- The paper presents a novel point cloud framework that exploits spatiotemporal sparsity and edge-aware enhancement for improved 3D human pose estimation.
- It utilizes structured temporal modules (ES-Seq and ETSC) to capture local motion cues, achieving significant MPJPE improvements on multiple backbones.
- The method demonstrates robust performance in low illumination and fast motion scenarios with real-time inference below 4 ms.
Exploiting Spatiotemporal Properties for Efficient Event-Driven Human Pose Estimation
Introduction
This work addresses the limitations of prior event-driven human pose estimation methods by leveraging the inherent spatiotemporal sparsity of event streams through a point cloud-based pipeline. Most current approaches destructively convert event data into dense frames for convolutional processing, thereby discarding the high temporal resolution critical for accurate, low-latency pose inference in challenging scenarios, such as low illumination and fast motion. The method introduced here circumvents these pitfalls via explicit temporal structure modeling and spatial edge-aware enhancement, with demonstrated integration and empirical gains across multiple point cloud backbones on the DHP19 benchmark.
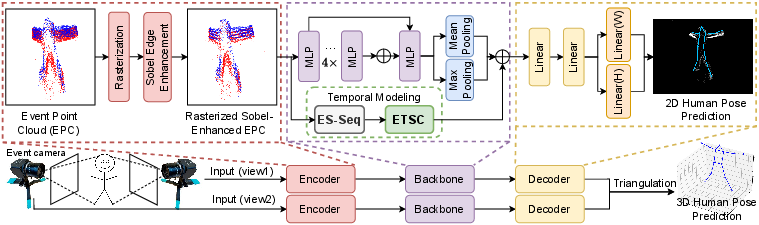
Figure 1: The proposed pipeline—highlighting the rasterization with Sobel-based edge enhancement, temporal modules (ES-Seq and ETSC), and SimDR decoding with triangulation—enables end-to-end 3D pose estimation from dual-view event data.
Methodology
Event Point Cloud Representation and Spatial Enhancement
The proposed framework utilizes the rasterized event point cloud paradigm, where each event is encoded as a 5D vector combining pixel coordinates, average timestamp, accumulated polarity, and event count over a fixed microsecond-resolution temporal window. This efficiently preserves sparsity while maintaining spatial and temporal granularity. To further enhance spatial feature localization under sparse conditions, a Sobel-based edge enhancement is applied directly in the voxel grid domain. This module boosts the polarity dimension via Sobel-weighted per-pixel modulation, which aids network discriminability of body part contours and motion boundaries.
Structured Temporal Modeling: ES-Seq and ETSC
Temporal contextualization is achieved in two distinct stages. First, the Event Slice Sequencing (ES-Seq) module segments the event cloud into K temporally consistent slices according to normalized timestamps, forming a coarse short intra-window sequence where local feature tokens are obtained by max pooling within each slice.
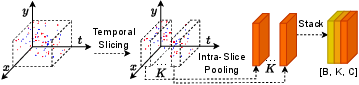
Figure 2: ES-Seq discretizes the event cloud into temporally ordered slices, yielding a sequence of maximal feature tokens.
Next, structured temporal dependencies are modeled via the Event Temporal Slice Convolution (ETSC) module, which applies both standard and dilated 1D convolutions with residual connections across the slice token sequence. This architecture efficiently captures short-term, local spatiotemporal motion cues while mitigating the vanishing gradient and limited receptive field drawbacks of classical temporal convolutions.
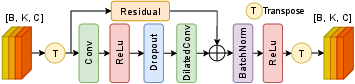
Figure 3: ETSC module: a stack of standard and dilated convolutions with residual connections extracts inter-slice dependencies from short, sparse event sequences.
The post-temporal features are pooled and fused with globally pooled spatial features (max and avg), furnishing a rich composite representation for the downstream pose decoding network, which utilizes SimDR for 2D keypoint estimation and triangulation for 3D pose reconstruction.
Experimental Results
Quantitative Analysis
Empirical results on the DHP19 dataset establish consistent performance gains across PointNet, DGCNN, and Point Transformer backbones. The method achieves the following MPJPE improvements:
- PointNet: 2D MPJPE reduced from 7.34 to 7.09, and 3D MPJPE from 83.12 mm to 80.16 mm.
- DGCNN: 2D reduced from 6.85 to 6.49, and 3D from 77.68 mm to 72.91 mm.
- Point Transformer: 2D improved from 6.57 to 6.38, and 3D from 74.30 mm to 72.16 mm.
The DGCNN backbone, with the temporal and spatial modules, surpasses the more complex Point Transformer baseline while maintaining lower computational cost. Inference latency remains well below 4 ms on an RTX 5090, compatible with real-time applications.
Qualitative Analysis
Visualization of pose estimation results illustrates improved robustness to subtle motion and static region ambiguities, particularly by reducing edge blurring and enhancing skeleton localization, as compared to baselines.
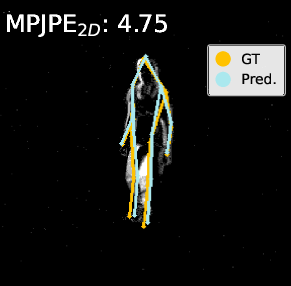
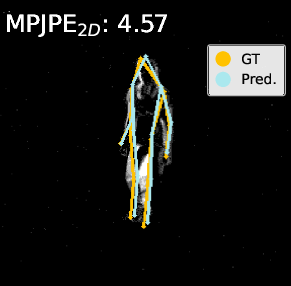
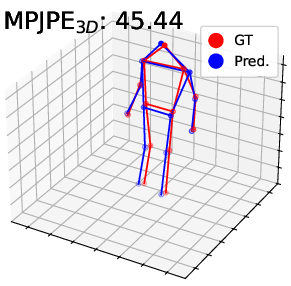
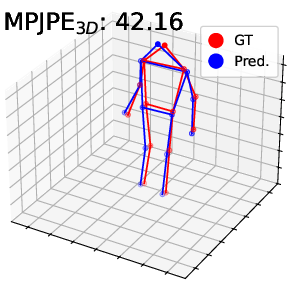
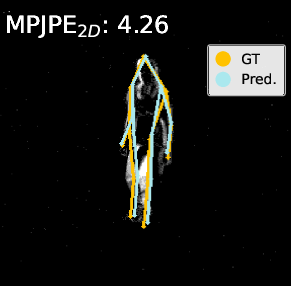
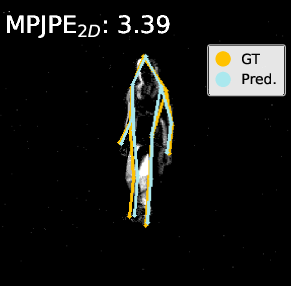
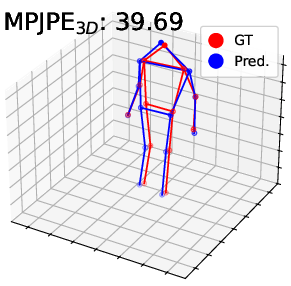
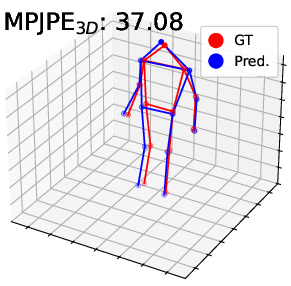
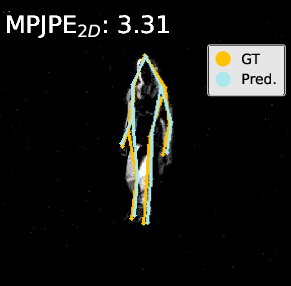

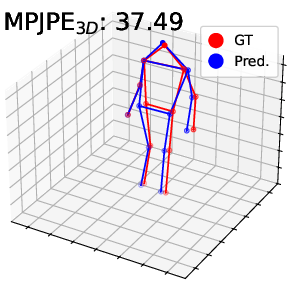
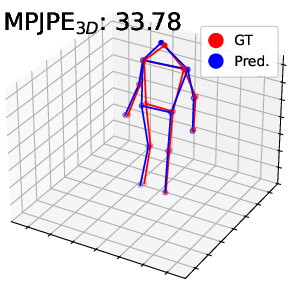
Figure 4: Visualization on DHP19—predicted 2D/3D poses for PointNet, DGCNN, and Point Transformer. The proposed pipeline (right) yields more accurate and faithful keypoint predictions, especially under motion blur and spatial ambiguity.
Ablation Study
Ablation demonstrates that temporal modeling contributes an approximate 3% gain in MPJPE, while additional Sobel-based spatial edge enhancement boosts accuracy by another 0.4%. These gains hold for both 2D and 3D metrics, corroborating the synergistic effect of joint spatiotemporal modeling.
Implications and Future Directions
This work marks a significant technical advance in event-driven human pose estimation, offering: (1) a principled pipeline with explicit compositional modules for spatial and temporal feature enhancement; (2) generality and plug-and-play integration with representative point cloud backbones; (3) efficiency superior to frame-based approaches in terms of both parameter count and FLOPs.
Practically, this enables robust pose estimation in environments and applications where traditional visual signals fail, such as high-speed cinema, clinical biomechanics, autonomous robotics, and AR/VR with strict latency budgets. Theoretically, it opens inquiry into more powerful, yet modular, spatiotemporal operations on neuromorphic data and motivates exploration of transformer-based or graph-based architectures directly on event clouds. Potential developments include adaptive temporal slicing, attention-based aggregation, and event-driven training protocols that more rigorously adapt to the statistics of asynchronous vision.
Conclusion
A structured, edge-aware, temporally explicit event point cloud pipeline for human pose estimation demonstrates clear quantitative and qualitative gains over previous methods. The approach effectively utilizes event camera sparsity, efficiently captures cross-slice temporal dependencies, and enhances spatial boundaries for robust keypoint prediction, as confirmed across multiple architectures and ablation settings on DHP19. This research strengthens the foundation for future explorations in efficient event-based motion analysis and broadens the applicability of event-driven perception paradigms.

