Visionary: The World Model Carrier Built on WebGPU-Powered Gaussian Splatting Platform
Abstract: Neural rendering, particularly 3D Gaussian Splatting (3DGS), has evolved rapidly and become a key component for building world models. However, existing viewer solutions remain fragmented, heavy, or constrained by legacy pipelines, resulting in high deployment friction and limited support for dynamic content and generative models. In this work, we present Visionary, an open, web-native platform for real-time various Gaussian Splatting and meshes rendering. Built on an efficient WebGPU renderer with per-frame ONNX inference, Visionary enables dynamic neural processing while maintaining a lightweight, "click-to-run" browser experience. It introduces a standardized Gaussian Generator contract, which not only supports standard 3DGS rendering but also allows plug-and-play algorithms to generate or update Gaussians each frame. Such inference also enables us to apply feedforward generative post-processing. The platform further offers a plug in three.js library with a concise TypeScript API for seamless integration into existing web applications. Experiments show that, under identical 3DGS assets, Visionary achieves superior rendering efficiency compared to current Web viewers due to GPU-based primitive sorting. It already supports multiple variants, including MLP-based 3DGS, 4DGS, neural avatars, and style transformation or enhancement networks. By unifying inference and rendering directly in the browser, Visionary significantly lowers the barrier to reproduction, comparison, and deployment of 3DGS-family methods, serving as a unified World Model Carrier for both reconstructive and generative paradigms.
First 10 authors:



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Visionary: A simple explanation
What is this paper about?
This paper introduces Visionary, a tool that runs in your web browser to show realistic 3D scenes in real time. It focuses on a technique called 3D Gaussian Splatting, which builds scenes from millions of tiny blurry dots (think of them like soft, translucent bubbles). Visionary makes it easy, fast, and flexible to view and update these scenes directly in the browser, without installing heavy software.
What questions does it try to answer?
In plain terms, the paper asks:
- How can we make 3D scenes that use “Gaussian splats” run smoothly on any computer, just by opening a website?
- How can we support not only still scenes but also moving scenes (like animated people or time-changing environments)?
- How can we plug in new AI models easily, so different research ideas work together without rewriting everything?
How does it work? (Explained with everyday ideas)
Visionary works like a web-based 3D game engine with three main parts. Here are the parts and some analogies to help:
Before the steps, two quick definitions:
- WebGPU: a modern, fast graphics engine built into new browsers (like a turbocharged engine compared to older WebGL).
- ONNX: a universal “plug adapter” for AI models so models from different places fit the same socket and run the same way.
Now the three parts:
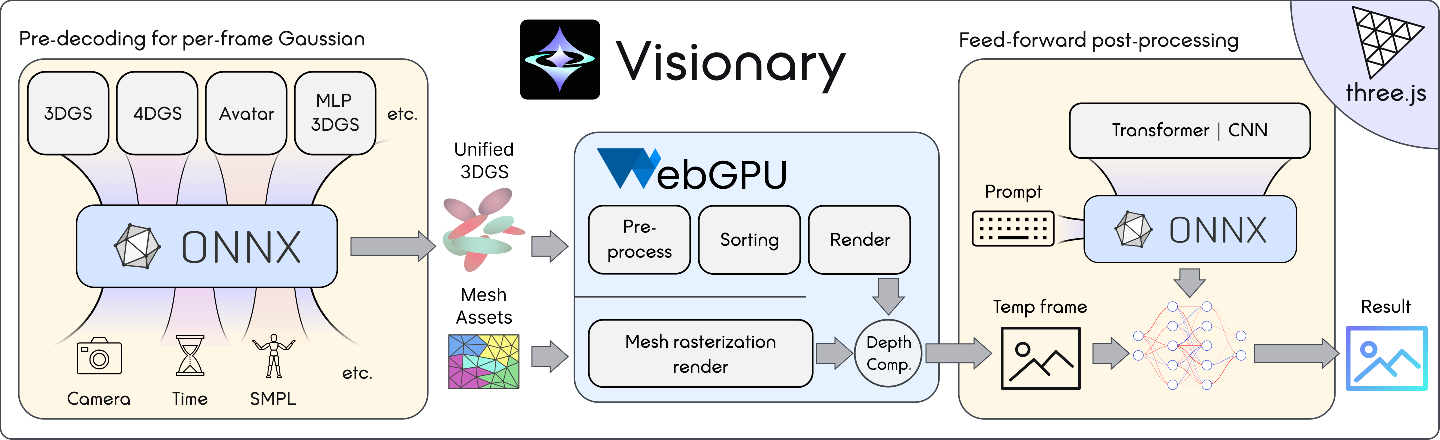
- Step 1: Pre-decoding with ONNX (the “model plug” step)
- Different AI methods can “generate” or “update” the tiny bubbles (their positions, sizes, colors, and transparency) every frame.
- Visionary defines a clear set of rules (called the Gaussian Generator contract) for these AI plugins: “If you give me bubble info in this exact format, I’ll render it.”
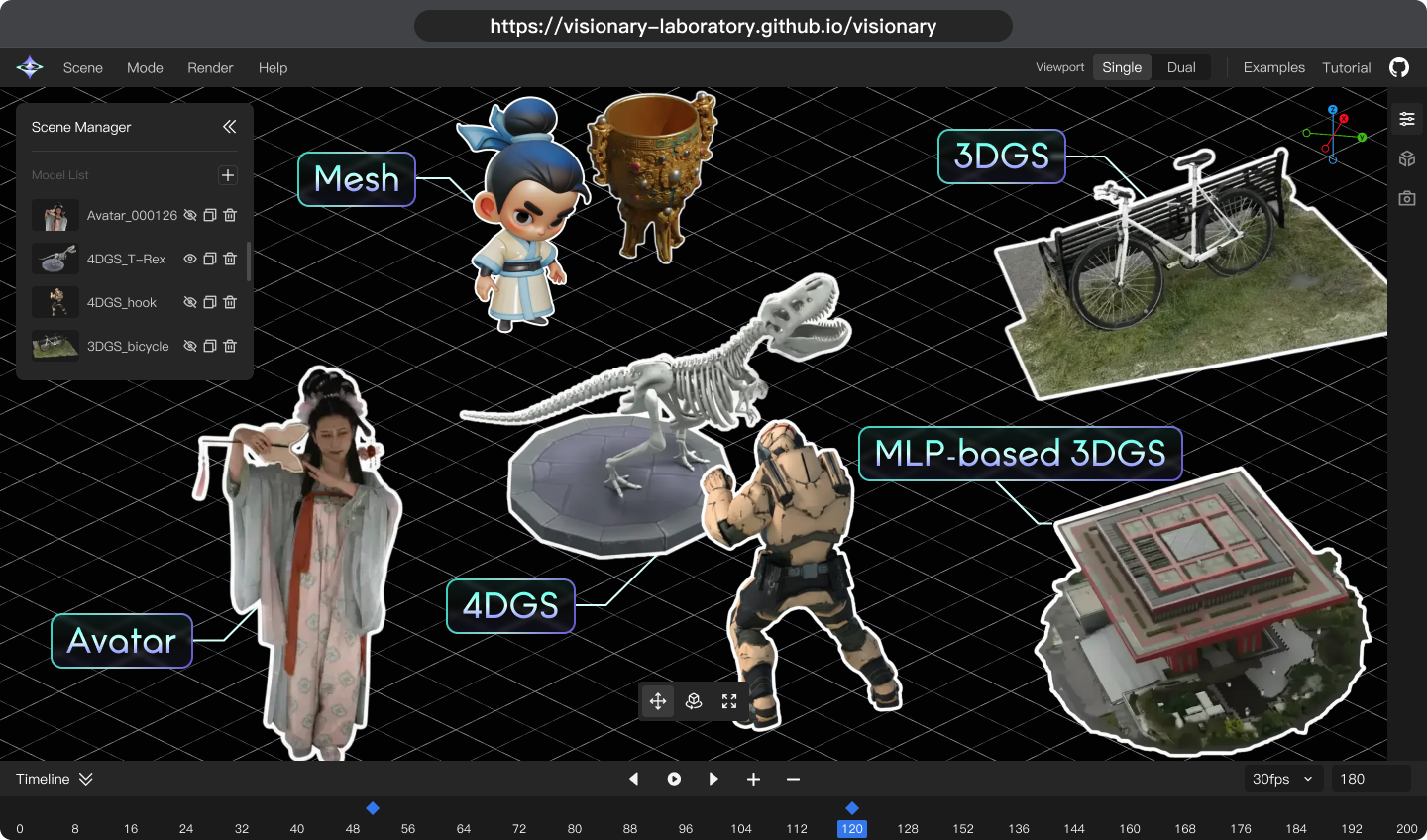
- This lets Visionary support many variants, like:
- MLP-based 3DGS: fewer stored bubbles, decoded by a small neural network each frame.
- 4DGS: scenes that change over time (like a moving object).
- Avatars: animated people driven by a body model (e.g., SMPL-X).
- Step 2: WebGPU rendering (the “draw it fast and correctly” step)
- Think of stacking many transparent stickers: you must sort them from back to front so they look right.
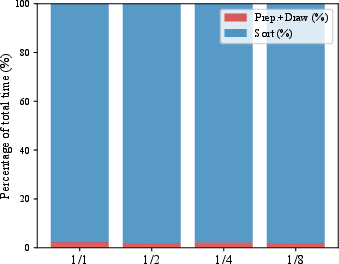
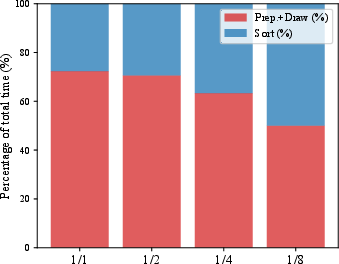
- Visionary does this sorting on the graphics card (GPU) every frame, which is super fast and accurate.
- Older web viewers sorted on the CPU (slower) or only did partial sorting (which can look wrong when you move the camera quickly).
- Visionary can also mix traditional 3D meshes with the bubbles and uses a depth test (like checking which sticker is truly in front) to combine them correctly.
- Step 3: Post-processing with ONNX (the “style and polish” step)
- After rendering, Visionary can run lightweight AI effects in the browser, like style changes or enhancements, using ONNX again.
Visionary also comes as a plugin for three.js (a popular web 3D library), with a simple TypeScript API, so developers can drop it into web apps easily.
What did they find?
Here are the main results and why they matter:
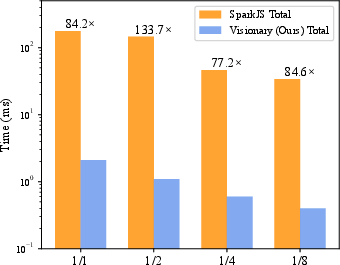
- Much faster than existing web viewers:
- Compared to WebGL-based tools like SparkJS or SuperSplat, Visionary’s GPU-based sorting and rendering make it up to around 100–135 times faster in their tests with millions of bubbles.
- Example: one heavy scene took about 177 ms per frame in SparkJS vs about 2 ms in Visionary (lower is better).
- More stable visuals when moving the camera:
- Because Visionary fully re-sorts on the GPU every frame, it avoids flickers, popping, or “wrong transparency” that can happen in other viewers when you spin the camera.
- Similar or slightly better image quality:
- On a standard benchmark, Visionary matched or slightly improved quality while staying fast.
- Works with dynamic content:
- It supports moving scenes (4DGS), animated human avatars, and neural-decoded variants (like MLP-based 3DGS) in real time, all inside the browser.
- Click-to-run, no heavy installs:
- You just open a link. It runs on your computer’s GPU through the browser, which also helps with privacy (data stays local).
Why does this matter?
- Lower barrier to entry:
- Researchers, students, and creators can share and test 3D scenes instantly via a link, without special drivers or long setups.
- A “universal carrier” for world models:
- World models are AI systems that try to understand and predict how the world changes over time. Many of them work only with 2D video and can get confused about 3D structure.
- Visionary helps by making it easy to visualize and use real 3D states (the bubbles), which are more consistent and physically believable than pure 2D tricks.
- Future-proof and flexible:
- The ONNX “plug adapter” and WebGPU engine make it simple to add new algorithms as they are invented, without rewriting the renderer.
Limitations and future directions
- Current limits:
- WebGPU and ONNX in the browser are still evolving, so support can differ between browsers and operating systems.
- Browsers also limit memory, so very large models may not fully fit yet.
- What’s next:
- Add physics and collisions (so objects can interact more realistically).
- Mix bubble scenes with advanced mesh pipelines and lighting.
- Build 3D agents that can think and act in these worlds.
- Connect to simulators and tools for robotics, science, and education.
In short, Visionary turns the browser into a fast, flexible, and open “game console” for modern 3D AI scenes. It lets many different AI models plug in, run in real time, and look correct—all with a simple link.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or left unexplored by the paper, tailored to actions future researchers can take.
- Cross-browser and cross-OS validation is absent: no empirical results across Chrome/Edge/Firefox and Windows (D3D12), macOS (Metal), Linux (Vulkan), nor with integrated GPUs and mobile GPUs to assess WebGPU and ONNX Runtime WebGPU compatibility, stability, and performance.
- Mobile viability is not evaluated: no measurements on phones/tablets (memory, thermals, energy, and frame rates) nor fallback strategies when WebGPU is unavailable or constrained (e.g., progressive features, WebGL fallback).
- Scalability to city-level and ultra-large scenes is untested: no out-of-core streaming, LOD/tiled culling, incremental loading, or memory-bounded sorting strategies for tens to hundreds of millions of Gaussians.
- Network delivery of assets/models is not addressed: no packaging, compression, progressive streaming, caching (e.g., service workers), or CDN strategies for large ONNX models and 3DGS assets to minimize load time and memory spikes.
- Memory footprint and resource profiling are missing: no quantitative GPU/CPU memory usage, bandwidth, atomic counter limits, buffer sizing, or performance sensitivity to asset sizes and FP16 packing.
- Baseline fairness and breadth are limited: comparisons cover SparkJS and Supersplat (with CPU/local sorting strategies) but exclude newer WebGPU viewers or native GPU-sorting baselines, making it unclear how Visionary fares against state-of-the-art GPU-first renderers.
- Rendering quality evaluation is narrow: only static PSNR/SSIM/LPIPS on MipNeRF360; no metrics for dynamic scenes (4DGS/avatars), temporal stability (flicker), or composition correctness under rapid motion and multi-model blending.
- Temporal coherence with post-processing is unexplored: diffusion-based stylization/enhancement’s effect on multi-view and temporal consistency is not measured (e.g., flicker, geometry hallucinations, identity preservation).
- Precision trade-offs of FP16 packing are not ablated: impact on depth sorting accuracy, covariance estimation, and color fidelity (including how half-precision affects extremely anisotropic splats) is unknown.
- Sorting correctness under ties and near-equal depths is not analyzed: stability guarantees (stable vs. unstable radix sort), tie-breaking strategies, and artifact rates under extreme depth overlap are unspecified.
- Scheduler/frame-budget policy is undefined: how per-frame ONNX inference and rendering are jointly scheduled to meet target FPS, including adaptive quality/resolution, load shedding, and fallback when inference overruns, is not described or evaluated.
- ONNX Runtime WebGPU limitations are not systematically documented: opset coverage, support for custom ops (e.g., HexPlane sampling, SMPL-X kinematics), dynamic output lengths, model graph size limits, and reliability of graph capture across diverse models are unclear.
- The Gaussian Generator contract lacks a formal specification: versioning, optional/required fields, dynamic shapes (variable number of Gaussians), batching semantics, precision requirements, and a compliance test suite are not provided.
- Security and trust are not addressed: risks of running untrusted ONNX graphs in-browser (resource abuse, privacy, model tampering), sandboxing, model signing, resource quotas, and user consent flows remain undefined.
- Fault tolerance and resilience are missing: behavior under WebGPU device loss, inference failures, driver resets, or partial model loads; state recovery and graceful degradation paths are unspecified.
- Mesh–Gaussian composition is limited to occlusion: no unified lighting/shading pipeline (shadows, PBR/BRDF consistency, tone mapping, color space alignment), nor shared shadow maps and relighting integration.
- Anti-aliasing and artifact handling are unreported: MSAA strategies, haloing on high-anisotropy ellipses, edge smoothing, gamma-correct premultiplied alpha, and mitigation of overdraw/fill-rate bottlenecks are not evaluated.
- Multi-model composition scalability is not quantified: contention on global buffers/atomics, sorting cost with many concurrent assets, and memory thrashing under heterogeneous models are not measured.
- Determinism and reproducibility across devices are not evaluated: numerical drift across drivers/GPUs, cross-platform consistency of outputs, and test harnesses for deterministic rendering/inference are missing.
- Developer ergonomics are unstudied: API stability/versioning, documentation completeness, editor usability, integration friction in existing web stacks, and maintenance/testing of the TypeScript plug-in are not assessed.
- Training-to-ONNX export generality is unclear: automation and completeness of export tooling across methods (e.g., PixelSplat/MVSplat/AnySplat, different avatar pipelines), handling of custom ops, licensing/IP constraints, and reproducibility of exports are not detailed.
- Real-time avatar control path is not characterized: end-to-end latency from motion capture/pose estimation to render, smoothing, networking, and multi-user scenarios are not measured.
- Physics and interaction are future work without a plan: collision detection, physical simulation (e.g., MPM), and interaction hooks are proposed but lack design, APIs, and quantitative targets for integration with GS-rendered worlds.
- Integration with IGV/world models remains conceptual: no experimental protocol, datasets, or metrics to evaluate how explicit 3D states (Gaussians) improve IGV consistency, memory, or long-horizon stability.
- Energy efficiency is unknown: power draw and thermal behavior for in-browser inference + rendering (laptops/mobile), and strategies for energy-aware scheduling are not analyzed.
- Browser memory constraints mitigation is incomplete: while noted as a limitation, concrete techniques (model distillation, quantization/pruning, chunked ONNX graphs, on-demand decoding) are not presented or validated.
- Alternative backends/rasterization paths are not compared: conditions under which hardware rasterization or tile-based approaches outperform compute-based pipelines, and hybrid strategies, are not explored.
- Stress testing under rapid camera motion for Visionary is not quantified: while artifact case studies are shown for other viewers, Visionary’s own failure modes, stress thresholds, and visual error rates are not reported.
- Advanced effects are absent: motion blur, depth of field, volumetrics, and consistent post-processing across GS + mesh are not supported or evaluated.
- Global sort algorithm details are sparse: complexity, memory usage, scalability limits (e.g., 32-bit index overflows), and fallbacks for extremely large arrays are not provided.
- Temporal synchronization across multi-component pipelines is unspecified: ensuring consistent timestamps across 3DGS, mesh animations, camera motion, and ONNX generators (e.g., rolling shutter or lens distortion corrections) is not discussed.
- Off-main-thread execution is not examined: use of Web Workers/WASM to reduce main thread contention and mitigate GC-induced jitter is not evaluated.
- Early culling before neural decoding is unexplored: strategies to predict/cull anchors or deformers prior to full decode to reduce per-frame inference cost are not presented.
Practical Applications
Practical Applications of “Visionary: The World Model Carrier Built on WebGPU-Powered Gaussian Splatting Platform”
Visionary is a web-native, WebGPU-based platform that unifies per-frame ONNX inference with real-time 3D Gaussian Splatting (3DGS) and mesh rendering. It standardizes plug-and-play integration via a Gaussian Generator contract and ships a three.js plugin with a concise TypeScript API. Below are actionable applications derived from its findings, methods, and innovations.
Immediate Applications
- Bold web-native 3D product viewers and configurators (Retail/e-commerce)
- What: High-fidelity, click-to-run 3D product pages with dynamic lighting, stylization, and real-time updates; supports hybrid mesh + 3DGS.
- Tools/workflow: three.js plugin integration; ONNX post-processing for style/enhancement; GPU sorting for large catalogs; depth-aware composition with meshes.
- Assumptions/dependencies: WebGPU support on target browsers; product capture pipeline to 3DGS; consumer devices with capable GPUs; content delivery policies (CDN).
- Interactive real estate and AEC tours (Real estate/architecture)
- What: In-browser virtual tours of buildings and renovations; overlay BIM/CAD meshes with splatted reconstructions.
- Tools/workflow: Depth-aware Gaussian–mesh composition; model transforms and frustum/opacity culling; progressive scene loading.
- Assumptions/dependencies: Accurate calibration between capture and BIM; browser memory limits for large scenes; asset conversion to 3DGS.
- Cultural heritage and museum exhibits (Public sector/education)
- What: Frictionless online exhibits of digitized artifacts/sites with high visual quality; runs in browser for broad public access.
- Tools/workflow: Web-based editor and viewer; ONNX-based enhancement for presentation; link-based sharing.
- Assumptions/dependencies: Licensing and IP for public display; scalable hosting of 3D assets; accessibility considerations.
- In-browser reproducibility and benchmarking for 3DGS-family research (Academia)
- What: Unified viewer to compare 3DGS, MLP-based 3DGS (e.g., Scaffold-GS), 4DGS, avatars, and post-processing methods under identical conditions.
- Tools/workflow: Gaussian Generator contract (ONNX I/O + metadata); per-frame inference and rendering in a single runtime; TypeScript API for experiments.
- Assumptions/dependencies: Exportability of models to ONNX; opset compatibility; browser differences in ONNX Runtime/WebGPU.
- Classroom-ready interactive labs and demos (Education)
- What: Students explore neural rendering concepts and world models directly in browser; no CUDA/toolchain installation.
- Tools/workflow: Curated scenes; switchable variants (static 3DGS, dynamic 4DGS); runtime toggles for SH/quantization.
- Assumptions/dependencies: School-managed devices must support WebGPU; bandwidth for asset hosting.
- Browser-based dailies and previsualization (Media/VFX)
- What: Shareable links for directors/clients to review neural scenes; multi-actor compositions; real-time style adjustments.
- Tools/workflow: WebGPU renderer with GPU sorting (stable during fast camera motion); ONNX style/enhancement networks.
- Assumptions/dependencies: Export pipelines from DCC tools into 3DGS/meshes; studio security policies; larger assets may need chunking/compression.
- AV/robotics dataset browsing and playback (Autonomous driving/robotics)
- What: Inspect dynamic 4D scenes (e.g., timestamp-driven 4DGS) from logs; synchronize sensor views; iterate without local installs.
- Tools/workflow: ONNX pre-decoding with timestamp inputs; HexPlane-based deformation deployed in-browser; dataset viewers embedding.
- Assumptions/dependencies: Conversion from raw logs to 4DGS; time alignment; web app authorization for sensitive data.
- Human avatar try-on and motion preview (Fashion/CGI/fitness)
- What: Animatable avatars in browser using SMPL-X-driven deformations; pose/shape control; retail try-on previews or motion coaching.
- Tools/workflow: ONNX-exported avatar models (e.g., LHM, R³-Avatar); client feeds pose/shape parameters; real-time Gaussian warping.
- Assumptions/dependencies: Availability of SMPL-X parameters; privacy/consent for identity data; model footprint fits browser limits.
- Marketing and interactive campaigns (Advertising)
- What: High-impact microsites with interactive 3D experiences; live style transforms and generative filters for branding.
- Tools/workflow: ONNX post-processing (e.g., EXGS); GPU compositing for multi-layer scenes; hosted viewer widgets.
- Assumptions/dependencies: Creative assets converted to 3DGS; content moderation; cross-device performance tuning.
- In-browser asset QA for game and engine teams (Software/gaming)
- What: Lightweight inspection of 3DGS assets and hybrid scenes before engine import; identify sorting/alpha issues early.
- Tools/workflow: three.js plugin embedded in internal tools; GPU-side per-frame preprocessing and global sorting; metrics export.
- Assumptions/dependencies: Export paths from engine/DCC to splats/meshes; GPU availability on CI machines for automated checks.
- Privacy-preserving clinical or lab visualization pilots (Healthcare/research)
- What: Sensitive data stays on device; clinicians/researchers visualize 3D reconstructions without server-side inference.
- Tools/workflow: Client-side ONNX inference with WebGPU; local-only sessions for protected datasets.
- Assumptions/dependencies: Suitability of 3DGS for specific modalities; regulatory review (HIPAA/GDPR); browser memory safeguards.
- City and campus viewers (GIS/urban planning)
- What: Web-native exploration of large spaces (city blocks/campuses) with layered annotations; integrate meshes for infrastructure.
- Tools/workflow: Global GPU sorting; hierarchical scene loading; depth-aware mesh–splat composition.
- Assumptions/dependencies: City-scale 3DGS training pipelines (e.g., CityGaussian); streaming-friendly formats; CORS/CDN.
- Hybrid CAD + capture design reviews (Manufacturing/AEC)
- What: Compare as-designed meshes with as-built scans via 3DGS; identify deviations; annotate and share in browser.
- Tools/workflow: Transform alignment; depth-tested compositing; parametric toggles for visual thresholds.
- Assumptions/dependencies: Accurate registration; asset security; role-based access controls.
Long-Term Applications
- Physics-aware web simulators and digital twins (Manufacturing/robotics/energy)
- What: Couple 3DGS with physics engines (e.g., MPM) for more realistic, interactive simulations in browser.
- Tools/products: WebGPU physics kernels; ONNX-wrapped deformation/physics modules; integrations with engine-independent UIs.
- Assumptions/dependencies: Mature browser physics stacks; stable WebGPU compute across devices; model–physics co-design.
- IGV + explicit 3D state “world model” debugging and authoring (AI research/media)
- What: Interactive pipeline where IGV models output or consume explicit 3D state (splats) for consistency and control.
- Tools/products: “World Model Debugger” combining latent video and 3DGS; standardized ONNX I/O between IGV and Visionary.
- Assumptions/dependencies: Research maturity of 3D-aware IGV; standardized intermediate representations; training–inference alignment.
- City-scale, multi-user digital twins in the browser (Public sector/smart cities)
- What: Real-time collaborative inspection of dynamic city models; integrate IoT feeds and planning overlays.
- Tools/products: Chunked/streaming 3DGS formats; LOD hierarchies (e.g., Hier-GS); auth-enabled collaboration tools.
- Assumptions/dependencies: Browser memory and threading limits; streaming standards and compression; municipal data policies.
- WebXR telepresence and immersive collaboration with avatars (Enterprise/education)
- What: Multi-user sessions with animatable avatars rendered via 4DGS in WebXR; spatialized meetings/classes.
- Tools/products: WebXR integration with Visionary; real-time pose capture; networked state sync.
- Assumptions/dependencies: Mobile WebGPU performance; low-latency networking; privacy and identity safeguards.
- Sim-to-real robotics training hubs (Robotics/AI)
- What: Use Visionary as a front-end for physics-based training (e.g., Isaac Gym) and domain adaptation; deploy learned policies in consistent 3D scenes.
- Tools/products: Connectors to vectorized simulators; relighting/domain adaptation modules; scenario authoring UIs.
- Assumptions/dependencies: Reliable interop with native simulators (WebAssembly/native bridge); licensing; compute budgets.
- Policy and procurement standards for open, web-native 3D (Policy/government)
- What: Encourage ONNX-based, browser-executable 3D experiences in public tenders to ensure accessibility and reproducibility.
- Tools/products: Reference RFP clauses; compliance checklists (WebGPU, ONNX, accessibility); open data portals with Visionary viewers.
- Assumptions/dependencies: Inter-agency consensus; training for procurement officers; alignment with cybersecurity guidelines.
- Clinical planning and patient education in-browser (Healthcare)
- What: 4D procedural rehearsal and patient-specific education with explicit 3D states; secure, local-first workflows.
- Tools/products: Specialized medical ONNX models; verifiable logging; clinician-oriented UI.
- Assumptions/dependencies: Regulatory approval and validation; fit-for-purpose fidelity; device management in clinics.
- Insurance and finance risk assessment via 3D captures (Finance/insurance/real estate)
- What: Use mobile captures→3DGS to assess claims, property conditions, and collateral—reviewable in a secure browser.
- Tools/products: Capture-to-3DGS pipelines; audit trails and chain-of-custody tooling; standardized assessment UIs.
- Assumptions/dependencies: Legal admissibility of reconstructions; data integrity protections; edge device variability.
- CDN and streaming standards for Gaussian content (Software/CDN)
- What: Define progressive/streaming formats for splats and dynamic deformations (4DGS); DRM and caching strategies.
- Tools/products: “3DGS CDN” services; chunked ONNX/state streaming; client-side LOD controllers.
- Assumptions/dependencies: Community agreement on formats; browser streaming APIs; robust compression/pruning (e.g., Compact-3DGS).
- Mobile-first and edge deployments (Consumer devices/IoT)
- What: Bring Visionary-class experiences to phones/tablets/embedded devices at scale.
- Tools/products: Aggressive pruning/compression and FP16 pipelines; workload-aware schedulers; partial server-assist fallbacks.
- Assumptions/dependencies: Broader WebGPU adoption (especially Safari/iOS); thermal/power constraints; offline-first packaging.
- Authoring marketplace and plugin ecosystem (Creator economy/software)
- What: SaaS “Gaussian Editor” and marketplace for generative filters, avatar rigs, 4D assets, and analytics.
- Tools/products: Contract-validated ONNX plugins; storefront and rating systems; enterprise support tiers.
- Assumptions/dependencies: IP management and licensing; moderation; sustainable developer incentives.
- Secure evidence presentation and public transparency portals (Policy/justice)
- What: Courts, councils, and agencies present 3D evidence and planning proposals in accessible web viewers with local processing options.
- Tools/products: Tamper-evident packaging; chain-of-custody metadata; redaction and access controls.
- Assumptions/dependencies: Legal frameworks for digital exhibits; strict audit requirements; accessibility compliance.
Notes on feasibility across applications:
- Browser technology: Requires modern browsers with WebGPU and ONNX Runtime Web support (currently best on Chromium; Safari/mobile support varies).
- Model export: Methods must export to ONNX; some ops may need rewriting or chunking; FP16 paths recommended for performance.
- Memory and security: Browser memory limits and CSPs affect maximum scene/model size; large post-processing may need offline or progressive designs.
- Hardware variability: Performance depends on device GPU/driver; fallbacks and LOD strategies are essential.
- Data governance: Privacy, consent, and IP ownership are critical for avatars, medical data, city models, and evidence use cases.
Glossary
- Affine transformation: A linear mapping that preserves points, straight lines, and planes, often used for scaling, rotating, and translating geometry. "applies a user-defined affine transformation to "
- Alpha compositing: A technique for combining semi-transparent layers based on per-pixel alpha values to produce the final image. "Following front–to–back alpha compositing, the rendered color at pixel is computed as"
- Anisotropic 3D Gaussian: A Gaussian distribution with direction-dependent variance in 3D space, used as rendering primitives. "Gaussian Splatting represents a scene as a set of anisotropic 3D Gaussian primitives:"
- Atomic counter: A GPU-side atomic integer used to safely accumulate counts or indices across parallel threads. "Valid splats are appended into global buffers via an atomic counter"
- Back-to-front order: Rendering order where farther elements are drawn before nearer ones to correctly composite transparency. "are alpha-composited in back-to-front order."
- Bilinear interpolation: A method to interpolate values on a 2D grid by linearly interpolating in two dimensions. "to retrieve corresponding feature vectors via bilinear interpolation."
- Canonical space: A fixed, neutral configuration of a scene or object used as a reference for deformation or animation. "their modeling often combines a canonical space with a neural deformable field."
- Clip space: A coordinate space after projection where geometry is clipped before viewport transformation. "transforms its parameter units to camera space and clip space"
- Constant folding: A compiler/export optimization that precomputes constant expressions to simplify runtime graphs. "invoke torch.onnx.export() with appropriate input/output names, opset version, and constant folding."
- Covariance matrix: A matrix describing the spread and orientation of a Gaussian distribution. "a covariance matrix , which is derived from a scale and a rotation quaternion "
- Depth-aware composition: Blending strategy that uses depth information to correctly occlude and combine different layers. "and composes them via depth-aware composition."
- Depth buffer: A texture storing per-pixel depth values used to resolve visibility. "we first rasterize the mesh to obtain a depth buffer $D_{\text{mesh}$"
- Depth test: A GPU test that compares fragment depth against the depth buffer to determine visibility. "we keep depth test enabled but depth write disabled"
- Diffusion denoiser (U-Net): A neural architecture used in diffusion models to iteratively remove noise and generate images. "we export the diffusion denoiser (U-Net~\cite{ronneberger2015u,ho2020denoising}) to a Web-friendly ONNX graph."
- Feedforward generative post-processing: Non-iterative neural enhancement or stylization applied after rendering. "Such inference also enables us to apply feedforward generative post-processing."
- Forward kinematics: Computing joint transformations from skeletal pose parameters to drive deformations. "the skeletal forward kinematics and per-Gaussian deformation can be exported into the ONNX graph"
- Frustum culling: Removing objects outside the camera’s view frustum to save rendering work. "performs frustum and opacity culling to remove invalid splats"
- Gaussian Generator contract: A standardized ONNX I/O schema specifying how per-frame algorithms output Gaussians. "We formalize this interface as the Gaussian Generator contract"
- Graph capture: Recording and reusing a GPU execution graph to reduce dispatch overhead across frames. "make the inference path compatible with WebGPU graph capture."
- GPU radix sort: A parallel sorting algorithm on the GPU used for ordering primitives by depth. "we perform a GPU radix sort~\cite{mcilroy1993engineering} over depths"
- HexPlane: A factorized spatiotemporal feature representation using six orthogonal 2D planes. "4D Gaussians employs an efficient HexPlane representation (akin to K-Planes~\cite{kplanes_2023})"
- Initializers: ONNX graph constants embedded in the model for parameters like canonical Gaussians. "embedded the canonical Gaussian attributes directly as internal constant tensors (Initializers)"
- Instanced rasterization: Rendering many similar primitives by reusing geometry with per-instance data. "and then draw all splats using instanced rasterization."
- Interactive Generative Video (IGV): A paradigm where world models simulate environments as sequences of latent video frames. "simulate the ``world'' as a sequence of 2D latent frames, manifested as Interactive Generative Video (IGV)."
- Jacobian: The matrix of partial derivatives describing local transformations under projection. "where denotes the Jacobian of at ."
- K-Planes: A multi-plane representation for neural fields used to factorize high-dimensional features. "akin to K-Planes~\cite{kplanes_2023}"
- Linear Blend Skinning (LBS): A standard technique to deform meshes or primitives by blending joint transformations with skinning weights. "The deformation is generally modeled via Linear Blend Skinning (LBS)."
- LPIPS: A perceptual image similarity metric learned from deep features. "in termps of PSNR, SSIM and LPIPS"
- Material Point Method (MPM): A physics simulation method combining particles and grids to model continuum materials. "Material Point Method (MPM) to simulate realistic dynamics"
- Multi-layer perceptron (MLP): A feedforward neural network used to decode Gaussian parameters from features. "which is fed into a multi-layer perceptron (MLP) to generate neural Gaussian parameters:"
- Neural Radiance Fields (NeRF): A neural representation that maps 3D coordinates and viewing direction to radiance and density. "Neural Radiance Fields (NeRF)~\cite{mildenhall2020nerf,barron2021mip,pumarola2021d,fridovich2022plenoxels,muller2022instant,li2023dynibar,zhan2024kfd}"
- Normalized Device Coordinates (NDC): A normalized coordinate space after projection, typically ranging from -1 to 1. "computes the 2D ellipse eigenvectors and NDC center "
- ONNX (Open Neural Network Exchange): An open standard for representing ML models to enable interoperability across frameworks and runtimes. "ONNX (Open Neural Network Exchange) serves as an open standard for machine learning interoperability"
- Opset version: The ONNX operator set version specifying supported ops semantics for export and runtime. "invoke torch.onnx.export() with appropriate input/output names, opset version, and constant folding."
- Opacity culling: Removing primitives below a minimum opacity threshold to reduce overdraw. "performs frustum and opacity culling to remove invalid splats"
- Packed layout: A compact memory organization for batched attributes to reduce bandwidth and improve performance. "in a packed layout (position, opacity, upper-covariance, and appearance)"
- Parametric body model: A statistical human body model parameterized by pose and shape for animation and reconstruction. "driven by a parametric body model (e.g, SMPL-X~\cite{SMPLX2019})"
- Primitive sorting: Ordering renderable primitives by depth or other criteria to ensure correct blending. "due to GPU-based primitive sorting."
- PSNR: Peak Signal-to-Noise Ratio, an image fidelity metric based on pixel-wise error. "in termps of PSNR, SSIM and LPIPS"
- Quaternion: A four-dimensional representation of rotation used to parameterize Gaussian orientation. "a rotation quaternion "
- SE(3): The Lie group of 3D rigid-body transformations combining rotation and translation. "a global transformation matrix for each joint ."
- SMPL-X: A parametric 3D human body model with expressive hands and face used for avatar animation. "driven by SMPL-X~\cite{SMPLX2019}"
- Spherical harmonics: Basis functions used to encode view-independent color or lighting on the sphere. "a view‑independent color encoded by spherical harmonics."
- Splatting: Rendering technique that projects volumetric primitives (Gaussians) onto the image plane and blends their contributions. "Gaussian Splatting represents a scene as a set of anisotropic 3D Gaussian primitives:"
- SSIM: Structural Similarity Index, an image quality metric assessing structural fidelity. "in termps of PSNR, SSIM and LPIPS"
- Three.js plug-in: An extension module for the three.js WebGL/WebGPU library to integrate custom renderers. "Visionary’s core system is packaged as a three.js plug-in for seamless extension and integration."
- Upper-triangular: The top-right half of a symmetric matrix used to store covariance efficiently. "and the upper-triangular 6-tuple are stored as ."
- Voxel grid: A 3D grid of volumetric cells used to place anchors or organize spatial features. "extract a sparse voxel grid and place anchors at the centers of occupied voxels."
- WebGL: A legacy web graphics API based on OpenGL ES, limited for general compute and dynamic pipelines. "are constrained by legacy \href{https://get.webgl.org/}{WebGL} pipelines"
- WebGPU: A modern web graphics and compute API enabling GPU-accelerated rendering and inference in browsers. "Visionary renders multiple 3DGS models together with optional mesh assets in a single WebGPU pipeline"
- World model: A model that predicts future states of an environment by internalizing its dynamics and structure. "A world model aims to internalize the governing laws of a physical environment, learning to predict future states based on current observations and actions."
Collections
Sign up for free to add this paper to one or more collections.