- The paper introduces BEP, a novel binary error propagation algorithm that enables end-to-end binary training without relying on floating-point operations.
- The paper demonstrates significant accuracy improvements, achieving up to 10.57% gains on feedforward and recurrent networks compared to traditional QAT methods.
- The paper leverages efficient bitwise operations and integer-valued weights, paving the way for deploying binary neural networks in resource-constrained and secure environments.
Binary Error Propagation (BEP) for Training Binary Neural Networks
Introduction
The introduction of the Binary Error Propagation (BEP) algorithm represents a significant advancement in the domain of Binary Neural Networks (BNNs). BNNs, which constrain both weights and activations to binary values, are especially beneficial for deployment in resource-constrained environments due to their drastic reductions in computational complexity and memory footprint. Despite these advantages, training BNNs has been complex due to the non-differentiable nature of binary variables, traditionally handled by quantization-aware training (QAT) techniques. However, QAT's reliance on full-precision parameters during training undermines the efficiency of binary computations. BEP addresses these challenges by establishing a discrete analog of the backpropagation chain rule, allowing error signals to be propagated backward through multiple layers using only binary operations. This makes BEP uniquely capable of enabling end-to-end binary training for both feedforward and recurrent neural networks, achieving test accuracy improvements of up to 10.57% in certain configurations.
Binary Error Propagation Algorithm
BEP revolutionizes the training of BNNs by formalizing a binary variant of the backpropagation algorithm, entirely dispensing with traditional floating-point arithmetic. In BEP, all forward and backward computations are performed via efficient bitwise operations, such as XNOR and Popcount. This effectively brings full end-to-end binary computation into both training and inference phases, capitalizing on the inherent efficiency of binary processing. BEP operates by initiating a backward update when the predicted logit for the ground-truth class is not sufficiently distinct from others. It formulates binary vectors representing desired activations for each layer, propagated backward from the output layer to the input through a recursive rule that mirrors traditional error backpropagation but in binary form. Additionally, BEP employs integer-valued hidden weights to provide synaptic inertia, preventing catastrophic forgetting and ensuring learning stability.
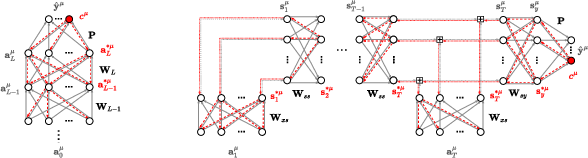
Figure 1: BEP applied to a binary MLP.
Experimental Evaluation
The empirical evaluation of BEP against state-of-the-art methods showcases its superior performance. Particularly in training binary multi-layer perceptrons (MLPs), BEP consistently outperforms leading local learning rules and QAT-based systems. Experiments conducted on datasets such as Random Prototypes and FashionMNIST reveal improvements in test accuracy by up to 6.89% over previous state-of-the-art algorithms. Furthermore, BEP extends naturally to recurrent neural networks (RNNs), an area where local learning rules typically fail due to the necessity of temporal credit assignment. BEP's ability to propagate global error signals enables it to effectively train binary RNNs, achieving an average accuracy improvement of 10.57% on time-series classification tasks in the UCR Archive.
Theoretical Underpinnings and Implications
Theoretically, BEP provides a structured way to achieve the global credit assignment needed for multi-layer BNNs, addressing a long-standing challenge in binary deep learning. The introduction of BEP allows for a cohesive, discrete backpropagation mechanism that extends the core concepts of traditional backpropagation into the binary domain without resorting to surrogate gradients. Practically, this has significant implications for deploying machine learning models on edge devices and specialized hardware, where computational resources are limited. The potential of BEP to enhance privacy-preserving computations through fully homomorphic encryption is another promising avenue, enabling secure and efficient training over encrypted data.
Conclusion
BEP stands as a technically sound and practically efficient algorithm for training binary neural networks. By eliminating the dependence on full-precision computations, BEP not only enhances computational efficiency but also paves the way for broader applications of binary deep learning models in resource-constrained and secure environments. Future research directions include extending BEP to more complex architectures like convolutional neural networks and exploring adaptive strategies for parameter tuning to further optimize its performance across different tasks and datasets.
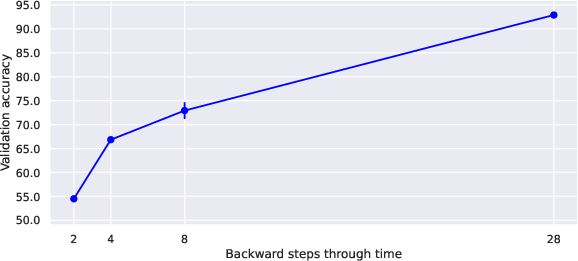
Figure 2: Validation accuracy of a binary RNN trained with BEP on the S-MNIST dataset for different values of the backward horizon length (depth of backpropagation).

