PosterCopilot: Toward Layout Reasoning and Controllable Editing for Professional Graphic Design
Abstract: Graphic design forms the cornerstone of modern visual communication, serving as a vital medium for promoting cultural and commercial events. Recent advances have explored automating this process using Large Multimodal Models (LMMs), yet existing methods often produce geometrically inaccurate layouts and lack the iterative, layer-specific editing required in professional workflows. To address these limitations, we present PosterCopilot, a framework that advances layout reasoning and controllable editing for professional graphic design. Specifically, we introduce a progressive three-stage training strategy that equips LMMs with geometric understanding and aesthetic reasoning for layout design, consisting of Perturbed Supervised Fine-Tuning, Reinforcement Learning for Visual-Reality Alignment, and Reinforcement Learning from Aesthetic Feedback. Furthermore, we develop a complete workflow that couples the trained LMM-based design model with generative models, enabling layer-controllable, iterative editing for precise element refinement while maintaining global visual consistency. Extensive experiments demonstrate that PosterCopilot achieves geometrically accurate and aesthetically superior layouts, offering unprecedented controllability for professional iterative design.
















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “PosterCopilot: Toward Layout Reasoning and Controllable Editing for Professional Graphic Design”
1. What is this paper about?
This paper introduces PosterCopilot, an AI system that helps make professional-looking posters. It doesn’t just create a first draft—it can also carefully edit and improve designs, piece by piece, like a skilled graphic designer. The big idea is to teach AI how to arrange images, text, and shapes on a canvas in smart, good-looking ways, and then let it make precise changes without messing up the whole picture.
2. What questions does the paper try to answer?
In simple terms, the researchers ask:
- How can we get AI to place design elements (like photos and words) neatly and correctly on a poster?
- How can the AI understand both geometry (where things go and how big they are) and aesthetics (what looks good)?
- How can the AI make careful edits—like changing just one object or one line of text—without changing everything else?
- Can this approach beat current tools and produce designs that look professional?
3. How does PosterCopilot work? (Simple explanation)
Think of making a poster like arranging furniture in a room: you need to decide where the couch goes, how big the table should be, and what looks balanced and nice. PosterCopilot learns to do this in three training stages and then works with a “teammate” that can generate or edit images when needed.
Here’s what the three training stages do (imagine training a player with different coaches):
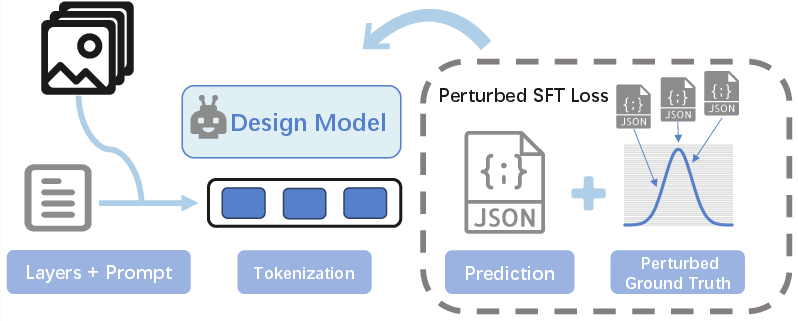
- Stage 1: Perturbed Supervised Fine-Tuning (PSFT)
- Analogy: Practice with slight variations to learn the “feel” of space.
- Instead of learning exact coordinates as fixed points, the AI practices with small, controlled “wobbles” around the correct positions. This helps it understand continuous space better—like learning to place a picture frame on a wall even if you start slightly off.
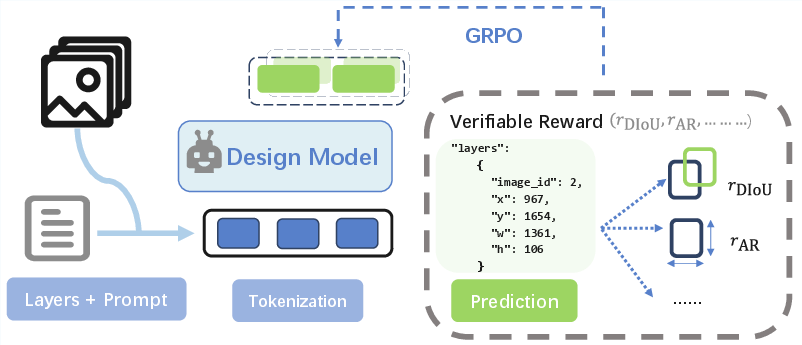
- Stage 2: Reinforcement Learning for Visual-Reality Alignment (RL-VRA)
- Analogy: A geometry coach checks the poster after it’s “hung,” correcting crooked frames, stretched images, or misplaced boxes.
- The AI gets rewards for accurate placement, keeping sizes and proportions correct, and outputting results in the right format. It learns to fix geometric mistakes (for example, not squashing a photo or drifting away from the intended position).
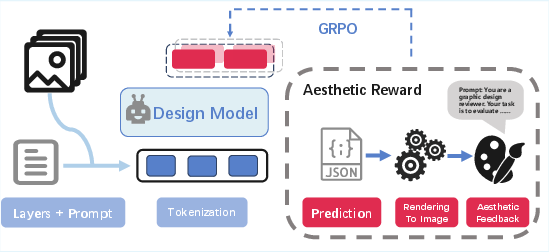
- Stage 3: Reinforcement Learning from Aesthetic Feedback (RLAF)
- Analogy: An art teacher gives feedback on what looks attractive and balanced.
- The AI explores more creative layouts and gets rewarded for designs that look good overall, even if they differ a bit from the original “answer.”
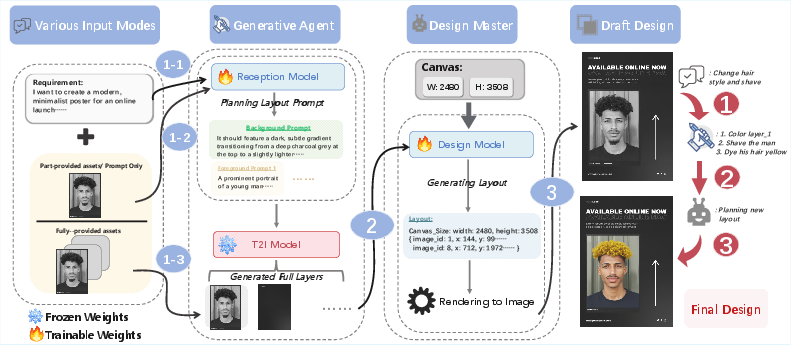
After training, PosterCopilot connects to a generative “agent” (another AI helper):
- If you don’t have all the assets (like a background image), the agent can create missing parts in the same style.
- It supports layer-specific editing: imagine each element on the poster sits on its own transparent sheet. You can change one sheet (like swapping a lollipop for an ice cream) without disturbing the others.
- It can do multiple rounds of edits, responding to precise instructions, while keeping the overall layout consistent.
4. What did they find, and why does it matter?
The researchers tested PosterCopilot against other tools, including popular commercial platforms and academic methods. They used both human designers and an AI judge to compare results.
Key findings:
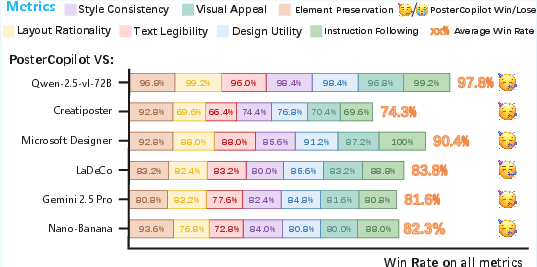
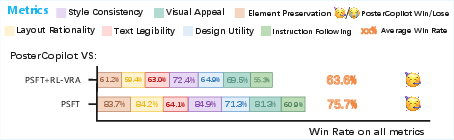
- PosterCopilot won most head-to-head comparisons, with an average win rate above 74% in user studies.
- It especially excelled at:
- Keeping user-provided elements intact (not removing or warping them).
- Making layouts that look organized, balanced, and professional.
- Following instructions while maintaining visual style and consistency.
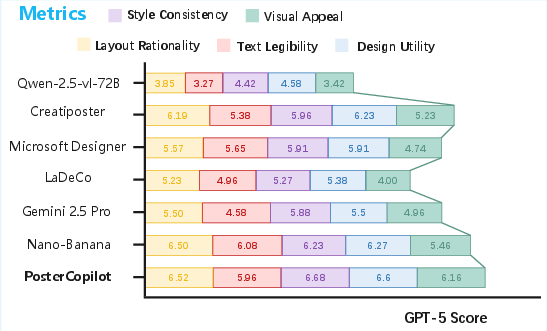
- Technical studies showed that:
- The second stage (RL-VRA) greatly improved geometric accuracy—boxes were placed and sized more correctly.
- The third stage (RLAF) boosted the overall look and appeal of posters.
- It also supports powerful editing:
- Single-layer edits without distortion (like changing a character’s pose or material).
- Theme switching (e.g., turning a “lollipop sale” poster into an “ice cream promotion” while keeping the same layout).
- Reframing to different canvas sizes while maintaining harmony.
Why it matters:
- Designers often need many rounds of precise edits. PosterCopilot supports that workflow while protecting the original assets.
- It helps bridge the gap between “what the computer generates” and “what looks good to people,” combining logic (geometry) with taste (aesthetics).
5. What’s the impact and what comes next?
Implications:
- PosterCopilot could act like a design assistant: it drafts, arranges, fixes, and improves your poster step by step.
- It makes AI-powered design more practical for real-world use—especially when lots of small edits are needed.
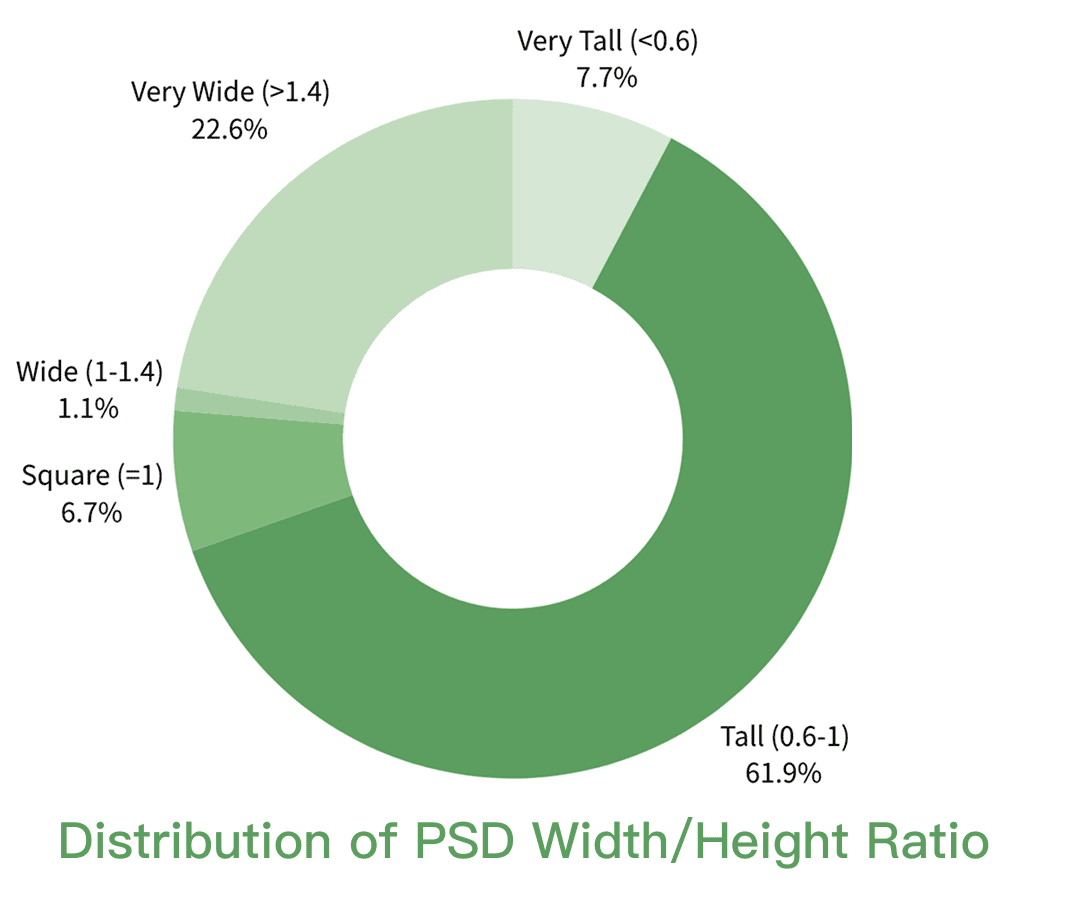
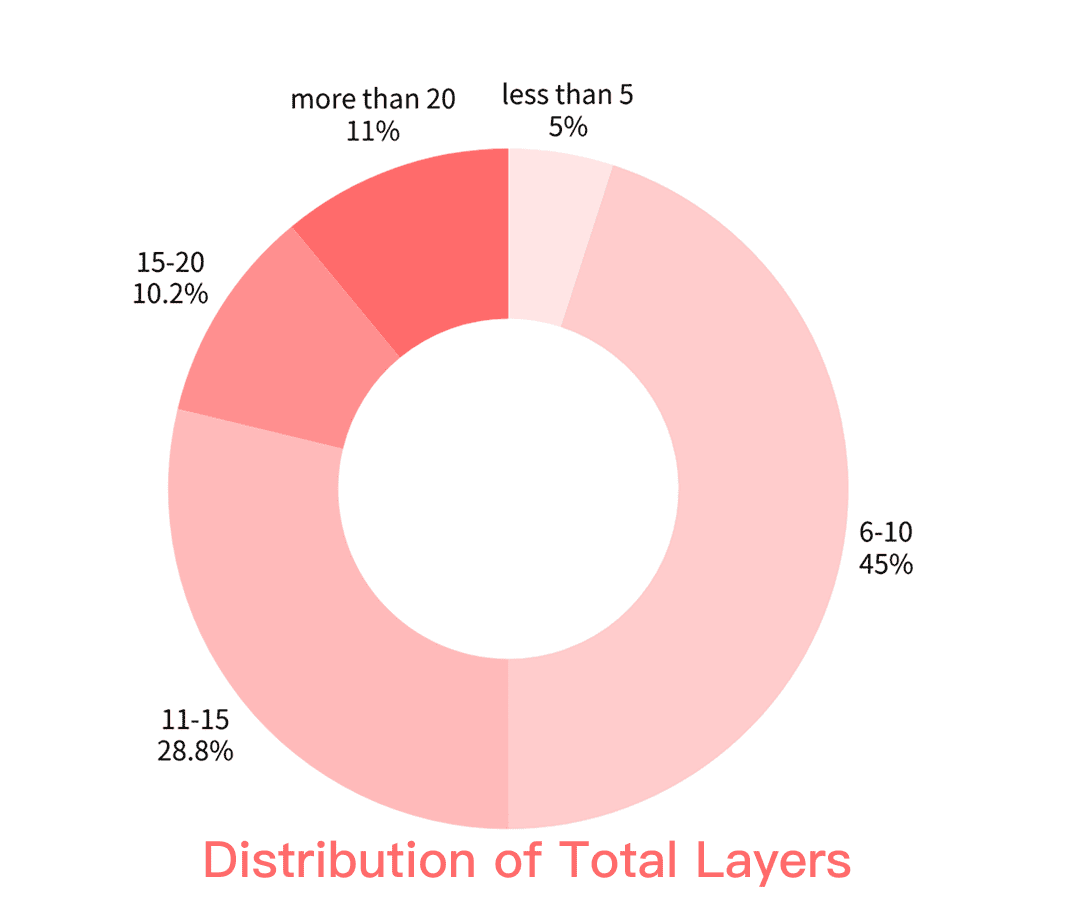
- It contributes a large, well-organized dataset of layered posters (160,000 posters with 2.6 million layers), which can help future research.
Limitations and future work:
- The “art teacher” reward is not tailored specifically to posters yet; a poster-specific aesthetic model could improve results further.
- Blend modes (how layers visually mix) are standard—exploring more creative blending could add polish.
Overall, PosterCopilot pushes AI design toward professional standards: better layout reasoning, careful control over edits, and results that look good—not just “correct.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, missing analyses, and actionable open questions for future work.
- Coordinate representation: The model still decodes continuous layout coordinates via discrete text tokens; no comparison to numeric heads or hybrid decoders (e.g., continuous regression modules or keypoint heads) that could eliminate token-induced geometric artifacts.
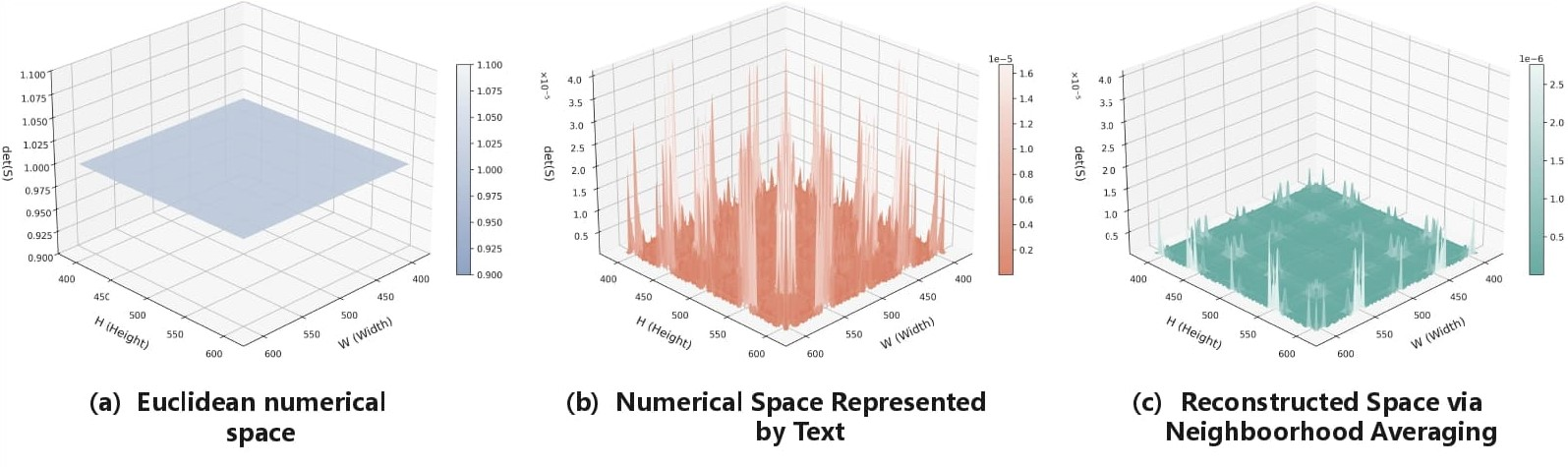
- PSFT design choices: The perturbation scheme (noise distribution, magnitude σ, per-dimension scaling, number of samples n) lacks principled selection and sensitivity analysis across asset densities and canvas sizes; theoretical grounding beyond the structure-tensor intuition is missing.
- Geometry validation: The “geometric instability” claim for text-based spaces is not quantitatively validated beyond a visualization; no controlled experiments isolating tokenization vs. decoding strategies to causally attribute errors.
- RL-VRA reliance on ground truth: The geometric reward depends on ground-truth boxes, limiting applicability to labeled data; how to extend alignment to unlabeled or in-the-wild assets via self-supervised visual constraints (overlap, alignment, symmetry, whitespace, grid adherence)?
- Reward shaping and stability: No ablation on KL coefficient β, GRPO group size K, clipping, or reward weights (λsize, λAR); training stability, sample efficiency, and variance across seeds remain unreported.
- Aesthetic reward validity: RLAF uses a generic aesthetic judge (VisualQuality-R1) not tailored to posters; needs a poster-specific, culturally robust, and bias-audited preference model, with tests for reward hacking and generalization across styles and regions.
- Human preference data: Absent collection of designer preference data to train or calibrate the aesthetic reward; open question on incorporating expert pairwise preferences or rubric-based scoring for typography, balance, and hierarchy.
- Typography modeling: Text is rasterized and evaluated coarsely; no explicit modeling of font selection, hierarchy, kerning, tracking, line breaks, text wrap, or grid-based typesetting; addressing text legibility (a known weakness) requires typography-aware modules and metrics.
- Multilingual and non-Latin scripts: No evaluation on scripts with complex shaping (Arabic, Devanagari), CJK fonts, right-to-left layouts, and accessibility considerations (contrast, font size).
- Beyond axis-aligned boxes: The system is limited to rectangular bounding boxes with no rotation, skew, masks, or vector shapes; support for Bezier curves, clipping paths, and rotated text/objects is not explored.
- Layer semantics and compositing: Layering is treated as z-order only; there is no controllable blend mode learning (the paper lists “standard blend modes” as a limitation), shadow/lighting, transparency, or advanced compositing controls common in professional tools.
- Dataset construction quality: OCR-based layer merging may introduce grouping errors; there is no quantitative audit of segmentation correctness, per-category quality, genre coverage, or annotation noise, nor a bias analysis (e.g., language, market, style distributions).
- Dataset availability and licensing: The paper claims a large multi-layer dataset but does not specify release terms, licenses, or usage restrictions; reproducibility and community benchmarking depend on public availability.
- Editing evaluation: No quantitative metrics for edit locality (how strictly edits are confined to target layers), preservation (unchanged layers), semantic fidelity, and layout stability across multi-round edits; no user study focused on iterative editing quality.
- Style consistency measurement: Asset synthesis and theme switching claim stylistic consistency but lack quantitative metrics (e.g., palette distance, CLIP-style embeddings, LPIPS/SSIM on reference-guided style) and controlled failure analyses.
- Constraint-aware design: The system does not explicitly support brand guidelines, modular grids, safe margins/bleeds, CMYK color constraints, or print specifications; how to encode and satisfy hard constraints during layout reasoning remains open.
- Robustness and scaling: No stress tests for extreme scenarios (50+ assets, tiny fonts, heavy occlusion, extreme aspect ratios); performance degradation and failure modes under high complexity are not characterized.
- Latency and resource profile: Inference time per design and per edit round, GPU/CPU memory footprint, and feasibility for interactive, real-time workflows are not reported; on-device or low-resource deployment is unaddressed.
- Generalization to other mediums: Applicability to magazines, brochures, social-media banners, UI screens, and animated layouts is unexplored; transfer learning or domain adaptation strategies are not studied.
- Instruction parsing reliability: The pipeline assumes accurate conversion of natural language requirements to structured constraints; robustness to underspecified, conflicting, or ambiguous instructions remains uncertain.
- Evaluation methodology: Reliance on proprietary GPT-5 for scoring (with omissions for instruction following and element preservation) reduces reproducibility; inter-rater reliability, statistical significance tests, and blinded protocols for human studies are not detailed.
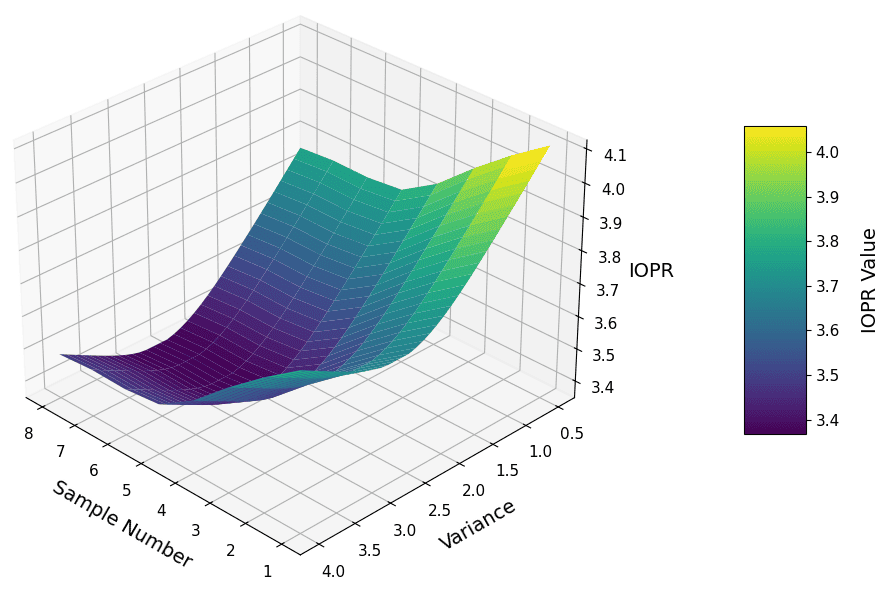
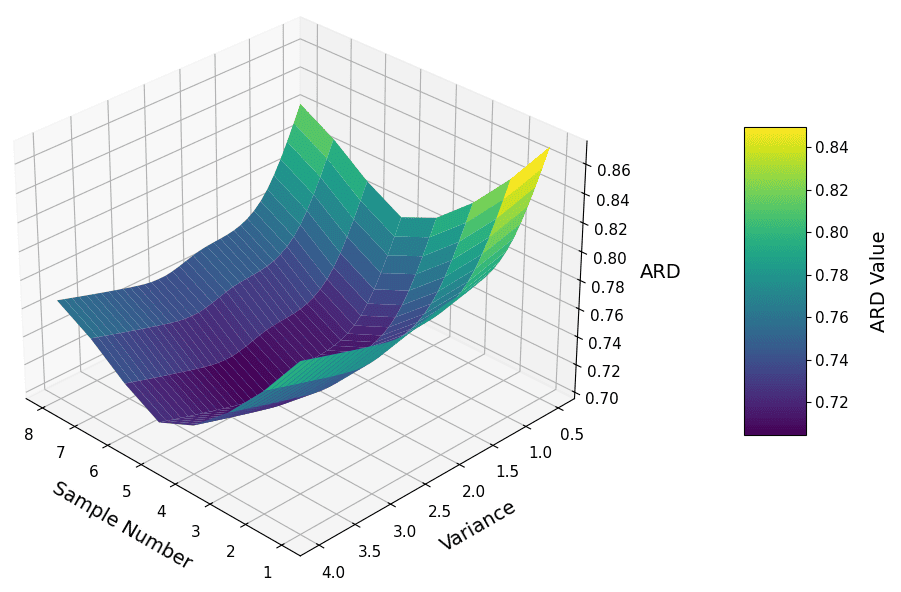
- Comparative quantitative benchmarks: IoU/IOPR/ARD are used only for ablations, not for cross-method comparisons; a standardized public benchmark with agreed-upon quantitative and preference metrics is missing.
- Human-in-the-loop learning: The system does not learn from real designers’ iterative corrections; integrating online preference learning or correction-driven RL for continual improvement is an open direction.
- Failure handling and reliability: No metrics on JSON formatting failures, invalid outputs, or recovery strategies; robustness of the format reward and parser under distribution shifts is unclear.
- Backbone dependence: Results depend on Qwen backbones and VisualQuality-R1; portability to other LMMs/T2I models, and sensitivity to backbone choice, are not examined.
Practical Applications
Immediate Applications
The following applications can be deployed with the current PosterCopilot workflow (PSFT + RL-VRA + RLAF, layer-controllable editing, JSON-structured outputs) and available tooling.
- Creative agencies and studios (software, advertising/marketing)
- Application: “Layout Copilot” inside Adobe Photoshop/Illustrator or Figma/Canva to auto-arrange provided assets into professional poster layouts, then iterate with precise layer-wise edits and theme switches.
- Tools/Products/Workflows: Plugin or API that ingests asset packs and requirements, outputs JSON layout + layered PSD/SVG; uses RL-VRA for geometric accuracy and RLAF for aesthetics; multi-round editing loop for designer-in-the-loop.
- Assumptions/Dependencies: High-quality layered assets, font licensing, model/API integration with design tools, GPU resources for T2I and LMM inference.
- E‑commerce and retail campaign production (advertising/marketing, software)
- Application: “Batch Reframer” that retargets a poster to many placements (homepage hero, app banner, OOH billboard) by changing canvas size while preserving layout harmony.
- Tools/Products/Workflows: Automated multi-aspect export pipeline; layout JSON → programmatic render → creative variations via RLAF for A/B testing.
- Assumptions/Dependencies: Brand guidelines, placement specs, DAM integration, human QA for text legibility and compliance.
- SMBs, social media managers, and event organizers (daily life, software)
- Application: One-click poster creator that completes missing assets (backgrounds, foregrounds) and supports fine-grained edits (e.g., swapping objects, colorways).
- Tools/Products/Workflows: Web/mobile app using the generative agent to synthesize missing layers and iterative layer-specific editing; preset templates for common events.
- Assumptions/Dependencies: T2I model quality and style consistency, basic design brief, legal ownership of provided assets.
- Print/prepress quality assurance (software, print industry)
- Application: “Layout QA Bot” that flags misalignment, aspect ratio distortion, and formatting errors using RL-VRA reward checks (DIoU, ARD, size).
- Tools/Products/Workflows: Preflight checker embedded in DTP workflows; validates JSON output consistency and highlights geometry violations before print.
- Assumptions/Dependencies: Access to layout JSON and original assets; rule thresholds tuned to print specs.
- Brand compliance and asset preservation (advertising/marketing, enterprise software)
- Application: “Brand‑Guard Copilot” that enforces element fidelity (proportions, layer order, no unintended warping) while enabling localized edits on approved layers.
- Tools/Products/Workflows: Policy-based editing guardrails; RL-VRA reward thresholds to prevent geometry drift; audit logs of edits.
- Assumptions/Dependencies: Brand libraries, compliance rules encoded in the workflow, role-based access controls.
- Localization workflows (advertising/marketing, software)
- Application: Multi-language poster adaptation with preserved layout; swap text layers (rasterized or vectorized) and refit content while maintaining composition.
- Tools/Products/Workflows: Language-specific text handling; layout reflow with RL-VRA; font fallback mapping; optional typographic post-processing for legibility.
- Assumptions/Dependencies: Font availability per locale, hyphenation rules, RTL/LTR support; additional legibility checks where PosterCopilot may underperform.
- Education and training in graphic design (education, academia)
- Application: Interactive tutor demonstrating layout corrections and aesthetic refinements; show how rewards (geometry and aesthetics) guide design decisions.
- Tools/Products/Workflows: Classroom demos, assignments using the multi-layer dataset; step-by-step edit replays; critique generation via the aesthetic judge.
- Assumptions/Dependencies: Institutional access to models and datasets; instructor-curated briefs; licensing for educational use.
- Developer APIs and workflow automation (software)
- Application: Layout-as-a-service providing JSON specifications and layered outputs; programmatic multi-round edits triggered by business rules or user prompts.
- Tools/Products/Workflows: REST API with inputs (assets, canvas, constraints) and outputs (layout JSON + renders); integration with DAM/CMS/CI pipelines.
- Assumptions/Dependencies: Stable endpoints, versioning, SLAs; cost control for inference; logging/auditing for governance.
- Public sector and community communications (policy operations, daily life)
- Application: Rapid creation of municipal/community event flyers with consistent visual hierarchy and accessible variants (e.g., large-type versions).
- Tools/Products/Workflows: Template library seeded by PosterCopilot; iterative layer edits for compliance stamps and disclaimers; exports for print and social.
- Assumptions/Dependencies: Accessibility guidance and local branding standards; approvals workflow; minimal compute footprints.
- Academic research baselines (academia)
- Application: Use the high-quality multi-layer poster dataset and training paradigm (PSFT, RL-VRA, RLAF) as benchmarks for layout reasoning and aesthetic alignment.
- Tools/Products/Workflows: Reproducible training scripts and ablations; cross-task transfer studies (e.g., continuous coordinate learning via PSFT).
- Assumptions/Dependencies: Dataset licensing; compute availability; public access to reward models or substitutes.
Long-Term Applications
These applications require further research, scaling, or productization (e.g., poster-specific aesthetic reward models, stronger typography engines, broader datasets, model compression).
- Multi-page editorial and brochure design (publishing, advertising/marketing)
- Application: Automated layout across pages with grid systems, typographic rhythm, and content flow (covers, spreads, catalogs).
- Tools/Products/Workflows: Extended RL rewards for pagination, grid alignment, and readability; dataset expansion beyond single-page posters.
- Assumptions/Dependencies: Multi-page datasets, typographic reward models (kerning, line breaks), editorial constraints.
- UI/UX screen and dashboard layout (software)
- Application: Apply PSFT+RL-VRA to interface components (cards, charts, forms) for auto-layout under interaction/accessibility constraints.
- Tools/Products/Workflows: Plug-ins for design systems; constraints solver for tap targets and WCAG; iterative refactoring of screen variants.
- Assumptions/Dependencies: Domain-specific datasets, accessibility rules encoded as rewards, human review loops.
- Brand‑safe generative asset synthesis (advertising/marketing, enterprise software)
- Application: Automatically generate new on-brand assets under strict compliance and IP constraints; prevent style drift.
- Tools/Products/Workflows: Poster-specific aesthetic reward model plus brand classifiers; content filters; provenance and watermarking.
- Assumptions/Dependencies: Legal frameworks for AI-generated assets, robust brand detection, governance/audit infrastructure.
- Real-time creative optimization (advertising/marketing, finance)
- Application: Continual A/B testing of poster variants where conversion metrics become RL rewards to optimize layouts for performance.
- Tools/Products/Workflows: Experimentation platforms feeding engagement KPIs into RLAF; variant orchestration and throttling.
- Assumptions/Dependencies: Reliable measurement pipelines, guardrails to avoid clickbait or unfair bias, privacy-compliant data flows.
- Accessibility-first design automation (policy, education, healthcare)
- Application: Integrate legibility and accessibility reward functions (WCAG/ADA) to auto-adjust font size/contrast and reading order.
- Tools/Products/Workflows: Text-specific reward models; contrast/legibility checks; assistive variants (high-contrast, large-type).
- Assumptions/Dependencies: Standards-aligned reward functions, localized accessibility rules, testing with diverse user groups.
- Edge/on-device assistants (software, mobile)
- Application: Low-latency poster creation and iterative edits on mobile devices for field teams and small businesses.
- Tools/Products/Workflows: Model distillation and quantization; partial-on-device inference with cloud fallback; offline templates.
- Assumptions/Dependencies: Efficient LMM/T2I deployment, hardware acceleration, graceful degradation strategies.
- Sector-specific design automation (manufacturing/CPG, healthcare, energy)
- Application: Packaging labels, safety signage, patient education posters, and procedural graphics with strict regulatory constraints.
- Tools/Products/Workflows: Rule engines codifying placement of warnings/disclaimers; RL constraints for mandatory elements; audit trails.
- Assumptions/Dependencies: Domain datasets, regulatory integration, formal verification for compliance-critical layouts.
- Policy and standards for AI-generated creative (policy)
- Application: Adoption of layer-structured metadata (JSON), provenance, audit logs, and disclosure norms for AI-assisted design in public communications.
- Tools/Products/Workflows: Industry standards (e.g., ISO-like specs) for layer metadata; watermarking; transparency labels.
- Assumptions/Dependencies: Cross-industry consensus, interoperability with design tools, regulatory buy-in.
- Cross-domain research extensions (academia)
- Application: Transfer PSFT/RL-VRA to other continuous geometry tasks (document layout, 3D scene arrangement, CAD nesting).
- Tools/Products/Workflows: New reward functions for physical constraints and spatial ergonomics; synthetic datasets; hybrid simulation loops.
- Assumptions/Dependencies: Task-specific evaluators, data generation pipelines, interdisciplinary collaboration.
Glossary
- Advantage (RL): A quantity that measures how much better an action is compared to the average or baseline in a given context, used to guide policy updates. "A_i represents the advantage of action relative to the group"
- Aesthetic reward model: A learned scorer that evaluates the visual appeal of generated designs to provide feedback for reinforcement learning. "Reinforcement Learning from Aesthetic Feedback (RLAF) employs a learned aesthetic reward model to encourage the model to generate aesthetically coherent and diverse compositions that extend beyond the ground truth."
- Aspect Ratio Distortion (ARD): A metric that quantifies changes in the width-to-height proportions of elements compared to their ground truth. "Aspect Ratio Distortion (ARD) \cite{zheng2020distance} for ablation study."
- Bounding box drift: A rendering-stage error where predicted boxes shift away from intended locations, causing spatial inaccuracies. "geometric flaws, such as bounding box drift and aspect ratio distortion."
- Distance Intersection over Union (DIoU): An IoU variant that penalizes the Euclidean distance between box centers to improve localization accuracy. "The spatial reward $r_{\text{Spatial}$ addresses layout misalignment through Distance Intersection over Union (DIoU) \cite{zheng2020diou}:"
- Group Relative Policy Optimization (GRPO): A reinforcement learning method that optimizes policies by comparing rollouts within a group, avoiding explicit value function estimation. "we employ Group Relative Policy Optimization (GRPO) \cite{shao2024deepseekmath}, which operates without explicit value function estimation."
- Huber loss: A robust loss function that behaves quadratically for small errors and linearly for large errors, reducing sensitivity to outliers. "maintains original dimensions using the Huber loss \cite{girshick2015fast}:"
- Intersection over Union (IoU): A standard measure of overlap between two regions, computed as the area of their intersection divided by the area of their union. "$\text{IoU}(\boldsymbol{b}_i, \boldsymbol{b}_i^{\text{gt})$"
- Inverse order pair ratio (IOPR): A metric that measures how often the relative layering order of elements is inverted or incorrect. "Inverse order pair ratio (IOPR) \cite{cheng2025graphic}"
- Kullback–Leibler divergence (KL divergence): A measure of dissimilarity between probability distributions, used as a regularizer to keep updated policies close to a reference. "$-\beta D_{KL}(\pi_\theta( \cdot \mid s) \,||\, \pi_{\text{ref}(\cdot \mid s))$"
- Large Multimodal Models (LMMs): Models capable of jointly understanding and generating across multiple modalities, such as text and images. "Recent advances have explored automating this process using Large Multimodal Models (LMMs)"
- Markov Decision Process (MDP): A mathematical framework for sequential decision-making where outcomes depend probabilistically on the current state and action. "We frame RL-VRA as an online policy optimization task under a single-step Markov Decision Process (MDP)."
- Minimal enclosing box: The smallest bounding box that contains two boxes, used in DIoU to normalize center distances. " represents the diagonal of the minimal enclosing box"
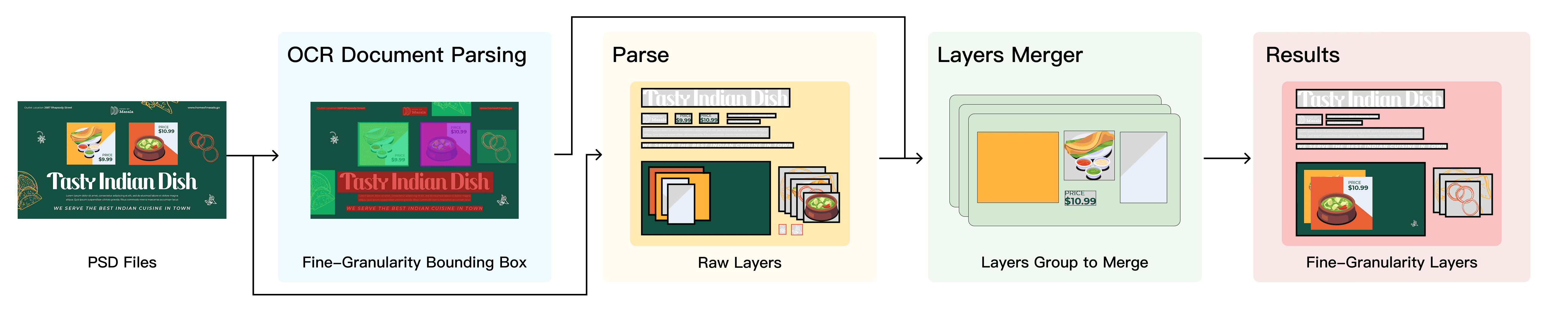
- Optical Character Recognition (OCR): Technology that detects and extracts text from images for downstream processing. "we employ OCR-based fine-granularity bounding box to merge overly fine-grained layers and filter out redundant ones."
- Perturbed Supervised Fine-Tuning (PSFT): A training strategy that adds controlled noise to targets so the model learns distributions over coordinates rather than memorizing discrete tokens. "we propose Perturbed Supervised Fine-Tuning (PSFT), which reformulates coordinate regression into a distribution-based learning paradigm by introducing controlled perturbations to ground-truth coordinates."
- Policy gradient: A class of reinforcement learning methods that update policy parameters by following the gradient of expected return. "This geometrically-grounded reward structure injects explicit visual-reality constraints directly into the policy gradient updates"
- Policy rollouts: Samples of actions generated by a policy to estimate performance and compute learning signals. "For each group of policy rollouts, we compute:"
- Rasterization: The process of converting text or vector graphics into pixel-based image layers for unified handling. "Text elements are rasterized into image layers for unified processing."
- Reference policy: A frozen baseline policy used to constrain learning via KL regularization and prevent overly large updates. "with $\pi_{\text{ref}$ serving as the frozen reference policy"
- Reinforcement Learning for Visual-Reality Alignment (RL-VRA): An RL phase that uses geometry-aware rewards to correct spatial inaccuracies and align outputs with real visual constraints. "we introduce the Reinforcement Learning for Visual-Reality Alignment (RL-VRA) phase."
- Reinforcement Learning from Aesthetic Feedback (RLAF): An RL phase that leverages aesthetic judgments to explore and optimize for visually appealing layouts beyond the ground truth. "we introduce the Reinforcement Learning from Aesthetic Feedback (RLAF) stage."
- Structure Tensor: A matrix computed from local image gradients to characterize orientation and coherence, used here to analyze geometric stability. "we visualize the local geometric uniformity using , the determinant of the Structure Tensor "
- Text-to-Image (T2I): Generative models that produce images from textual descriptions. "be fed together into a text-to-image (T2I) model to generate the corresponding assets."
- Value function: An estimator of expected return used in many RL algorithms; GRPO avoids learning it by using group-relative comparisons. "operates without explicit value function estimation."
Collections
Sign up for free to add this paper to one or more collections.

