- The paper presents a novel dataset capturing comprehensive multimodal data including visual, force, and tactile signals for articulated object manipulation.
- It details rigorous sensor calibration, cross-view synchronization, and benchmarking that reveal current limitations in force and tactile prediction models.
- The dataset supports human–robot transfer research by unifying diverse sensor modalities with detailed ground-truth 3D and kinematic annotations.
Hoi!: A Multimodal Dataset for Force-Grounded, Cross-View Articulated Manipulation
Motivation and Dataset Design
Articulated object manipulation in real-world environments poses unique challenges for both perception and control, requiring tight coupling between visual cues, haptic signals, and active skill transfer between human and robotic embodiments. Existing datasets for manipulation heavily segment into either human-centric long-horizon activities or robotics-centric short-horizon primitives, rarely providing coherent, multimodal annotations that link appearance, force, and action. The Hoi! dataset is designed to bridge this gap by enabling research into force-grounded manipulation, providing cross-view, cross-embodiment, and multimodal data for human and robot interactions with everyday articulated objects such as drawers, doors, refrigerators, and dishwashers.
The dataset comprises 3048 sequences across 381 objects in 38 indoor environments, with each object operated under four main embodiments: human hand, human hand with wrist-mounted camera, a handheld UMI gripper, and a custom Hoi! force-torque and tactile-sensing gripper. All interactions are recorded in multiple synchronized viewpoints: egocentric (via Project Aria glasses), wrist-mounted, and static exocentric RGB-D. Ground-truth 3D environment scans (pre/post manipulation) anchor these sequences, providing the geometric substrate for precise kinematic and force annotations.




































Figure 1: A diverse collection of real-world indoor environments featuring kitchens, bathrooms, offices, and living spaces are annotated with multimodal sequences showing articulated object interaction.
Hardware: The Hoi! Gripper
Central to this effort is the open-sourced Hoi! gripper, engineered for high-precision tactile and force sensing in realistic, hand-operated contexts. The hardware employs a 2-finger parallel mechanism controlled via a Dynamixel XM430 motor, with interaction force measured by a Bota SensONE 6-DoF sensor, and Digit GelSight sensors providing rich contact pressure maps. Pose tracking and visual feedback are captured with a stereo camera and Project Aria device, delivering aligned wrist-view images and real-time spatial calibration. Gravity compensation of force-torque readings ensures measurement of net interactions rather than sensor biases or gravitational artefacts.
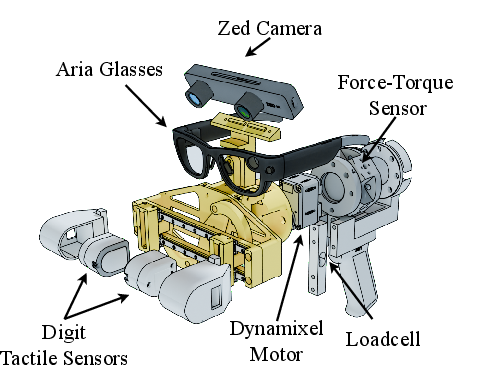
Figure 2: The Hoi! gripper combines visual, pose, force, and tactile sensing for robot-aligned, human-executed manipulation data gathering.
Dataset Composition and Multimodal Alignment
Spatial and temporal alignment is achieved through high-resolution laser-scanned 3D reconstructions, QR-based clock synchronization, and comprehensive sensor calibrations. The collection protocol enforces consistent data capture, controlling for initial states, manipulation order, and viewpoint coverage. Environmental diversity spans kitchen, office, living room, and lab scenes, each with unique articulation mechanisms and material properties.
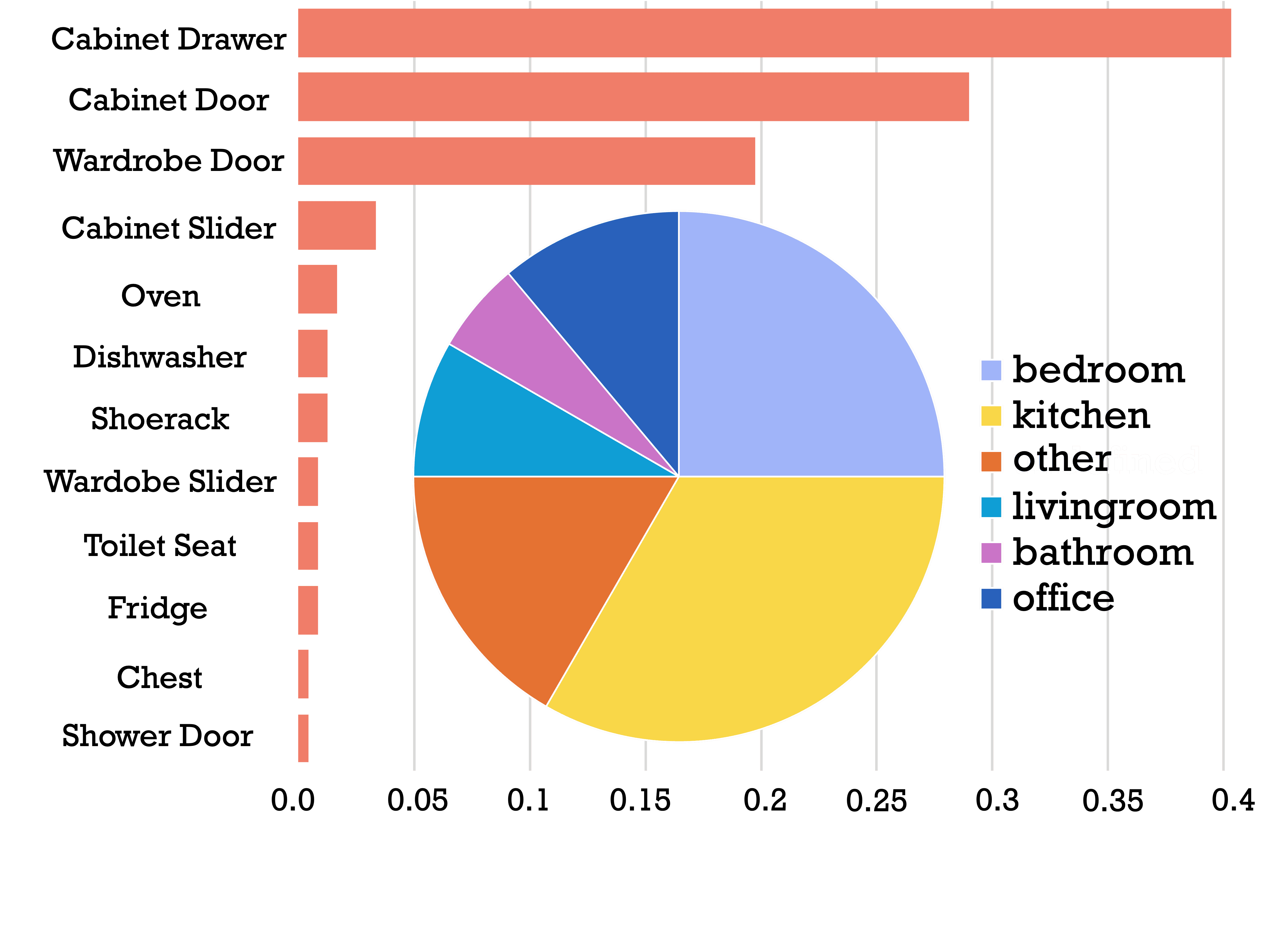
Figure 3: Distribution of environments and articulated interaction categories, demonstrating coverage across manipulation modalities and object types.
Recordings are annotated for articulation type (prismatic, revolute), axes, kinematic masks, language description, and articulated motion parameters with precise 3D correspondence. Human demonstrations with the gripper mimic manipulator kinematics closely, allowing for direct cross-domain transfer evaluation. Robust multi-view annotation enables rigorous benchmarking of cross-embodiment policy learning and multimodality fusion.
Figure 4: Dataset collection setup – 3048 multimodal sequences, 381 articulated objects, and 38 locations with synchronized visual, pose, force, and haptic data.












Figure 5: Synchronized recordings from exocentric, egocentric, and wrist-mounted viewpoints for both human and robot executions.
Benchmarking: Articulation, Force, and Tactile Learning
Three primary benchmarks address core manipulation understanding:
- Articulated Object Estimation: Methods must infer articulation type and 3D joint parameters from single or continuous visual observations. Results show GPT-5 VLMs predicting articulation type with robust accuracy (egocentric: 88.5%, exocentric: 87.5%), while geometric methods such as ArtiPoint and ArtGS experience pronounced performance degradation compared to controlled datasets, attributable to depth estimation noise and clutter-induced segmentation errors.
- Tactile Force Estimation: Employing the Sparsh model with DINO/DINOv2 decoders, normal/tangential/combined force estimation from tactile images yields RMSEs of 3-4 N, an order of magnitude higher than laboratory benchmarks. This degradation is traced to out-of-distribution complex contact geometries in real handles, multifinger, and multi-contact regimes, highlighting the essential challenge of tactile generalization.
- Visual Force Prediction: ForceSight predicts per-task force vectors from RGB-D and textual goal, with RMSEs in Hoi! at 2.23 N (projected) and 2.57 N (raw), compared to 0.40 N on its original dataset. Error outliers correlate with stiff or force-intensive mechanisms, indicating prior models’ lack of exposure to high-load articulated interactions.
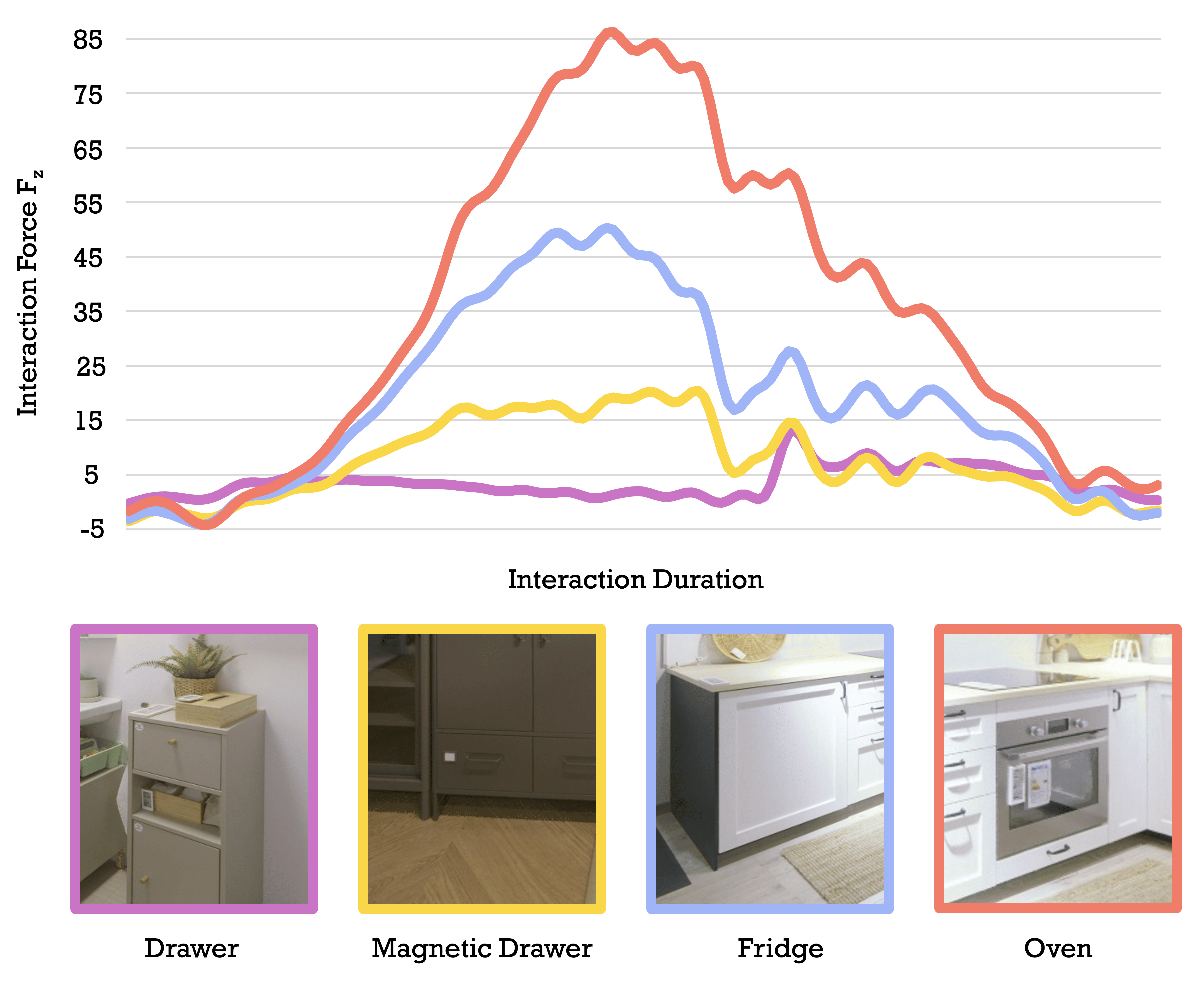
Figure 6: Measured interaction forces for various articulated elements, illustrating variance and complexity in real-world tasks.
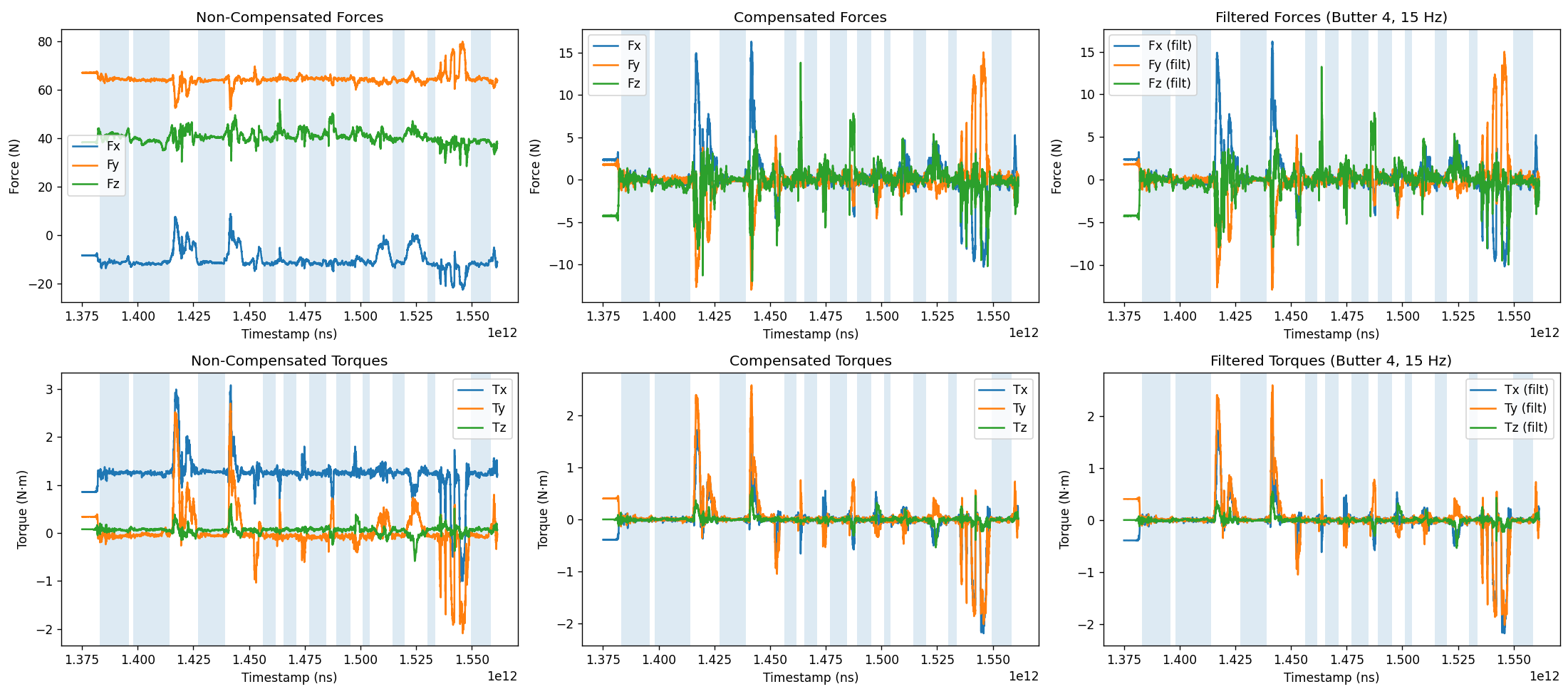
Figure 7: Gravity compensation pipeline for force-torque sensor measurements, visualizing removal of bias and gravitational effects to reveal net interaction forces.
Implications and Limitations
Hoi! exposes significant modality and domain gaps in existing approaches to multimodal manipulation. Articulation estimation methods reliant on depth (e.g., monocular or SLAM-based) exhibit limited resilience to real-world occlusions and hand-object clutter. Tactile force prediction models trained on simplistic lab indenters do not translate to the diverse, high-variance contact geometries present in genuine in-the-wild manipulation tasks. Visual force models have difficulty generalizing to novel, force-demanding mechanisms, reflecting the scarcity of such examples in legacy datasets.
Practically, Hoi!'s cross-view, multimodality enables research into vision-language-actuation interfaces, robust tactile perception, and policy learning that leverages both human and robot experiential priors. The open-source gripper design has further potential to unify benchmarks across labs and facilitate reproducibility in haptic and manipulation research.
Limitations include incomplete coverage of rare or extreme articulation mechanisms, hybrid embodiment constraints in human-operated robot gripper demonstrations, and current benchmarks’ focus on object-centric perception rather than end-to-end joint policy learning.
Future Prospects
Expansion directions include integration of full-body manipulator demonstrations, coverage of high-complexity mechanisms and rare edge-cases, enriched annotation for composite/hierarchical articulations, and continuous capture protocols for long-horizon skill transfer. Ambitious research trajectories are enabled by Hoi!, including the development of transferable force policies, policy distillation from multi-embodiment demonstrations, and multimodal reasoning for interaction affordance prediction—essential for robust, generalizable agents.
Conclusion
Hoi! delivers a comprehensive, multimodal, cross-view dataset addressing the lack of force-grounded, cross-embodiment annotated data for articulated object manipulation. Quantitative benchmarks reveal substantial deficiencies in the generalization capability of current articulation, tactile, and force estimation models, underscoring the necessity of multimodal, in-the-wild datasets. By equipping the community with richly annotated visual, haptic, and kinesthetic data, Hoi! enables rigorous investigation into transferable manipulation skills, multimodal perception, and generalizable policy learning for embodied agents.

