MagicQuillV2: Precise and Interactive Image Editing with Layered Visual Cues (2512.03046v1)
Abstract: We propose MagicQuill V2, a novel system that introduces a \textbf{layered composition} paradigm to generative image editing, bridging the gap between the semantic power of diffusion models and the granular control of traditional graphics software. While diffusion transformers excel at holistic generation, their use of singular, monolithic prompts fails to disentangle distinct user intentions for content, position, and appearance. To overcome this, our method deconstructs creative intent into a stack of controllable visual cues: a content layer for what to create, a spatial layer for where to place it, a structural layer for how it is shaped, and a color layer for its palette. Our technical contributions include a specialized data generation pipeline for context-aware content integration, a unified control module to process all visual cues, and a fine-tuned spatial branch for precise local editing, including object removal. Extensive experiments validate that this layered approach effectively resolves the user intention gap, granting creators direct, intuitive control over the generative process.
Sponsor






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MagicQuill V2: Easy-to-Control AI Image Editing with Layers
1) What this paper is about
This paper introduces MagicQuill V2, a new AI tool for editing images that works a lot like drawing apps with layers (think Photoshop). Instead of typing one long, vague prompt like “make the dog face the camera and add a hat,” MagicQuill V2 lets you tell the AI exactly:
- what you want to add,
- where it should go,
- what shape it should have, and
- what colors it should be.
It combines the creative power of modern AI with the precise control of classic graphics software.
2) What the researchers wanted to achieve
The team asked a simple question: How can we give people fine-grained control over AI image edits without relying only on text prompts?
Their goals were:
- Split a user’s intent into clear parts: what to create, where to put it, how it should look, and with what colors.
- Build a system where each part is controlled by its own “layer,” so edits are predictable and precise.
- Make the AI pay close attention to those layers and follow them accurately, even for tricky edits like “turn just the dog’s head” or “remove this object.”
3) How the system works (in everyday terms)
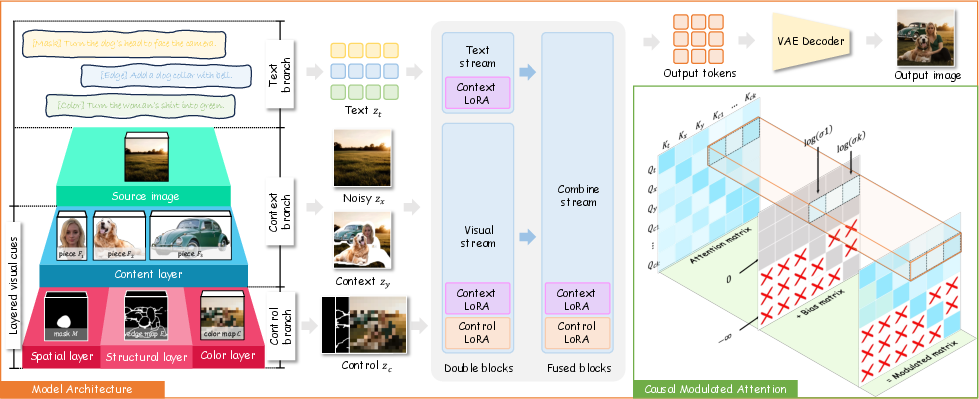
Think of editing an image like building a sandwich: each layer adds something important. MagicQuill V2 uses four visual layers so you can express your idea step by step.
Here are the four layers:
- Content layer (the “what”): pieces of objects you want to add (for example, a dog or a hat).
- Spatial layer (the “where”): a mask you paint to show the exact area to edit.
- Structural layer (the “shape”): a simple sketch or edge map that shows outlines and pose.
- Color layer (the “colors”): brush strokes that tell the model which colors to use.
To make the AI understand and respect these layers, the team did two big things:
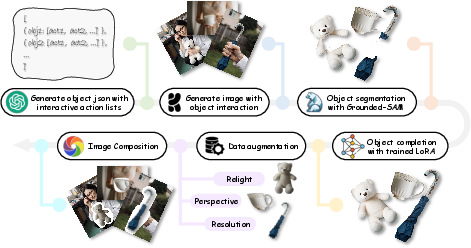
- Training with smart, realistic examples:
- They created scenes, cut out objects, and then “repaired” missing parts of those objects with a special mini-model (so the system learns to insert real, complete objects, not just “paste” them).
- They changed the lighting, size, and perspective of the objects (like tilting or shrinking them) before putting them back into the scene. This teaches the AI to fix lighting mismatches, handle low-resolution inputs, and correct geometry.
- A unified “control module” inside the AI:
- Imagine lots of voices talking (text, image noise, layers); they gave the visual layers a “volume knob” so the AI listens more or less to each cue. This knob is called the control strength (σ). Turn it up to make the AI follow your sketch strictly; turn it down if your sketch is rough and you want the AI to fill in the details.
- They also prevent different control signals (like edge vs. color) from interfering with each other, so each does its job cleanly.
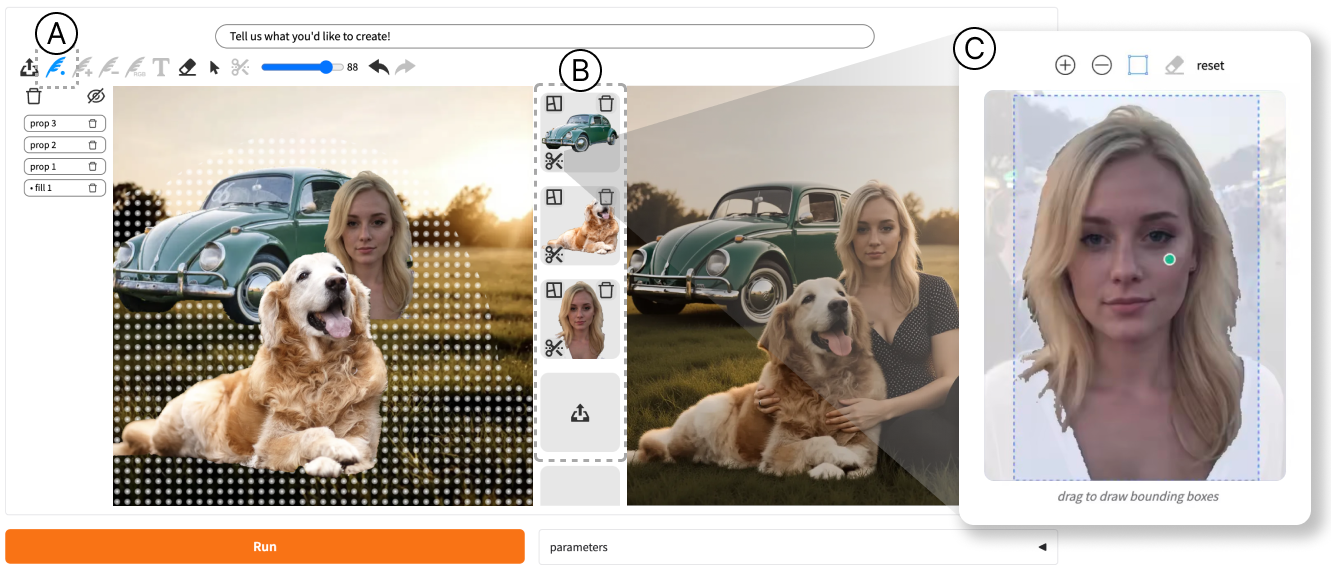
There’s also an interactive interface:
- A Fill Brush to paint where the edit should happen (the mask).
- A Visual Cue Manager where you drag-and-drop object pieces onto the canvas.
- A Segmentation Panel powered by SAM (Segment Anything) to quickly cut out objects from images for reuse.
4) What they found and why it matters
The team tested MagicQuill V2 against well-known tools and models and found:
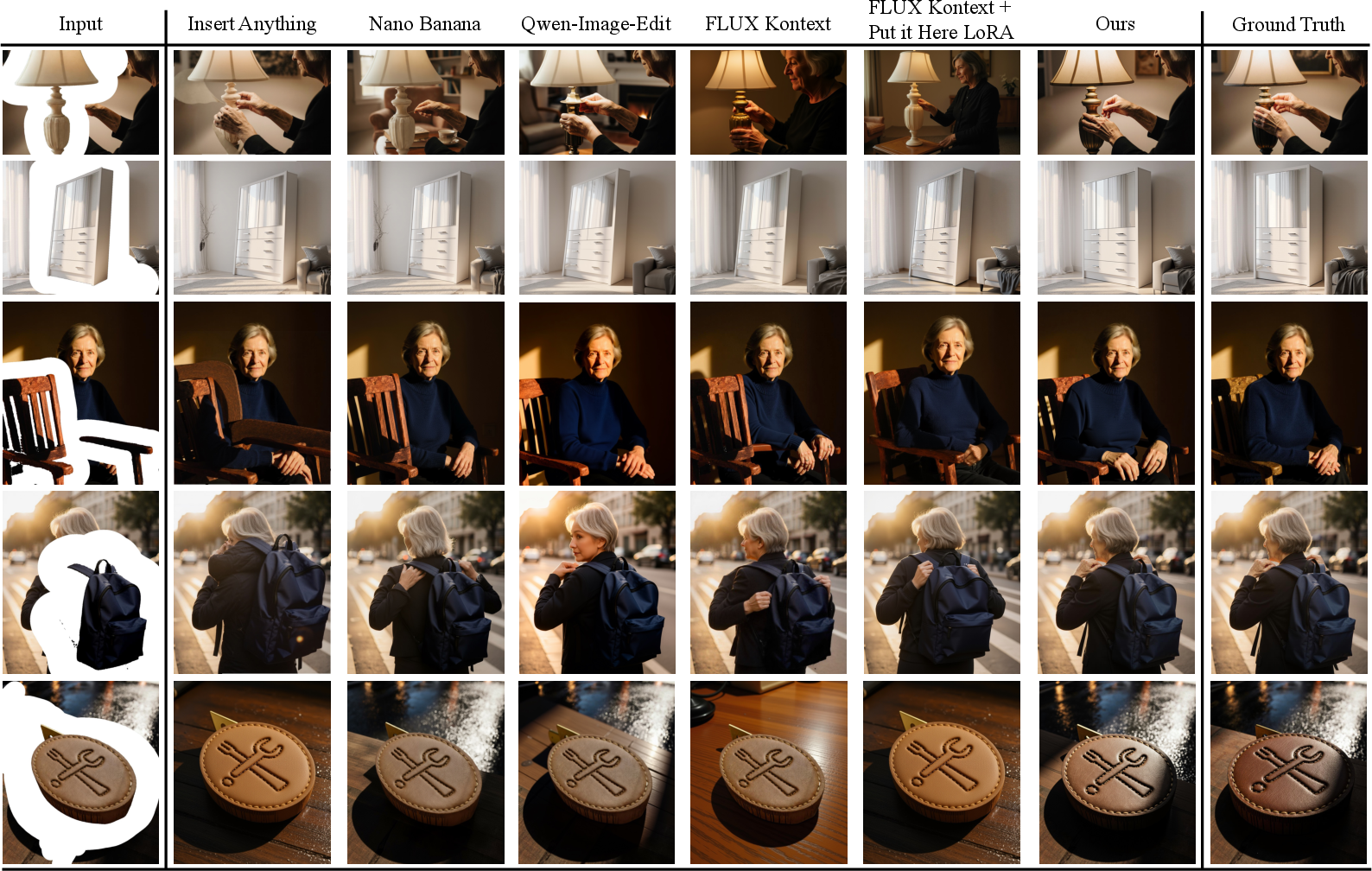
- Better object insertion and blending:
- It handled complex interactions (like a hand correctly wrapping around a backpack), fixed lighting to match the scene, and corrected perspective (so things don’t look crooked or “pasted on”).
- It beat methods like Insert Anything, Qwen-Image, FLUX Kontext, and Nano Banana in both visual examples and measurements.
- Strong control over shape and color:
- Using just edges: great shapes but sometimes imperfect colors.
- Using just color: great colors but sometimes wrong shapes.
- Using both together: best results—faithful to the target edit and highly precise.
- Precise local edits and object removal:
- The spatial layer (mask) lets you restrict changes to exactly where you paint.
- It outperformed specialized object-removal tools (like SmartEraser and OmniEraser) on a large benchmark, making removals cleaner and more realistic.
Why this matters: Users don’t have to wrestle with vague text prompts anymore. When you say “add a hat here, make it red, and tilt it like this,” the system does exactly that.
5) What this could change
MagicQuill V2 shows a practical way to combine AI creativity with human control. This could:
- Help designers, students, and hobbyists make complex edits quickly without pro-level drawing skills.
- Reduce frustration from prompt guessing—your visual cues act like “exact instructions.”
- Lead to future tools for layered editing in video, collaborative design, and even educational apps where learning by tinkering is key.
In short, MagicQuill V2 bridges the gap between “describe it with words” and “draw it exactly,” making AI image editing more predictable, precise, and fun.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each point highlights what is missing or uncertain and suggests directions future work could take.
- Reliance on synthetic training data (Flux Krea–generated scenes and Qwen-generated captions) raises domain-shift concerns; generalization to diverse, real-world photographs, non-photorealistic styles, and out-of-distribution scenes is not evaluated.
- The content-layer pipeline is built around single “primary” objects; scalability to multi-object insertion with complex inter-object interactions (contact, occlusion ordering, shadows, mutual lighting) is not studied or benchmarked.
- Object completion LoRA is trained on ~3k objects with brushstroke masks; robustness to real occlusions (self-occlusion, motion blur, translucency, fine structures like hair) and varied materials is untested.
- Foreground extraction depends on Grounded-SAM; failure modes when segmentation is imperfect (tight boundaries, transparency, reflections, thin structures) are not analyzed, nor are post-processing strategies to mitigate segmentation errors.
- Photometric harmonization uses ICLight-based relight augmentation during training, but quantitative evaluation of lighting, shadows, reflections, and contact shading fidelity is missing; no physics- or illumination-aware metrics are reported.
- Perspective augmentation corrects simple distortions, yet there is no systematic evaluation of geometric plausibility (e.g., orientation, scale, vanishing points) across varied camera models and focal lengths.
- The unified control module downsamples control cues to a fixed low resolution; impact on fine-grained alignment at high resolutions, large aspect ratios, and very small structures is not quantified.
- Attention bias design enforces strict isolation across control signals (−∞ between different cues), potentially discarding beneficial cross-cue synergies; ablations on alternative fusion strategies (soft coupling, learned gating) are absent.
- The guidance strength parameter σ is a single global scalar per cue; spatially varying or per-token control strengths, multi-scale schedules across denoising steps, and user-controllable local weighting are unexplored.
- Structural and color branches are trained for conditional generation from noise (y = ∅), then applied to editing at inference; a dedicated training/evaluation protocol for conditional editing with context images y is missing.
- Robustness to imperfect, hand-drawn, or noisy control cues (messy sketches, sparse edges, conflicting color strokes) lacks quantitative evaluation; only limited qualitative analysis of σ is provided.
- Conflict resolution between text prompts and visual cues is not formalized; there is no mechanism or user control to weight text versus each cue when instructions contradict or compete.
- Layer ordering semantics (z-depth, occlusions between multiple content layers) and their visual consequences are not defined; how the system chooses which layer “wins” in overlapping regions remains unclear.
- The spatial layer dataset is generated via self-distillation from the base model, which may propagate model biases and errors; absence of human-labeled masks or ground-truth local-edit datasets limits validity.
- Regional editing is compared to inpainting methods qualitatively; there is no comprehensive quantitative benchmark for content-aware local edits (color tweaks, texture changes, style transfer) beyond object removal.
- Object removal evaluation is limited to RORD; cross-benchmark validation (different scenes, domains, occlusion patterns) and user studies on realism and detectability of removals are not reported.
- Identity preservation for people, pets, or branded objects is asserted qualitatively; there is no evaluation with identity-specific metrics (e.g., face recognition similarity, logo consistency) or controlled identity tests.
- Failure case analysis is missing; the paper does not catalog typical breakdowns (wrong geometry, color bleeding, loss of object identity, over-adherence to poor cues) to guide future improvements.
- Interactive system performance (latency, throughput, memory footprint) and usability (learning curve, error recovery, cognitive load) are not measured via user studies or HCI metrics.
- No assessment of reproducibility and deployment: model sizes, LoRA ranks, hardware requirements, batching limits, and maximum image resolutions are unspecified; toolkit and dataset release details are absent.
- Security and ethics considerations (misuse for deceptive edits, watermarking, provenance tracking, safety filters) are not discussed; guardrails for sensitive content or identity manipulation are missing.
- Extensibility of control modalities beyond edges, masks, and color (e.g., depth, normals, material/texture maps, semantic layouts, lighting probes) is not explored or ablated.
- Handling of multi-step, iterative workflows (undo/redo consistency, determinism with seeds, reproducibility of layered edits) is unaddressed in the interface and model design.
- Temporal consistency for video (extending layered control to sequences, cross-frame alignment of cues, flicker reduction) is not investigated despite related video-editing literature.
- Benchmarking fairness and coverage: comparisons mainly include a subset of recent systems and community LoRAs; broader, standardized, and open benchmarks with human ratings for realism, control fidelity, and intent alignment are lacking.
Glossary
- Attention logits: The raw, pre-softmax scores computed in attention mechanisms that determine how much each token attends to others. "by adding a custom bias matrix, , to the attention logits:"
- Bias matrix: A matrix added to attention logits to modulate or restrict information flow between token groups. "by adding a custom bias matrix, , to the attention logits:"
- Causal Modulated Attention: An attention variant that uses a bias matrix to control and isolate the influence of different cues. "A Causal Modulated Attention mechanism applies a bias matrix to the attention logits to precisely manage the influence and isolation of each control cue."
- CLIP-I: An image–image similarity metric based on CLIP embeddings for measuring visual alignment. "CLIP-I "
- CLIP-T: A text–image similarity metric based on CLIP for measuring prompt-image alignment. "CLIP-T "
- Color layer (color map): A control layer providing explicit color guidance via a color map during generation or editing. "color layer (color map ) for exact color control."
- Conditional distribution: The probability distribution of outputs given specific conditioning inputs. "we aim to approximate the conditional distribution:"
- ControlNet: A framework that augments diffusion models with spatial conditions (e.g., edges, depth) to improve controllability. "ControlNet \cite{zhang2023controlnet}"
- Convex hull: The smallest convex region enclosing a set of points, often used to bound changed pixels. "calculate the convex hull of the changed regions."
- DINO: A learned visual feature similarity metric used to assess image alignment or identity. "DINO "
- Diffusion Transformers: Transformer-based diffusion architectures for image generation/editing that replace UNets. "With the architectural shift towards more powerful Diffusion Transformers"
- Edge map: A binary or sparse representation of image edges used as structural guidance. "a structural layer guided by an edge map"
- FID: Fréchet Inception Distance, a distribution-based metric for assessing realism of generated images. "FID "
- Flow matching: A training paradigm that matches flows between data and noise distributions for generative modeling. "Flow Matching for In-Context Image Generation and Editing in Latent Space"
- Foreground pieces: User-provided object cutouts that specify what content to synthesize or insert. "specified by one or more foreground pieces "
- Grounding SAM: A segmentation approach combining grounding with Segment Anything for object mask extraction. "we utilize Grounding SAM \cite{ren2024groundedsam} to extract the primary object's mask"
- Guidance scale: A scalar that adjusts the strength of control signals within the attention mechanism. "The term acts as a user-adjustable guidance scale"
- ICLight: A method for illumination manipulation/harmonization used to augment lighting conditions. "applying random lightmaps with ICLight \cite{zhang2025iclight}"
- Image harmonization: Adjusting inserted foregrounds to match the scene’s lighting and color for realism. "image harmonization \cite{guo2021image_harmonization,pitie2005n,cohen2006color,tao2013error,sunkavalli2010multi,zhu2015learning,tsai2017deep,dovenetharm,jiang2021ssh,Ling2021region,Hao2020ImageHW,cong2020bargainnet,Sofiiuk2021fore,chen2024deep,FreeCompose,qi2018semi}"
- Image inpainting: Filling or regenerating missing image regions, often guided by masks. "inpainting-based models like FLUX Fill \cite{flux2023}"
- Latent (latent representation): A compact, learned representation of images or modalities used within generative models. "noisy image latent ()"
- Layered image synthesis: Techniques that decompose or compose images into layers for controllable generation or editing. "Layered image synthesis encompasses both layer decomposition \cite{...} and layer composition (assembling generative elements), which our work aligns with."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank updates into model weights. "Low-Rank Adaptation (LoRA) \cite{hu2022lora} adapter"
- LPIPS: A perceptual distance metric comparing deep features to quantify visual similarity. "LPIPS "
- MLLM (Multimodal LLM): Large models that process and reason over multiple modalities (e.g., text and images). "Multimodal LLMs (MLLMs)~\cite{fu2023mgie, liu2025magicquill}"
- MMA (Multi-Modal Attention): An attention module that jointly attends across text, image, and condition tokens. "The final Query, Key, and Value for Multi-Modal Attention (MMA) can be expressed as:"
- MMDiT (Multi-Modal Diffusion Transformer): A diffusion transformer architecture handling multiple modalities via shared attention. "In the Multi-Modal Diffusion Transformer (MMDiT) \cite{flux2023, batifol2025kontext}"
- Object removal: Erasing objects from images while plausibly restoring the background. "including object removal."
- Perspective augmentation: Data augmentation that applies perspective transforms to simulate viewpoint changes. "perspective augmentation applies a random perspective transformation"
- Photometric augmentation: Modifying lighting or color conditions to improve robustness and harmonization. "we perform photometric augmentation by applying random lightmaps"
- Pixel-wise difference: Computing differences at each pixel to detect changes between images. "we compute the pixel-wise difference between the source and edited images"
- Positional encoding: Encodings that inject spatial coordinate information into token representations. "the positional encoding for a resized patch at grid is mapped to its original high-resolution coordinates"
- PSNR: Peak Signal-to-Noise Ratio, a distortion-based metric for image quality. "PSNR "
- QKV (Query–Key–Value): The triplet of projections used in attention to compute affinities and aggregates. "the Query-Key-Value (QKV) transformation for image-related branches is defined as:"
- Rectified-flow objective: A training loss that learns a vector field to transport noise to data in rectified flow models. "optimizing the rectified-flow objective"
- Resolution augmentation: Randomly altering input resolution to simulate varying input quality. "resolution augmentation involves randomly downsampling and resizing the object."
- SAM (Segment Anything Model): A general-purpose segmentation model enabling prompt-based object masks. "SAM \cite{kirillov2023sam}"
- Self-distillation: Generating supervision signals using a teacher/base model on unlabeled data. "we generate via self-distillation."
- Spatial layer: A control layer specifying where edits occur, typically via a mask. "spatial layer (mask ) for targeted regional editing"
- SSIM: Structural Similarity Index, a perceptual metric emphasizing structural fidelity. "SSIM "
- Structural layer: A control layer providing geometric guidance (e.g., via edges) to shape content. "a structural layer guided by an edge map"
Practical Applications
Immediate Applications
The paper’s layered composition paradigm and interactive system can be put to work right away across creative, commercial, and research workflows. Below is a concise set of deployable use cases, each with sector links, potential tools/products, and feasibility notes.
- Precise photo cleanup and object removal
- Sector: consumer photo apps, media/VFX
- Tools/products/workflows: “Smart Eraser Pro” powered by the fine-tuned spatial layer; localized edits using masks that preserve identity and context
- Assumptions/dependencies: GPU-backed inference; safety filters to prevent misuse; provenance logging recommended
- E-commerce listing enhancement and catalog composition
- Sector: retail/e-commerce
- Tools/products/workflows: “Layered Product Composer” that inserts/recolors items (e.g., shoes, bags) with edge+color layers; relight and perspective harmonization via the content pipeline
- Assumptions/dependencies: rights to foreground cues; truthful representation policies; batch-processing API integration with DAM systems
- Marketing creative A/B testing at scale
- Sector: advertising, marketing tech
- Tools/products/workflows: “Creative Variants Generator” using layer recipes (content/spatial/structural/color) to spin targeted variants while keeping layout constants
- Assumptions/dependencies: brand safety checks; prompt governance; consistent color fidelity across channels
- Fashion and apparel colorway generation
- Sector: fashion, retail
- Tools/products/workflows: “Colorway Studio” using the color layer with edge guidance to recolor garments, maintain seams and patterns; rapid seasonal refreshes
- Assumptions/dependencies: validation of color accuracy under varying lighting; minimize hallucination of fabric textures; supply-chain signoff before public release
- Interior design and real estate virtual staging
- Sector: real estate, design
- Tools/products/workflows: “Staging Assistant” for inserting furniture décor with foreground cues; relight augmentation improves photometric consistency; spatial masks to restrict edits
- Assumptions/dependencies: disclaimers for staged images; accurate perspective controls; ethics guidance to avoid misleading buyers
- Social media and creator tooling
- Sector: consumer, creator economy
- Tools/products/workflows: mobile-friendly “Layer Brushes” (Fill, Edge, Color) for memes, posts, thumbnails; SAM-powered segmentation for quick content extraction
- Assumptions/dependencies: on-device optimizations or cloud endpoints; content moderation; clear labelling of edited media
- Shot cleanup and continuity fixes for media/VFX
- Sector: film/TV/post-production
- Tools/products/workflows: localized object removal; color and structure-consistent touch-ups; drop-in foreground assets with context-aware integration
- Assumptions/dependencies: high-resolution workflows; version control; integration with NLE/compositing tools (e.g., After Effects)
- Education in visual arts and HCI
- Sector: education/academia
- Tools/products/workflows: “Layered Composition Lab” assignments to teach composition, color theory, and spatial reasoning; σ-control experiments to explore cue strength
- Assumptions/dependencies: curated, safe datasets; instructor guides; campus compute resources
- Privacy and compliance redaction
- Sector: public sector, journalism, enterprise compliance
- Tools/products/workflows: mask-driven removal/blurring of faces, license plates, sensitive objects; automated “Edit Ledger” export of layer stack for audit trails
- Assumptions/dependencies: enforce C2PA-like provenance; disclosure policies; reversible operations stored securely
- Synthetic dataset curation for computer vision
- Sector: academia/ML, robotics (simulation)
- Tools/products/workflows: “Controllable Dataset Builder” generating images with ground-truth edge/color/mask cues; occlusion-robust content integration via completion LoRA
- Assumptions/dependencies: domain-gap awareness; licensing of source assets; standardized metadata schemas for layers
- Graphic design agency templated workflows
- Sector: creative agencies
- Tools/products/workflows: reusable “Layer Packs” per brand; Visual Cue Manager for drag-and-drop asset kits; SAM panel for fast segmentation and reuse
- Assumptions/dependencies: team onboarding; style guides embedded as layer presets; versioned asset libraries
- Healthcare non-diagnostic de-identification
- Sector: healthcare operations (not clinical diagnosis)
- Tools/products/workflows: spatial-layer redaction of faces/backgrounds in patient photos for communications/training
- Assumptions/dependencies: strictly avoid diagnostic images; compliance with HIPAA/GDPR; watermarking and provenance
Long-Term Applications
These opportunities require further research, scaling, standardization, or new model capabilities. They build on the layered-control insights, unified conditioning, and interactive tooling introduced by MagicQuill V2.
- Layered video editing with temporal consistency
- Sector: media/video, social platforms
- Tools/products/workflows: per-frame masks/edges/colors with temporal tracking; σ schedules over time
- Assumptions/dependencies: video diffusion/transformers; motion-aware SAM; temporal stability metrics
- Real-time AR composition on mobile
- Sector: mobile/AR, retail try-ons, experiential marketing
- Tools/products/workflows: on-device layered cues for furniture placement, apparel previews; live relight/perspective harmonization
- Assumptions/dependencies: efficient on-device inference; sensor fusion (depth/IMU); low-latency segmentation
- 3D-aware layered generation and asset pipelines
- Sector: 3D content, gaming, CAD
- Tools/products/workflows: extend edge/color/spatial cues into geometry-aware models (NeRF/3D diffusion); asset insertion with correct lighting and occlusions
- Assumptions/dependencies: differentiable rendering; 3D priors; dataset of multi-view layer annotations
- Multi-user collaborative editing with provenance
- Sector: SaaS collaboration, enterprise design
- Tools/products/workflows: shared “Layer Intent Graphs” with role-based locks; cryptographic signing of layer operations
- Assumptions/dependencies: concurrency control; secure audit trails; integration with C2PA and DAM systems
- A “Layered Intent Format” (LIF) standard
- Sector: standards/policy/industry consortia
- Tools/products/workflows: interoperable schema for content/spatial/structural/color cues; portable provenance and σ settings
- Assumptions/dependencies: cross-vendor adoption; governance frameworks; reference validators
- Compliance pipelines for synthetic media governance
- Sector: platforms, regulators, newsrooms
- Tools/products/workflows: mandatory layer-stack export; visible/invisible watermarks; automated “edit-to-disclosure” mapping
- Assumptions/dependencies: policy mandates; user education; provenance resilient to re-encoding and scaling
- Retail virtual try-on with physics and fabric realism
- Sector: fashion tech
- Tools/products/workflows: structured edge/color cues augmented with fabric simulation; accurate drape and shadowing
- Assumptions/dependencies: garment deformation models; body/pose estimation; calibration pipelines
- Robotics and AV simulation with controllable occlusions
- Sector: robotics/autonomous systems
- Tools/products/workflows: generate scenes with precise occlusion/illumination variations via layered cues; stress-test perception stacks
- Assumptions/dependencies: high-fidelity synthetic-to-real transfer; scenario libraries; evaluation protocols
- Accessibility-first co-creation interfaces
- Sector: accessibility/UX
- Tools/products/workflows: voice or eye-tracking mapped to layer operations; adaptive σ tuning for noisy cues
- Assumptions/dependencies: multimodal UX research; robust error recovery; inclusive design standards
- Cross-modal “smart pens” and MLLM co-pilots
- Sector: creative software, education
- Tools/products/workflows: attribute-specific instruments that convert rough sketches or voice descriptions into structured layers; intent refinement via MLLMs
- Assumptions/dependencies: reliable intent inference; guardrails; data privacy for reference images
- Forensic “edit trace” and chain-of-custody
- Sector: legal/e-discovery, cybersecurity
- Tools/products/workflows: tamper-evident records of layer operations; verifiable attestation of edits over time
- Assumptions/dependencies: cryptographic signing; platform cooperation; standards for admissibility in court
- Enterprise-grade DAM and CI/CD for creatives
- Sector: martech, product design
- Tools/products/workflows: APIs to run layered edits in pipelines; automated QA checks for geometry/color compliance
- Assumptions/dependencies: scalable inference; quality benchmarks; governance policies
Notes on Feasibility and Dependencies
- Technical dependencies: FLUX Kontext backbone or equivalent diffusion transformer; LoRA adapters; SAM-based segmentation; GPU/TPU acceleration; optional ICLight for relighting.
- Operational assumptions: legitimate rights to foreground assets; brand/compliance approvals; provenance and disclosure for edited content; moderation to mitigate misuse.
- Generalization constraints: current results are strongest in photorealistic domains; specialized verticals (e.g., medical imaging) require domain-tuned training and strict policies.
- UX considerations: user education on layer concepts and σ control; accessible interfaces; workflows that log and export layer stacks for audit and collaboration.
Collections
Sign up for free to add this paper to one or more collections.