Generation is Required for Data-Efficient Perception
Abstract: It has been hypothesized that human-level visual perception requires a generative approach in which internal representations result from inverting a decoder. Yet today's most successful vision models are non-generative, relying on an encoder that maps images to representations without decoder inversion. This raises the question of whether generation is, in fact, necessary for machines to achieve human-level visual perception. To address this, we study whether generative and non-generative methods can achieve compositional generalization, a hallmark of human perception. Under a compositional data generating process, we formalize the inductive biases required to guarantee compositional generalization in decoder-based (generative) and encoder-based (non-generative) methods. We then show theoretically that enforcing these inductive biases on encoders is generally infeasible using regularization or architectural constraints. In contrast, for generative methods, the inductive biases can be enforced straightforwardly, thereby enabling compositional generalization by constraining a decoder and inverting it. We highlight how this inversion can be performed efficiently, either online through gradient-based search or offline through generative replay. We examine the empirical implications of our theory by training a range of generative and non-generative methods on photorealistic image datasets. We find that, without the necessary inductive biases, non-generative methods often fail to generalize compositionally and require large-scale pretraining or added supervision to improve generalization. By comparison, generative methods yield significant improvements in compositional generalization, without requiring additional data, by leveraging suitable inductive biases on a decoder along with search and replay.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but big question: If we want machines to “see” the world as well as people do, do they need to be able to “generate” images in their mind? The authors argue yes. They show that to be data-efficient (learning well from limited examples) and to handle new combinations of things you’ve never seen together before, a generative approach is needed. They back this up with theory and experiments on realistic images.
Key ideas in everyday language
Before diving in, here are a few friendly definitions:
- Encoder vs. decoder:
- An encoder is like a “labeler” that looks at a picture and quickly assigns internal codes to what’s in it.
- A decoder is like a “simulator” that takes internal codes and can draw the picture they represent.
- Generative vs. non-generative:
- Generative approaches use a decoder and then work backwards (invert it) to figure out the hidden “recipe” of the image.
- Non-generative approaches skip the simulator and use an encoder to jump straight from image to internal codes.
- Latent variables:
- These are the hidden pieces of information (like Lego pieces) that, when put together, create the full picture. The paper calls these “slots” (for example, one slot might be the animal, another the background).
- In-domain (ID) vs. out-of-domain (OOD):
- ID means combinations you saw during training (like “dog in house” if you trained on that).
- OOD means new combinations you didn’t see before (like “dog in park” or “penguin in desert”).
- Compositional generalization:
- The ability to understand a new scene made from known parts in a new combination, even if you never saw that combo before.
Objectives and research questions
The paper sets out to answer:
- Can non-generative methods (just encoders) reach human-like data efficiency and compositional generalization?
- Or do we need generative methods (using a decoder and inverting it) to get there?
- What kinds of built-in assumptions or “inductive biases” are required for each approach to work out-of-domain?
- Practically, how can we invert a decoder efficiently to handle new combinations?
Approach and methods
Theoretical approach
The authors build a mathematical model of how images are created from hidden parts (slots), and study what must be true for a model to correctly handle new combinations of these parts.
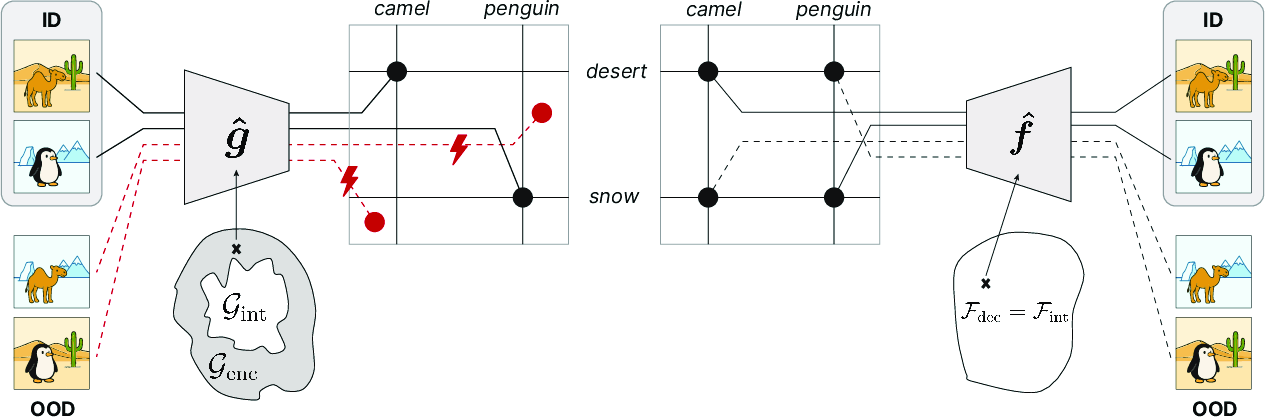
- They assume a “compositional generator”: a decoder that combines slots (like objects and backgrounds) into an image. It allows different degrees of interaction (like simple addition or more complex mixing).
- They define a class of “good” decoders that are structured so that, if your model learns them, you can recover the slots from both ID and OOD images.
- Key result: It’s straightforward to force a decoder to have this “good” structure using architecture design or regularization (you can build your simulator to obey certain rules). But it’s generally infeasible to force an encoder to have the needed structure out-of-domain, because that structure depends on the unknown geometry of all possible future images (the “data manifold” you haven’t seen yet). In short, you can reliably constrain decoders, but not encoders.
Everyday analogy:
- Decoder constraints are like building a Lego instruction manual with clear sections per piece, so you can always take the model apart correctly later.
- Encoder constraints would require knowing the shape of all possible Lego sculptures you might ever see—even those you’ve never built—which is impractical.
Practical approach: How to invert a decoder efficiently
The paper shows two ways to invert a learned decoder for OOD images:
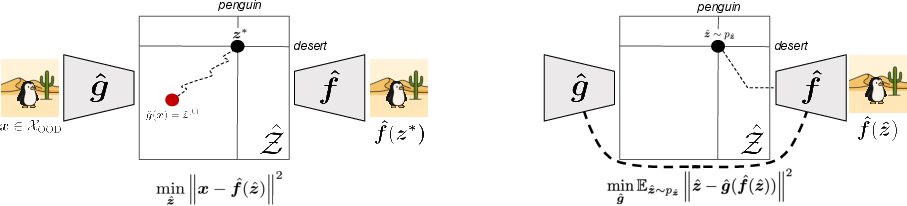
- Gradient-based search:
- Start with the encoder’s quick guess for the slots.
- Then run a small optimization to refine the slots so the decoder’s reconstruction closely matches the input image.
- Think of it like “System 1 vs. System 2”: a fast guess followed by slow, careful reasoning to get it right.
- Generative replay:
- Use the decoder to generate lots of new synthetic images by recombining known slots in new ways.
- Train the encoder on these generations so it learns to handle OOD combinations too.
- This is like practicing with simulated scenarios before seeing them in real life.
Experiments
They test on a photorealistic dataset called PUG (with animals, backgrounds, and textures) and create three splits:
- PUG-Background: new animal–background combos
- PUG-Texture: new animal–texture combos
- PUG-Object: new pairs of animals without occlusion (simplest interactions)
Models:
- Non-generative methods: Vision Transformer (ViT) encoders + slot encoders trained either unsupervised or supervised.
- Generative methods: Decoders that use cross-attention to draw pixels from slots, designed and regularized to match the “good” compositional structure.
Measurement:
- Train a simple linear readout on ID slots to predict the labels for each slot; score how well this readout works out-of-domain.
Main findings and why they matter
- Theory:
- You can reliably enforce the right structure on decoders (generative methods), which means you can guarantee compositional generalization.
- You generally cannot enforce the necessary out-of-domain structure on encoders (non-generative methods) because it depends on unknown future data.
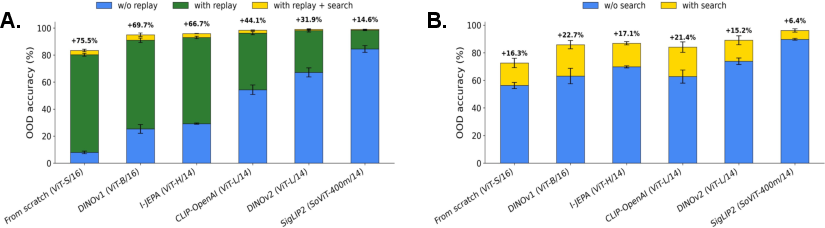
- Experiments:
- Non-generative methods trained from scratch or with limited pretraining often fail to generalize to new combinations out-of-domain.
- They improve with large-scale pretraining (like very big web datasets) or extra labels—but this costs data efficiency.
- Generative methods, with properly constrained decoders and the use of search and replay, achieve strong OOD performance without needing extra data.
- Special case: When parts don’t interact much (PUG-Object), non-generative methods can generalize well even without generative tools, because the problem is simpler.
Why this matters:
- Humans learn efficiently from few examples and handle new combinations easily. This work suggests machines need generative “simulators” to approach that kind of data efficiency, rather than only relying on encoders trained on massive data.
Implications and potential impact
- Building perception systems that are data-efficient likely requires a generative backbone: a decoder you can invert to recover the hidden slots that make up an image.
- Adding gradient-based search and generative replay can make these systems practical and robust out-of-domain.
- This could reduce the need for gigantic datasets and heavy supervision, moving us closer to human-like learning efficiency.
- Future directions include scaling these generative approaches to more complex scenes and creating better benchmarks for compositional generalization in realistic settings.
In short: To generalize like humans with limited data, machines probably need to “generate” internally—using a decoder they can invert—so they can understand new combinations of familiar parts.
Knowledge Gaps
Below is a single, concise list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each item is stated so that future researchers can act on it.
- Validity of the function class assumption: The theory hinges on generators belonging to the class F_int (additive slot-wise terms plus bounded-degree polynomial interactions). It remains unclear whether F_int adequately models real-world rendering phenomena (e.g., occlusions, lighting, shadows, perspective, non-polynomial interactions). Identify broader or alternative function classes that still guarantee OOD identifiability and test them empirically.
- Necessity vs. sufficiency of F_int: The paper shows F_int satisfies the required identifiability properties, but does not prove it is necessary. Characterize the minimal structural conditions under which OOD identifiability holds and compare against F_int.
- Diffeomorphism assumptions: The analysis assumes f is a diffeomorphism on its image, which may be violated in realistic scenes (many-to-one mappings due to occlusions, transparency, noise). Develop theory and methods for non-invertible generative processes and evaluate how these affect compositional generalization.
- Encoder constraints and data manifold geometry: The impossibility argument for constraining encoders draws on unknown OOD manifold geometry. Investigate whether manifold geometry (e.g., tangent spaces T_x X) can be reliably estimated from ID data and used to design practical, data-driven regularizers that generalize OOD.
- Strength and fidelity of decoder-side constraints: The implemented decoder regularization (attention discouraging pixels from attending to multiple slots) is only loosely related to the formal derivative constraints (e.g., block-diagonal Hessians for n=1). Quantify how well such practical regularizers enforce membership in F_int, and test alternative architectural/regularization designs that more directly target the theoretical derivative structure.
- Measuring adherence to theoretical structure: The experiments do not measure whether trained decoders satisfy the derivative properties (e.g., D2 f cross-slot terms near zero). Develop diagnostics to estimate these properties on trained models and link them to OOD generalization outcomes.
- Error tolerance and robustness in inversion: The theoretical guarantees assume an accurately learned decoder. Provide error bounds quantifying how approximation errors in hat f affect OOD inversion via search and replay, and characterize how robust these procedures are to model misspecification.
- Search efficiency and convergence: Gradient-based search is proposed as “System 2” inference but is not analyzed for convergence speed, sensitivity to initialization, or failure modes in high-dimensional z. Systematically study optimization landscapes, initialization strategies, step budgets, and computational cost vs. accuracy trade-offs.
- Replay distribution design: Generative replay assumes sampling latents with independent slot-wise marginals p_hat z. Develop methods to learn or infer realistic slot marginals (including dependencies), detect and avoid sampling unrealistic latents, and evaluate how replay quality impacts OOD generalization.
- Confirmation bias in replay: Training encoders on synthetic OOD from the learned decoder risks overfitting to decoder biases. Establish protocols to detect and mitigate confirmation bias, e.g., through cross-model replay, adversarial replay, or validation against external OOD benchmarks.
- Slot design limitations: Replay was only applicable for PUG-Background because slots captured object/background but not textures or attributes. Design slot spaces and decoders that support recombination across richer concept types (e.g., texture, pose, color, relations) and evaluate replay on these compositions.
- Scope of empirical evaluation: PUG datasets, while photorealistic, are small-scale with limited concept diversity and simple compositions. Construct larger, more realistic compositional benchmarks (including occlusions, multiple interacting objects, attributes, relations) and evaluate both generative and non-generative methods rigorously.
- Evaluation metrics: OOD performance is measured via linear readouts and Hungarian matching but does not assess slot segmentation quality (e.g., IoU, ARI), representation purity, or disentanglement. Introduce comprehensive metrics that directly test compositionality and concept disentanglement.
- Data efficiency quantification: The central claim concerns data efficiency, but the experiments do not measure sample complexity explicitly. Design controlled studies that quantify how OOD performance scales with ID data size for generative vs. non-generative approaches.
- Role of supervision and pretraining scale: The observed improvements in non-generative models come from large-scale pretraining and supervision, but the mechanisms are not analyzed. Investigate which properties (e.g., language supervision, diversity of contexts) drive compositional generalization and whether they can be replicated at smaller scales.
- Encoder inductive biases not fully explored: Beyond Slot Attention and standard ViT backbones, there exist encoder designs with strong compositional priors (e.g., object-centric generative encoders, equivariant architectures, graph-structured encoders). Provide formal and empirical tests of whether such encoder-side inductive biases can approximate G_int without requiring decoder inversion.
- Special case n=0 generalization: The paper shows easy OOD generalization when concepts do not interact (n=0), but does not probe transitions as interaction degree increases. Analyze how OOD performance degrades as n grows and whether partial constraints or hybrid methods bridge the gap between n=0 and n>1.
- Tangent-space constraint feasibility: The theoretical constraints for g involve projections onto T_x X. Develop practical estimators for T_x X from ID data (e.g., local PCA, manifold learning) and evaluate whether approximate constraints can improve OOD performance without explicit decoder inversion.
- Optimization-induced generalization in non-generative models: The paper suggests non-generative compositional generalization is contingent on luck in optimization. Study training dynamics and implicit biases that favor or disfavor compositional solutions, and test training regimes that reliably bias toward better OOD encoders.
- Applicability beyond vision: Claims are motivated by visual perception; it remains unclear whether the arguments extend to other modalities (audio, text, multimodal) or structured domains. Formulate and test analogous theoretical and empirical setups in non-visual domains.
- Real-world rendering and non-polynomial interactions: Many rendering effects (e.g., global illumination, specular highlights) are complex and non-local. Evaluate whether F_int constraints or their practical approximations suffice for such scenes, or propose new constraints aligned with modern differentiable rendering physics.
- Computational feasibility at scale: Gradient-based search and replay add inference-time and training-time compute. Quantify these costs at realistic scales, and develop amortization strategies or learned optimizers to reduce latency while preserving OOD gains.
- Generalization types beyond compositionality: The study focuses on compositional OOD; other shifts (viewpoint, lighting, style, clutter) are not analyzed. Extend analysis and experiments to a broader set of OOD scenarios to gauge the generality of generative vs. non-generative advantages.
- Decoder architectural choices: Cross-attention Transformers are one instantiation. Explore alternative decoders (e.g., diffusion, neural fields, multi-scale architectures) that may better align with theoretical constraints and offer superior inversion properties.
- Alignment and slot permutations OOD: The theory allows slot-wise reparameterizations and permutations h_pi, but OOD alignment of slots to semantics can drift. Investigate strategies to stabilize slot identities across OOD (e.g., canonicalization, contrastive slot identities, semantic anchors).
- Reliability under noise and domain shift: The theory assumes noise-free generation. Incorporate noise models, sensor artifacts, and domain mismatch into the analysis and test robustness of search and replay under these conditions.
- Formal impossibility vs. practical infeasibility: The encoder-side infeasibility claims are suggestive rather than absolute impossibility results. Develop formal lower bounds or impossibility theorems under realistic regularization families, or identify specific feasible families if they exist.
- Comparative study with state-of-the-art generative classifiers: The paper references emerging work using diffusion models as classifiers but does not compare against them. Benchmark generative inversion methods against diffusion-based or energy-based classifiers on compositional OOD tasks.
- Learning slot marginals from ID data: Replay requires p_hat z but the paper does not detail how to estimate it. Propose procedures to learn slot distributions (including cross-slot dependencies) from ID latents and study their impact on replay effectiveness.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, especially in domains with clear compositional structure (objects, backgrounds, textures) and tolerable latency for test-time search.
- Software/ML infrastructure — compositional generalization add-ons
- Use case: Add a “test-time search” module to existing encoder-based vision stacks to refine predictions on OOD images via gradient-based inversion of a trained decoder.
- Tools/workflow: Train a regularized slot-based decoder; at inference, run encoder for an initial latent guess, then 5–50 gradient steps to minimize reconstruction error; optionally cache results. Package as a drop-in PyTorch/TensorFlow component.
- Sector: Software, MLOps.
- Dependencies/assumptions: Availability of a differentiable decoder that approximates the data generating process; acceptable latency budget; slots reflect meaningful factors of variation; low-to-moderate interaction degree among factors (e.g., limited occlusion or multiplicative effects).
- Data-efficient retraining via generative replay
- Use case: Improve OOD robustness of existing encoders by training them offline on synthetic images created by recombining ID slot codes through a learned decoder.
- Tools/workflow: Fit decoder + encoder on ID; sample independent slot marginals; generate novel recombinations; train encoder on synthetic pairs using reconstruction/consistency losses; deploy updated encoder without online search.
- Sector: Software, ML model lifecycle.
- Dependencies/assumptions: Decoder identifies factors up to slot-wise transforms; independent slot sampling approximates unseen compositions; synthetic artifacts don’t mislead the encoder.
- Industrial quality inspection with novel backgrounds/finishes
- Use case: Detect defects reliably when product finishes or backgrounds change (new lighting, textures, or fixtures).
- Tools/workflow: Slot-based decoder trained on ID factory conditions; replay to synthesize new textures/backgrounds; test-time search for ambiguous frames.
- Sector: Manufacturing.
- Dependencies/assumptions: Stable object geometry; controllable slot partition (product vs. background/texture); camera stabilization or known variation bounds.
- Retail/e-commerce product recognition across varied scenes
- Use case: Robust SKU recognition on user-uploaded images taken in diverse locations and backgrounds with minimal additional labeled data.
- Tools/workflow: Use pre-trained ViT + slot-decoder; replay for unseen background combinations; optional test-time search for hard cases.
- Sector: Retail, marketplaces.
- Dependencies/assumptions: Clear object/background compositionality; reliable slot inference for products; compute budget for occasional search.
- Remote sensing/land-cover mapping with new co-occurrences
- Use case: Generalize to novel combinations of land uses (e.g., crops + novel soil textures) without new labels.
- Tools/workflow: Train decoder with minimal slot interactions; replay to mix land-cover factors; use search during inference on flagged OOD tiles.
- Sector: Energy, agriculture, climate/EO.
- Dependencies/assumptions: Factors (vegetation, soil, water, built area) are slot-like; stable spectral signatures; manageable cloud/atmospheric variability.
- AR/VR scene decomposition under new lighting/backgrounds
- Use case: Improve object segmentation and placement realism in unfamiliar rooms or lighting conditions with minimal extra data.
- Tools/workflow: Train slot-based decoder with attention regularization to limit interactions; replay for lighting/background recombinations; search when occlusion makes segmentation uncertain.
- Sector: XR, gaming, creative tools.
- Dependencies/assumptions: Fast-enough inference path; differentiable renderers or learned decoders approximating photorealistic variation.
- Robotics in semi-structured environments (warehouses, labs)
- Use case: Reduce data needs for new aisle layouts or container/background variations; maintain grasp/placement accuracy on novel object-context combos.
- Tools/workflow: Fit decoder on ID scenes; perform replay to synthesize new shelf/background combos; trigger search for frames with high encoder uncertainty.
- Sector: Robotics, logistics.
- Dependencies/assumptions: Moderate scene complexity; camera calibration; latency budget for search around grasp-critical frames.
- Medical imaging pre-deployment robustness checks (non-diagnostic)
- Use case: Audit OOD generalization to rare device artifacts or unusual anatomical context before deployment.
- Tools/workflow: Use generative replay to produce plausible combinations of artifacts/anatomy learned from ID; evaluate encoder consistency; escalate to manual review for failures.
- Sector: Healthcare QA/AIOps.
- Dependencies/assumptions: Strict regulatory boundaries (use for QA, not diagnosis); clinically plausible decoders; IRB/compliance for data use.
- Security/surveillance analytics
- Use case: Maintain detection under novel camera backgrounds and seasonal texture changes without large-scale retraining.
- Tools/workflow: Replay to synthesize seasonal/background changes; test-time search for low-confidence detections.
- Sector: Security, smart cities.
- Dependencies/assumptions: Clear object vs. background slot separation; manageable false positives from synthetic artifacts.
- Education/research tooling for compositional generalization
- Use case: Reproducible benchmarks and libraries for slot-decoder training, derivative-based interaction regularization, test-time search, and replay.
- Tools/workflow: “Compositional Perception Engine” library; PUG-like datasets; plug-ins for ViT backbones; evaluation scripts for ID/OOD splits.
- Sector: Academia, EdTech.
- Dependencies/assumptions: Open datasets with controllable factor combinations; GPU availability; adoption by the research community.
- OOD generalization audits in ML governance
- Use case: Standardize OOD testing of vision models using decoder inversion to surface blind spots before deployment.
- Tools/workflow: Replay-driven synthetic OOD sets; test-time search to quantify recoverability; reporting dashboards.
- Sector: Policy, compliance, MLOps.
- Dependencies/assumptions: Access to model internals or surrogate decoders; organizational processes for model risk assessment.
Long-Term Applications
These applications likely require further research, scaling, domain-specific decoders, and/or stronger guarantees (e.g., safety-critical certification).
- Autonomous driving perception with principled OOD guarantees
- Use case: Decompose scenes into objects, road contexts, and weather; generalize to novel co-occurrences (e.g., unusual roadworks + fog).
- Tools/workflow: High-fidelity generative decoders with constrained interactions; continuous replay from fleet data; real-time search for ambiguous frames.
- Sector: Automotive, mobility.
- Dependencies/assumptions: Ultra-low-latency search; rigorous validation of generative realism; strong occlusion handling; certification pathways.
- Surgical and diagnostic imaging with generative inversion
- Use case: Robust identification of pathologies across rare anatomical contexts and device artifacts with far less labeled data.
- Tools/workflow: Domain-specific decoders aligned with anatomy-pathology “slots”; regulatory-grade data curation; replay for rare combos; clinician-in-the-loop search.
- Sector: Healthcare.
- Dependencies/assumptions: Clinically validated decoders; safety and bias audits; explainability standards; integration with PACS/EHR.
- Open-world assistive robotics in homes
- Use case: Handle endless novel object-context combinations (new furniture, lighting, clutter) with continual learning and minimal supervision.
- Tools/workflow: Generative world models for object/background/affordances; continual replay; on-device search under power constraints.
- Sector: Consumer robotics, accessibility.
- Dependencies/assumptions: Efficient hardware acceleration for search; privacy-preserving on-device generation; robust slot discovery in clutter.
- Foundation vision models that replace heavy contrastive pretraining
- Use case: Train data-efficient, compositional foundation models by constraining decoders and learning to invert them, reducing reliance on web-scale data.
- Tools/workflow: Scalable decoder architectures with interaction-regularized attention; large-scale replay curricula; hybrid encoder-initialized search at pretraining time.
- Sector: Software, AI platforms.
- Dependencies/assumptions: Stable training of large generative decoders; scalable replay without mode collapse; evaluation at internet scale.
- Safety-critical OOD monitors via inversion difficulty
- Use case: Use optimization difficulty (search convergence metrics) as an early-warning signal of distribution shift in critical systems.
- Tools/workflow: Instrument inference-time losses and step counts; trigger fallbacks when search fails to reach reconstruction thresholds.
- Sector: Aviation, industrial control, autonomous systems.
- Dependencies/assumptions: Calibrated thresholds; fail-safe integration; comprehensive OOD taxonomies.
- Scientific imaging and discovery under novel conditions
- Use case: Generalize to new experimental setups (microscopy staining, telescope filters) with limited new data.
- Tools/workflow: Physics-aware decoders with factorized slots (specimen, stain, optics); replay across experimental parameters; search for challenging frames.
- Sector: Pharma, materials, astronomy.
- Dependencies/assumptions: Hybrid physics–ML models; domain simulators; rigorous uncertainty quantification.
- Remote inspection and maintenance (energy, telecom)
- Use case: Detect faults on infrastructure under unusual combinations of wear, weather, and background clutter from drone imagery.
- Tools/workflow: Domain decoders trained on historical conditions; replay for rare co-occurrences; search for uncertain detections; human triage loops.
- Sector: Energy, utilities, telecom.
- Dependencies/assumptions: High-resolution data; efficient edge processing; transparent risk workflows.
- Generative perception for embodied agents with planning loops
- Use case: Integrate perception-by-inversion with action selection where search acts as “System 2” perceptual reasoning before critical actions.
- Tools/workflow: Coupled perception decoder and world-model planner; compute-aware scheduling of search; replay-driven curriculum for long-horizon tasks.
- Sector: Robotics, autonomous exploration.
- Dependencies/assumptions: Joint training stability; compute budgets; safety constraints.
- Privacy-preserving model improvement via synthetic OOD
- Use case: Reduce need for collecting sensitive OOD data by using replay to generate training distributions in regulated environments.
- Tools/workflow: On-premises decoders trained on permitted data; synthetic OOD generation for retraining encoders; formal privacy assessments.
- Sector: Public sector, healthcare, finance.
- Dependencies/assumptions: Validity of synthetic data for intended use; regulatory acceptance of synthetic augmentation; governance frameworks.
- Standardized OOD generalization benchmarks and policy adoption
- Use case: Create procurement and certification standards requiring evaluation under controlled OOD compositions and reporting inversion success metrics.
- Tools/workflow: Public benchmark suites (object–background–texture splits); tooling for replay/search reporting; audit trails.
- Sector: Policy, standards bodies.
- Dependencies/assumptions: Cross-industry consensus; shared repositories and metrics; participation from regulators and industry.
- On-device perception with “anytime” inversion
- Use case: Mobile or edge devices that trade accuracy for speed by halting search early, or continuing search when power is available.
- Tools/workflow: Anytime optimization; dynamic compute allocation; small decoders fine-tuned with replay for target hardware.
- Sector: Mobile, IoT, AR wearables.
- Dependencies/assumptions: Efficient gradient computation on edge hardware; robust fallback when search is curtailed.
- Transparent, interpretable perception via slot readouts
- Use case: Provide factor-wise explanations (per-slot readouts) for decisions in regulated sectors.
- Tools/workflow: Shared linear readouts per slot; Hungarian assignment for slot-label mapping; dashboards showing slot reconstructions and search traces.
- Sector: Finance, healthcare, public sector.
- Dependencies/assumptions: Stable slot semantics; human-understandable factorization; governance processes for interpretability claims.
Notes on assumptions and dependencies across applications
- Slot factorization quality: Success depends on learning meaningful, disentangled slot representations (objects, backgrounds, textures), typically encouraged with architectural and regularization choices.
- Interaction degree: The theory assumes generators with limited-degree interactions between factors; heavy occlusion or complex lighting/material effects may require richer decoders.
- Decoder fidelity: Generative replay efficacy hinges on how well the decoder approximates the true data-generating process; domain-specific decoders may be needed.
- Compute/latency: Test-time search introduces overhead; designs may mix fast encoder-only inference with conditional search on uncertain inputs.
- Data governance: Replay can reduce data collection needs but may require validation that synthetic distributions are adequate and compliant.
- Evaluation: New OOD benchmarks and metrics (e.g., search convergence, reconstruction error thresholds) are needed to guide deployment in high-stakes settings.
Glossary
- Adam: An adaptive stochastic optimization algorithm commonly used to train neural networks. "with Adam~\citep{kingma2015adam}"
- anti-causal direction: The modeling direction from effects to causes, often considered harder for generalization than the causal direction. "generalization is typically easier to achieve in the causal direction than in the anti-causal direction."
- autoencoder: A neural network that learns to reconstruct inputs via an encoder-decoder pair, enabling fast in-domain inversion. "in-domain (ID) via an autoencoder"
- bijection: A one-to-one and onto mapping; used here slot-wise to permit reparameterizations and permutations. "slot-wise bijections "
- block-diagonal: A matrix structure with independent blocks along the diagonal and zeros elsewhere; used to characterize derivative constraints. "block-diagonal derivative matrices "
- Cartesian: Refers to axis-aligned product structure; the latent space extends as a Cartesian product across slots. "since the manifold extends in a Cartesian fashion and its structure is therefore known."
- compositional data generating process: A process where observations are generated by combining latent “slots” (concepts) in structured ways. "Under the compositional data generating process of~\citet{brady2025interaction}, we formalize the inductive biases..."
- compositional generalization: The ability to generalize to unseen combinations of known components (concepts). "compositional generalization, a hallmark of human perception."
- cross-attention Transformer: A Transformer architecture in which queries attend to a set of keys/values; used here for pixels attending to slots. "we use a cross-attention Transformer, where each pixel queries the slots"
- data manifold: A lower-dimensional surface embedded in high-dimensional space on which natural data lie. "depends on the geometry of the data manifold ."
- diffeomorphism: A smooth, invertible map with a smooth inverse; used to model the generator’s mapping between latents and images. "diffeomorphisms (on their image) with the following form will satisfy~\cref{eq:ood_ident_gen}"
- generative replay: A procedure that generates synthetic samples from a learned generator to train or adapt an encoder offline. "can also be solved in an offline manner by leveraging generative replay"
- gradient-based search: Optimization over latent variables using gradients to invert a decoder at test time. "either online through gradient-based search"
- Hessian: The matrix of second derivatives of a function; used to express interaction constraints between slots. "then the Hessian has the structure that..."
- Hungarian algorithm: A combinatorial optimization algorithm for assignment problems used to align slots to labels. "using the Hungarian algorithm~\citep{Kuhn1955}"
- identifiability: The property that a model or mapping is uniquely determined (up to symmetries) from observed data. "The problem of OOD identifiability."
- in-domain (ID): The set of data or combinations observed during training. "in-domain (ID) and out-of-domain (OOD) images"
- inverse problem: Recovering latent causes from observed effects; here, inferring slots from images. "perception as an inverse problem"
- inverting a decoder: Obtaining latent representations by searching for inputs to a generator that reproduce a given image. "representations result from inverting a decoder to recover the latent variables that generate an image"
- Jacobian: The matrix of first derivatives; its structure (with the Hessian) characterizes inverse generators. "structured Jacobian and Hessian."
- latent variable model: A probabilistic or functional model where observations are generated from unobserved variables. "we assume that images arise from a latent variable model."
- left inverse: A function g such that g(f(z)) = z for z in the domain; used when the generator is not square/invertible on the ambient space. "with a (left)-inverse "
- LoRA adapter: A low-rank parameter-efficient fine-tuning method for large pretrained models. "then optionally fine-tuned using a LoRA adapter~\citep{hu2022lora}"
- measure-zero set: A negligible subset in the measure-theoretic sense; used to qualify generic properties of derivatives. "up to a set of measure 0"
- multi-index: A tuple of nonnegative integers used to index multivariate monomials in polynomial interactions. "A multi-index is an ordered tuple $\alphab=(\alpha_1, \alpha_2, ...,\alpha_d)$ of non-negative integers..."
- occlusions: Visual interactions where one object blocks part of another, complicating compositionality. "no interactions (such as occlusions) between objects are possible."
- orthogonal projection: The projection of a vector onto a subspace that minimizes squared distance; used with tangent spaces. " denotes the orthogonal projection on the tangent space"
- out-of-domain (OOD): Data or combinations not seen during training, used to test generalization. "out-of-domain (OOD) images arise from a latent variable model"
- readout: A simple linear (or shallow) classifier/regressor applied to learned representations. "can be solved via a simple readout applied independently to each inferred slot"
- regularization: Additional constraints in the loss to encourage desired model properties or structures. "through regularization or architectural design."
- Slot Attention: A module that iteratively assigns parts of the input to a fixed set of slots via attention. "a Slot Attention module~\citep{locatello2020object}"
- slot encoder: The component that extracts a set of slot representations (one per concept) from image features. "a slot encoder queries the resulting patch embeddings via cross-attention to produce a set of slots."
- tangent space: The linear approximation of a manifold at a point; used to express projected derivative constraints. "the tangent space of the data manifold"
- VAE: A Variational Autoencoder; a probabilistic autoencoder trained with a variational objective. "using a VAE loss~\citep{kingma2014autoencoding}"
- Vision Transformer (ViT): A Transformer architecture applied to image patches for visual representation learning. "processed by a Vision Transformer (ViT)~\citep{dosovitskiy2020image}"
- weak supervision: Training signals that are indirect, noisy, or incomplete compared to full labels. "self- or weak supervision"
Collections
Sign up for free to add this paper to one or more collections.

