- The paper presents NoisyCLIP, a novel method for measuring text-to-image alignment in the latent space that halves computational cost while retaining 98% of alignment performance.
- The method uses a twin-tower encoder architecture with contrastive fine-tuning on noisy latent representations to enhance semantic alignment during reverse diffusion.
- Benchmark analysis shows improved prompt adherence and robust recall, setting a new standard for real-time, in-process alignment verification in generative image synthesis.
Introduction and Motivation
Conditional diffusion models have become the backbone of contemporary image generation pipelines, delivering high-fidelity samples steered by textual input. Despite advances in cross-attention dynamics and latent-space manipulation, misalignment and semantic drift between prompts and outputs remain pervasive, particularly in computationally intensive scenarios like Best-of-N (BoN) selection. Existing evaluation protocols focus predominantly on post-generation alignment metrics, which incur substantial compute overhead due to the necessity of rendering all outputs before filtering for semantic fidelity. "Beyond the Noise: Aligning Prompts with Latent Representations in Diffusion Models" (2512.08505) addresses this bottleneck by introducing NoisyCLIP, a method for measuring text-to-image alignment in the latent space during diffusion, enabling real-time selection and early termination of poorly aligned samples.
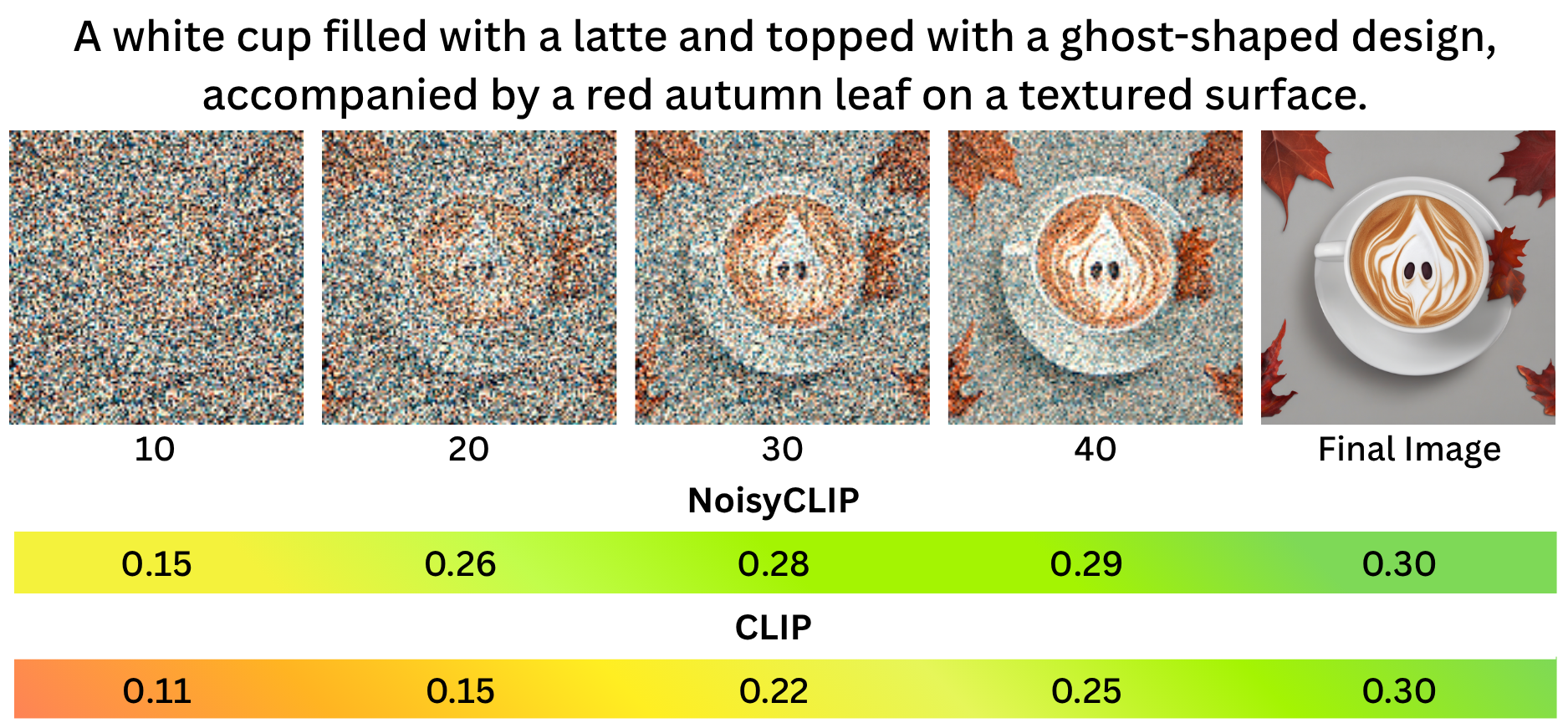
Figure 1: NoisyCLIP measures language-to-latent alignment during reverse diffusion by comparing textual prompts to intermediate latent representations, enabling early detection of misalignments.
Framework: NoisyCLIP and Latent Alignment Assessment
NoisyCLIP is built on a twin-tower encoder architecture, designed to operate within the noise-corrupted latent domains produced at intermediate steps of the reverse diffusion trajectory. This approach is grounded in augmenting CLIP-style models, which traditionally operate in RGB image space, via contrastive fine-tuning on noisy latents extracted from the reverse diffusion process.
The authors formalize the alignment signal Slatent(zt,y)=τθ(y)⋅νθ(Φ(zt)), where Φ is a linear mapping transforming the latent zt to a form ingestible by the image encoder νθ, and τθ denotes the frozen text encoder shared with the underlying diffusion architecture. Contrastive learning is performed in latents corresponding to early and mid-reverse diffusion steps, leveraging a curated Noisy-Conceptual-Captions dataset and controlling for positive/negative pairs via explicit batch-level in-batch negatives.
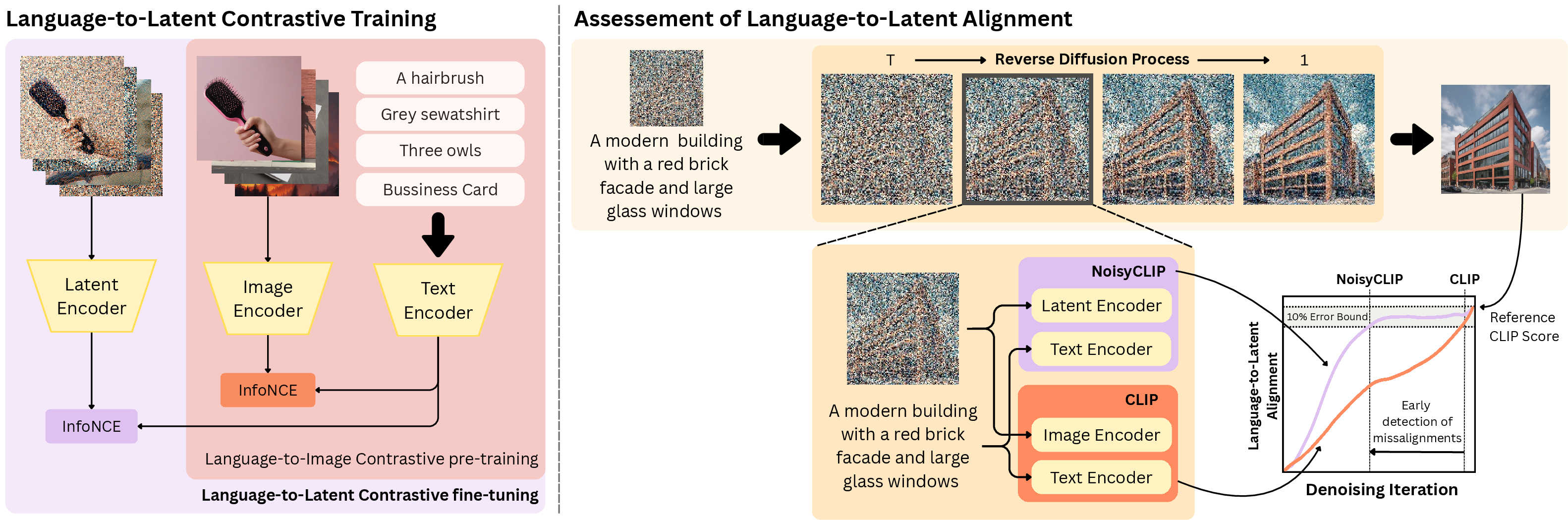
Figure 2: Similarity between prompt and generated image is computed at intermediate denoising stages, with scores tightly correlated to scores obtained on the final image due to encoder fine-tuning on noisy latents.
Benchmarking and Methodological Contributions
The paper introduces two benchmarks for systematic evaluation: Noisy-Conceptual-Captions (caption selection and factual consistency) and Noisy-GenAI-Bench (BoN selection covering attribute, scene, spatial, and logical prompt types). These datasets catalogue not only final images but full latent trajectories, enabling granular analysis of prompt-image adherence across incremental denoising steps.
Key experimental tasks undertaken include:
- Language-to-Latent Alignment: Ranking of images for a given prompt at each latent stage, quantifying separability using VQAScore.
- Best-of-N Selection: Early selection of the most aligned latent path, assessed at varying diffusion costs.
- Factual Consistency: Recall@1 evaluation requiring selection of correct prompts versus adversarially corrupted distractors.
Strong Results: Efficiency–Fidelity Trade-off in BoN
Empirical results underscore NoisyCLIP's computational benefits: by operating selection at the midpoint (latent ≈20–30) rather than image-space finalization, compute is halved while retaining 98% of CLIP-based alignment performance (VQAScore). Figure 3 demonstrates that NoisyCLIP separates top-ranked candidates as early as latent 20, achieving a ∼3% score gap. CLIP, absent noisy latent training, fails to maintain separation except at low-noise endpoints.
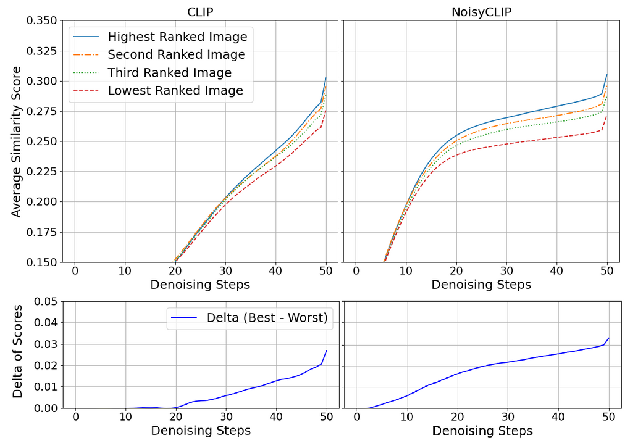
Figure 3: Alignment measurement analysis throughout reverse diffusion reveals that NoisyCLIP distinguishes aligned from misaligned images by latent 20.
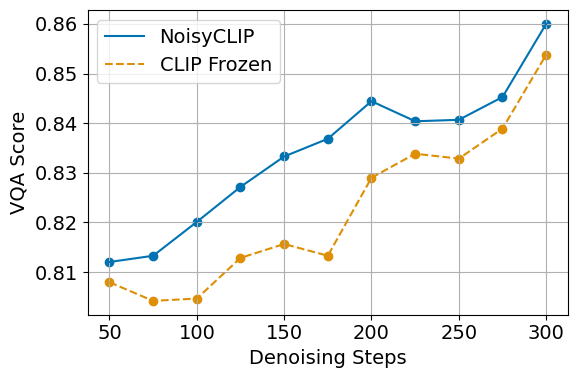
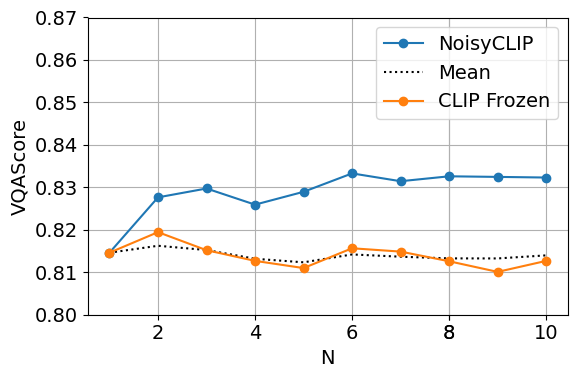
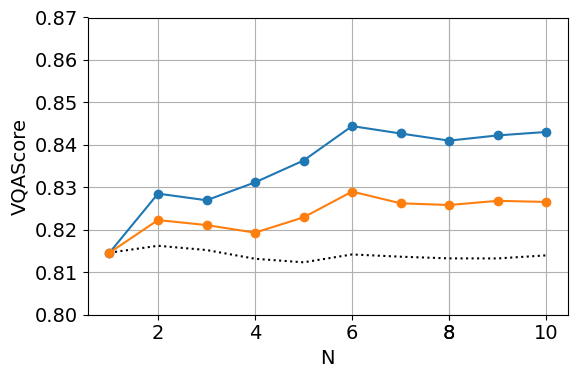
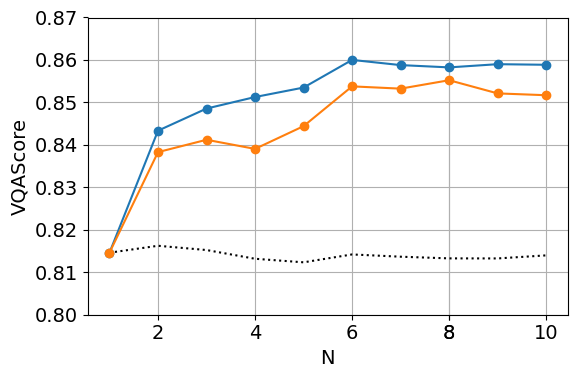
Figure 4: Alignment (VQAScore) plotted against denoising cost, showing NoisyCLIP achieves comparable alignment at half the computational cost (N=6 BoN).
Qualitative and quantitative results indicate superior early selection in BoN across both basic and advanced prompt categories, with notable improvements over baseline CLIP in complex, multi-entity or logically involved generations.

Figure 5: Best-of-6 generation—NoisyCLIP outperforms CLIP at fixed budgets and often matches full-cost CLIP performance using half the diffusion steps.
Factual Consistency and Robustness
NoisyCLIP exhibits robust semantic discrimination, achieving Recall@1 scores exceeding 0.5 within the first half of denoising steps, outperforming CLIP across all tested non-factual distractor types (color, count, background, subject). Early correct caption selection is demonstrated in Figure 6.
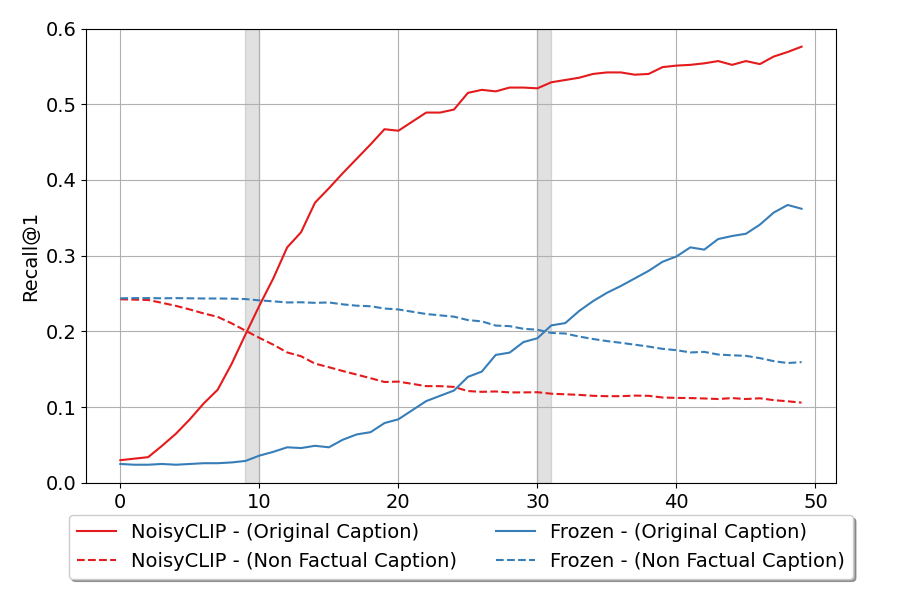
Figure 6: Recall@1 for correct versus non-factual distractor captions, indicating high discriminative power of NoisyCLIP at early latent stages.
Analysis across training latent intervals reveals optimal generalization for models fine-tuned in mid-range latent domains (20–29), balancing initial-stage robustness with terminal alignment accuracy, unlike low or high-noise exclusive training.
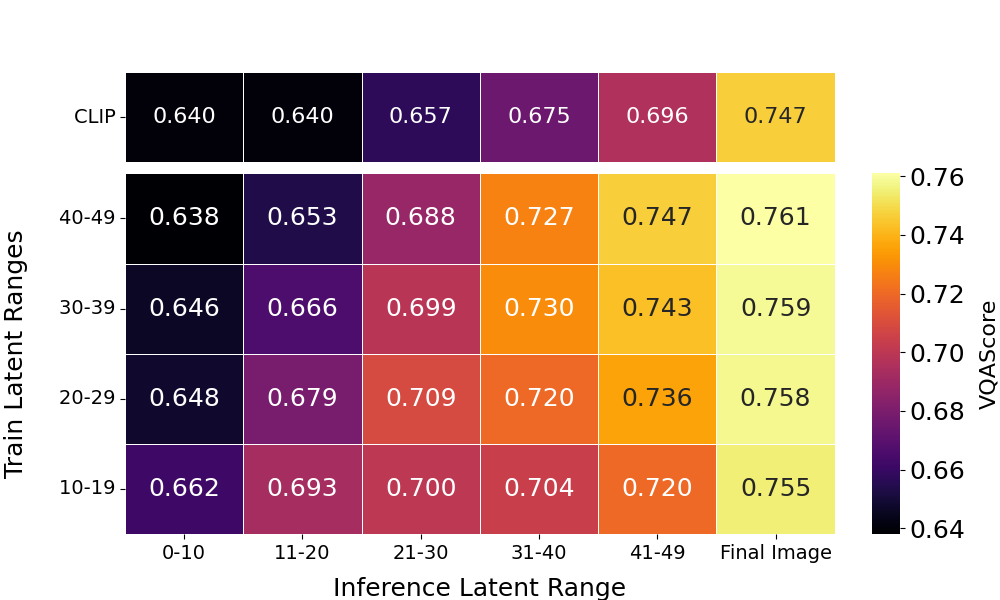
Figure 7: Training/inference latent range correlation—moderate noise training yields stable alignment across the generation.
Ablation and Encoder Scalability
Experiments demonstrate that fine-tuning solely the image encoder suffices; joint text-image encoder tuning yields negligible or adverse gains. Encoder scaling studies show performance improvements proportional to model capacity (ViT-L/14 > ViT-B/16), solidifying the link between representational expressivity and robust alignment under noise.
Practical and Theoretical Implications
Practically, NoisyCLIP redefines BoN strategies in generative frameworks, offering early misalignment detection, dynamic early stopping, and compute savings whilst maintaining semantic quality. This paradigm enables integration of robust alignment metrics into control loops for real-time, efficient multimodal generation. Theoretically, the study evidences that latent-space alignment metrics, when fine-tuned on noise-corrupted trajectories, can reliably project final semantic fidelity earlier in the generative process. Extension to alternative contrastive backbones (e.g. SigLIP) shows promise but highlights architectural variance in transferability.
Conclusion
NoisyCLIP operationalizes continuous language-to-latent alignment evaluation throughout reverse diffusion, transforming semantic validation from a post-hoc filter into a computationally integral selection mechanism. With strong evidence for significant cost reductions and minimal fidelity loss, this approach establishes a new baseline for in-process alignment-aware generation and informs future directions for adaptive prompt-conditioned control in scalable diffusion pipelines. The open benchmarks and protocol blueprints provided invite further research in latent diagnostics, backbone generalization, and transfer to broader multimodal frameworks.