- The paper rigorously compares general and novel statistical methods by assessing Type I error, power, and predictive accuracy across diverse exposure scenarios.
- It shows that general methods perform well under moderate complexity while novel approaches like BKMR excel in highly nonlinear or interactive settings.
- The findings offer practical guidelines for method selection in epidemiological mixture analysis, balancing model interpretability, computational efficiency, and diagnostic precision.
Comparative Evaluation of Statistical Methods for Chemical Mixture Analyses in Epidemiology
Introduction
Analyzing health impacts of chemical mixtures in epidemiology presents multifaceted statistical challenges, notably the presence of correlation among exposure variables, moderate-to-high dimensionality, and potentially nonlinear or interactive exposure-response relationships. The field has witnessed the development of “novel” methods specifically designed for mixtures, such as Bayesian Kernel Machine Regression (BKMR), Weighted Quantile Sum (WQS) regression, and Quantile G-Computation (QGC). These methods promise advantages over traditional, “general” approaches (e.g., GLMs, GAMs, PCR, Elastic Net) but the nuanced circumstances under which these novel methods offer demonstrable benefits remain underexplored. This paper presents a rigorous simulation-based assessment encompassing both general and novel methodologies, providing a granular perspective on Type I error control, statistical power, predictive accuracy, and interpretability.
Statistical Framework and Methods Considered
The fundamental modeling structure focused on estimating the expected outcome μi=E(yi∣ai,xi) using a link function g, with exposures ai and covariates xi. The principal modeling classes examined were:
- General Methods: GLMs, GAMs, PCR, Elastic Net/LASSO.
- Novel Mixture Methods: BKMR, WQS regression, QGC.
Each method was evaluated in terms of its suitability for (i) discriminating individual mixture component effects, (ii) detecting overall mixture associations, and (iii) predictive modeling/accuracy, as well as interpretability and technical limitations.
Simulation Study Design
A controlled simulation study interrogated the empirical properties of the aforementioned methods across a factorial grid of scenarios: varying sample size (n), exposure dimension (p), correlation among exposures (ρ), and underlying exposure-response function complexity (linear, nonlinear, interaction, dense, and with possible opposing effects). The study targeted quantification of Type I error rates (false positives under the null), statistical power (probability of correctly detecting nonzero associations), and predictive mean squared error (MSE) on out-of-sample data. Nominal Type I error control thresholds were set to α=0.05.
Component-Wise Hypothesis Testing
GLMs, GAMs, and BKMR with stringent Posterior Inclusion Probability (PIP) cutoff ($0.95$) achieved robust Type I error control (at or below 0.05). In less complex exposure-response settings (linear, nonlinear, simple interactions), both GLMs and GAM (HT) delivered competitive or superior power relative to novel approaches, provided exposure dimensionality and correlation were moderate.
Overly-sensitive approaches (BKMR with PIP cutoff $0.5$, Elastic Net, GAM variable selection) suffered from excessive Type I error (as seen at β=0 in power curves).
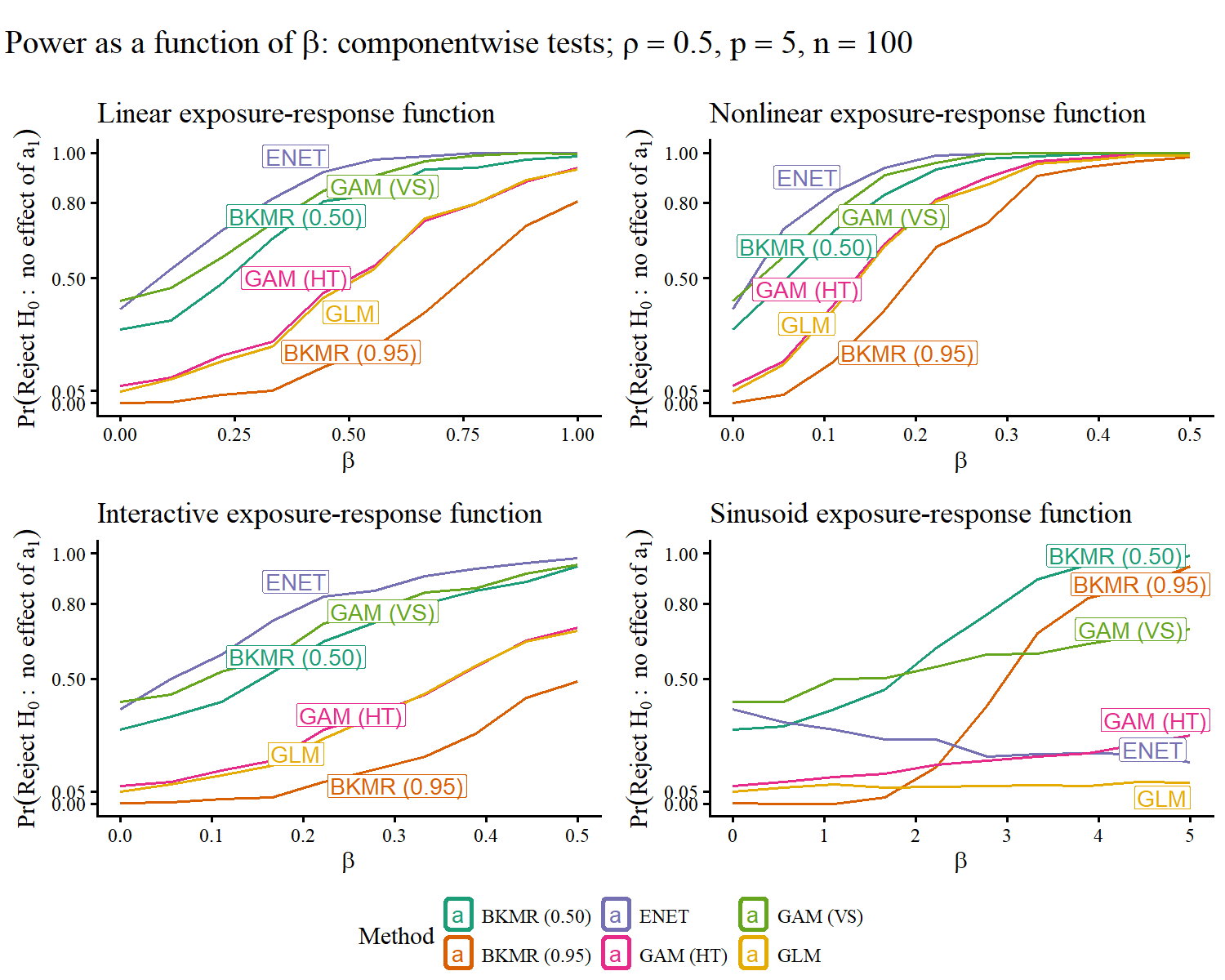
Figure 1: Estimated Type I error and power for component-wise tests, showing which methods are overly sensitive versus strictly controlled.
In highly nonlinear, interactive scenarios (sinusoid), only BKMR maintained acceptable power, highlighting flexibility as a critical advantage when true signal complexity surpasses additive or linear model capacity.
Overall Mixture Hypothesis Testing
The GLM F-test was effective for small-to-moderate p and ρ but its power diminished rapidly when dimensionality or exposure intercorrelation escalated. Methods such as QGC, WQS, and PCR, which summarize exposures prior to hypothesis testing, provided stronger power in these settings. However, these methods assume “directional homogeneity” or summarize outcome-exposure relationships irrespective of component-outcome directionality, losing power with opposing effects.
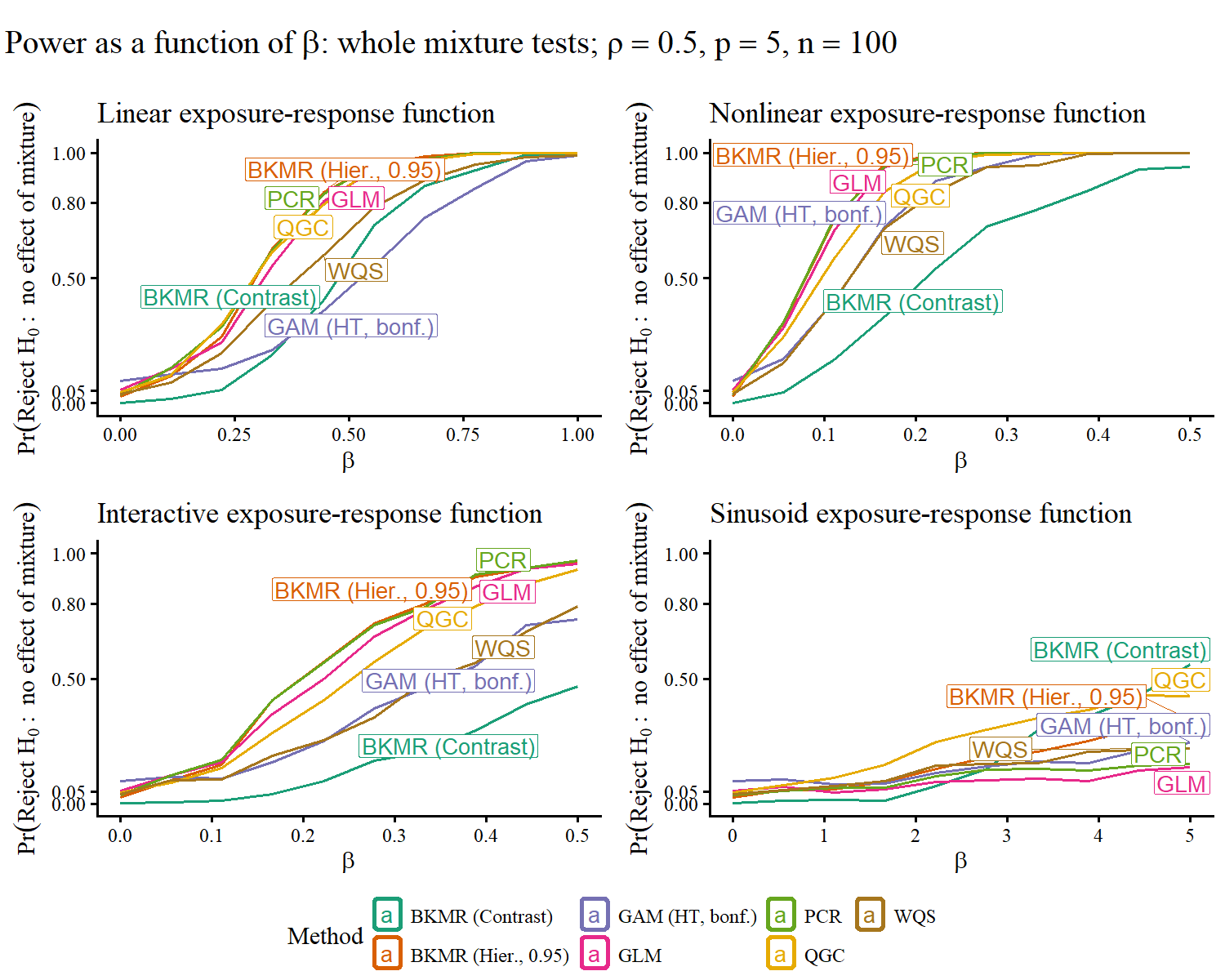
Figure 2: Power curves for overall mixture association under moderate correlation, showing relative performance across modeling strategies.
Empirical evidence favored QGC and PCR in moderate-to-high correlation scenarios.
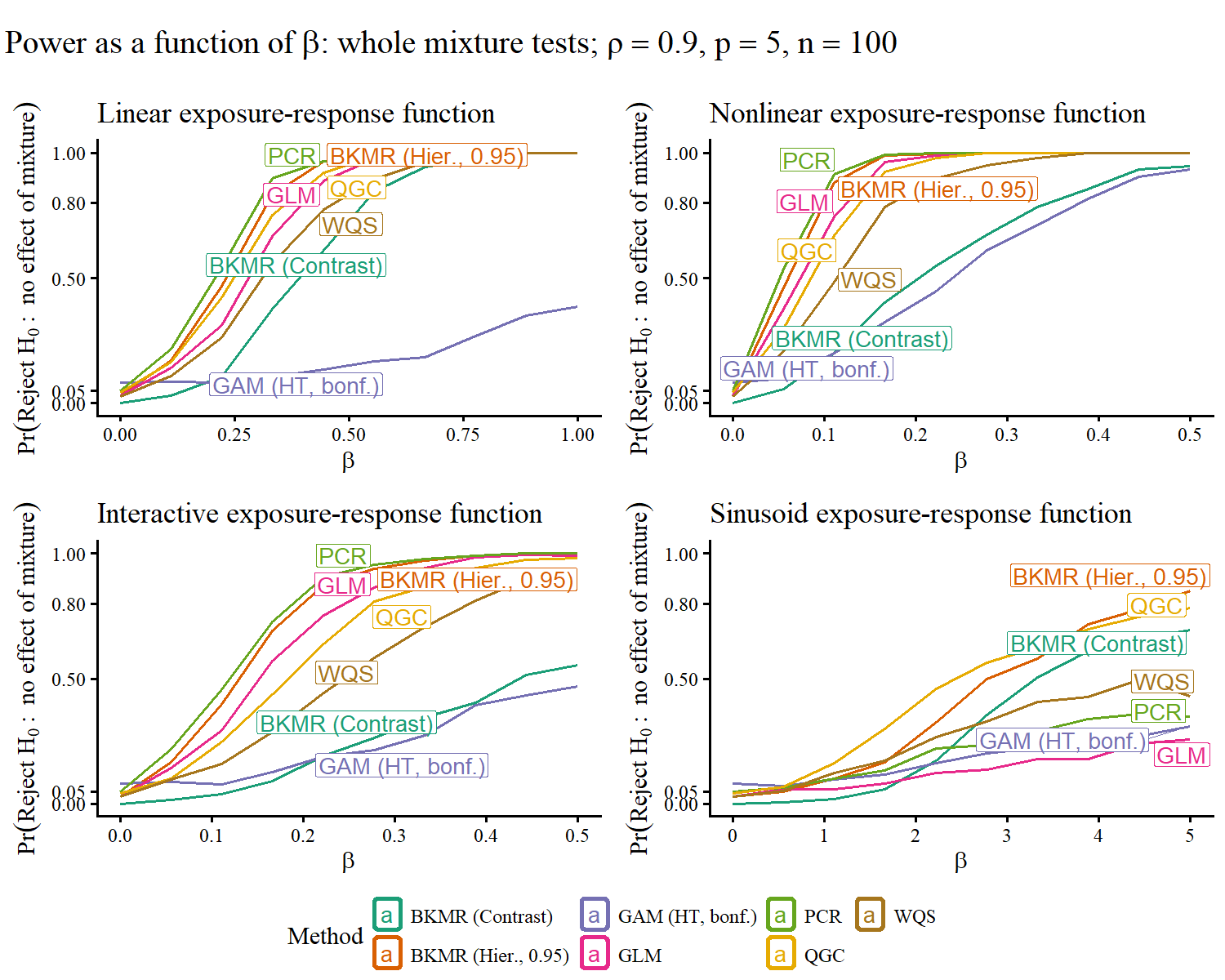
Figure 3: Increased exposure correlation (high ρ) amplifies the performance advantage of QGC and PCR over GLM.
Opposing effects posed a significant challenge, sharply reducing power for whole-mixture tests except for GLM and GAM.
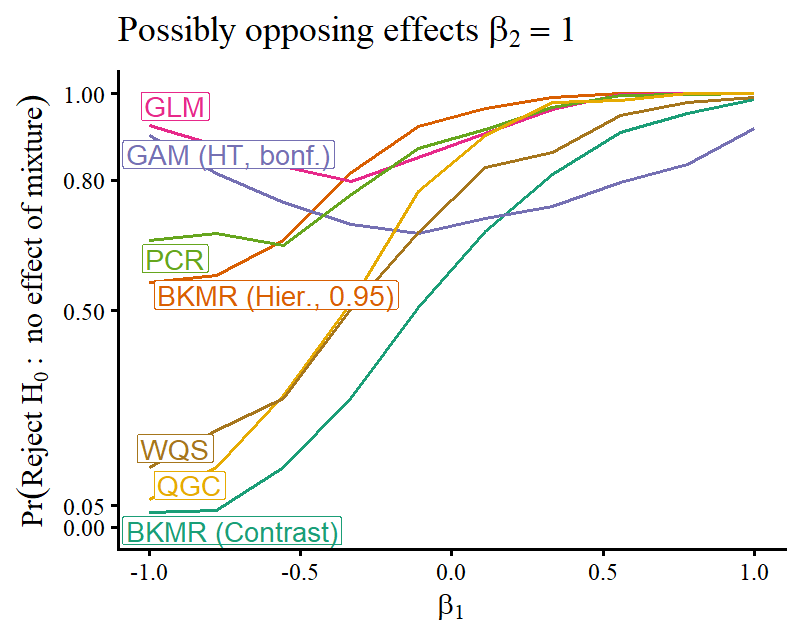
Figure 4: When mixture components have opposing effects, GLM/GAM outperform QGC, WQS, BKMR, and PCR for overall mixture association.
MSE analyses indicated that correct model specification is crucial as the strength of exposure-response association increases. GLM and Elastic Net were optimal for linear scenarios; GAM for nonlinear; and BKMR for interaction-dominated or complex nonlinear settings.
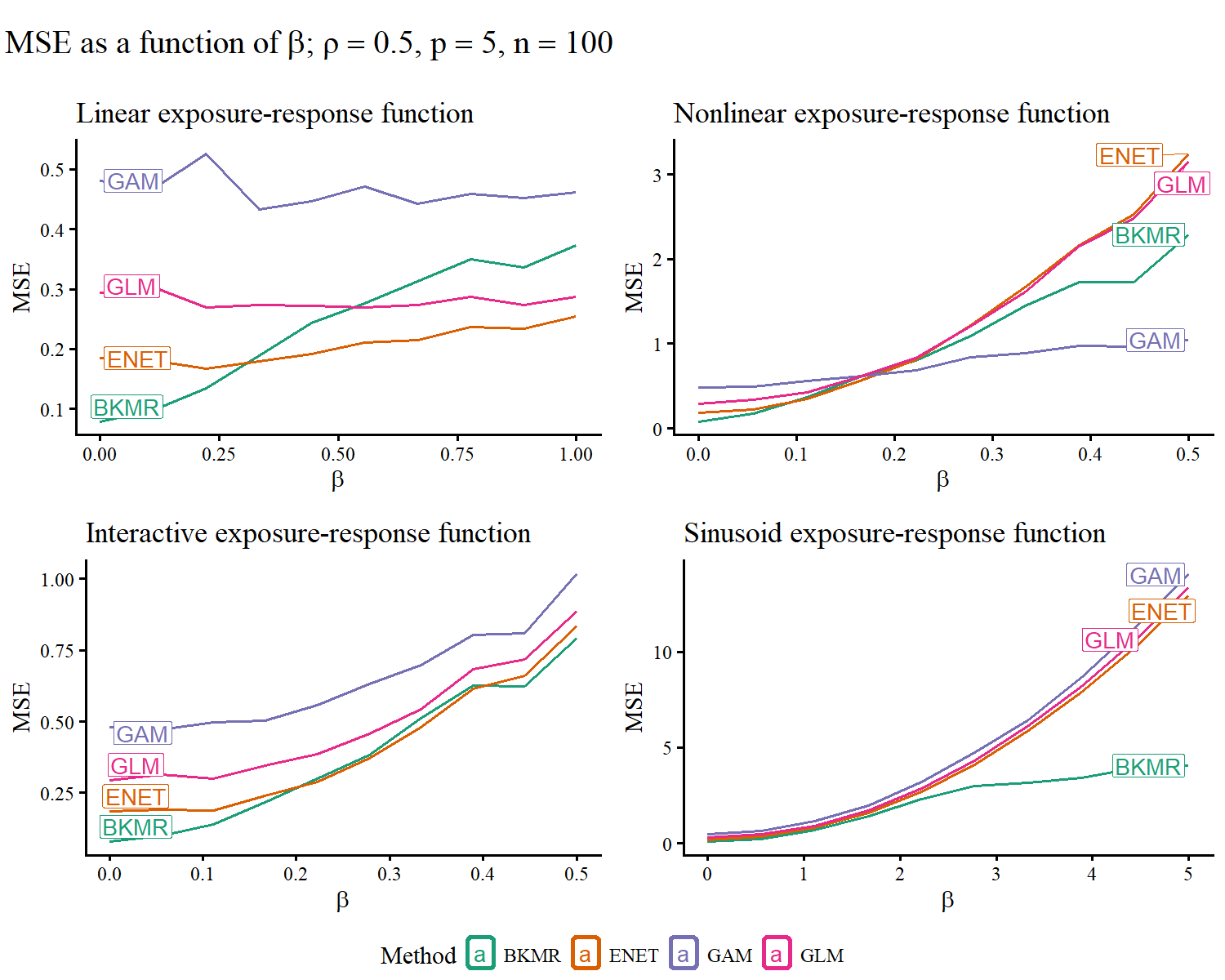
Figure 5: Predictive MSE comparison across models and association strengths for several exposure-response functional forms.
Elastic Net and BKMR excelled when true associations were weak, likely due to variable selection mechanisms.
Practical Recommendations and Method Selection
Empirical findings support the following claims:
- General methods (GLM, GAM) are preferred for moderate p, moderate ρ, and non-complex exposure-response functions.
- Novel methods (BKMR, QGC, WQS, PCR): Only justified with highly interactive/nonlinear exposure-response surfaces or pronounced exposure correlation/many predictors.
- Opposing effects: General methods remain robust; whole-mixture summary methods experience severe power loss.
- Low sample size: BKMR is disadvantaged; general techniques are recommended.
- Interpretability: GLMs/QGC yield coefficients interpretable as marginal effects; other methods require graphical/post-hoc summaries.
Tradeoffs include computational efficiency (GLMs, GAMs are fastest), interpretability (highest for GLMs), and diagnostic flexibility. PIP thresholds for BKMR require careful tuning; QGC/WQS weights can mislead if directional homogeneity is violated; PCR may obscure significant mixture components not captured by selected principal components.
Implications and Future Directions
These findings delineate clear boundaries for the utility of novel mixture methods. Theoretical implications include the necessity for tailored error rate control in high-dimensional hypothesis testing and a demand for model selection strategies sensitive to both data-generating process complexity and domain-specific interpretability requirements. Practically, the field should resist uncritical adoption of specialized mixture methods in favor of careful matching between method and data characteristics.
Emerging research may address hybrid strategies combining flexible modeling (e.g., kernel methods) with interpretability (contrast summaries) and formalize guidance for PIP cutoff calibration or cross-validated predictive selection across heterogeneous scenarios. Further research is also warranted to expand evaluation for very high-dimensional, sparse, or multi-omics settings and sharpen utility criteria for policy-relevant inference.
Conclusion
Rigorous simulation analysis establishes that choice of method for analyzing chemical mixtures in epidemiology should be scenario-driven: general methods suffice in simplistic regimes, while novel, mixture-specific algorithms are only advantageous in more convoluted statistical contexts (high ρ, complex h, large p). Methodological enthusiasm for novel techniques must be balanced by empirical validation and interpretability demands. Future developments in mixture modeling should aim for flexible, robust, and interpretable solutions adaptable to varied real-world challenges.