText/DCLM): very fast.
- A small classifier on top of Luxical embeddings: very fast, similar to FastText.
- Results:
- Speed: Luxical-based filtering is about as fast as FastText and much faster than the transformer pipeline.
- Quality: All three curated datasets lead to similar downstream accuracy for a 3B-parameter LLM (and all beat an unfiltered baseline).
- Takeaway: Luxical delivers a strong speed–quality balance for building training sets, matching the utility of heavier models while running far faster.
Why is this important?
- Web-scale AI needs smart ways to pick and organize text from trillions of tokens. Doing this with slow models is expensive.
- Luxical gives you dense embeddings (useful across many tasks) at near-lexical speed.
- It’s a practical middle ground: flexible like transformers, fast like lexical methods.
- Because it’s CPU-friendly and open-source, teams can plug it into data pipelines without special hardware.
What are the limitations and where could this go next?
- Best for “coarse” tasks: grouping, clustering, deduplication, and broad filtering. If you need very fine-grained ranking or deep reasoning, big transformer encoders still win.
- Tested mainly in English and on web data; more languages and domains need study.
- Future ideas: multilingual Luxical, distilled variants, deeper integration with data curation tools, and links to newer “static embedding” approaches.
Bottom line
Luxical shows you don’t need a huge, slow model to get useful text embeddings for organizing the web. By counting smart token patterns and learning the teacher’s sense of similarity, Luxical-One runs 3x–100x faster than popular neural baselines while delivering strong enough quality for large-scale tasks like clustering and filtering. If you’re building big datasets or cleaning web text for training LLMs, Luxical is a simple, fast tool that can make your pipeline cheaper and more efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Coverage beyond English: The report evaluates a single English model (Luxical-One) trained on FineWeb; performance, vocabulary design, and tokenization efficacy for other languages (especially morphologically rich and non-Latin scripts) are untested.
- Domain generalization: The fixed 5-gram vocabulary mined from FineWeb may not transfer to domains like scientific text, code, legal text, or social media; systematic evaluation and adaptation strategies (e.g., domain-specific vocabulary mining, mixed-domain vocabularies) are absent.
- Asymmetric retrieval and search: The paper focuses on symmetric document–document similarity; performance on asymmetric retrieval (query→document), precise ranking, and real search workloads (e.g., Recall@k, MRR, NDCG on standard datasets) remains unknown.
- Benchmarking on standard suites: No results on MTEB or other widely used embedding benchmarks (e.g., STS, classification, reranking, multilingual retrieval) to quantify general-purpose utility and trade-offs relative to transformer baselines.
- Clustering and dedup metrics: While Luxical is motivated for clustering and semantic deduplication, there are no quantitative cluster quality measures (e.g., silhouette, NMI) or dedup efficacy metrics on large corpora (e.g., SemDeDup-like evaluations).
- Long-document handling: The document-half matching proxy may favor lexical overlap; evaluation on long-document tasks (e.g., whole-article retrieval, section linking, multi-page documents) with realistic ground truth is missing.
- Vocabulary design ablations: The choice of 5-grams (vs. uni/bi/tri-grams, mixed n-grams, subword or character n-grams) and vocabulary size (2M) is not analyzed; ablations on n-gram length, vocabulary size, and selection algorithms (e.g., hashing trick vs. exact) are needed.
- OOV and drift: There is no strategy for out-of-vocabulary coverage, vocabulary updates, or IDF recalibration under domain shift, time drift, or multilingual corpora; incremental/online updating methods are unexplored.
- IDF estimation robustness: IDF is log-scaled using approximate counts from a sample; sensitivity to sampling choices, corpus size, and updates (and whether merging IDF into the first layer changes training stability) is not studied.
- Architecture ablations: The MLP’s layer widths (92→3072→3072→192), ReLU choice, and L2 normalization after each projection are not justified by experiments; alternative nonlinearities, residual connections, dimensionality–quality curves, and Matryoshka-style multi-resolution embeddings are not explored.
- Distillation objective analysis: The Gram-matrix KL objective (with diagonal removed) lacks ablations versus other distillation losses (e.g., InfoNCE, triplet, cosine regression, teacher-pair contrastive), temperature sensitivity studies, batch-size effects, and convergence diagnostics.
- Teacher selection: Only one teacher (Arctic-2.0-M v2.0 family) is used; effects of teacher quality, dimensionality (e.g., 256 vs. other sizes), multilingual teachers, multi-teacher distillation, and teacher ensemble averaging are open questions.
- Embedding dimensionality trade-offs: The student’s 192-dim output is fixed; a systematic study of dimension vs. quality and speed (including matryoshka truncations and task-specific dimensionality) is absent.
- Throughput scaling: Benchmarks are limited to an Apple M4 Max CPU and an NVIDIA A10G GPU; multi-core scaling behavior, NUMA effects, vectorization, distributed CPU clusters, I/O bottlenecks, and tokenization throughput under varied document lengths are not profiled.
- Memory footprint and precision: The first projection (V=2M to d=92) implies large parameter matrices; memory use, load times, cache behavior, and gains from quantization/low-precision (e.g., int8, float16) are not reported.
- Tokenization bottleneck: Tokenization dominates runtime; alternatives (e.g., faster C++ backends, sentencepiece variants, character-level pipelines, mixed granularity tokenizers) and their impact on end-to-end throughput are not evaluated.
- Integration with sparse methods: The hybrid “lexical-dense” approach is not compared to modern sparse methods (BM25/SPLADE) in first-stage retrieval or fusion (e.g., hybrid search combining Luxical dense with inverted index), leaving deployment guidance incomplete.
- ANN indexing behavior: The distributional geometry of Luxical embeddings under approximate nearest neighbor indexing (e.g., HNSW, IVF) and corresponding quality–latency trade-offs are not analyzed.
- Filtering pipeline generality: Classifier-based filtering uses a single 10% cut on FineWeb with a 3B LM downstream; sensitivity to selection rates, label sources, model sizes (e.g., 1B–70B), training schedules, and combined dedup+filtering recipes remains unexplored.
- Bias, safety, and toxicity: No assessment of whether Luxical embeddings facilitate or hinder detection of harmful content, demographic biases, or unsafe data, nor evaluation vs. transformer baselines on safety-focused filters.
- Robustness to adversarial or noisy inputs: Effects of spam, boilerplate, templated pages, HTML markup, multilingual fragments, code blocks, and OCR noise on embedding reliability and speed are not measured.
- Reproducibility artifacts: The paper does not detail release of the mined 5-gram vocabulary, IDF statistics, and exact training corpus identifiers, making precise reproduction of Luxical-One’s preprocessing and training harder.
- Energy and cost metrics: End-to-end cost and energy comparisons (CPU-only Luxical vs. GPU-based transformers) across realistic data volumes are not provided, limiting operational planning.
- Maintenance and updating: Strategies for refreshing vocabularies/IDF, retraining with new teachers, continual distillation, and backward compatibility of embeddings over time are not discussed.
- Security and privacy: The implications of embedding web-scale corpora for PII exposure, re-identification risks, and compliance (e.g., GDPR/CCPA) in data organization pipelines are not addressed.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now with the open-source Luxical library and the released English model “luxical-one,” especially in settings that need coarse-grained, symmetric similarity at high throughput on CPU.
- Industry | Software/AI Infrastructure: Web-scale LLM data curation backbones
- Use Luxical as the first-stage embedding pass over crawled text to support semantic deduplication, clustering, and quality-based filtering before LLM training.
- Tools/workflow: Luxical (GitHub), DatologyAI/luxical-one (Hugging Face), batch CPU embedding; build ANN indices with FAISS/ScaNN/Milvus/Qdrant; train lightweight MLP classifiers on top of Luxical embeddings.
- Benefits: 3x–100x throughput vs transformer encoders; comparable to FastText throughput with dense-embedding flexibility; coarse-grained quality comparable to neural baselines in tested settings.
- Assumptions/dependencies: English documents; tasks emphasize symmetric document–document similarity; thresholding and classifier calibration needed; quality depends on teacher model and domain match.
- Industry | Search & Content Platforms: Two-stage retrieval (fast candidate generation + neural re-rank)
- Use Luxical for offline embedding of large document collections and ANN-based candidate generation; re-rank top-K with a stronger transformer (e.g., MiniLM/Qwen) to achieve high precision.
- Tools/workflow: Luxical embeddings + FAISS for first-stage recall, transformer re-ranker for precision; integrates with Vespa, Elasticsearch vector modules, or custom services.
- Benefits: Lower latency and compute cost for first-stage recall; CPU-only deployment for the first pass.
- Assumptions/dependencies: Coarse recall acceptable in stage one; English content; extra infrastructure for re-ranking.
- Industry | Data Governance & Compliance: High-throughput pre-filtering
- Embed corpora and run small MLPs to flag low-quality, policy-violating, or off-scope content at crawl-time or import-time, before heavier analysis or human review.
- Tools/workflow: Luxical embeddings + shallow MLPs trained on policy labels; combine with regex/NER for PII detection.
- Benefits: Order-of-magnitude faster than transformer classifiers while retaining flexibility beyond single-score lexical models.
- Assumptions/dependencies: Labeled examples for policy categories; operational thresholds; periodic re-training for drift.
- Industry | UGC Platforms: Semantic deduplication and near-duplicate clustering
- Reduce spam, link-farm content, and low-value duplicates by maintaining a CPU-built embedding index for fast near-duplicate detection.
- Tools/workflow: Luxical embeddings + cosine similarity thresholds; LSH/ANN; dedup queues integrated into moderation or ingestion pipelines.
- Benefits: Substantial CPU cost savings and throughput gains on at-scale pipelines.
- Assumptions/dependencies: English-heavy streams; duplicates predominantly lexical/semantic rather than multimodal; tuned thresholds.
- Industry | Analytics/Marketing: Topic discovery over large text streams
- Cluster product reviews, support tickets, or survey responses to summarize themes and track issue trends.
- Tools/workflow: Luxical embeddings + KMeans/HDBSCAN; optional small MLP for sentiment/quality labels.
- Benefits: Faster iteration and re-scoring without recomputing embeddings.
- Assumptions/dependencies: Coarse clusters acceptable; English text; periodic recalibration if product taxonomy changes.
- Industry | Legal/eDiscovery: Early case assessment and triage
- Quickly cluster and deduplicate email corpora and documents to prioritize review batches.
- Tools/workflow: On-prem CPU deployment with Luxical; FAISS/Annoy for clustering; export cluster summaries for counsel.
- Benefits: CPU-only, privacy-preserving processing; faster turnaround for early assessment.
- Assumptions/dependencies: English-centric collections; legal constraints on data handling; human-in-the-loop validation.
- Academia | Corpus building and exploratory analysis
- Rapidly embed large public corpora to perform dataset deduplication, domain slicing, and distribution analysis.
- Tools/workflow: Luxical + Hugging Face Datasets; FAISS for nearest-neighbor exploration; lightweight classifiers for custom filters.
- Benefits: Enables multi-pass reuse of a single embedding stage for multiple downstream analyses.
- Assumptions/dependencies: Alignment between teacher domain and target corpus; English language focus.
- Academia/Education | Open Educational Resource (OER) mining
- Reproduce a FineWeb-Edu-style scorer using MLPs on Luxical embeddings to rank web documents by educational quality.
- Tools/workflow: Luxical + small MLP; labels from rubric-based annotation or LLM-assisted rating; batch CPU scoring.
- Benefits: Comparable downstream quality to transformer baselines with much higher throughput.
- Assumptions/dependencies: Availability of labels for “educational” vs. not; ongoing validation to avoid bias.
- Policy/Government | Web archives triage and harmful-content monitoring
- Triage large crawls for topic- or risk-aware auditing; prioritize subsets for human review.
- Tools/workflow: Luxical embeddings + classifiers for risk categories; cluster sampling for coverage.
- Benefits: CPU deployability on public-sector infrastructure; throughput suitable for national archives or regulatory crawls.
- Assumptions/dependencies: English content predominance; clear escalation paths to human review; transparent governance.
- Daily Life/SMEs | Document and email dedup/search without GPUs
- For small businesses and personal knowledge bases, embed and cluster documents on laptops to reduce clutter and improve search.
- Tools/workflow: Luxical CLI or simple Python scripts; SQLite + FAISS; cron-based incremental indexing.
- Benefits: Private, on-device processing; usable with commodity CPUs.
- Assumptions/dependencies: Primarily English documents; disk budget for storing vectors; basic ops know-how.
- Industry & Academia | Iterative labeling and scoring loops
- Decouple a one-time embedding pass from repeated, fast MLP experiments for scoring/labeling, speeding up research and production iteration.
- Tools/workflow: Persist Luxical embeddings; run rapid MLP training/evaluation cycles; integrate with hyperparameter search.
- Benefits: Embedding cost amortized; sub-second scoring over large batches in subsequent iterations.
- Assumptions/dependencies: Stable feature space; careful tracking/versioning of embeddings.
Long-Term Applications
Below are applications that are plausible extensions but require further research, training, or scaling (e.g., new vocabularies, multilingual teachers, domain-specific distillation, or productization).
- Multilingual Luxical for global deployments (Industry, Academia, Policy)
- Train Luxical with multilingual tokenizers and vocabularies; distill from multilingual teachers (e.g., Arctic-Embed 2.0).
- Potential: Cross-lingual dedup, clustering, and candidate retrieval worldwide; government archival processing across languages.
- Dependencies: Multilingual training data; per-language n-gram vocab and IDF; teacher coverage; evaluation sets.
- Domain-specific Luxical variants (Healthcare, Legal, Finance)
- Build specialized vocabularies and distill from domain encoders to handle jargon, abbreviations, and compliance taxonomies.
- Potential: Clinical literature triage, legal discovery at scale, financial filings clustering/risk scanning.
- Dependencies: High-quality domain data and labels; domain teacher models; strict privacy/compliance validation.
- Hybrid sparse+dense search engines (Software/Search)
- Fuse Luxical embeddings with BM25/SPLADE signals for first-stage retrieval, balancing lexical exact-match and semantic recall.
- Potential: More robust recall under misspellings/variants, reduced dependence on GPU-heavy rerankers.
- Dependencies: Fusion training/tuning; evaluation frameworks; pipeline integration.
- On-device/edge inference for privacy-preserving analytics (Daily Life, IoT, Mobile)
- Optimize Luxical for laptops/phones/gateways to cluster transcripts, notes, or logs locally.
- Potential: Personal knowledge management, offline spam pre-filtering, and SME privacy-preserving analytics.
- Dependencies: Memory/latency optimization, quantization, Rust tokenizer ports to mobile, power constraints testing.
- Streaming web-crawl indexing and real-time dedup (Industry, Policy)
- Incremental embedding and ANN maintenance to dedup and route content as it arrives.
- Potential: Lower storage and compute for web crawlers; faster feedback loops for data quality in LLM pipelines.
- Dependencies: Robust streaming tokenization/aggregation; index maintenance; concept-drift handling.
- Training-time dynamic data selection for LLMs (Software/AI Infrastructure)
- Use Luxical similarity to sample batches on-the-fly that match desired distributions (curriculum learning, decontamination).
- Potential: Better data efficiency; improved scaling via data-aware training.
- Dependencies: Tight coupling to training infra; low-latency data services; rigorous ablation/evaluation.
- Code, logs, and semi-structured text variants (Software/DevOps)
- Adapt tokenization/vocab to code/logs; distill from code/log teachers to cluster similar stack traces or code snippets.
- Potential: Faster incident triage, root-cause clustering, and developer knowledge-base dedup.
- Dependencies: Appropriate tokenizers (subword or language-specific), curated training corpora, domain labels.
- Retrieval-augmented generation (RAG) pipelines with CPU-first stages (Software, Education, Enterprise)
- CPU Luxical for building document indices and first-stage retrieval in RAG; heavy rerankers only on narrowed candidates.
- Potential: Lower infra costs for medium-scale deployments; easier on-prem integrations.
- Dependencies: Document chunking and index design; trade-off studies on recall vs. latency; English limitations.
- Risk and safety analytics at scale (Policy, Platforms)
- Combine Luxical with safety-tuned MLPs to monitor large corpora for misinformation categories, extremism, or harmful trends.
- Potential: High-throughput triage for regulators or platforms; targeted human audits.
- Dependencies: High-quality, robust safety labels; bias auditing and governance; multilingual expansion.
- Energy- and cost-aware data pipelines (Cross-sector)
- Replace GPU-heavy embedding passes with CPU-friendly Luxical to reduce energy use and cost in ETL and indexing pipelines.
- Potential: Lower operational carbon footprint and TCO for recurring data processing jobs.
- Dependencies: Org-level SRE integration; cost/energy metering; acceptance that some fine-grained precision shifts to later stages.
Notes on Feasibility and Constraints
- Strengths to leverage now: CPU throughput; coarse symmetric similarity; ability to reuse one embedding pass across multiple tasks; simple deployment (Rust tokenizer + Numba kernels).
- Limitations to account for: English-only model release; less suitable for fine-grained ranking and reasoning-heavy tasks; quality tied to teacher model and domain; tokenization can dominate runtime; careful thresholding and evaluation necessary in high-stakes settings (healthcare, finance, policy).
- Typical toolchain integrations: FAISS/ScaNN/Milvus/Qdrant for ANN; Spark/Dask/Ray for distributed embedding; vector stores (e.g., Elasticsearch/OpenSearch vector modules, Vespa); small MLPs for fast classifiers; governance dashboards for monitoring.
Glossary
- AdamW optimizer: An Adam variant with decoupled weight decay that improves regularization during training. "We use the AdamW optimizer \citep{adamw} in a warmup-stable-decay learning rate schedule reaching a peak learning rate of 7e-4 with a global batch size of 576."
- arrow-tokenize extension: A custom Rust-based tokenizer that returns Arrow arrays to reduce Python garbage collection overhead at scale. "This arrow-tokenize extension mitigates Python garbage collection overhead by returning tokenized outputs as PyArrow arrays that garbage collect much faster than Python list-of-list outputs."
- Asymmetrical and symmetrical retrieval tasks: Retrieval settings where query and candidate representations differ (asymmetrical) or share the same form (symmetrical). "producing representations suitable to a blend of asymmetrical and symmetrical retrieval tasks"
- bag-of-ngrams: A sparse lexical representation counting occurrences of contiguous token sequences (n-grams). "similar to the bag-of-ngrams featurization in FastText \citep{joulin2017bag}, but eschewing the hashing trick in favor of exact ngram matching over a predetermined vocabulary of ngrams."
- BERT uncased tokenizer: The lowercase wordpiece tokenizer used by BERT models. "The model adopts the BERT uncased tokenizer to segment input text"
- BM25: A probabilistic information retrieval ranking function that scores term matches with length and saturation adjustments. "Lexical and sparse retrieval methodsâranging from TF--IDF and BM25 to more recent models such as SPLADEâexploit term-level structure to achieve strong ranking performance with inverted indexes"
- contrastive distillation loss: A training objective that aligns student embeddings with teacher-induced similarities via contrastive signal. "Contrastive distillation loss recommended when training Luxical models."
- cosine similarities: A similarity metric measuring the cosine of the angle between vectors. "For a given query half, we compute cosine similarities to all 99{,}999 other halves and rank them."
- FastText: A lightweight bag-of-ngrams lexical model for efficient text classification. "lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores"
- Gram-matrix distillation: Training that matches the student’s pairwise similarity (Gram) matrix to that of a teacher model. "use a Gram-matrix distillation objective that pushes the embedding geometry to match the similarity structure of a larger teacher embedding model"
- hashing trick: Mapping features to a fixed-size index via hashing instead of maintaining an explicit vocabulary. "but eschewing the hashing trick in favor of exact ngram matching over a predetermined vocabulary of ngrams."
- inverted indexes: Data structures mapping terms to postings lists for fast lexical retrieval. "achieve strong ranking performance with inverted indexes"
- knowledge distillation: Training a smaller student model to mimic a larger teacher model’s behavior or representations. "a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost."
- Kullback–Leibler divergence: An information-theoretic measure quantifying the difference between two probability distributions. "we minimize a KullbackâLeibler divergence the rows of the diagonal-stripped Gram matrices:"
- Massive Text Embedding Benchmark (MTEB): A standardized suite for evaluating text embedding models across diverse tasks. "benchmarks such as the Massive Text Embedding Benchmark (MTEB) \citep{muennighoff-etal-2023-mteb}"
- MinHash-based deduplication: A technique using MinHash signatures to identify near-duplicate documents efficiently. "Early corpora such as the Colossal Clean Crawled Corpus (C4) used heuristic language identification, blocklists, and MinHash-based deduplication to turn Common Crawl into a usable training set"
- Multi-Layer Perceptron (MLP): A feed-forward neural network with one or more hidden layers and nonlinear activations. "which we also refer to as a Multi-Layer Perceptron or MLP for short"
- nearest-neighbor search: Retrieving the closest vectors under a chosen metric for clustering or similarity tasks. "Geometric methods such as clustering and nearest-neighbor search can operate directly on Luxical embeddings"
- Numba: A just-in-time compiler for Python that accelerates numerical kernels on CPUs. "Luxical implements this operation with Numba-optimized kernels \citep{lam2015numba} to achieve high throughput on CPUs."
- PyArrow arrays: Columnar in-memory data structures enabling efficient cross-language data exchange and fast garbage collection. "returning tokenized outputs as PyArrow arrays that garbage collect much faster than Python list-of-list outputs."
- ReLU: The Rectified Linear Unit activation function that outputs max(0, x). "a small ReLU network"
- semantic deduplication: Removing duplicate or highly similar content based on meaning rather than exact lexical overlap. "semantic deduplication \citep{abbas2023semdedupdataefficientlearningwebscale} across billions of documents."
- Space-Saving Algorithm: A streaming frequent-item algorithm with bounded memory for estimating item frequencies. "we used the Space-Saving Algorithm \citep{spacesavingalgorithm} to identify a vocabulary two million (approximately) most frequent 5-grams"
- SPLADE: A sparse lexical expansion model that scores term importance for retrieval within a transformer framework. "ranging from TF--IDF and BM25 to more recent models such as SPLADEâexploit term-level structure"
- temperature scaling: Adjusting similarity or logit magnitudes by a temperature parameter to control distribution sharpness. "After temperature scaling (denoting the temperature hyperparameter as )"
- term-frequency–inverse-document-frequency (TF–IDF): A weighting scheme combining term frequency with inverse document frequency to emphasize informative terms. "map this sparse term-frequency-inverse-document-frequency (TF--IDF) representation to a dense, normalized embedding."
Collections
Sign up for free to add this paper to one or more collections.

