Sell Data to AI Algorithms Without Revealing It: Secure Data Valuation and Sharing via Homomorphic Encryption
Abstract: The rapid expansion of Artificial Intelligence is hindered by a fundamental friction in data markets: the value-privacy dilemma, where buyers cannot verify a dataset's utility without inspection, yet inspection may expose the data (Arrow's Information Paradox). We resolve this challenge by introducing the Trustworthy Influence Protocol (TIP), a privacy-preserving framework that enables prospective buyers to quantify the utility of external data without ever decrypting the raw assets. By integrating Homomorphic Encryption with gradient-based influence functions, our approach allows for the precise, blinded scoring of data points against a buyer's specific AI model. To ensure scalability for LLMs, we employ low-rank gradient projections that reduce computational overhead while maintaining near-perfect fidelity to plaintext baselines, as demonstrated across BERT and GPT-2 architectures. Empirical simulations in healthcare and generative AI domains validate the framework's economic potential: we show that encrypted valuation signals achieve a high correlation with realized clinical utility and reveal a heavy-tailed distribution of data value in pre-training corpora where a minority of texts drive capability while the majority degrades it. These findings challenge prevailing flat-rate compensation models and offer a scalable technical foundation for a meritocratic, secure data economy.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains a way to let people sell useful data to AI systems without showing the actual data. It tackles a big problem: buyers want to know if a dataset will help their AI model before paying, but as soon as they look at it, they could copy it without paying. The authors introduce a method called the Trustworthy Influence Protocol (TIP) that lets a buyer measure how helpful a piece of data would be—while the data stays locked and unreadable the whole time.
What questions does it try to answer?
- How can an AI buyer estimate how much a new piece of data will improve their model without seeing the data?
- Can this be done in a way that keeps both the buyer’s and seller’s information private?
- Is the estimation accurate for big AI models like BERT or GPT‑2?
- What does this mean for real data markets (like healthcare or books used to train AI)?
How did the researchers approach the problem?
The authors combine two ideas: a way to measure a data point’s usefulness to a model, and a way to do math on locked (encrypted) data.
The key idea: scoring data without seeing it
- Think of training an AI model like learning from homework. A “gradient” tells you how a single example nudges the model to get better or worse. If an example nudges the model in a good direction, it’s valuable.
- An “influence score” estimates how much adding one new example would improve the model’s performance on the buyer’s chosen tests. It’s like asking: “If I learn from this one homework problem, will my test score go up?”
- Normally, to compute that score, you need details from the seller’s data and the buyer’s evaluation set. That would reveal secrets. So the authors keep everything encrypted and still compute the score.
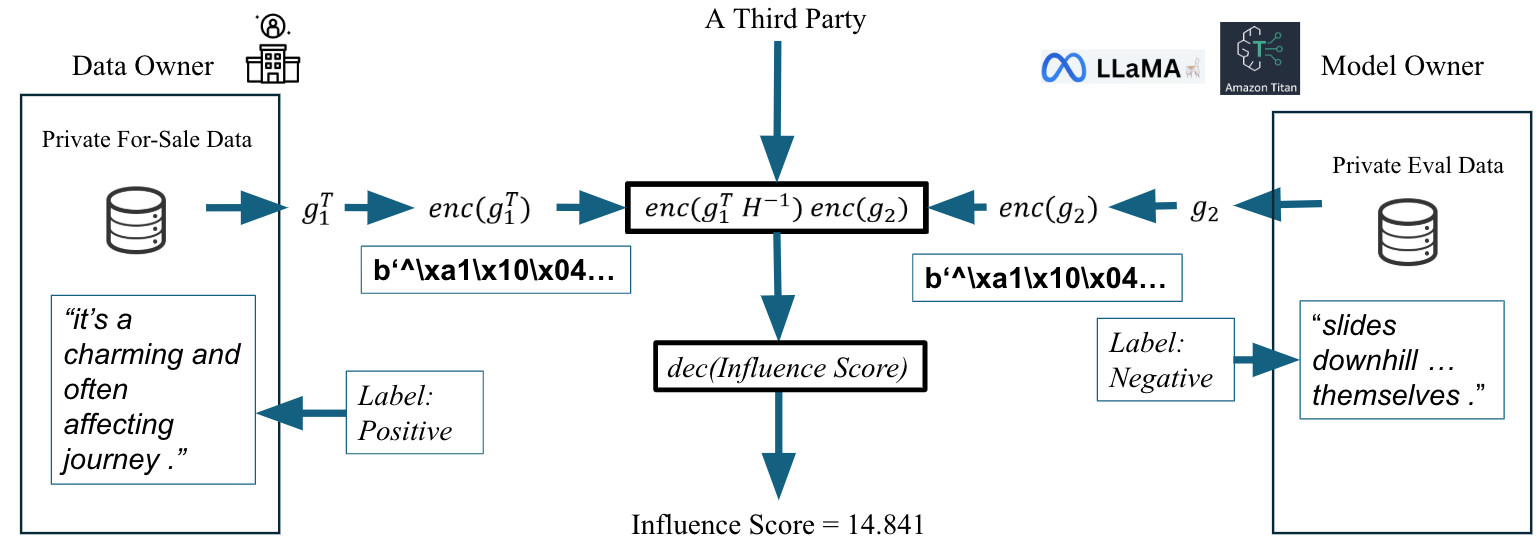
How TIP works in four steps
Imagine a calculator that can do math on numbers inside locked boxes, without ever opening them.
- Setup: The buyer makes a special lock-and-key. They turn their private test info into a “test vector,” lock it, and send the locked version to a broker (a computer that does the math). The buyer keeps the key.
- Seller’s part: The seller turns each data point into a “gradient vector” (the direction it would nudge the model), locks it with the buyer’s lock, and sends it to the broker. The seller doesn’t have the key either.
- Broker’s math on locked data: The broker multiplies the buyer’s locked test vector with the seller’s locked gradient to get a locked score. Thanks to Homomorphic Encryption (HE), the broker can do this without ever seeing the actual numbers.
- Buyer’s result: The buyer uses their key to unlock the score. A more negative score means the data would help reduce the model’s error more—so it’s more valuable.
Key tool: Homomorphic Encryption (specifically CKKS), which lets you do approximate arithmetic (add/multiply) on encrypted numbers—like using a calculator with gloves on that never touches the raw numbers.
Making it fast enough for big AI models
Big models have huge gradients (millions or billions of numbers). To make this practical:
- The authors compress gradients into a smaller “summary” using low‑rank projections (you can imagine summarizing a long book into key points). They use techniques like LoRA (Low‑Rank Adapters) to keep the important directions and drop the rest.
- They also account for model “curvature” (whether the model is on a flat or steep part of the learning landscape) using an approximation (K‑FAC). In simple terms: improvements that help in weak spots count more than repeating what the model already knows.
- With these tricks, the encrypted math works fast enough even for models like BERT and GPT‑2.
What did they find?
The authors tested their method on three setups (small images with an MLP, BERT for sentiment, and GPT‑2 for language). They also ran market-like simulations in healthcare and a generative AI “book market.”
Here are the main takeaways:
- Encrypted scores are almost identical to normal scores. The influence scores computed on encrypted data matched the plain, non‑encrypted results extremely closely (near‑perfect correlation). That means you can trust the encrypted version to make the same decisions.
- It’s fast enough per data point. After compressing gradients, the extra time per data point was around 0.15 seconds in their tests. The speed depends mainly on the size of the compressed vector, not on the full size of the model.
- Healthcare simulation: The encrypted influence score predicted real improvement well. When the buyer actually retrained with a seller’s data, the measured improvement matched what the encrypted score predicted—with a very high correlation (~0.96). This helps buyers avoid paying for unhelpful data.
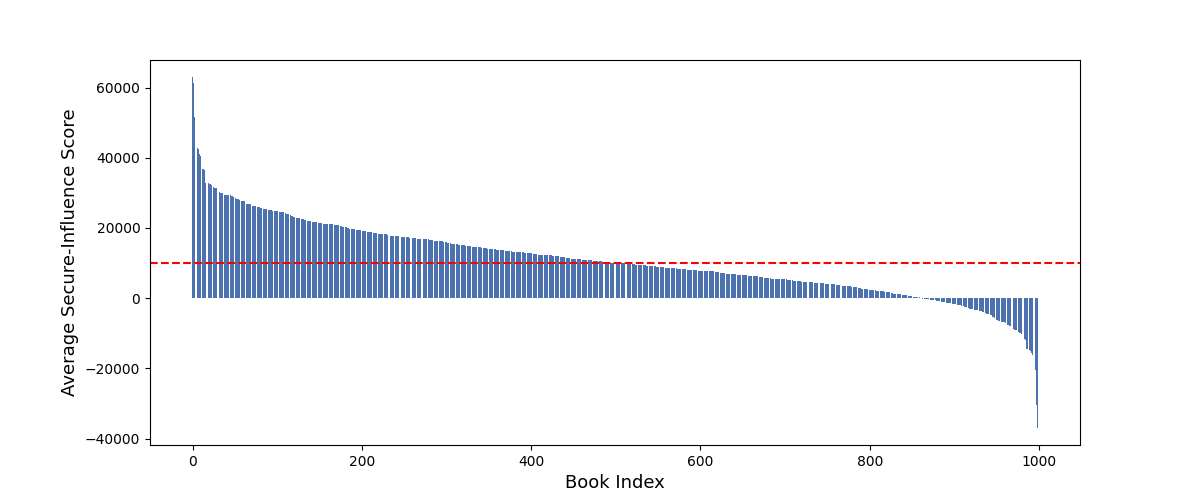
- Generative AI book market: Data value is extremely uneven. A small number of books made models better, while many others didn’t help or even hurt. This challenges the idea of paying everyone a flat rate just because their data was included.
Why does this matter?
This work points toward safer, fairer data markets where value is measured before purchase—without exposing secrets.
- Solves the “value vs. privacy” dilemma: Buyers can verify usefulness without seeing the data; sellers don’t risk leaks.
- Fairer payments: Since the method measures each item’s actual contribution, creators can be paid by impact rather than a flat fee.
- Safer sharing in regulated areas: Fields like healthcare can collaborate without exposing sensitive records.
- Better AI, less waste: Models can choose the most helpful data and avoid training on data that doesn’t help—or makes things worse.
In short, the Trustworthy Influence Protocol offers a practical way to build data marketplaces where privacy is protected, usefulness is measured accurately, and payments can reflect real value.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- Formal adversarial threat model: The protocol is analyzed under a semi-honest model; there is no treatment of malicious adversaries, broker–seller collusion, or active attacks (e.g., tampering with ciphertexts, replay/fault attacks).
- Verifiable computation: TIP relies on an untrusted broker but provides no mechanism for the buyer to verify correctness of homomorphic dot-product computations (e.g., homomorphic MACs, SNARKs, verifiable HE). How to add end-to-end integrity proofs without degrading performance?
- Information leakage via outputs: The buyer learns scalar scores; the paper lacks a formal leakage analysis (e.g., how many queries and what adaptivity allow reconstruction/inference about the seller’s data or labels). What are safe output policies (rate limits, aggregation, DP noise) that preserve bargaining utility?
- CKKS security and parameterization: No explicit security level (e.g., ≥128-bit), modulus chain, rescaling schedule, noise growth bounds, or worst-case decryption error analysis are provided. What parameter sets guarantee both accuracy targets (e.g., MAE ≤ 1e−5) and modern security under chosen-parameter attacks?
- Chosen-ciphertext and decryption oracle risks: CKKS is malleable and not CCA-secure. What protections (e.g., authenticated encryption wrappers, robust decryption policies) prevent broker-crafted ciphertexts from enabling key/secret leakage via buyer decryption?
- Ciphertext footprint and bandwidth: The paper does not quantify ciphertext sizes, packing strategies, rotations, or end-to-end network costs. What are the communication/storage requirements per candidate and at marketplace scale (106–109 points)?
- Scalability beyond toy LLMs: Results include GPT-2 and low-rank adapters; there is no evaluation on truly billion-parameter LLMs (e.g., Llama-class) with realistic k, nor end-to-end throughput under production constraints. What are performance envelopes and bottlenecks at industrial scale?
- Runtime inconsistencies: Per-sample times are near-constant across very different projected dimensions (8292 vs. 384), and total overheads differ sharply (e.g., BERT: 10016s vs. GPT-2: 3.1s). What hardware, batching, packing, and level-management explain these discrepancies, and how do they generalize?
- Projection operator design and trust: P (LoRA/K-FAC-based) is buyer-specific, but the protocol does not describe how P is shared/verified by sellers or how its choice affects bias/fidelity. What ranks/placements yield optimal accuracy/compute trade-offs, and how robust is P across tasks/models?
- Theoretical validity in non-convex regimes: Influence-function derivations assume local convexity near the optimum, which is unrealistic for deep nets. What error bounds connect projected influence to realized utility under non-convexity, stochastic optimizers, and adaptive fine-tuning?
- K-FAC preconditioner fidelity: There is no sensitivity analysis for damping, layer-wise approximations, or data dependence. How do preconditioning choices affect score stability, ranking robustness, and adversarial exploitability?
- Additivity assumption for subset valuation: The paper adopts approximate additivity without quantifying interaction effects (synergy/redundancy). How large are non-additive errors in practice, and can submodular or bundle-aware selection improve purchasing decisions?
- Robustness to adversarial/poisoned data: Sellers could craft points to maximize encrypted scores but harm downstream training. What defenses (e.g., robust influence, adversarial detection, certification) mitigate gaming and poisoning under TIP?
- Model confidentiality constraints: TIP assumes public model parameters; the protocol does not support buyers who must keep parameters private. Can TIP be extended to two-party/MPC variants that hide both model and data while preserving valuation accuracy?
- Privacy of buyer evaluation set: There is no formal analysis of what sellers/brokers can infer about D_eval from observed outcomes or meta-signals (e.g., scoring patterns across many candidates). What guarantees prevent membership/property inference?
- Broker necessity and alternatives: The protocol depends on a broker. Can two-party HE/MPC or TEEs (SGX/SEV) remove this trust anchor, and what are the performance/security trade-offs?
- Output monetization and mechanism design: TIP produces utility scores but does not specify pricing rules, contracts, or auction formats that prevent cherry-picking, collusion, or adverse selection. How should scores translate to payments under negative/uncertain utility?
- Handling negative utility: The paper observes heavy-tailed value and harmful data but provides no compensation or market rule for negative contributions (penalties, refunds, clawbacks). What mechanisms align incentives while deterring low-quality data?
- Legal/regulatory integration: There is no pathway for rights management, provenance verification, auditability, or dispute resolution (e.g., copyright/medical compliance). How can encrypted valuation be embedded in enforceable contracts and audits?
- Post-purchase misuse: TIP solves pre-purchase valuation but does not address enforcement after acquisition (e.g., usage scope, downstream training). What cryptographic/contractual controls ensure compliance once plaintext data is delivered?
- Multi-buyer key management: Sellers must encrypt per-buyer; the paper does not detail key rotation, revocation, and cross-buyer scalability or reusability of seller-side computations. What key management workflows enable large, dynamic markets?
- Output aggregation policies: The paper lacks guidelines on batching, SIMD packing, rotation minimization, and amortized costs for large N. What operator schedules and packing strategies minimize latency/cost while preserving precision?
- Modalities beyond text/image: Claims of support for complex modalities are not demonstrated (audio, video, multimodal alignment, non-differentiable objectives). How does TIP generalize across modalities and label regimes?
- Empirical coverage gaps: The healthcare section is truncated and lacks full statistical reporting (confidence intervals, robustness checks), and the generative book market’s methodology/results are not detailed. What broader benchmarks and ablations (rank k, P variants, preconditioners, datasets) validate generality?
- Ethical implications: Meritocratic markets may disadvantage contributors whose data is low-value or harmful under a specific model/task. How should fairness and social welfare be incorporated into encrypted valuation and compensation schemes?
Practical Applications
Practical Applications of the Trustworthy Influence Protocol (TIP)
Below are actionable applications derived from the paper’s methods and findings, grouped by time horizon. Each item notes relevant sectors, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed with current HE libraries (e.g., CKKS via SEAL/OpenFHE), LoRA-based gradient projection, and standard MLOps.
- Privacy-preserving pre-purchase data valuation for AI model fine-tuning
- Sectors: software/AI, generative AI, enterprise ML
- What: Buyers rank prospective datasets by their marginal utility to a specific model/task without seeing raw data; sellers avoid revealing content pre-transaction.
- Tools/workflows: TIP SDK + HE libs; Hugging Face/Transformers integration; LoRA adapters for gradient projection; brokered HE compute service; buyer encrypts eval vector, sellers encrypt projected gradients, broker returns encrypted dot products, buyer decrypts for pricing.
- Assumptions/dependencies: Semi-honest threat model; buyer’s model weights/architecture are available for seller-side gradient computation; reliable CKKS parameterization and slot rotations; evaluation set is representative; compute/bandwidth for HE.
- Secure healthcare data procurement and collaboration (HIPAA-aligned)
- Sectors: healthcare, life sciences
- What: Hospitals evaluate peer institutions’ cohorts for improving readmission/mortality models without sharing PHI; supports selective, high-utility data acquisition.
- Tools/workflows: Hospital-side gradient computation (on-prem/VDI), K-FAC-based preconditioners, encrypted valuation via broker, post-purchase secure transfer under BAAs.
- Assumptions/dependencies: Institutional approvals; de-identification for post-purchase use; evaluation set reflects target population; legal/compliance processes.
- Dataset curation for LLM pretraining and fine-tuning
- Sectors: generative AI, media platforms
- What: Use influence scores to prune or reweight harmful/low-value text; paper’s evidence shows heavy-tailed value distribution where many samples degrade performance.
- Tools/workflows: MLOps plug-in to score incoming data; negative-score filtering; per-sample or per-shard weighting during training.
- Assumptions/dependencies: Low-rank projections preserve utility signal; stable K-FAC approximations; adequate compute for per-sample valuation.
- Price discovery and negotiation for data licensing
- Sectors: publishing, media, social platforms, stock photo/video libraries
- What: Encrypted valuation informs merit-based prices for books, images, posts, etc., before any content is revealed.
- Tools/workflows: Valuation dashboards for sellers/buyers; batch scoring of catalogs; contracts referencing TIP-derived scores.
- Assumptions/dependencies: Contractual acceptance of influence-based pricing; provenance and itemization to link scores to assets.
- Compliance and due diligence audits for data purchases
- Sectors: finance, healthcare, government, regulated industries
- What: Maintain audit trails showing expected utility at acquisition time; reduces adverse selection and supports procurement governance.
- Tools/workflows: Signed logs of encrypted computations; reproducible HE configurations; third-party “valuation oracle” attestations.
- Assumptions/dependencies: Chain-of-custody for encrypted artifacts; reproducible seeds/model checkpoints; regulator acceptance.
- Privacy-preserving B2B data collaboration across verticals
- Sectors: retail (POS), energy (grid sensors), mobility (fleet telemetry), manufacturing/IoT (predictive maintenance)
- What: Firms assess partner datasets for their models without exposing proprietary logs or evaluation criteria.
- Tools/workflows: TIP-as-a-service; edge-side gradient projection; batch or streaming encrypted scoring.
- Assumptions/dependencies: Public model weights or agreed surrogate models for projections; network bandwidth and HE-friendly data sizing.
- Content creator compensation triage for AI training
- Sectors: creator economy, platforms, media
- What: Rank creators’ assets by contribution to model performance to guide royalty pools and negotiations.
- Tools/workflows: Creator portals showing aggregated valuation; payout calculators using additive influence assumptions for bundles.
- Assumptions/dependencies: Provenance tracking; additivity of influences for subsets; governance to prevent perverse incentives.
- Low-risk data procurement for startups and SMEs
- Sectors: cross-industry AI adopters
- What: Evaluate datasets “blindly” before purchase to control costs and avoid poor acquisitions.
- Tools/workflows: Pay-per-evaluation broker APIs; standard templates for encrypted RFPs; small eval sets to start.
- Assumptions/dependencies: Reliable small-sample evaluation proxies; cost-effective broker compute.
- Internal data quality monitoring and drift control
- Sectors: software/SaaS, IoT
- What: Continuously score new logs/events for marginal utility; gate or downweight negative-utility data to stabilize models.
- Tools/workflows: Automated scoring in data pipelines; alerts for sustained negative influence; feedback loops to data engineering.
- Assumptions/dependencies: Compute budget for recurring HE scoring; stable evaluation sets; ops maturity in MLOps.
Long-Term Applications
These require further research, scaling, standardization, or legal/regulatory evolution.
- Encrypted data marketplaces with per-example royalties and real-time pricing
- Sectors: media, social platforms, AI marketplaces
- What: Marketplaces use TIP for on-demand, model-specific pricing and royalty accounting (e.g., per-book/per-clip valuation for LLM training).
- Tools/products: Marketplace plugins; valuation oracles; on-chain attestations; settlement systems tied to TIP scores.
- Assumptions/dependencies: Legal standards for utility-based compensation; scalability to tens/hundreds of millions of items; robust provenance.
- Consumer-controlled personal data exchanges
- Sectors: ad tech, health wearables, fintech
- What: Devices compute encrypted gradient “fingerprints” locally so individuals can sell the utility of their data without exposing contents.
- Tools/products: Mobile HE runtimes; device SDKs; consent and payout apps.
- Assumptions/dependencies: Efficient on-device HE; UX and consent frameworks; privacy regulations (GDPR/CCPA/HIPAA).
- Policy frameworks for fair compensation of copyrighted materials in AI
- Sectors: government, IP law, creative industries
- What: Regulators and courts reference encrypted valuation evidence in licensing disputes and rate-setting.
- Tools/products: Certified TIP evaluators; standardized evaluation sets for public-interest tasks.
- Assumptions/dependencies: Judicial acceptance; standardized protocols and metrics; reproducibility requirements.
- Utility-aware federated and collaborative fine-tuning
- Sectors: healthcare networks, financial consortia, IoT alliances
- What: Integrate TIP into federated learning to select clients/samples with highest marginal utility under privacy guarantees.
- Tools/products: TIP+FL hybrid frameworks (HE+MPC); client selection policies; encrypted sampling strategies.
- Assumptions/dependencies: Communication-efficient HE/MPC; secure aggregation compatibility; fairness constraints.
- Streaming/online encrypted data valuation for continual learning
- Sectors: real-time analytics, cybersecurity, AIOps
- What: Real-time valuation of incoming streams to gate training data and adapt sampling rates.
- Tools/products: Incremental K-FAC/influence estimators; HE kernels optimized for streaming; autoscaling broker services.
- Assumptions/dependencies: Throughput improvements (HE rotations, bootstrapping); robust online approximations.
- Cross-modal and multimodal valuation (vision, audio, video)
- Sectors: autonomous systems, media archives, robotics
- What: Extend projected gradient approach to multimodal encoders to price frames/clips/tracks securely.
- Tools/products: Adapter strategies for vision/audio models; modality-specific projections; broker pipelines for large assets.
- Assumptions/dependencies: Efficient per-sample gradient extraction; stable projections that preserve utility signal.
- Hardware acceleration for homomorphic influence computations
- Sectors: cloud providers, HE vendors, semiconductor
- What: GPU/ASIC support for CKKS vector ops (rotations, NTT) to cut latency and cost.
- Tools/products: HE-optimized libraries and hardware; managed HE services.
- Assumptions/dependencies: Vendor investment; standardization across HE stacks.
- Robustness, safety, and fairness-aware valuation
- Sectors: public sector, regulated industries, responsible AI
- What: Incorporate bias/toxicity metrics into evaluation vectors so TIP penalizes harmful content; align with machine unlearning.
- Tools/products: Fairness-augmented eval sets; safety-weighted influence objectives.
- Assumptions/dependencies: Agreement on fairness metrics; risk of proxy bias if eval sets are unrepresentative.
- Anti-scraping and licensing negotiation tooling for platforms
- Sectors: social media, news, image/video libraries
- What: Platforms present TIP-based utility curves to justify license terms with AI firms; negotiate model/task-specific fees.
- Tools/products: Negotiation dashboards; standardized encrypted “test suites” for prospective buyers.
- Assumptions/dependencies: Mutual trust in protocol integrity; confidentiality of evaluation criteria.
- Insurance and financing products for data assets
- Sectors: fintech, insurers, data-as-an-asset accounting
- What: Underwrite data acquisitions with policies priced to verified utility; introduce SLAs tied to model improvement.
- Tools/products: Actuarial models using TIP audit trails; escrow services contingent on realized utility.
- Assumptions/dependencies: Sufficient historical evidence; standard contracts and enforcement.
General Assumptions and Dependencies
- Security model: Semi-honest parties and untrusted broker; CKKS provides approximate arithmetic with bounded error; correctness validated by high fidelity (near-perfect Pearson correlations with plaintext baselines in experiments).
- Model access: Sellers need access to the buyer’s public model architecture/weights (or agreed surrogates) to compute projected gradients; if weights are proprietary, additional secure computation or sandboxing is needed.
- Projection fidelity: Low-rank gradient projections (e.g., LoRA) must preserve utility-relevant directions; inverse Hessian approximations (e.g., K-FAC) should be stable for the target task.
- Additivity: Pricing of bundles often assumes near-additive influences across samples; may require checks for interaction effects.
- Compute and ops: HE overhead scales with projected dimension and number of samples (~0.15s/sample in reported tests); bandwidth and HE parameter tuning are operational considerations.
- Governance: Legal acceptance of influence-based valuation, provenance verification, and clear post-purchase data handling are necessary for market adoption.
Glossary
- Adverse selection: A market failure where buyers risk overpaying for low-quality data due to asymmetric information. "Conversely, the buyer faces the risk of adverse selection, potentially overpaying for a dataset whose quality is exaggerated by the seller \citep{zhang2024survey}."
- Arrow's Information Paradox: An economic principle stating information’s value cannot be assessed without disclosure, but disclosure gives it away. "This chaotic environment persists because the industry faces a fundamental economic friction known as Arrow's Information Paradox."
- Autoregressive architectures: Models that predict the next element based on previous elements, common in generative LLMs. "GPT-2 presents unique challenges: gradients span tens of millions of parameters, and autoregressive architectures require deeper stacks of attentionâMLP layers."
- BFV/BGV: Integer-based homomorphic encryption schemes not ideal for approximate real-valued computations. "To support this at scale, we choose Fully Homomorphic Encryption (FHE) as the cryptographic substrate and, within FHE, the CKKS scheme because it natively supports approximate arithmetic on real-valued gradient vectors, avoiding the quantization overhead of integer schemes such as BFV/BGV \citep{fan2012somewhat, brakerski2012fully, cheon2017homomorphic}."
- CKKS scheme: A homomorphic encryption scheme supporting approximate arithmetic on real numbers. "We therefore utilize the CKKS scheme \citep{cheon2017homomorphic}."
- Cipherspace: The encrypted domain in which computations are performed under homomorphic encryption. "This lemma provides the necessary primitive: it allows us to compute the dot product $s(z_s) = -\langle \tilde{v}_{\mathrm{eval}, \tilde{g}(z_s) \rangle$ in the cipherspace."
- Cosine similarity: A measure of directional alignment between two vectors, used as a model-agnostic baseline. "This is a model-agnostic heuristic that measures the directional alignment between the Seller's data and the Buyer's evaluation gradient $z_{\text{eval}$ in Euclidean space."
- Data attribution: Methods to quantify the contribution of individual training points to model behavior. "Data attribution concerns how to evaluate the value of individual data points; therefore, it is different from other explanation methods, such as feature attribution methods like LIME or SHAP \citep{NIPS2017_7062,ribeiro2016should}."
- Data Shapley Value: A Shapley-based method for fair data valuation via retraining on subsets, typically computationally expensive. "Foundational approaches like the Data Shapley Value \citep{ghorbani2019data} provide a theoretically rigorous framework for fair valuation but are computationally prohibitive for large models, as they require retraining the model on exponentially many subsets."
- Differential Privacy: A technique that injects noise to protect individual data contributions during computation. "The dominant paradigm in privacy-preserving machine learning is Differential Privacy \citep{dwork2014algorithmic}, which protects individual records by injecting calibrated noise into the computation outputs or gradients."
- Empirical risk minimizer: The parameter vector that minimizes average training loss on the dataset. "Let be the empirical risk minimizer."
- Fully Homomorphic Encryption (FHE): Cryptography enabling arbitrary computations on encrypted data with results decrypting to correct outputs. "To support this at scale, we choose Fully Homomorphic Encryption (FHE) as the cryptographic substrate..."
- Generative AI: AI systems that generate content such as text or images and raise new attribution and valuation challenges. "The stakes of this inquiry have risen sharply with the deployment of Generative AI."
- Gradient-based influence functions: Techniques that estimate a data point’s marginal effect on loss using gradients and curvature. "By integrating Homomorphic Encryption with gradient-based influence functions, our approach allows for the precise, blinded scoring of data points against a buyer's specific AI model."
- Hessian: The matrix of second derivatives of the loss with respect to parameters, encoding curvature. "Let $H_{\hat{\theta} = \nabla^2 R_n(\hat{\theta})$ be the Hessian of the training loss at the optimum."
- HIPAA: U.S. health privacy law governing protected health information. "The healthcare sector presents a paradigmatic example of the ``value-privacy dilemma.'' While hospitals possess vast repositories of patient data that could theoretically enhance peer institutions' predictive models, these datasets are siloed due to privacy risks (the Health Insurance Portability and Accountability Act of 1996 (HIPAA)\footnote{https://www.hhs.gov/hipaa}) and competitive concerns."
- HSCRC: Maryland Health Services Cost Review Commission, a source of inpatient data used for simulation. "To validate the proposed framework in a domain characterized by high data heterogeneity and stringent privacy regulations, we simulate a data market using inpatient case-mix records from the Maryland Health Services Cost Review Commission (HSCRC\footnote{https://hscrc.maryland.gov})."
- ICD-10: International medical coding standard for diagnoses used in healthcare datasets. "We followed the International Classification of Diseases, 10th version (ICD-10: \url{https://www.icd10data.com/ICD10CM/Codes})"
- Influence Functions (IF): Approximations of how upweighting a training point affects model parameters and test loss. "Influence Functions (IF) utilize a first-order Taylor expansion to approximate the effect of a data point on the model parameters \citep{koh2017understanding}."
- Inverse Hessian-Vector Product (IHVP): A computation central to influence functions that applies the inverse Hessian to a gradient vector. "Formally, the influence of a training point on a test point is computed via the Inverse Hessian-Vector Product (IHVP)."
- Johnson-Lindenstrauss transforms (SJLT): Sparse random projections used to reduce dimensionality while preserving structure. "Most recently, \citet{hu2025grass} achieved sub-linear time complexity by leveraging the inherent sparsity of gradients combined with sparse Johnson-Lindenstrauss transforms (SJLT), outperforming previous baselines in throughput."
- Kronecker-Factored Approximate Curvature (K-FAC): An approximation method for the Fisher/Hessian using Kronecker factorizations. "The details of the projection construction which utilizes Low-Rank Adaptation (LoRA) structures and Kronecker-Factored Approximate Curvature (K-FAC) initialization are detailed in Appendix~\ref{app:scalable}."
- LLMs: Very large neural models for language tasks whose scale challenges valuation and encryption. "To ensure scalability for LLMs, we employ low-rank gradient projections..."
- LoGRA: A scalable influence estimation method exploiting low-rank gradient structure. "LoGRA \citep{choe2024your} further exploits the low-rank structure of gradients in linear layers to reduce dimensionality."
- LoRA (Low-Rank Adaptation): A technique that adds low-rank adapters to reduce gradient dimensionality and enable efficient fine-tuning. "In all models, we insert lightweight LoRA adapters so that gradients flowing through these adapters serve as low-dimensional âfingerprintsâ of each data example."
- Machine unlearning: The process of removing the effects of specific data from a trained model. "Beyond model debugging, attribution now serves as the technical substrate for resolving copyright disputes, enabling machine unlearning of toxic content \citep{yao2024machine}, and calculating fair compensation for content creators \citep{grynbaum2023times}."
- Metric tensor: A geometric operator that reweights directions according to curvature in influence computations. "It acts as a metric tensor that down-weights gradient components in directions of high curvature (where the model is already confident/stiff) and amplifies components in directions of low curvature (where the model is uncertain/flat)."
- Model-specific data valuation: Valuing data relative to the specific model and task geometry rather than using model-agnostic heuristics. "We then survey feature attribution methods and data attribution methods, including Shapley-based approaches and influence-function-based techniques, and explain why the latter are particularly suitable for model-specific data valuation at scale."
- Preconditioner: A transformation (often inverse Hessian-based) applied to gradients to account for curvature during influence computation. "Unlike the MNIST case, here the influence computation involves a KFAC-based inverse-Hessian preconditioner."
- Projection operator: A mapping from high-dimensional gradients to a lower-dimensional subspace preserving essential structure. "We introduce a projection operator (where ) that maps high-dimensional gradients into a low-dimensional subspace that preserves the principal directions of the model's curvature."
- Secure Multi-Party Computation (MPC): Protocols enabling joint computation over private inputs without revealing them. "Beyond differential privacy, secure multi-party computation (MPC) has also been used for privacy-preserving data valuation."
- Semi-honest security model: An assumption where parties follow protocols but may try to learn additional information. "Formally, the market consists of two primary agents operating under a semi-honest security model:"
- Shapley values: Cooperative game-theory values used to fairly attribute contributions, applied to data valuation. "We then survey feature attribution methods and data attribution methods, including Shapley-based approaches and influence-function-based techniques..."
- Slot rotation operations: CKKS operations that rotate encrypted vector slots to enable summations for inner products. "Furthermore, slot rotation operations allow the summation of vector elements within a ciphertext to compute inner products."
- TRAK: A method that approximates influence via gradient similarity and random projections without Hessian inversion. "TRAK \citep{park2023trak} replaces the Hessian with a linearized gradient similarity metric using random projections."
- Trustworthy Influence Protocol (TIP): The paper’s proposed encrypted protocol for computing data utility without revealing data. "We introduce the Trustworthy Influence Protocol (TIP), which enables buyers to compute precise utility scores on encrypted gradients without ever exposing their model parameters or viewing the raw data."
- Value-privacy dilemma: The tension that data’s utility cannot be verified without revealing it, risking misuse. "The rapid expansion of Artificial Intelligence is hindered by a fundamental friction in data markets: the ``value-privacy dilemma'', where buyers cannot verify a dataset's utility without inspection, yet inspection may expose the data (Arrow's Information Paradox)."
- Vertical federated learning: A federated setup where parties hold different feature sets for the same samples. "For example, FedValue \citep{han2021data} applies MPC to compute Shapley values in vertical federated learning, where multiple parties collaboratively train a predictive model on tabular data and seek to attribute value to feature groups via a largely model-agnostic, information-theoretic metric."
Collections
Sign up for free to add this paper to one or more collections.