- The paper introduces a minimax optimization framework that leverages Wasserstein geometry to generate worst-case distributions in adversarial settings.
- It employs a single-loop gradient descent-ascent algorithm with neural transport mapping to ensure both computational efficiency and robust convergence.
- Empirical results on tasks like MNIST and CIFAR-10 validate the model’s scalability and effectiveness in robust risk mitigation.
Worst-case Sample Generation via Minimax Optimization in Wasserstein Space
The paper "Worst-case generation via minimax optimization in Wasserstein space" (2512.08176) develops a minimax framework for risk-driven adversarial data generation with an explicit focus on distributionally robust optimization (DRO) using Wasserstein geometry. The central objective is to construct and sample worst-case distributions that exhibit maximal risk with respect to a decision model, surpassing traditional discrete DRO approaches both in expressiveness and computational tractability.
The minimax formulation commences from the penalized DRO objective:
θ∈RpminQ∈P2maxEv∼Q[ℓ(θ,v)]−2γ1W22(Q,P),
where P is the reference distribution, θ parametrizes the decision model, ℓ is a loss function, and γ controls the radius of the ambiguity set. Leveraging the Brenier theorem, the inner maximization over Q is equivalently reformulated via a transport map T: Q=T#P, reducing adversarial learning to functional space optimization.
Algorithmic Framework: Gradient Descent-Ascent and Neural Transport
The essential contribution is a single-loop gradient descent-ascent (GDA) scheme which jointly and efficiently updates the model parameters θ and the transport map T. The gradient expressions for (θ,T) are derived:
- ∂θL(θ,T)=Ex∼P∂θℓ(θ,T(x))
- ∂TL(θ,T)(x)=∂vℓ(θ,T(x))−γ1(T(x)−x)
The GDA recursion is given by:
θk+1=θk−τ⋅∂θL(θk,Tk);Tk+1(x)=Tk(x)+η⋅∂TL(θk,Tk)(x),
where (τ,η) are step sizes, and the updates operate either in vector or function space.
Further, a neural network parametrization Tφ of the transport map is introduced and trained via L2-matching loss to ensure out-of-sample generalization and scalability to high-dimensional data, such as images.
Convergence Theory
The paper establishes nonconvex convergence guarantees for the GDA algorithm under Polyak-Łojasiewicz (PL) or strong concavity conditions, without requiring convexity-concavity of the objective. The minimax problem admits two regimes:
- T-fast (Inner maximization): Under an NC-PL assumption, GDA finds an ϵ-stationary point in O(ϵ−2) iterations for arbitrary γ, with step sizes set relative to smoothness and condition number derived from ℓ and γ, ensuring stability even for large perturbations.
- θ-fast (Inner minimization): When L(θ,T) is strongly concave in θ after averaging over T#P, similar convergence rates apply (again O(ϵ−2)), contingent on a class of "good" transport maps which preserve concavity.
A more general regime with nonconvex-nonconcave structure (NC-NC) is handled using a one-sided proximal point method (PPM), also achieving O(ϵ−2) stationary point complexity under interaction-dominant landscape assumptions.
Empirical Analysis
Validation is performed on synthetic regression and image classification tasks (e.g., MNIST, CIFAR-10 in the latent VAE space), comparing GDA's particle optimization and neural map learning to classical elimination approaches.
Empirical results demonstrate:
- Steady and monotonic decrease of gradient norms for both θ and T (Figure 1, Figure 2, Figure 3),
- Rapid convergence that matches or surpasses elimination-based (double-loop) methods, especially in terms of the number of gradient evaluations,
- Successful generalization of the neural transport map Tφ to test samples, evidenced by semantically meaningful adversarial deformations interpolated in latent space (Figure 4).
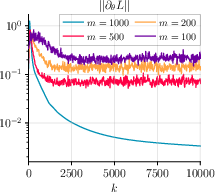
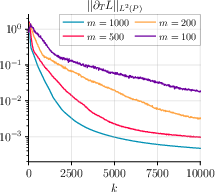
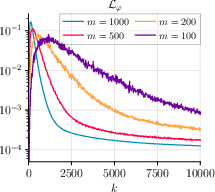
Figure 1: GDA with momentum on MNIST using different batch sizes yields consistent convergence, with gradient norms GNθ and GNT steadily decreasing across mini-batches for γ=8.0.

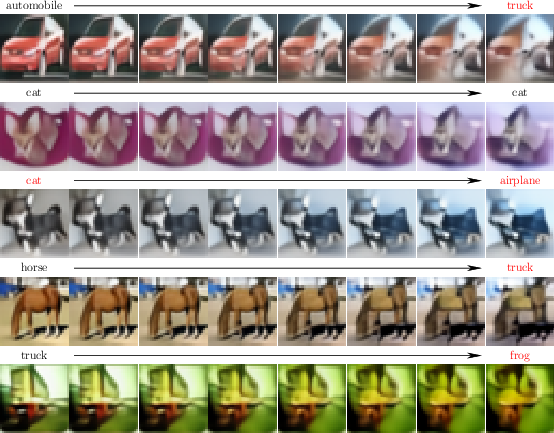
Figure 5: Illustrative results of particle optimization and sample trajectories in MNIST latent space, showing effective worst-case sample generation and model stress testing.
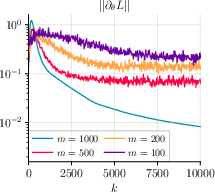
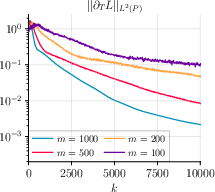
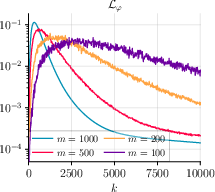
Figure 2: GDA without momentum on MNIST displays similar convergence properties, confirming the robustness of the single-loop minimax strategy.
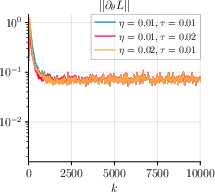
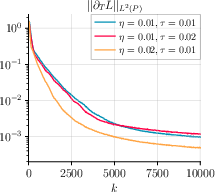
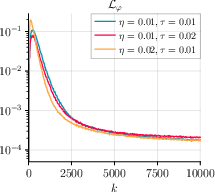
Figure 3: GDA with momentum and varying step sizes η, τ highlights the algorithm’s stability and efficacy for different configurations with batch size m=500.

Figure 4: Interpolation panels document the learned deformations for test samples and their nearest neighbors, underscoring the neural transport map’s generalization capacity beyond the training distribution.
Theoretical and Practical Implications
Contrary to discrete DRO, which is computationally inhibitive and lacks generalization beyond training samples, the proposed continuous transport-map-based minimax approach enables expressive, risk-tailored generation of worst-case data points and is computationally scalable via neural parameterization and stochastic GDA.
The convergence theory provided accommodates large ambiguity radii γ, enabling exploration of worst-case distributions that can induce substantial distributional shifts. This is relevant for robust machine learning, stress-testing in operational domains (autonomous systems, power grids, healthcare), and for designing models with strong risk mitigation capabilities.
The framework’s reliance on Wasserstein geometry and functional optimization opens possibilities for future use of more advanced first-order minimax algorithms (e.g., OGDA, extragradient), extension to multimodal or highly structured distributions, and further analysis of neural approximation error in functional spaces.
Conclusion
This work advances risk-induced generative modeling under distributional uncertainty by reformulating adversarial DRO as functional minimax optimization in Wasserstein space, validated by strong theoretical convergence guarantees and empirical studies on high-dimensional tasks. The neural transport map ensures scalability and generalization, offering a principled route toward simulation-free, robust worst-case sample generation. Future directions include extending minimax theory to richer neural architectures and broader domains, and analyzing approximation effects induced by neural parameterizations.

