- The paper demonstrates that models with peak metric accuracy diverge from human perceptual error patterns, following an inverse-U relationship.
- It introduces a novel human-annotated depth dataset and employs affine error decomposition to dissect systematic biases in DNN depth estimates.
- The findings suggest that optimizing solely for accuracy can lead to non-human-like, brittle behaviors in critical computer vision applications.
Accuracy Does Not Guarantee Human-Likeness in Monocular Depth Estimators
Introduction
Monocular depth estimation (MDE) constitutes a central task in computational 3D vision, underpinning applications such as autonomous driving and robotic perception. The established paradigm for MDE evaluation emphasizes pixel-wise accuracy against sensor-based ground truth (e.g., LiDAR), but this axis alone is agnostic to the extensive literature on the representational divergence between DNNs and human perception. Recent object recognition research has demonstrated that increasing accuracy on physical benchmarks does not necessarily entail behavioral or representational convergence with the human visual system. The present study critically investigates whether this decoupling manifests in MDE, leveraging a novel human-annotated depth dataset for the KITTI outdoor benchmark, and evaluating the behavioral alignment of 69 state-of-the-art DNNs.
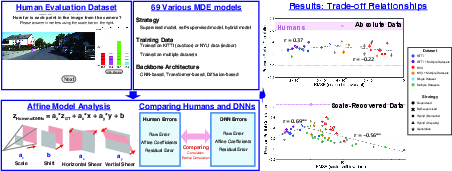
Figure 1: Overview of the research pipeline integrating the construction of a human depth evaluation dataset, large-scale DNN benchmarking, and affine decomposition of estimation errors.
Human-Centric Depth Dataset and Experimental Protocol
The human evaluation framework involved psychophysical collection of absolute depth judgments from 890 participants for 16 query points per image across 328 KITTI scenes. To maximize the consistency and informativeness of estimates, depth judgments were collected for groups of four points simultaneously, mitigating isolated local uncertainty. Outlier filtering by intra-group correlation produced a high-quality dataset (average n=17.9 observers per scene). This sampling strategy ensures that the error structure reflects robust, internally consistent perceptual biases, not idiosyncratic noise. The resulting dataset enables the first systematic, per-image comparison of residual error structure between humans and MDE models on KITTI.
DNN Model Benchmarking and Evaluation Procedure
The tested models span the contemporary landscape of MDE, including convolutional, transformer, hybrid, and diffusion-based architectures, with training strategies encompassing supervised, self-supervised, and hybrid protocols. Models were trained on either in-distribution (KITTI), out-of-distribution (NYU, Bonn, DDAD, TUM), or mixed-domain datasets. To ensure comparability of error patterns across models with heterogeneous output spaces (absolute, relative, or disparity), all estimates were brought to a common scale via per-image affine alignment against physical depth.
Behavioral similarity between DNNs and humans was quantified as a partial correlation (controlling for physical ground truth) between estimation residuals, computed across repeated random observer splits to ensure robustness (1,000 split iterations per model). Performance was independently assessed for raw error and after factorizing systematic biases with an affine decomposition (scale, shift, horizontal/vertical shear, and residual error).
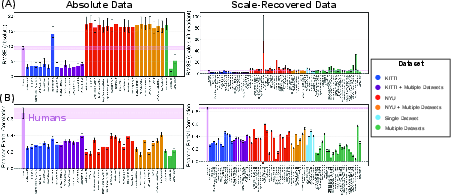
Figure 2: Comparative evaluation of RMSE and human-DNN error pattern correlation for absolute and scale-recovered depth estimators.
Results
DNN Accuracy vs. Human-Likeness: The Core Trade-Off
Analysis of 69 models reveals that optimal RMSE with respect to physical ground truth is predominantly achieved by in-distribution KITTI-trained models, which systematically outperform both out-of-distribution DNNs and human observers in metric accuracy. However, higher metric accuracy does not correspond to greater human-likeness. Instead, as model accuracy increases beyond human-level, the correlation between human and DNN error patterns forms a pronounced inverse-U relationship: models achieving the lowest RMSE display lower similarity to the structure of human perceptual errors. Models with approximately human-level accuracy (but no explicit human data in training) are most behaviorally aligned with humans.
This relationship is robust across both absolute and scale-invariant metrics, with the trade-off particularly pronounced when affine normalization is applied. Quantitatively, Pearson correlations between log-RMSE and human similarity reverse sign across the human-superior and human-inferior regimes, confirming the effect is not an artifact of summary statistics or sample partitioning.
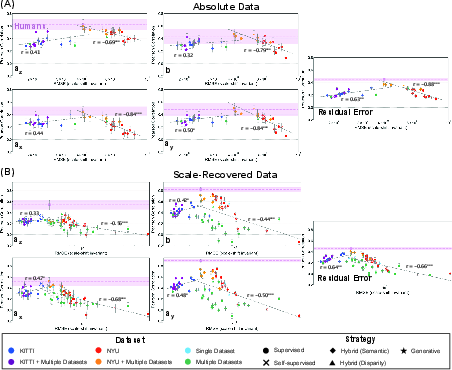
Figure 3: Trade-off between metric accuracy and behavioral human-likeness across affine error components, demonstrating an inverse-U relationship.
Affine Decomposition: Dissecting Systematic Biases
Affine error decomposition exposes how human-DNN alignment or divergence is distributed across geometric error components. The trade-off resurfaces—and strengthens—at this more granular level: models with moderate (human-level) accuracy best match human biases in all affine coefficients (scale, shift, horizontal/vertical shear), not just in aggregate error. Superior-performing models, especially those heavily optimized for KITTI, deviate in each of these systematic biases, converging toward “unnatural” error geometries not exhibited by the human visual system.
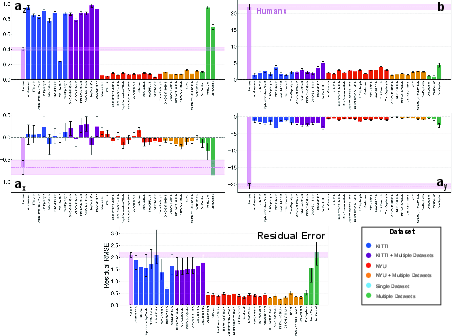
Figure 4: Comparison of affine bias and residual error components for humans and a representative subset of 36 DNNs (absolute depth outputs).
Consistency Across Architectures and Datasets
Across model classes (CNNs, Transformers, hybrids), backbone effects are minor relative to data regime effects. Transformer architectures show a slight, but non-uniform, human-similarity advantage at equal accuracy. Training on NYU or other environments produces higher human-similarity for some model backbones, implying that statistical properties of the training distribution critically mediate alignment. Self-supervised or hybrid protocols do not, in isolation, yield more human-like error patterns.
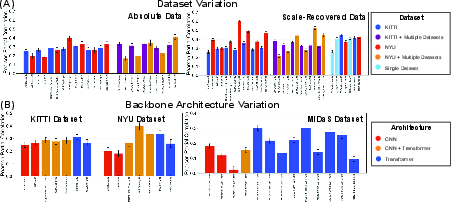
Figure 5: Disaggregated analysis of human-DNN similarity by (A) dataset and (B) backbone architecture.
Qualitative Error Analysis
Qualitative visualization of error maps corroborates quantitative findings. Both humans and the most human-like DNNs exhibit overestimation for vertical structures (e.g., walls, distant vehicles) and characteristic shearing distortions along the KITTI ground plane, reflecting the affine structure of visual space and consistent with established perceptual studies. The most accurate SOTA DNNs are instead less biased but achieve their success via error patterns never observed in any human participant, indicating a reliance on dataset-specific or synthetic cues.
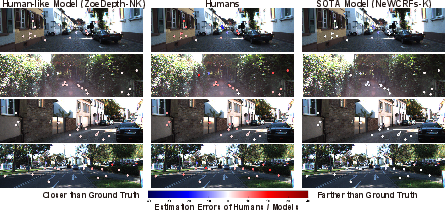
Figure 6: Example images showing horizontal and vertical shear biases (ax, ay) manifested in human depth estimates, contrasted to DNN outputs.
Implications
The central claim—metric accuracy does not guarantee human-likeness in monocular depth estimation—is strongly supported quantitatively and qualitatively. This has critical implications for both AI safety/interpretability and the design of robust visual reasoning systems. Models optimized exclusively for physical accuracy on narrow data regimes (e.g., KITTI) develop estimation strategies divergent from human priors, potentially leading to brittle out-of-distribution behavior and adversarial vulnerability. Conversely, models with more mid-level accuracy (across varied data) achieve robust human-like error patterns without explicit perceptual supervision.
Integrating human-centric benchmarks as an orthogonal axis to physical accuracy is not only a matter of interpretability but also of improving generalization. Whether maximizing human-similarity entails increased robustness to novel contexts remains an open but crucial research direction. The public release of data and code will facilitate further systematic explorations of these hypotheses.
Future Directions
Key questions raised include:
- Can models optimized for both human-likeness and metric accuracy outperform human observers in both domains, or is a trade-off intrinsic to data and task structure?
- How does explicit integration of human perceptual priors (e.g., via data augmentation, loss design, or representational regularization) shift the balance between accuracy and robustness?
- What are the algorithmic consequences of embedding human-like biases (such as affine distortion or depth compression) in safety-critical systems?
Further, while human-like MDE can enhance human-AI alignment and interpretability, propagation of human perceptual biases into automated decisions raises ethical and operational challenges.
Conclusion
A comprehensive evaluation of 69 state-of-the-art MDE models against a new large-scale human perceptual dataset reveals that monotonically increasing accuracy on physical benchmarks as traditionally defined leads to greater divergence from human error patterns. Only models at or near human-level RMSE exhibit estimation biases and residual structure consonant with the human visual system. These findings mandate the adoption of multifaceted, human-centered benchmarks in vision model evaluation and provide robust evidence against the sufficiency of physical accuracy as the sole criterion for model excellence and reliability.
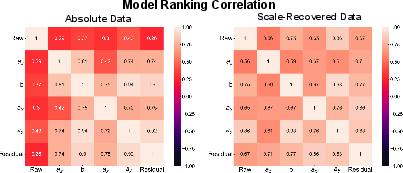
Figure 7: Strong consistency in human-similarity ranking across affine error components, demonstrating robustness of the central result.

