SplatSuRe: Selective Super-Resolution for Multi-view Consistent 3D Gaussian Splatting
Abstract: 3D Gaussian Splatting (3DGS) enables high-quality novel view synthesis, motivating interest in generating higher-resolution renders than those available during training. A natural strategy is to apply super-resolution (SR) to low-resolution (LR) input views, but independently enhancing each image introduces multi-view inconsistencies, leading to blurry renders. Prior methods attempt to mitigate these inconsistencies through learned neural components, temporally consistent video priors, or joint optimization on LR and SR views, but all uniformly apply SR across every image. In contrast, our key insight is that close-up LR views may contain high-frequency information for regions also captured in more distant views, and that we can use the camera pose relative to scene geometry to inform where to add SR content. Building from this insight, we propose SplatSuRe, a method that selectively applies SR content only in undersampled regions lacking high-frequency supervision, yielding sharper and more consistent results. Across Tanks & Temples, Deep Blending and Mip-NeRF 360, our approach surpasses baselines in both fidelity and perceptual quality. Notably, our gains are most significant in localized foreground regions where higher detail is desired.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
Imagine building a 3D scene from lots of photos taken around an object. A popular, fast method to do this is called 3D Gaussian Splatting. It can make realistic new views, but if the training photos are low resolution (blurry or small), the final 3D scene looks soft and lacks fine details when you try to render high‑resolution images.
This paper introduces SplatSuRe, a way to make sharper, high‑resolution renders from low‑resolution photos. The key idea: only add “super‑resolution” (a smart upscaling that guesses fine details) in the places where the 3D model truly needs it, instead of everywhere. That keeps the scene consistent from all angles and avoids weird, mismatched details.
What question are they trying to answer?
- How can we get crisp, high‑resolution 3D renders when we only have low‑resolution training photos?
- How do we use super‑resolution without causing inconsistencies (like textures that don’t match) across different camera views?
- Can we figure out exactly where extra detail is needed and add it only there?
How did they do it? (Explained simply)
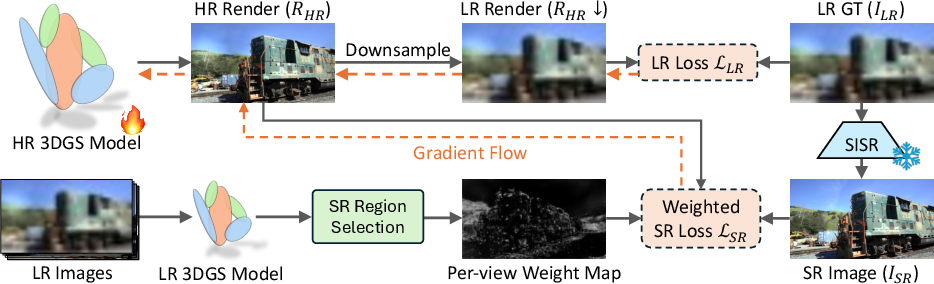
Think of the 3D scene as being painted with many tiny, soft “glow balls” (Gaussians). Each one holds color and size and gets projected into each camera view. Some parts of the scene are seen up close in some photos (so they’re well detailed), while other parts are far away in all photos (so they’re fuzzy).
SplatSuRe works in three main steps:
- Step 1: Build a rough 3D model from low‑res photos
- They first train the usual 3D Gaussian Splatting model using low‑resolution images. This gives stable geometry (where things are in 3D).
- Step 2: Score how well each spot has been “seen”
- For every tiny 3D “glow ball,” they ask: across all training photos, was it ever seen up close (small on the screen means far; large on the screen means close)?
- They compute a “fidelity score” for each Gaussian that basically answers: “Has this spot ever been seen with high detail in any view?”
- High score = some photo saw it up close → no need to invent extra detail here.
- Low score = never seen up close → probably needs extra detail.
- Step 3: Create per‑image “where to add detail” maps and train smartly
- For each training photo, they render a “weight map” (a grayscale mask) that is bright where super‑resolution should be used and dark where it shouldn’t.
- During training of a high‑resolution model, they use two signals:
- Low‑res supervision (to keep everything consistent overall).
- Super‑resolution supervision (from a separate SR tool like StableSR), but only in the bright areas indicated by the weight map.
- In short: the model learns from real low‑res images everywhere, and from super‑resolution only where detail is missing.
Why this helps:
- Super‑resolution on every image independently can make small, conflicting textures that don’t line up from different angles.
- By selectively applying it only where no close‑up view exists, the model gets sharper details without introducing mismatches.
What did they find?
Across several datasets of real scenes (like Tanks and Temples, Deep Blending, and Mip‑NeRF 360), SplatSuRe:
- Produces sharper, clearer details than previous methods that either:
- Don’t use super‑resolution, or
- Apply super‑resolution everywhere.
- Keeps textures consistent across different viewpoints, reducing blur and weird artifacts.
- Works especially well in localized foreground or undersampled areas—places that weren’t seen up close in any photo.
- Beats strong baselines on many quality metrics that measure both accuracy and perceptual realism.
One caveat: in scenes that are already very well covered by many views (like smooth camera paths with many photos), there’s less benefit from super‑resolution, and methods focused on anti‑aliasing can perform very well too.
Why does this matter?
This approach helps make high‑quality 3D models from cheaper, smaller, or blurrier images. That’s useful for:
- Faster scans of real spaces for games, movies, AR/VR, and digital twins.
- Making detailed 3D assets without needing high‑end cameras.
- Combining with other tools (like diffusion models or 3D upscalers) to further improve quality while keeping views consistent.
Final takeaway
SplatSuRe is like a smart magnifying glass for 3D reconstruction: it only zooms in where the scene lacks detail and leaves well‑seen areas alone. By using the geometry of the scene and the positions of the cameras, it knows where extra detail helps—and where it would just cause trouble. The result is sharper, more reliable 3D renders from low‑resolution inputs, without extra heavy training or complicated new networks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies unresolved issues and concrete opportunities for future work raised by the paper:
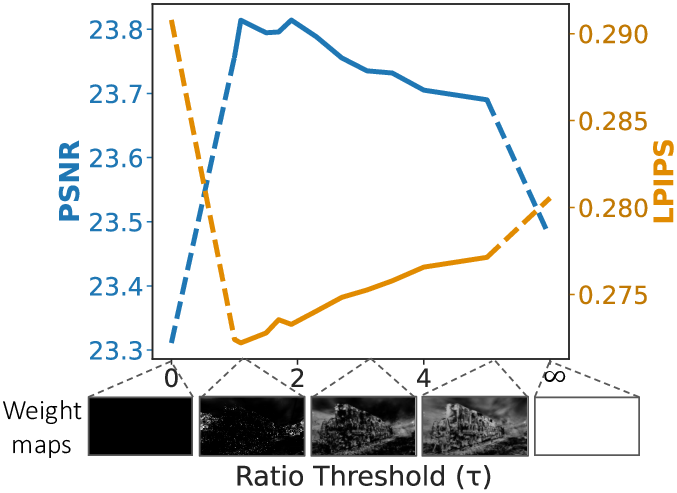
- Sensitivity to hyperparameters and lack of auto-tuning
- No automatic or learnable selection of the ratio threshold τ, smoothness k, and loss weights (λ, γ); performance varies by scene and sampling density. How to infer τ (and related weights) per-scene or per-region adaptively or via meta-learning?
- Static, one-shot weight maps
- SR weight maps are computed from an LR 3DGS trained once and appear fixed thereafter. Do iterative or online updates of fidelity scores and weight maps during HR training improve results, especially as densification changes geometry and visibility?
- Heuristic fidelity metric
- The fidelity score relies solely on the max/min screen-space radius ratio. It ignores texture content, edge strength, blur, noise, exposure variation, and view-dependent appearance. Can content- and uncertainty-aware metrics (e.g., local frequency/gradient energy, SISR confidence, photometric consistency) yield better SR targeting?
- Robustness to pose/geometry errors
- The method assumes accurate SfM poses and reliable LR 3DGS geometry; two scenes were excluded due to COLMAP failure. How robust is SplatSuRe to calibration noise, pose drift, imperfect depth/occlusion, or sparse/erroneous correspondences, and can it be made resilient?
- Sparse-view and low-visibility cases
- Gaussians visible in fewer than three views are forced to score 0 (encouraging SR), which risks hallucinations in poorly constrained regions. Can visibility-aware regularization or priors prevent over-hallucination in low-coverage areas?
- No explicit 3D consistency constraint on SR content
- Selective weighting mitigates, but does not enforce, cross-view consistency of SR hallucinations. How to integrate multi-view SR priors (e.g., video SR, 3D-consistent diffusion, multi-view SISR) or cycle-consistency losses to explicitly constrain consistency?
- Single upsampling level and no multi-scale scheduling
- The approach modulates SR strength at a single scale. Would multi-scale fidelity maps and progressive scale schedules (e.g., 1.5×→2×→4×) improve stability and detail while controlling inconsistency?
- Limited analysis of densification interaction
- Densification changes Gaussian counts, sizes, and anisotropy over training. What is the effect on fidelity scoring, the set M(t), and the stability of SR weighting as Gaussians split/clone?
- Inadequate treatment of anisotropy and projected area
- The screen-space “radius” uses 3√(max eigenvalue) as a proxy. Would using full projected area/shape (e.g., ellipse area, orientation) yield a more faithful sampling measure, particularly for highly anisotropic Gaussians?
- Occlusion and parallax handling
- The selection uses max-radius view and rendered scores but does not explicitly model parallax-induced edge shifts or per-pixel occlusion changes across views. Can per-pixel reprojection checks or visibility-aware consistency further reduce boundary artifacts?
- SR model uncertainty and domain shift
- Weighting does not use SISR confidence/uncertainty or detect when SR is off-domain (e.g., unusual textures, specularities). Can SR uncertainty, ensemble variance, or detect-and-downweight strategies improve reliability?
- Limited evaluation on extremely well-sampled vs under-sampled regimes
- Mip-NeRF 360 results suggest SR is less beneficial (even harmful) when sampling is dense. Can the method auto-detect such regimes and smoothly deactivate SR, or blend with Mip-Splatting filters?
- No direct metric for 3D multi-view consistency
- Evaluation relies on 2D metrics (PSNR/SSIM, LPIPS, FID/CMMD, MUSIQ/NIQE). Introduce explicit 3D consistency metrics (e.g., cross-view reprojection error, re-render consistency under novel baselines, patch-level cycle-consistency) to quantify the core claim.
- No user study or task-based evaluation
- Perceptual metrics can under- or over-penalize SR methods. Do human evaluations or task-driven tests (e.g., feature matching across views) corroborate perceived improvements and consistency?
- Computational and memory overhead unreported
- Computing per-Gaussian radii across all views and rendering weight maps adds cost (O(N×T)). What are the runtime/memory implications, scalability to larger scenes, and trade-offs with denser training sets?
- Generalization to dynamic scenes and transient effects
- The method presumes static scenes. How to extend selective SR to dynamic or transient scenarios where cross-view supervision conflicts are inherent?
- Handling view-dependent effects and reflectance
- Fidelity scoring assumes transferable high-frequency supervision across views, which may not hold for specular or non-Lambertian regions. Can reflectance-aware selection or BRDF-conditioned weighting reduce spurious detail transfer?
- Failure modes with blur/noise/compression in “close” views
- The assumption that closer LR views contain higher-frequency cues fails with motion blur, defocus, or heavy compression. Can image-quality-aware filtering of supervising views mitigate incorrect “high-fidelity” signals?
- Integration with diffusion priors left unexplored
- The approach is orthogonal to diffusion-based 3D consistency methods, but no concrete integration is demonstrated. How to couple geometry-aware selection with 3D-consistent diffusion (e.g., as a selective prior/loss) to further improve consistency?
- Baseline breadth and combinations
- No comparisons with combinations like Mip-Splatting + selective SR, or SRGS augmented with geometry-aware weighting. Do hybrid pipelines outperform individual components?
- Loss design and parameter-level targeting
- The SR loss applies on rendered images; it does not differentially target Gaussian parameters (opacity, SH coefficients, scales). Would parameter-specific weighting or decoupled geometry vs appearance optimization yield better stability?
- Initialization and training protocol clarity
- It is unclear whether the HR 3DGS is initialized from the LR model or retrained from scratch using LR-derived weight maps. Do different initialization strategies affect convergence, consistency, and final quality?
- Limited exploration of extreme upscaling
- Only brief mention of 8× SR (appendix). What are the limits of selective SR at higher scales, and can progressive scaling/regularization make 8×–16× viable?
- Scene content priors
- Gains are “most significant in localized foreground regions,” but the method is not content-aware. Can semantic or depth priors guide where SR is more impactful (e.g., text/signage, human-made edges) without harming consistency?
- Open-source reproducibility details
- Precise implementation details (normalization of Wt, recomputation frequency, data structures for M(t), cost) are not fully specified. Providing these would aid reproducibility and facilitate follow-up research.
Practical Applications
Immediate Applications
These applications can be deployed today using existing 3DGS codebases (e.g., 3DGS/Mip‑Splatting, Nerfstudio), off‑the‑shelf SfM (e.g., COLMAP), and pretrained SISR models (e.g., StableSR, SwinIR).
- Media, VFX, and Gaming (content production)
- Use case: Turn low‑resolution multi‑view captures into sharp, multi‑view‑consistent 3D assets for games, films, and VR/AR without upgrading cameras.
- Tools/workflows: LR capture → SfM (camera poses) → train LR 3DGS → compute SplatSuRe weight maps → HR 3DGS training with selective SR → export splats/mesh bake → integrate into Unreal/Unity.
- Assumptions/dependencies: Static scenes; reliable camera calibration; GPU time for two‑stage training; SR model choice matters (generative SR may hallucinate textures; SplatSuRe mitigates but does not eliminate this).
- Photogrammetry & Digital Twins for AEC (Architecture, Engineering, Construction)
- Use case: Produce higher‑resolution site models from smartphone/drone imagery with multi‑view consistency for as‑built documentation, progress tracking, and clash detection.
- Tools/workflows: Integrate SplatSuRe as a plug‑in to photogrammetry pipelines; bake high‑frequency textures into meshes; deliver HR renders to stakeholders.
- Assumptions/dependencies: Adequate viewpoint coverage and overlap; lighting variations should be handled (or pre‑normalized); benefit larger in scenes with varied camera‑object distances.
- E‑commerce and Product Digitization
- Use case: High‑fidelity 360° product visuals from low‑cost multi‑view rigs without inconsistent SR artifacts (e.g., fine print, fabrics, logos).
- Tools/products: Turntable multi‑view capture → SplatSuRe HR 3DGS → consistent novel views/interactive viewers.
- Assumptions/dependencies: Good pose estimation; small objects with close‑up views benefit most.
- Cultural Heritage and Archival Reconstruction
- Use case: Reconstruct and upscale consistent 3D models from archival LR photos or museum captures while preserving geometry and suppressing SR hallucinations across views.
- Tools/workflows: Batch processing with SplatSuRe; export for web‑based viewers and preservation archives.
- Assumptions/dependencies: Sufficient multi‑view redundancy; domain shift of SR model to historic imagery may require careful model choice.
- Drone‑based Inspection (Energy, Utilities, Infrastructure)
- Use case: Generate crisp, consistent 3D models of towers, solar arrays, wind turbines, bridges from LR drone passes to support defect triage and measurement.
- Tools/workflows: On‑prem/cloud pipeline that ingests drone imagery; SplatSuRe for selective SR; produce HR orthos, renders, or splats for analysts.
- Assumptions/dependencies: Static assets during capture; pose accuracy; SR generalization to textures like concrete, metals; results should be clearly labeled as enhanced for compliance.
- Insurance and Remote Claims Assessment
- Use case: Produce higher‑resolution 3D reconstructions of damaged assets from consumer‑grade photo sets while keeping cross‑view texture consistency for adjuster review.
- Tools/workflows: Self‑serve upload portal → automated SplatSuRe pipeline → downloadable HR models/renders.
- Assumptions/dependencies: Provenance and disclosures on generative SR; accuracy-sensitive measurements should be validated.
- Robotics and Mapping (offline model building)
- Use case: Build sharper environment models from LR multi‑view sequences for simulation, scene understanding, and planning (e.g., warehouse digital twins).
- Tools/workflows: Use SplatSuRe to produce HR‑consistent 3DGS from robot camera logs; render proxy views for planners/simulators.
- Assumptions/dependencies: Works best on near‑static scenes; for online SLAM this is an offline post‑processing step; requires camera intrinsics/extrinsics.
- Education and Research
- Use case: Generate high‑quality HR renderings from LR datasets for courses and benchmarks; baseline for research on multi‑view consistency and geometry‑aware SR.
- Tools/workflows: Add SplatSuRe to Nerfstudio or lab pipelines; expose per‑Gaussian fidelity maps for analysis/teaching.
- Assumptions/dependencies: Students need GPU access; simple hyperparameter tuning (e.g., threshold τ) per scene.
- Developer Tooling and SDKs
- Use case: Provide a “Selective SR” module/API for 3DGS frameworks that outputs per‑view weight maps and runs HR training with LR+weighted SR losses.
- Tools/products: CLI and Python API; plug‑ins for Nerfstudio, Blender add‑ons, Unreal importers.
- Assumptions/dependencies: Maintained bindings to 3DGS codebases; versioned support for multiple SISR backbones.
- Consumer/Prosumer Smartphone Scans (daily life)
- Use case: Hobbyists create crisper 3D scans of rooms and objects from phone photos for sharing, 3D printing, or VR tours.
- Tools/workflows: Mobile app that uploads photos to a cloud SplatSuRe service; returns HR renders and interactive viewers.
- Assumptions/dependencies: Good coverage and static scenes; compute done in cloud; clear labeling of generative enhancement.
Long‑Term Applications
These require further research, integration, at‑scale engineering, or validation (e.g., dynamic scenes, regulated sectors, real‑time constraints).
- Active View Planning and Capture Guidance (Robotics, Drones, Film)
- Use case: Use the per‑Gaussian fidelity score to guide camera/drone movement and trigger captures in undersampled regions, reducing the need for SR or improving SR placement.
- Tools/products: Live heatmaps on capture UIs; autonomous drone planners that close fidelity gaps.
- Dependencies: Online estimation of fidelity during capture; tight SfM/SLAM integration; latency constraints.
- Real‑time/On‑device Selective SR for AR/Telepresence
- Use case: Incrementally build and refine HR models while streaming; apply SR only where geometry indicates need.
- Tools/products: Edge accelerators; mixed CPU/GPU streaming pipelines; progressive splat updates.
- Dependencies: Efficient, low‑latency SISR and 3DGS training/inference; dynamic scene handling.
- Dynamic Scenes and 3D Video Super‑Resolution
- Use case: Extend selective SR to time‑varying radiance fields or splats (moving objects/lighting), preserving temporal and multi‑view consistency.
- Tools/products: Temporal weight maps; joint optical flow and geometry‑aware SR.
- Dependencies: Robust pose and motion estimation; new losses for temporal coherence; compute scale‑up.
- Integration with 2D/3D Diffusion Priors (Content creation, Digital Humans)
- Use case: Apply diffusion‑based priors only in geometry‑flagged undersampled regions for sharper yet consistent detail synthesis.
- Tools/products: SplatSuRe as a gating module for diffusion‑guided 3D pipelines; controllable detail injection.
- Dependencies: Stable 3D‑consistent diffusion backbones; safeguards against semantic drift.
- Provenance, Watermarking, and Policy for Generated Detail (Forensics, Public Sector)
- Use case: Export weight maps and SR influence metadata to flag which pixels/regions received generative detail; aid auditability and trust.
- Tools/products: Metadata standards; viewer overlays indicating “SR‑assisted” areas; compliance dashboards.
- Dependencies: Industry standards for 3D generative provenance; institutional policies for admissibility and disclosure.
- Healthcare and Medical Imaging Reconstruction
- Use case: Geometry‑aware SR for endoscopic or intraoperative multi‑view 3D reconstruction where some views are close‑up and others are distant; reduce inconsistent hallucinations.
- Tools/products: Research prototypes for surgical training simulators or pre‑operative planning.
- Dependencies: Rigorous clinical validation; domain‑adapted SR models; bias/safety assessments; regulatory approval.
- Autonomous Vehicles and HD Mapping
- Use case: Build HR 3D reconstructions from LR multi‑camera rigs for HD map updates in low‑bandwidth settings, focusing SR on undersampled regions (e.g., tall signs, overpasses).
- Tools/products: Fleet pipelines with selective SR gating; map QA systems.
- Dependencies: Robust real‑world generalization; large‑scale automation; safety and accuracy guarantees.
- Cross‑modal Fidelity Estimation (LiDAR/Depth + RGB)
- Use case: Fuse depth/LiDAR to refine per‑Gaussian fidelity scores and weight maps, improving SR targeting and reducing ambiguity in textureless regions.
- Tools/products: Multi‑sensor capture rigs; calibration toolchains.
- Dependencies: Precise multi‑sensor calibration; synchronization; new fusion algorithms.
- Automatic Hyperparameter/Threshold Selection and Uncertainty‑aware SR
- Use case: Learn scene‑adaptive τ and weighting using validation metrics or uncertainty models to balance sharpness and consistency.
- Tools/products: Auto‑tuning modules; scene diagnosis reports.
- Dependencies: Proxy metrics for consistency; generalized calibration across domains.
- Cloud‑scale Services and Cost‑optimized Capture Policies
- Use case: Large‑scale selective SR services that reduce capture/storage costs (LR data in, HR models out) with SLAs for quality; procurement guidance for sensor specs based on SplatSuRe performance.
- Tools/products: Multi‑tenant job schedulers; quality dashboards; TCO calculators.
- Dependencies: Robust orchestration; dataset governance; clear quality/provenance policies.
Notes on Feasibility and Deployment Constraints
- Core dependencies: multi‑view LR images with accurate camera poses (SfM/SLAM), largely static scenes, and a pretrained SR backbone. The method requires training an LR 3DGS to compute fidelity, then training an HR 3DGS with selective SR—plan for added compute time.
- Domain sensitivity: SR model choice affects realism vs. fidelity trade‑offs (e.g., StableSR vs. SwinIR). Scenes with dense, uniform coverage benefit less; highly varied camera–object distances benefit most.
- Risk management: In regulated or measurement‑critical settings, disclose SR usage and avoid over‑reliance on generative details; consider exporting and inspecting weight maps for QA.
Glossary
- 2D covariance matrix: The matrix describing the Gaussian’s spread and orientation after projection onto the image plane. "The 2D covariance matrix is given by the EWA Splatting approximation~\cite{zwicker2002ewa}."
- 3D Gaussian Splatting (3DGS): A scene representation that models surfaces with 3D Gaussian primitives rendered via splatting for real-time novel view synthesis. "3D Gaussian Splatting (3DGS) enables high-quality novel view synthesis"
- Alpha blending: A compositing technique that combines overlapping contributions using opacity, common in volumetric rendering. "Volumetric rendering with alpha blending is used to splat the Gaussians onto the image plane"
- Aliasing artifacts: Visual distortions caused by undersampling high-frequency content, especially when rendering at higher resolutions. "models trained with low resolution (LR) images suffer from aliasing artifacts when rendered at higher resolutions"
- Anisotropic Gaussians: Gaussian primitives whose spread varies by direction, allowing elliptical footprints rather than circular. "representing scenes as an explicit set of anistropic Gaussians optimized through differentiable splatting."
- CMMD: A distributional perceptual metric that compares feature distributions between generated and real images. "we include FID~\cite{heusel2017gans}, CMMD~\cite{jayasumana2024rethinkingfidbetterevaluation}, and DreamSim~\cite{fu2023dreamsim}"
- COLMAP: A Structure-from-Motion and multi-view stereo toolkit used to estimate camera poses and reconstruct sparse point clouds. "two are excluded because COLMAP fails."
- D-SSIM: A differentiable form of the Structural Similarity metric used as a loss for optimization. "a weighted sum of and $\mathcal{L}_{\text{D-SSIM}$ losses is used to optimize the Gaussian parameters"
- Densification pipeline: The process of splitting and cloning Gaussians during training to increase representational fidelity where needed. "We retain the standard 3DGS rendering and densification pipeline, modifying only the supervision losses for our method."
- Differentiable rasterization: A rendering process that produces gradients with respect to scene parameters, enabling end-to-end optimization. "representing scenes as sets of anisotropic Gaussians optimized through differentiable rasterization."
- Diffusion priors: Knowledge encoded in pretrained diffusion models used to guide or enhance image generation and super-resolution. "Diffusion priors have also been applied as post-processing to enhance renders from 3DGS models"
- DreamSim: A perceptual similarity metric that measures semantic agreement in pretrained embedding spaces. "we include FID~\cite{heusel2017gans}, CMMD~\cite{jayasumana2024rethinkingfidbetterevaluation}, and DreamSim~\cite{fu2023dreamsim}"
- Eigenvalues: Scalars indicating the principal variances of the projected Gaussian footprint, derived from the covariance matrix. "where and are the eigenvalues of the Gaussian's 2D covariance matrix"
- EWA Splatting: Elliptical Weighted Average splatting; an approximation used to compute the 2D Gaussian footprint during rendering. "The 2D covariance matrix is given by the EWA Splatting approximation~\cite{zwicker2002ewa}."
- FID: Fréchet Inception Distance; a metric comparing feature distributions of generated and real images to assess realism. "we include FID~\cite{heusel2017gans}, CMMD~\cite{jayasumana2024rethinkingfidbetterevaluation}, and DreamSim~\cite{fu2023dreamsim}"
- Gaussian fidelity score: A per-Gaussian measure of how well it is sampled across views, used to decide where to apply SR. "We first compute a Gaussian fidelity score that measures how well each Gaussian is sampled across training views"
- Inconsistency modeling module: A learned component designed to estimate and mitigate cross-view inconsistencies in SR outputs. "S2Gaussian~\cite{wan2025s2gaussian} focuses on sparse view reconstruction and proposes an inconsistency modeling module trained per-scene to reduce inconsistencies in SR images."
- LPIPS: Learned Perceptual Image Patch Similarity; a reference-based perceptual metric capturing feature-level differences. "For reference-based assessment, we report SSIM, PSNR, and LPIPS~\cite{zhang2018perceptual}"
- Low-pass Gaussian filter: A blur filter used to prevent aliasing by ensuring a minimum Gaussian footprint size. "3DGS dilates each Gaussian by convolving it with a fixed low-pass Gaussian filter to prevent aliasing and ensure a minimal rendering size"
- Mip-NeRF 360: A dataset of real-world indoor and outdoor scenes with 360° captures used for evaluating novel view synthesis methods. "Across Tanks {paper_content} Temples, Deep Blending and Mip-NeRF 360, our approach surpasses baselines in both fidelity and perceptual quality."
- Mip-Splatting: An alias-free variant of Gaussian splatting that applies multi-scale filtering to preserve radiance across resolutions. "Mip-Splatting~\cite{Yu2024MipSplatting} mitigates this aliasing by applying scale-adaptive 3D and 2D filtering while preserving radiance energy across resolutions"
- Multi-view consistency: The property that generated details align across different camera viewpoints without contradictions. "delivers greater detail and multi-view consistency than prior approaches"
- MUSIQ: A no-reference image quality metric assessing perceptual realism and naturalness. "we evaluate no-reference perceptual quality using MUSIQ~\cite{ke2021musiqmultiscaleimagequality} and NIQE~\cite{6353522}"
- Neural radiance fields (NeRF): A volumetric scene representation learned from images that models view-dependent color and density. "Super-resolution (SR) has long been applied to neural radiance fields~\cite{mildenhall2021nerf} to enhance novel view synthesis quality"
- NIQE: Natural Image Quality Evaluator; a no-reference metric estimating image naturalness. "we evaluate no-reference perceptual quality using MUSIQ~\cite{ke2021musiqmultiscaleimagequality} and NIQE~\cite{6353522}"
- Opacity: The scalar transparency parameter of a Gaussian controlling how much it contributes to the pixel color. "scalar opacity "
- PSNR: Peak Signal-to-Noise Ratio; a reference-based metric measuring pixel-level reconstruction fidelity. "For reference-based assessment, we report SSIM, PSNR, and LPIPS~\cite{zhang2018perceptual}"
- Radiance energy: The scene’s emitted light energy that methods aim to preserve across scales/resolutions. "preserving radiance energy across resolutions"
- Scale-adaptive filtering: Filtering that adapts to the footprint scale to reduce aliasing at different resolutions. "mitigates this aliasing by applying scale-adaptive 3D and 2D filtering"
- Screen-space radius: The size of a Gaussian’s projected footprint in pixels, used to assess sampling frequency. "the screen-space radius, measured in pixel units, of Gaussian is:"
- Sigmoid function: A smooth, S-shaped function mapping real values into [0,1], used to convert ratios to weights. "where is the sigmoid function"
- Single-image super-resolution (SISR): SR performed independently on each image, without multi-view coupling. "the images produced by the frozen single-image super-resolution (SISR) model are spatially weighted by these maps"
- Spherical harmonic coefficients: Coefficients for representing view-dependent color via spherical harmonic basis functions. "view-dependent color , represented as a base color with spherical harmonic coefficients."
- Sparse view reconstruction: Reconstructing a scene from few input views, which increases ambiguity and inconsistency risks. "S2Gaussian~\cite{wan2025s2gaussian} focuses on sparse view reconstruction"
- Structure from Motion (SfM): A pipeline that estimates camera parameters and a sparse 3D point cloud from multi-view images. "The model is initialized using Structure from Motion (SfM) on the training views"
- Super-resolution (SR): Enhancing image resolution and details, often via generative models, to supply high-frequency supervision. "A natural strategy is to apply super-resolution (SR) to low-resolution (LR) input views"
- Transmittance: The accumulated transparency along a ray that determines how much background contributes behind foreground Gaussians. "Gaussians are sorted in depth order before splatting to ensure that transmittance is computed correctly."
- Video super-resolution: SR that leverages temporal consistency across frames to produce coherent, sharp sequences. "or video super-resolution~\cite{Shen2024SuperGaussian}"
- View-dependent color: Color that varies with viewing direction, often modeled via spherical harmonics in 3DGS. "view-dependent color , represented as a base color with spherical harmonic coefficients."
- Volumetric rendering: Rendering that accumulates color and opacity along rays through a volume to form pixel intensities. "Volumetric rendering with alpha blending is used to splat the Gaussians onto the image plane"
- Weight maps: Spatial masks that modulate SR supervision per pixel to focus on undersampled regions. "render per-view weight maps that indicate where SR is needed."
Collections
Sign up for free to add this paper to one or more collections.