Envision: Benchmarking Unified Understanding & Generation for Causal World Process Insights
Abstract: Current multimodal models aim to transcend the limitations of single-modality representations by unifying understanding and generation, often using text-to-image (T2I) tasks to calibrate semantic consistency. However, their reliance on static, single-image generation in training and evaluation leads to overfitting to static pattern matching and semantic fusion, while fundamentally hindering their ability to model dynamic processes that unfold over time. To address these constraints, we propose Envision-a causal event progression benchmark for chained text-to-multi-image generation. Grounded in world knowledge and structured by spatiotemporal causality, it reorganizes existing evaluation dimensions and includes 1,000 four-stage prompts spanning six scientific and humanities domains. To transition evaluation from single images to sequential frames and assess whether models truly internalize world knowledge while adhering to causal-temporal constraints, we introduce Envision-Score, a holistic metric integrating multi-dimensional consistency, physicality, and aesthetics. Comprehensive evaluation of 15 models (10 specialized T2I models, 5 unified models) uncovers: specialized T2I models demonstrate proficiency in aesthetic rendering yet lack intrinsic world knowledge. Unified multimodal models bridge this gap, consistently outperforming specialized counterparts in causal narrative coherence. However, even these unified architectures remain subordinate to closed-source models and struggle to overcome the core challenge of spatiotemporal consistency. This demonstrates that a focus on causally-isolated single images impedes multi-frame reasoning and generation, promoting static pattern matching over dynamic world modeling-ultimately limiting world knowledge internalization, generation.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Envision, a new way to test AI image models. Instead of judging them on single pictures, Envision checks whether an AI can create a short sequence of four images that tell a cause-and-effect story over time—like a 4-panel comic strip. The goal is to see if models truly understand “how the world works,” not just how to draw a pretty picture.
What questions did the paper ask?
The paper asks simple but important questions:
- Can AI models go beyond making one good-looking image and instead create a sequence that makes logical sense over time?
- Do they understand basic world knowledge and physics well enough to show events that unfold correctly?
- Which kinds of models do best at telling these visual stories: traditional text-to-image models, or newer “unified” models that understand and generate images and text together?
How did they test it?
The researchers built a benchmark called Envision and used it to evaluate 15 different AI models. Here’s how Envision works:
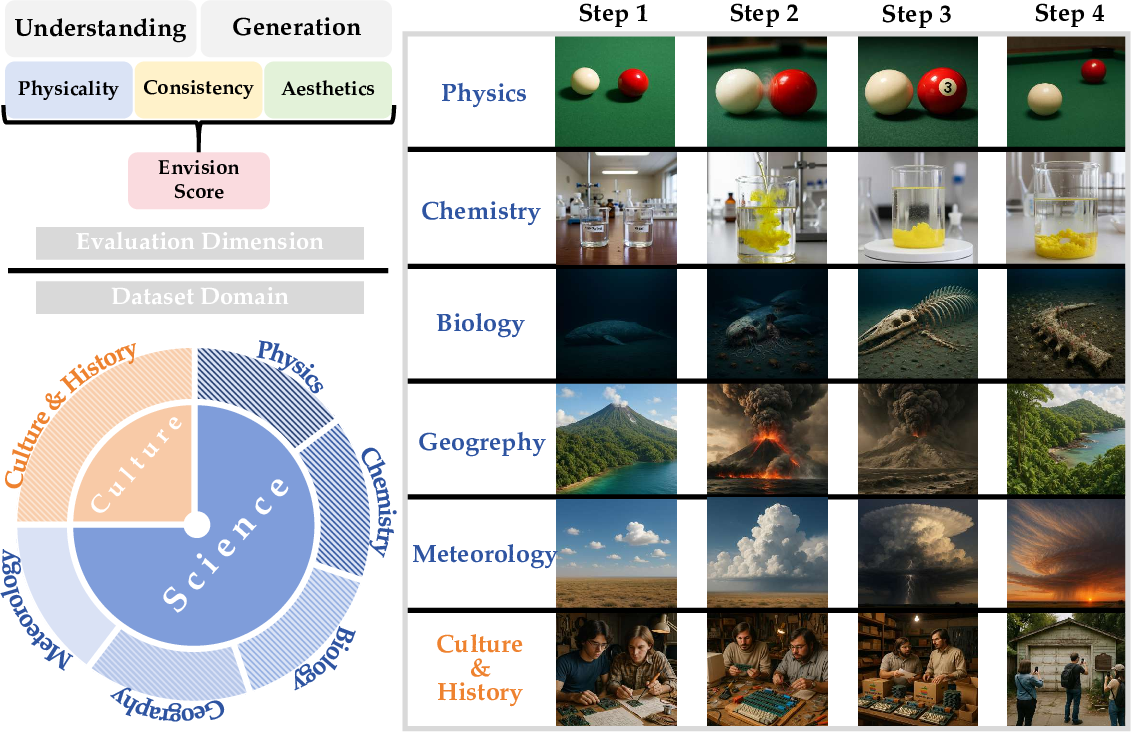
The Envision dataset
- They created 1,000 short, four-step story prompts across six areas: physics, chemistry, biology, meteorology (weather), geography, and human history/culture.
- Each prompt asks a model to generate four images that show a process over time. For example, melting ice, a chemical reaction, a plant growing, a storm forming, a river eroding land, or a historical timeline.
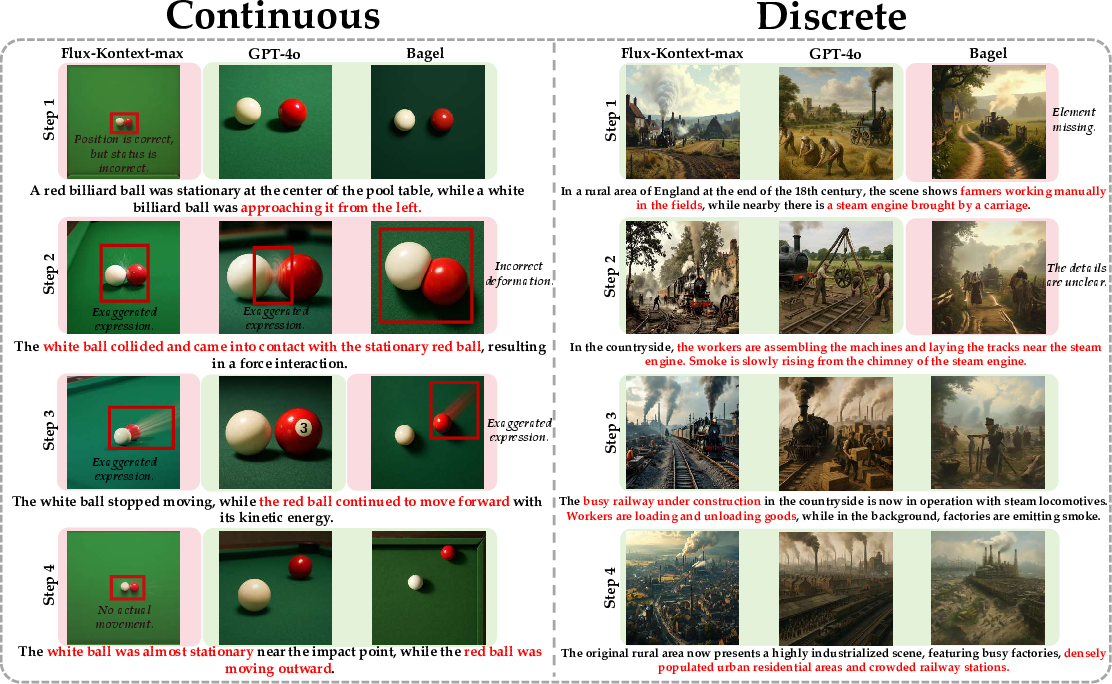
Two kinds of event sequences
- Continuous sequences: Smooth changes over time in the same scene (like ice melting or a ball rolling). These must obey physics and look consistent frame to frame.
- Discrete sequences: Bigger jumps over time or place (like stages of evolution or eras in history). These must still make sense logically, even if the steps are far apart.
Think of continuous sequences like a slow-motion clip, and discrete sequences like snapshots from different moments in a timeline.
Scoring with Envision-Score
To judge the image sequences, the team used an AI “referee” to score them based on three things:
- Consistency: Do the images tell a clear, logical story? Are facts and details kept consistent across frames?
- Physicality: Do the events obey the rules of the real world (like gravity, motion, and cause and effect)?
- Aesthetics: Are the images clear and visually appealing?
Because cause-and-effect matters most, Consistency and Physicality together count for 80% of the score, and Aesthetics counts for 20%.
To keep scores reliable, they ran multiple trials and checked that the AI judge agreed with human experts.
Models tested
They tested:
- Open-source text-to-image models (like FLUX and Stable Diffusion 3.5)
- Closed-source text-to-image models (like GPT-4o and Gemini)
- Unified multimodal models (UMMs), which both understand and generate images and text (like Seedream, Qwen-Image, and others)
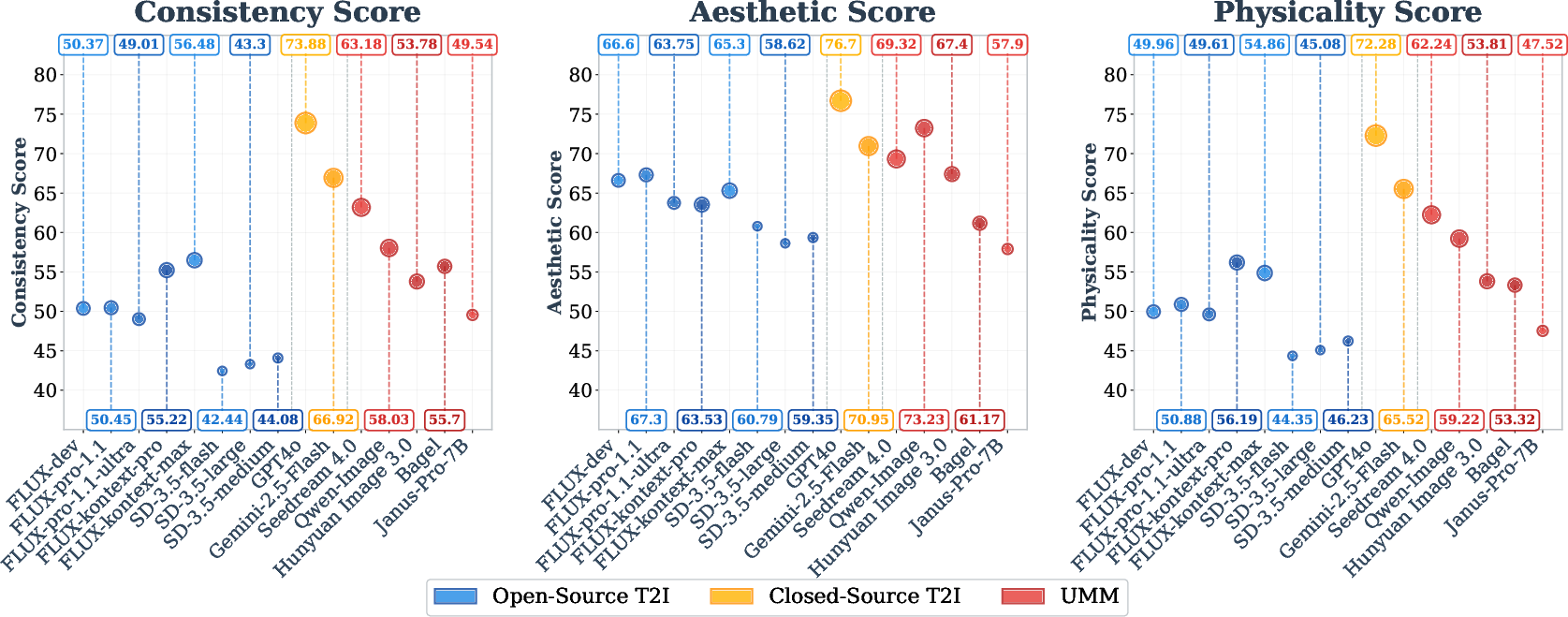
What did they find?
Here are the main results:
- Closed-source models (like GPT-4o and Gemini) performed best overall. They were strongest in making sequences that were logical, obeyed physics, and still looked good.
- Open-source text-to-image models were great at making beautiful images, but they often missed the logic and physics—so their stories didn’t always make sense.
- Unified multimodal models did better at causal storytelling than most open-source models, showing stronger “world knowledge.” But they still struggled with keeping things consistent across all frames, especially when strict physics or timing mattered.
- The hardest challenge for all models was “spatial-temporal consistency”—getting details, positions, and changes over time to match and flow naturally.
The authors call this the “Understanding–Generation Paradox”: models may “know” facts in a static way but fail to use that knowledge when generating a sequence of events. In short, being good at single images doesn’t mean the model can handle a process.
Why it matters
This research suggests that judging AI on single pictures is not enough. Real-world understanding means knowing how things change and why. Envision pushes AI models to:
- Learn cause and effect, not just styles and patterns
- Follow physics and common sense over multiple steps
- Combine understanding and generation so the story stays coherent
The big takeaway: To build truly smart visual AIs, we need training and tests that focus on sequences (like short image stories or video), not just single images. This could lead to better AI for science education, simulations, planning, storytelling, and any task that depends on modeling real processes over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that future work could address to strengthen the benchmark, its evaluation protocol, and the scientific claims drawn from it.
- Dataset scale and diversity: The benchmark includes only 1,000 four-stage sequences across six domains, which may be insufficient to capture the breadth of real-world dynamic processes, rare events, edge cases, and culturally diverse narratives.
- Domain imbalance: The dataset is 75% natural sciences and 25% history/culture; how this weighting affects conclusions and generalization remains unstudied.
- Prompt generation provenance and bias: Narrative prompts are generated/refined with GPT-4o under human supervision; the extent of model-induced bias, hallucination risks, and prompt ambiguity has not been audited or quantified.
- Absence of ground-truth visual targets: There are no canonical “correct” images per step; evaluation relies on plausibility rather than reference alignment, leaving open how to validate correctness beyond VLM judgments.
- Short, fixed-length sequences: All evaluations use four stages; the impact of longer sequences (e.g., 8–16 steps), variable lengths, or hierarchical event decompositions on causal coherence is unexplored.
- Missing evaluation for conditioning on prior frames: Generation appears to be per-step text-only (no explicit conditioning on previous images); whether models with memory/state (image-conditioned, recurrent, or video diffusion) improve spatiotemporal consistency remains untested.
- Lack of video-model baselines: The benchmark does not evaluate text-to-video or multi-frame diffusion models that natively enforce temporal consistency, limiting conclusions about modality-specific advantages.
- Continuous versus discrete causality is underspecified: Beyond narrative descriptions, there is no formal operational definition (e.g., measurable continuity constraints, state-transition invariants) to separate these regimes and analyze errors systematically.
- No physics-grounded validators: Physicality is judged by a VLM; there are no automatic checks for conservation laws, collision constraints, mass/energy continuity, or kinematic consistency, reducing the rigor of “physical reliability.”
- Metric normalization inconsistencies: Scores are defined on a 0–5 scale, yet reported tables show values in the 40–80 range; the transformation/normalization applied is not documented, complicating reproducibility and interpretation.
- Weight choices in Envision-Score are not justified: The 0.4/0.4/0.2 weights for consistency/physicality/aesthetics lack sensitivity analyses, human preference validation, or ablations to support the chosen emphasis.
- VLM-as-judge validity and bias: GPT-4o is both an evaluated model and the judge; potential self-favoring bias, cross-model bias, and per-domain bias are not quantified. Robustness to judge updates and drift is also unaddressed.
- Limited human evaluation: The alignment with five PhD experts over a small subset is reported without inter-rater reliability statistics, power analyses, or error taxonomies, leaving uncertainty around human–VLM agreement in failure cases.
- Statistical significance and uncertainty: While multi-trial scoring is mentioned, the benchmark does not report confidence intervals, significance tests, or robustness analyses for model rankings.
- Error taxonomy for causal failures is missing: There is no structured classification of failure modes (e.g., attribute drift, identity persistence errors, temporal order inversion, physics violation types), hindering targeted model improvement.
- Viewpoint control is under-specified: The benchmark claims spatial versatility (fixed vs varying views), but it does not isolate or quantify viewpoint-induced difficulty or assess view-consistency explicitly.
- Attribute and identity tracking across frames: There is no dedicated metric for identity persistence, attribute retention, or object correspondence across steps, central to causal sequence coherence.
- Ambiguity resolution and multi-validity scoring: Many prompts may admit multiple valid visualizations; the current scoring may penalize correct but alternative outputs. A strategy for multi-solution acceptance is lacking.
- Hyperparameter fairness: All models are run with default settings; the effect of tuning for multi-image coherence is not studied, potentially disadvantaging models not optimized for sequential generation.
- Model size/data confounds: The paper attributes performance gaps to architecture and training paradigms without controlling for model size, data scale, or training compute, limiting causal attribution.
- Training interventions are not evaluated: The benchmark diagnoses the “Understanding–Generation Paradox” but does not test whether training with multi-image sequences, causal curricula, or explicit CoT-guided generation measurably improves outcomes.
- Closed-loop generation protocols: There is no assessment of iterative generation where the model explicitly uses prior frames as causal memory and self-verifies constraints before producing the next frame.
- Cross-judge generalization: The choice of GPT-4o as the judge is justified qualitatively; a comprehensive cross-judge study (e.g., multiple VLMs, adversarial probes, consensus mechanisms) is missing.
- Reproducibility and versioning: GPT-4o and other closed models can change over time; the benchmark does not specify judge versioning, calibration procedures, or strategies to ensure longitudinal comparability.
- Dataset licensing and provenance: The legal status, licensing, and provenance of textbook/online sources used to construct prompts are not detailed, raising questions about redistribution and downstream use.
- Cultural fairness and sensitivity: The cultural/history subset is narrow; potential biases, sensitivity to cultural contexts, and fairness assessments across regions and eras are not reported.
- Benchmark compute and practicality: The computational cost of multi-image evaluation and multi-trial scoring is not quantified; guidelines for scalable, cost-aware evaluation are missing.
- Bridge to real-world applications: It remains unclear how Envision scores correlate with downstream tasks (e.g., scientific visualization, education, simulation); external validity is untested.
- Open-source tooling completeness: The exact scoring prompts, rubrics, and judge instructions (including chain-of-thought or rationale usage) are not fully specified, which hampers faithful re-implementation.
- Formalization of the “Understanding–Generation Paradox”: The paradox is described conceptually, but no operational measures, diagnostics, or quantitative tests are provided to evaluate it across architectures and training regimes.
Practical Applications
Immediate Applications
The following applications leverage the Envision benchmark, dataset, and Envision-Score to improve model evaluation, training, and downstream use of text-to-multi-image generation, with sector links and concrete workflows.
- Model evaluation and QA in software/ML
- Use case: Adopt Envision-Score as a continuous integration gate for T2I/UMM model releases to ensure causal, physical, and aesthetic quality across domains (physics, chemistry, biology, meteorology, geography, history/culture).
- Tools/workflows: “VLM-as-Judge” scoring service; Envision-Score dashboards; regression tests on the 1,000 four-stage prompt sequences; model comparison reports.
- Assumptions/Dependencies: Access to the Envision dataset and scorer (e.g., GPT-4o or an open VLM alternative); compute budget; stable API and licensing; awareness of metric gaming risks.
- Training-time reward shaping and fine-tuning in software/ML
- Use case: Integrate Envision-Score as a reward for reinforcement learning from AI feedback (RLAIF) or as a preference model to improve consistency and physicality during fine-tuning.
- Tools/workflows: Curriculum learning with continuous and discrete causal sequences; multi-trial scoring to stabilize reward signals.
- Assumptions/Dependencies: Reliable VLM-as-Judge alignment with human judgment; sufficient compute; careful mitigation of reward hacking.
- Content pipeline QA for media and advertising
- Use case: Auto-check multi-image storyboards and product explainer sequences for causal narrative coherence before publishing.
- Tools/products: “Causal Storyboard QA” plugin that flags violations of factual consistency or spatiotemporal continuity; batch scoring and triage queues.
- Assumptions/Dependencies: Human-in-the-loop review; model access with predictable latency; domain-specific prompt templates.
- Science and education content authoring
- Use case: Generate stepwise visual narratives for physical processes (e.g., thermodynamics), chemistry reactions, ecological succession, or historical events, with automated plausibility checks.
- Tools/products: Educator toolkits with four-stage prompt templates; “Causal Tutor” feedback using Consistency and Physicality sub-metrics.
- Assumptions/Dependencies: Pedagogical oversight; clear disclaimers that generated sequences are illustrative, not definitive; domain calibration for curricula.
- Procurement and policy evaluation of generative vendors
- Use case: Include Envision-Score in RFPs and vendor assessments to quantify causal coherence and physical plausibility alongside aesthetics.
- Tools/workflows: “Envision Compliance Scorecard” for procurement; standardized evaluation protocol with fixed seeds and trial counts.
- Assumptions/Dependencies: Agreement on scoring weights (Consistency/Physicality vs Aesthetics); reproducible runs; cross-vendor comparability.
- Platform safety and compliance checks
- Use case: Pre-publication screening to reduce implausible or misleading multi-image content (e.g., pseudo-scientific narratives).
- Tools/workflows: Physicality thresholding (Basic Properties, Dynamics and Interactivity, Physical Reliability); auto-escalation to moderation teams.
- Assumptions/Dependencies: False positive/negative management; policy integration; transparency around automated judgments.
- Academic research diagnostics
- Use case: Use Envision to analyze the “Understanding–Generation Paradox,” quantify failures in spatiotemporal reasoning, and benchmark new architectures or training regimes.
- Tools/workflows: Controlled ablations (single-image vs multi-image training); continuous vs discrete causality stress tests; cross-model analyses.
- Assumptions/Dependencies: Careful experimental design; open-source baselines; reproducibility protocols.
- Daily-life creator tools
- Use case: Help hobbyists produce coherent multi-step tutorials (DIY, cooking, fitness routines) with consistency checks.
- Tools/products: “Prompt chain templates” and sequence validators embedded in creator apps.
- Assumptions/Dependencies: Clear guidance on limitations; simple UI; access to reliable generation models.
- Synthetic data curation for ML
- Use case: Filter and label generated sequences based on Envision-Score to build higher-quality training corpora emphasizing causal and physical coherence.
- Tools/workflows: Data pipelines that select high-physicality outputs; metadata tagging by sub-metric (SC, FC, STC, BP, DI, PR).
- Assumptions/Dependencies: Licensing compatibility; scorer robustness; avoidance of overfitting to the evaluation metric.
- Robotics and simulation pre-checks
- Use case: Use multi-image plausibility checks as a lightweight triage for visual simulations or demos (not safety-critical).
- Tools/workflows: “Causal plausibility gate” before public demos; physicality thresholds for showcasing robot tasks or process animations.
- Assumptions/Dependencies: Non-dependence on these checks for operational safety; clear disclaimers; domain-specific tuning.
Long-Term Applications
These applications depend on advances in model architectures, training data (especially multi-image/video with causal links), and evaluation tooling, making them suitable as strategic development goals.
- Causal planner–generator architectures in software/ML
- Use case: Build UMMs with explicit interleaving of understanding and generation (e.g., plan with causal constraints, then render each frame), addressing the understanding-generation disconnect.
- Tools/products: “Causal Planner + Generator” module; integrated world-model training using multi-image sequences.
- Assumptions/Dependencies: New architectural inductive biases; large-scale, causally linked datasets; robust planning policies.
- Bridging T2MI to T2V for video generation
- Use case: Use multi-image sequences as a stable intermediate representation to train and evaluate T2V with strong spatiotemporal continuity and physics adherence.
- Tools/products: “Envision-Score for Video” (extension of sub-metrics to frame-level and sequence-level); video CoT planning.
- Assumptions/Dependencies: Scalable video datasets; efficient training; consistent evaluation across variable frame rates and perspectives.
- World simulation and digital twins for industry
- Sector: energy, manufacturing, logistics
- Use case: Generative causal simulation of process dynamics (line reconfiguration, grid stability events) to aid forecasting and decision support.
- Tools/products: “Generative Causal Simulator” integrated with digital twin platforms; scenario planning with multi-stage causal constraints.
- Assumptions/Dependencies: Integration with real sensor data; domain-specific validation; safety and reliability requirements.
- Robotics planning and control
- Use case: Use causally coherent generative models to predict task execution sequences, anticipate failure modes, and plan multi-step actions.
- Tools/workflows: Causal model-based planning; consistency-constrained trajectory prediction.
- Assumptions/Dependencies: High-fidelity world models; alignment with control policies; rigorous safety validation.
- Healthcare training and trajectory visualization
- Use case: Simulate disease progression, treatment pathways, surgical steps, or patient recovery trajectories as coherent multi-image narratives.
- Tools/products: Clinical training simulators with physicality and factual consistency checks; interactive case-based learning.
- Assumptions/Dependencies: Medical expert curation; regulatory compliance; strong factual grounding and dataset localization.
- Finance scenario planning and risk communication
- Use case: Visualize multi-stage market or policy shock sequences with causal coherence for analyst training and stakeholder communication.
- Tools/workflows: Causally constrained narrative generation; multi-image scenario “playbooks.”
- Assumptions/Dependencies: Domain adaptation; careful avoidance of spurious causality; governance for decision support use.
- Education: interactive causal lab assistants
- Use case: Students propose hypotheses and receive simulated causal progressions (e.g., reaction kinetics, ecosystem changes) with feedback on physical plausibility.
- Tools/products: “Causal Lab Tutor” that assesses student inputs via Consistency and Physicality metrics.
- Assumptions/Dependencies: Curriculum alignment; robust misconception handling; teacher oversight.
- Governance standards and certification
- Policy use case: Establish industry standards that require causal, physical, and factual coherence benchmarks (Envision-like) for generative systems used in public-facing or safety-relevant contexts.
- Tools/workflows: Certification frameworks; audit protocols with multi-trial scoring; public transparency reports.
- Assumptions/Dependencies: Multi-stakeholder adoption; open evaluation tooling; mitigation of measurement gaming.
- Deepfake and synthetic media forensics
- Use case: Detect generative manipulations by probing causal inconsistencies across frames (e.g., physics violations, time-order contradictions).
- Tools/workflows: “Causal Integrity Analyzer” using sub-metrics (STC, PR) to flag suspicious sequences.
- Assumptions/Dependencies: Ground-truth datasets; robust thresholds; adversarial testing.
- Climate and disaster response training
- Sector: emergency management, meteorology
- Use case: Generate causally coherent training scenarios (storm evolution, flood progression, wildfire spread) for preparedness and public education.
- Tools/products: Scenario trainers with domain-calibrated physicality scoring; interactive drills.
- Assumptions/Dependencies: Validation against historical data; domain experts-in-the-loop; ethical communication practices.
- Enterprise MLOps: causal QA services
- Use case: Offer “Causal QA” as a managed service to evaluate and certify generative models before deployment, ensuring spatiotemporal coherence and physical plausibility.
- Tools/products: Managed scoring pipelines; SLA-backed evaluation; red-teaming with causal stress tests.
- Assumptions/Dependencies: Cost control for large-scale evaluations; reproducibility; privacy and IP compliance.
Cross-cutting assumptions and dependencies
- Data and evaluation: Broader, high-quality multi-image/video datasets with explicit causal annotations; open, reliable VLM-as-Judge models to reduce closed-source dependence.
- Architecture and training: Inductive biases that enforce interleaved understanding–generation; planning mechanisms (e.g., causal CoT) that constrain sequential generation.
- Human oversight and governance: Expert review for high-stakes domains; transparency in scoring and limitations; safeguards against metric overfitting and misuse.
- Compute and cost: Scaling evaluations and training with multi-trial protocols; balancing statistical reliability with operational budgets.
- Ethical and regulatory constraints: Clear disclosures for synthetic narratives; domain-specific compliance (healthcare, finance, public policy).
Glossary
- Aesthetic Quality: A sub-dimension measuring the artistic merit and stylistic refinement of generated images. "Sub-dimensions include: Expressiveness, Aesthetic Quality, and Authenticity."
- Aesthetics: An evaluation dimension focused on visual appeal without sacrificing narrative integrity. "Aesthetics: Ensure that narrative expression does not come at the expense of aesthetic quality."
- AR with Diffusion Head: A hybrid approach where an autoregressive backbone interfaces with a diffusion-based generator. "AR with Diffusion Head approaches, such as Transfusion, often keep a pre-trained MLLM frozen and route its features to an external generator"
- Autoregressive (AR) Models: Models that generate sequences token-by-token, often by tokenizing images for sequential prediction. "Autoregressive (AR) Models like Chameleon~\cite{team2024chameleon}, Janus~\cite{wu2025janus}, and Emu3~\cite{wang2024emu3} tokenize visual inputs for sequential generation,"
- Authenticity: A sub-dimension assessing how realistic and believable generated content appears. "Sub-dimensions include: Expressiveness, Aesthetic Quality, and Authenticity."
- Basic Properties: A Physicality sub-dimension evaluating fundamental attributes (e.g., mass, shape, material states) required for plausible scenes. "Sub-dimensions include: Basic Properties, Dynamics and Interactivity, Physical Reliability."
- Bidirectional evaluation paradigm: An assessment framework that tests how generation informs understanding and vice versa. "The Envision establishes a bidirectional evaluation paradigm for T2I models"
- Causal ambiguity: Uncertainty about cause and effect due to lack of temporal cues. "creating causal ambiguity where the genesis and consequence of a visual state are indistinguishable."
- Causal event progression: A structured sequence of events linked by cause-and-effect over time. "we propose Envision—a causal event progression benchmark for chained text-to-multi-image generation."
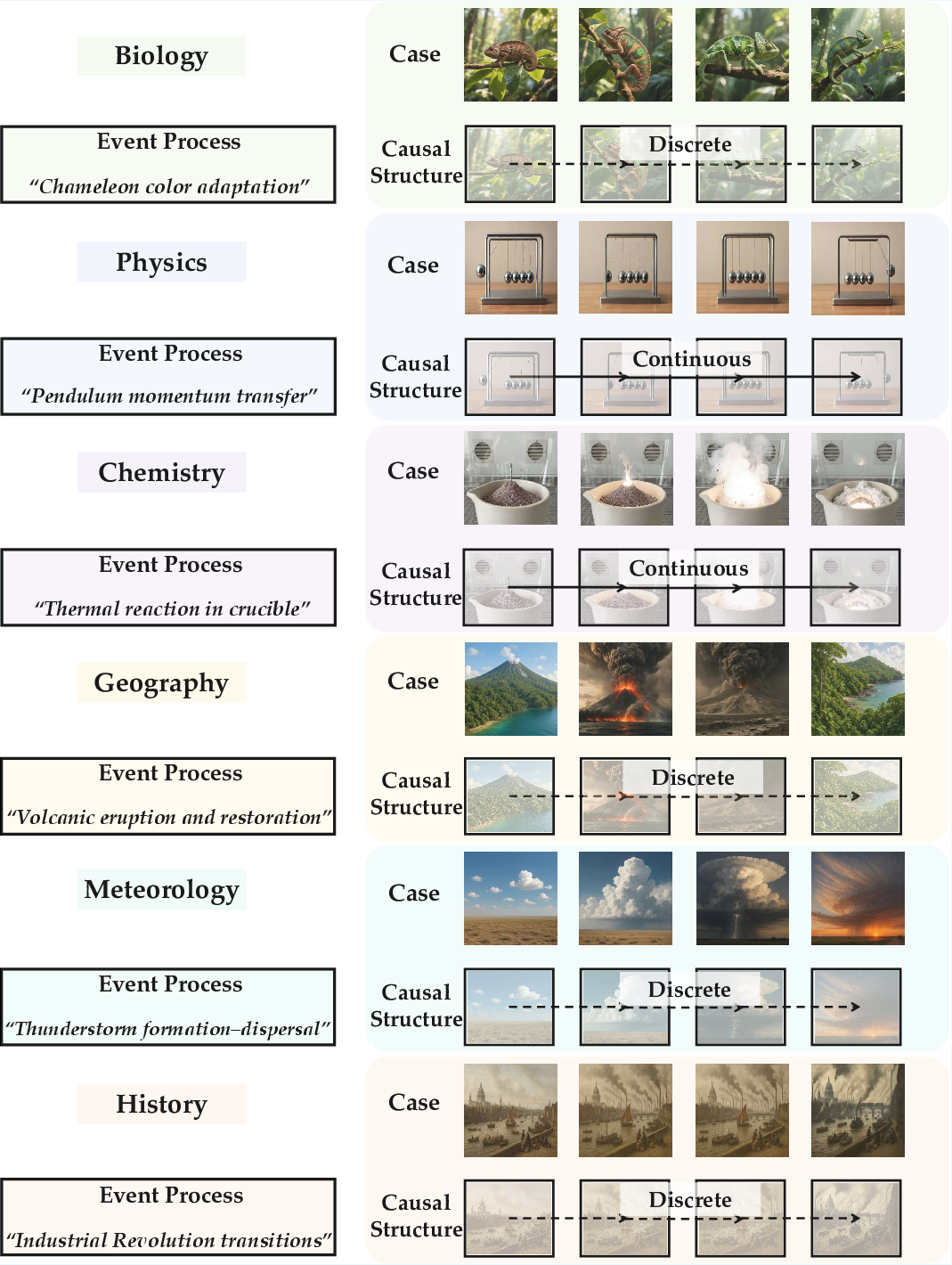
- Causal structure: The organized pattern of cause-and-effect relations across time and space. "representative cases showcase the causal structure of processes as discrete (dashed) or continuous (solid) spatial relations over time."
- Causal-temporal constraints: Requirements that generated sequences obey causal order and temporal logic. "assess whether models truly internalize world knowledge while adhering to causal-temporal constraints"
- Conservation laws: Physical principles (e.g., conservation of mass/energy) that must hold during state transitions. "generate smooth, physically consistent transitions that adhere to conservation laws,"
- Consistency: An evaluation dimension checking logical, factual, and narrative coherence across frames. "Consistency: Ensuring an unbroken multi-image sequence, this metric evaluates the preservation of logical, factual, and narrative coherence throughout the sequence."
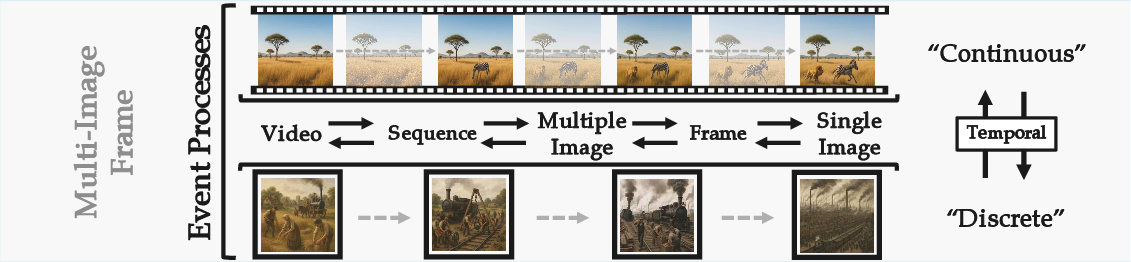
- Continuous Causality: Sequences with smooth time evolution in a fixed spatial context requiring fine-grained physical coherence. "Continuous Causality: These sequences maintain a consistent spatial context with smooth, uninterrupted temporal progression,"
- Discrete Causality: Sequences with temporal or spatial jumps that still require high-level logical coherence. "Discrete Causality: These sequences involve significant spatial leaps or substantial temporal jumps between frames,"
- Dynamics and Interactivity: A Physicality sub-dimension judging motion, interactions, and state changes among entities. "Sub-dimensions include: Basic Properties, Dynamics and Interactivity, Physical Reliability."
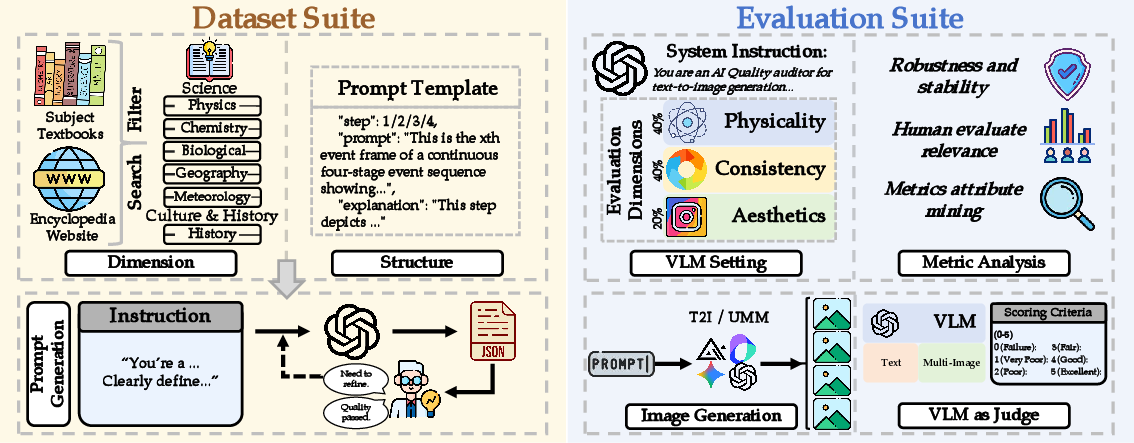
- Envision-Score: A composite metric combining Consistency, Physicality, and Aesthetics into a single score. "We propose Envision-Score, a dedicated metric for comprehensively evaluating event-level multi-image sequences across aesthetics, consistency, and physical."
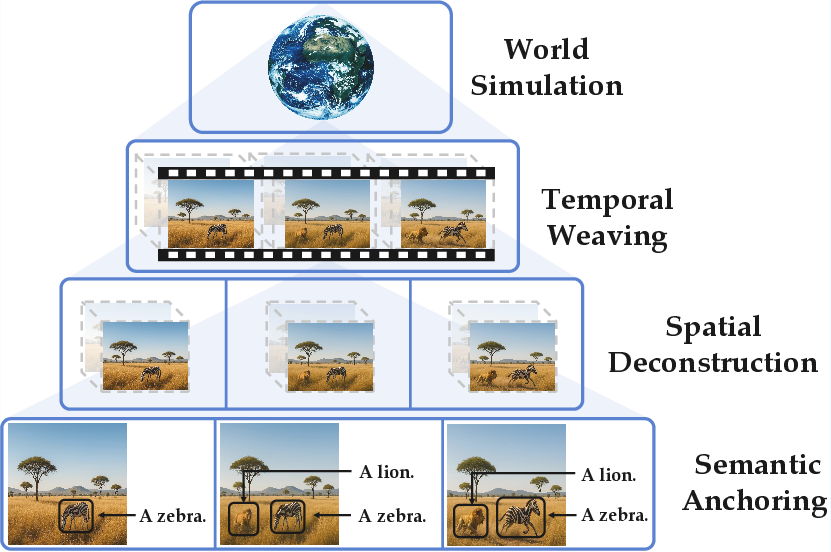
- Envision-Vision: The conceptual framework describing four stages needed for dynamic world modeling. "This vision, termed Envision-Vision, is concretely embodied in four stages:"
- Expressiveness: An Aesthetics sub-dimension evaluating clarity and richness of visual communication. "Sub-dimensions include: Expressiveness, Aesthetic Quality, and Authenticity."
- Factual Consistency: A Consistency sub-dimension checking alignment with real-world facts and prompt specifics. "Sub-dimensions include: Semantic Consistency, Spatial-Temporal Consistency, and Factual Consistency."
- Integrated Transformers: Architectures unifying different generative paradigms within one backbone to reduce bottlenecks. "Integrated Transformers~\cite{zhao2024monoformer, chen2024diffusion} unify different paradigms in one backbone to eliminate bottlenecks."
- Mixture-of-Transformers (MoT): A sparse, modular design that routes tasks or tokens to specialized transformer experts. "the Mixture-of-Transformers (MoT) paradigm~\cite{liang2024mixture, deng2025emerging} introduces a sparse, modular design, as seen in Bagel."
- Multi-trial Evaluation Protocol: A reliability procedure running multiple independent scoring trials per sequence. "we implement a comprehensive multi-trial evaluation protocol."
- Physical Reliability: A Physicality sub-dimension assessing adherence to physical rules over sequences. "Sub-dimensions include: Basic Properties, Dynamics and Interactivity, Physical Reliability."
- Physicality: An evaluation dimension measuring plausibility with respect to physical laws and dynamics. "Physicality: Focused on the plausibility of dynamic processes, this metric quantifies a model's internalization of physical laws and its capacity for reliable simulation."
- Semantic Anchoring: Mapping visual features to conceptual entities as a foundation for reasoning. "Semantic Anchoring (mapping visual features to conceptual entities)"
- Semantic Consistency: A Consistency sub-dimension ensuring meanings, attributes, and entities remain coherent across frames. "Sub-dimensions include: Semantic Consistency, Spatial-Temporal Consistency, and Factual Consistency."
- Spatial Deconstruction: Inferring 3D relations from 2D images to maintain spatial coherence. "Spatial Deconstruction (deconstructing 2D spatial relationships using implicit 3D cognition)"
- Spatial-Temporal Consistency: A Consistency sub-dimension ensuring coherence in both spatial layout and temporal evolution. "Sub-dimensions include: Semantic Consistency, Spatial-Temporal Consistency, and Factual Consistency."
- Spatiotemporal causality: Cause-and-effect relationships grounded in both space and time. "Grounded in world knowledge and structured by spatiotemporal causality,"
- Temporal Continuity: A requirement that frames in a sequence connect smoothly over time. "+ Temporal Continuity"
- Temporal directionality: The forward progression of time necessary to distinguish causes from effects. "static images lack temporal directionality,"
- Temporal Weaving: Constructing cross-time causal chains and state transitions. "Temporal Weaving (constructing cross-temporal causal chains and state transitions)"
- Text-to-Image (T2I): Generative task producing images from text descriptions. "Current text-to-image (T2I) models are capable of rendering images with remarkable realism and diversity"
- Text-to-Multi-Image (T2MI): Generating multi-image sequences from text, bridging images and video. "T2MI: Text-to-Multi-Image."
- Text-to-Video (T2V): Generating videos from text prompts with temporal coherence. "T2V: Text-to-Video"
- Unified Multimodal Models (UMMs): Architectures integrating understanding and generation across modalities. "Unified Multimodal Models (UMMs): The UMMs under evaluation are Janus-Pro-7B"
- Understanding-Generation Paradox: A failure mode where static understanding does not translate to dynamic generative control. "The Understanding-Generation Paradox: Fundamental Disconnect."
- VLM-as-Judge: Using a vision-LLM as an automated evaluator for generated outputs. "we adopt a composite methodology centered on three pillars: (1) Event Sequence-level Evaluation, (2) Deconstruction and Integration of Evaluation Dimensions, and (3) VLM-as-Judge Evaluation."
- Weighted Scoring Formulation: A scheme combining sub-dimension scores into dimension scores and a weighted overall score. "Weighted Scoring Formulation."
- World Simulation: Building internal models to predict and simulate spatiotemporal processes. "World Simulation (building an internal world model to predict spatiotemporal states and simulate process dynamics)"
Collections
Sign up for free to add this paper to one or more collections.

