Lotus-2: Advancing Geometric Dense Prediction with Powerful Image Generative Model
Abstract: Recovering pixel-wise geometric properties from a single image is fundamentally ill-posed due to appearance ambiguity and non-injective mappings between 2D observations and 3D structures. While discriminative regression models achieve strong performance through large-scale supervision, their success is bounded by the scale, quality and diversity of available data and limited physical reasoning. Recent diffusion models exhibit powerful world priors that encode geometry and semantics learned from massive image-text data, yet directly reusing their stochastic generative formulation is suboptimal for deterministic geometric inference: the former is optimized for diverse and high-fidelity image generation, whereas the latter requires stable and accurate predictions. In this work, we propose Lotus-2, a two-stage deterministic framework for stable, accurate and fine-grained geometric dense prediction, aiming to provide an optimal adaption protocol to fully exploit the pre-trained generative priors. Specifically, in the first stage, the core predictor employs a single-step deterministic formulation with a clean-data objective and a lightweight local continuity module (LCM) to generate globally coherent structures without grid artifacts. In the second stage, the detail sharpener performs a constrained multi-step rectified-flow refinement within the manifold defined by the core predictor, enhancing fine-grained geometry through noise-free deterministic flow matching. Using only 59K training samples, less than 1% of existing large-scale datasets, Lotus-2 establishes new state-of-the-art results in monocular depth estimation and highly competitive surface normal prediction. These results demonstrate that diffusion models can serve as deterministic world priors, enabling high-quality geometric reasoning beyond traditional discriminative and generative paradigms.
 *Figure 4: Comparisons in Detail Sharpness.
*Figure 4: Comparisons in Detail Sharpness. 
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Lotus-2, a new way for computers to understand the 3D shape of a scene from just one picture. It focuses on predicting “dense geometry,” which means figuring out, for every pixel, things like how far away it is (depth) and which way the surface is facing (surface normal). Lotus-2 uses knowledge learned by a powerful image generator to make these predictions more accurate and stable, even with very little training data.
What questions does the paper ask?
- How can we use the “world knowledge” inside large image generators to make reliable, accurate 3D predictions from a single image?
- Can we avoid the randomness that makes generators produce different results each time, and instead get stable, repeatable predictions?
- Is it possible to get both strong overall structure and sharp fine details, without needing huge training datasets?
How does the method work?
Think of a big image generator as someone who has looked at billions of pictures and learned a lot of “common sense” about the world—what shapes look like, how objects fit together, and what’s physically possible. Lotus-2 doesn’t ask this generator to “imagine” new images. Instead, it uses the generator’s built-in knowledge as a guide to make careful, consistent measurements of geometry.
The method has two stages:
- Stage 1: Core Predictor (Get the structure right in one go)
- Instead of taking many small steps (which can add errors), Lotus-2 takes one decisive step to turn the input image into its geometry (like depth), following a simple, direct path. This is called a “single-step deterministic” approach: no random noise, no guessing—so you get the same result every time for the same image.
- It also includes a tiny “Local Continuity Module” (LCM), which is like smoothing the seams after unfolding a folded map. This prevents faint grid-like artifacts that can appear due to how the generator’s features are packed and unpacked internally.
- Stage 2: Detail Sharpener (Polish the details without breaking the structure)
- After Stage 1 gets the big picture right, Stage 2 adds fine details (like crisp edges and thin structures) using a few small, careful steps. Importantly, it stays on a “safe track” defined by Stage 1 so it doesn’t invent impossible shapes. This stage is also deterministic—no randomness.
Key ideas explained simply:
- Deterministic vs. stochastic: Deterministic is like following a recipe exactly—same cake every time. Stochastic (random) is like rolling dice during cooking—you might get different results each time. For geometry, you want the recipe, not the dice.
- Rectified flow: Imagine sliding straight from point A to point B instead of taking a wiggly path. That straight path is simpler, faster, and less error-prone.
- Pack/Unpack and LCM: The model temporarily “folds” information to save space, then “unfolds” it. The LCM is a light touch-up that smooths out the fold lines.
What did they find?
- Stable and accurate predictions with very little data: Lotus-2 trains on only about 59,000 samples (less than 1% of what some top systems use) and still reports state-of-the-art results in estimating depth from one image, plus strong results for surface normals.
- Consistency beats randomness: Removing random noise from the process stops the output from wobbling. The same image produces the same geometry every time.
- One strong step works better than many small steps (when data is limited): The single-step design gave better accuracy and was easier to train than multi-step methods, which can accumulate errors.
- Clean prediction is better than “predict the fix”: Instead of predicting the difference between the input image and the correct geometry (which can drag in unwanted texture and lighting), predicting the clean geometry directly gives sharper, cleaner results.
- The LCM matters: That simple, tiny smoothing module removes grid-like artifacts and improves both visual quality and accuracy.
Why is this important?
- Works on tough images: Lotus-2 handles hard cases like shiny, transparent, or low-texture objects, and even artworks like oil paintings—things that often confuse other models.
- Faster and more reliable: Deterministic, single-step structure prediction is efficient and stable, which is great for practical use.
- Less data, better results: Getting top performance without giant datasets makes this approach more accessible and less expensive.
What could this lead to?
- Better tools for 3D and 4D reconstruction, AR/VR, and robotics: Reliable depth and surface predictions from one image help machines understand spaces the way humans do.
- Improved image editing and generation: Accurate geometry can guide image tools to add realistic shadows, lighting, and object placement.
- A new way to use generative models: Instead of asking image generators to “improvise,” Lotus-2 shows how to use their world knowledge as a steady, dependable guide for accurate measurements.
In short, Lotus-2 turns the vast “common sense” inside modern image generators into a stable, precise measuring tool for 3D geometry—getting strong structure first, then sharpening the details—while using surprisingly little training data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored, framed to guide concrete future research directions:
- Sensitivity to backbone choice: The approach is built around FLUX (DiT + rectified-flow). How does Lotus-2 perform if the world prior is swapped (e.g., SDXL, AuraFlow, non-VAE backbones)? Is there a systematic protocol for selecting or adapting different generative priors?
- Use of an image-trained VAE for geometry latents: The encoder/decoder were trained on RGB images, not geometry maps. What distortions, dynamic-range compression, or nonlinearity does the VAE introduce when encoding/decoding depth and normals? Would a geometry-specific VAE (or direct pixel-space modeling) improve fidelity and metric accuracy?
- “Constrained manifold” is not formalized: The detail sharpener is said to operate within the manifold defined by the core predictor, but no explicit constraint or projection operator is described. How can this constraint be made explicit (e.g., via a penalty, projection, or consistency regularizer) to guarantee preservation of global structure?
- Uncertainty and ambiguity handling: By design, Lotus-2 is deterministic. How can uncertainty (e.g., aleatoric/epistemic) be quantified for inherently ambiguous monocular geometry, and how might confidence-aware outputs or calibrated predictive intervals be integrated without reintroducing instability?
- Trade-offs in refinement steps and solvers: The detail sharpener uses Euler updates with up to 10 steps. What is the accuracy–speed–hallucination trade-off across different step counts, schedules, and ODE solvers (e.g., Heun, midpoint, RK4), and can adaptive step sizing reduce artifacts?
- Local Continuity Module (LCM) design space: LCM uses two 3×3 conv layers to mitigate Pack–Unpack grid artifacts. Are more advanced alternatives (e.g., sub-pixel convolution variants, dynamic filters, local attention, learned rearrangement, anti-aliasing filters) more effective, and how do they affect high-frequency detail retention and runtime?
- Pack–Unpack dependence and scalability: The architecture assumes latent down/up-sampling via Pack–Unpack at 2×2 granularity. How robust is the method to different image resolutions, aspect ratios, odd dimensions, and large-scale inputs? What happens if Pack–Unpack is replaced or removed while preserving efficiency?
- Dataset scale, composition, and label quality: Results are reported with 59K samples, but the diversity, label noise, and domain composition are not detailed. How does performance scale with curated OOD data (e.g., transparency, reflections, low-texture scenes), synthetic data, and varying annotation quality?
- OOD generalization is mostly qualitative: The teaser claims strong zero-shot generalization (e.g., paintings, transparent objects), but quantitative OOD benchmarks and controlled stress tests (transparency, specular highlights, extreme lighting) are lacking.
- Metric depth and calibration: The paper does not clarify whether depths are absolute or relative and how scale/shift alignment is handled across datasets. How should metric calibration be incorporated (e.g., via intrinsics, scene priors) to yield metrically accurate predictions?
- Physical consistency across tasks: Joint constraints (e.g., integrability constraints between depth and normals, cross-task consistency) are not enforced. Can physics-based priors (PDE-based integrability, shading consistency) improve reliability without sacrificing determinism?
- Failure-mode analysis: Potential issues like texture-copying, over-smoothing from LCM, or hallucinations during refinement are mentioned qualitatively but not systematically analyzed. A catalog of common failure modes and targeted mitigations would aid robustness.
- Detail sharpener training pipeline: The sharpener learns from core-predicted “coarse” outputs to “fine” ground truth. How sensitive is training to teacher error, distribution shift, and dataset leakage? Would curriculum learning, scheduled sampling, or consistency losses improve stability?
- Loss design in latent vs pixel space: Training relies on latent-space L2. How do alternative losses (e.g., scale-invariant depth losses, robust norms, perceptual or gradient losses in pixel space) affect accuracy, sharpness, and artifact suppression?
- Runtime and memory characterization: Although single-step inference is emphasized, detailed benchmarks (latency, throughput, memory footprint) versus leading baselines across resolutions are not reported. What are the speed/accuracy trade-offs when enabling the sharpener?
- Text/semantic conditioning: FLUX’s text conditioning is unused. Can semantic prompts or learned textual priors disambiguate challenging scenes (e.g., category-aware geometry) while keeping inference deterministic?
- Multi-task learning and broader properties: The method is demonstrated on depth and normals; extensions to albedo, shading, reflectance, optical flow, and material properties remain untested. Does joint training across tasks help leverage shared world priors?
- Multi-view and temporal consistency: The framework targets single images. How can it be extended to enforce cross-view or temporal consistency for videos, and what changes (e.g., recurrent refinement, 3D priors) are needed to maintain determinism across frames?
- Robustness to camera intrinsics and photometric variations: Sensitivity to focal length, lens distortion, exposure, noise, and HDR is not analyzed. How should intrinsics/extrinsics and photometric normalization be integrated to improve metric reliability?
- Reproducibility details for training: Key hyperparameters (optimization schedules, augmentation, masking for invalid/missing depth, normalization) are not fully specified here. A standardized, open protocol would improve replicability and fair comparison across datasets.
Practical Applications
Immediate Applications
The following applications can be deployed now or with minimal engineering, leveraging Lotus-2’s deterministic two-stage pipeline (core predictor + optional detail sharpener), strong zero-shot generalization, and data efficiency.
- Deterministic depth/normal APIs for controlled image generation (software/media)
- Use Lotus-2 as the geometry source for depth/normal-conditioned image synthesis (e.g., ControlNet-like workflows), improving stability and detail without test-time ensembles.
- Tools/products: “Lotus-2 Depth API” and “Lotus-2 Normal API” for creative suites (Photoshop, After Effects, Nuke, Blender).
- Assumptions/dependencies: Access to FLUX/DiT latent pipeline and VAE; outputs are relative depth unless calibrated.
- Single-photo 3D asset enhancement for e-commerce and advertising (e-commerce/creative software)
- Generate high-quality normal maps and pseudo-depth from catalog photos to drive relighting, shadow baking, and 3D-like viewers.
- Workflow: photo ingestion → VAE encode → core predictor → detail sharpener → export PBR maps (normal, height).
- Assumptions/dependencies: Domain-specific fine-tuning may be needed for certain product categories; metric scale requires calibration.
- Robust AR effects and filters on consumer devices (mobile/AR)
- Improve background blur, portrait bokeh, relighting, and occlusion handling (hair, glasses, transparent bottles) with deterministic outputs that avoid stochastic artifacts.
- Tools/products: SDK integration with ARKit/ARCore; on-device inference with 1-step core predictor and optional 2–10 refinement steps.
- Assumptions/dependencies: Mobile performance hinges on model optimization (quantization, pruning) and VAE acceleration.
- Visual effects and compositing for film/TV (media/CG)
- Generate per-pixel depth and surface normals for consistent relighting, depth-aware defocus, and compositing from single frames.
- Tools/products: Production plugins for Nuke and Fusion leveraging Lotus-2’s deterministic refinement for reproducible shots.
- Assumptions/dependencies: Calibration for metric needs; artist-in-the-loop QC remains essential.
- Robotics grasp planning for challenging materials (robotics/industrial automation)
- Use Lotus-2’s improved handling of transparent/reflective objects to inform grasp point proposals and collision checks in monocular setups.
- Workflow: monocular image → Lotus-2 geometry → grasp estimator → motion planner.
- Assumptions/dependencies: Depth is relative; fuse with stereo/SLAM or known object scale for metric planning; validate safety before deployment.
- Interior design and real estate visualization from single photos (AEC/real estate)
- Produce room geometry proxies to place furniture and simulate lighting from listing images; improve occlusion reasoning.
- Tools/products: “Photo-to-layout” feature in design apps; normals/depth for quick mockups.
- Assumptions/dependencies: Metric scaling via camera metadata or reference objects; domain fine-tuning for indoor scenes improves performance.
- Drone-based inspection pre-processing (energy/utilities)
- Enhance monocular frames with stable depth/normal priors for reflective infrastructure (solar panels, insulators) to support defect detection pipelines.
- Workflow: capture → Lotus-2 geometry → defect detector; deterministic outputs aid auditing.
- Assumptions/dependencies: Not a substitute for metric sensors; fuse with GPS/IMU/SLAM for scale; validate per asset type.
- Cultural heritage and art digitization (museums/cultural sector)
- Generate relief-like depth from paintings and artifacts—including oil paintings—to support visualization and study.
- Tools/products: “Relief-from-image” for online exhibits.
- Assumptions/dependencies: Depth is not a physical scan; use as visualization aid, not for restoration-grade measurements.
- Data-efficient academic baselines for dense prediction (academia)
- Adopt Lotus-2 as a reproducible, low-data baseline for depth/normal estimation studies; extend to other dense properties (e.g., albedo).
- Tools/products: Open-source benchmark suite using 59K samples; deterministic evaluation reduces variance.
- Assumptions/dependencies: Pre-trained FLUX weights licensing; domain adaptation costs for specialized datasets.
- Model engineering: Local Continuity Module (LCM) as a drop-in fix for grid artifacts (ML systems/software infra)
- Integrate the lightweight LCM after non-parametric Pack/Unpack in latent-transformer pipelines to eliminate grid artifacts without removing Pack/Unpack.
- Assumptions/dependencies: Minimal code changes; preserves pre-trained priors and efficiency.
Long-Term Applications
The following applications are promising but require further research, scaling, domain adaptation, or integration with complementary systems.
- Safety-critical monocular perception in autonomous driving (automotive)
- Deterministic depth/normal priors to augment perception stacks for rare conditions (reflections, low texture), improving consistency over stochastic pipelines.
- Tools/products: Priors for sensor fusion modules (LiDAR/radar/camera).
- Assumptions/dependencies: Extensive validation; metric scale via multi-sensor fusion; adherence to safety standards and regulatory testing.
- On-device AR glasses with real-time deterministic geometry (wearables/AR)
- Run single-step core prediction at low latency on edge hardware and apply adjustable refinement for scene detail.
- Assumptions/dependencies: Model compression, hardware acceleration (NPUs), and VAE latency reduction; power constraints.
- End-to-end photo-to-3D reconstruction for consumers (software/creative)
- Integrate Lotus-2 with neural rendering (e.g., NeRF variants) to produce reliable geometry priors for casual 3D capture from a few photos.
- Tools/products: “One-click 3D” mobile/desktop apps with controllable refinement.
- Assumptions/dependencies: Multi-view consistency modules; robust scale recovery; UI to handle failure cases.
- Industrial metrology and measurement from images (manufacturing)
- Use deterministic geometry for preliminary measurements where traditional scanning is unavailable.
- Assumptions/dependencies: Camera calibration, known reference objects, or learned scale; rigorous uncertainty modeling; compliance with QA standards.
- Transparent/reflective object manipulation in home/service robots (robotics)
- Improve grasping and navigation for glassware and mirrors using stable depth/normal priors coupled with tactile feedback.
- Assumptions/dependencies: Domain-specific fine-tuning; safety testing; fusion with active sensing to resolve metric ambiguities.
- Satellite and aerial monocular height estimation (geospatial)
- Provide deterministic height proxies for buildings/terrain to complement stereo/SAR in mapping.
- Assumptions/dependencies: Large-scale domain adaptation; geodetic calibration; careful bias auditing across regions.
- Extension to broader physical properties (material/appearance decomposition)
- Adapt the two-stage deterministic framework to estimate albedo, roughness, specular, and shading from single images for PBR pipelines.
- Tools/products: “Single-image material inference” for DCC tools.
- Assumptions/dependencies: New annotations or synthetic supervision; domain transfer strategies to avoid appearance leakage.
- Medical imaging geometry inference from monocular modalities (healthcare)
- Explore 3D structure estimation from single-view imaging (e.g., endoscopy) to aid navigation or reconstruction.
- Assumptions/dependencies: Strict clinical validation; ethical review; domain-specific pretraining; not a substitute for medical-grade 3D modalities.
- Standardization and policy for reproducible CV inference (policy/regulation)
- Promote deterministic inference in procurement and certification guidelines to reduce nondeterministic variance in public-sector CV applications (mapping, inspection).
- Assumptions/dependencies: Community benchmarks; documentation of world-prior biases (e.g., LAION-derived); energy-impact reporting.
- Sustainable ML practices via data efficiency (cross-sector)
- Use Lotus-2’s small-data training approach to reduce annotation and compute demands in dense prediction tasks.
- Assumptions/dependencies: Careful domain adaptation to avoid performance regressions; bias and generalization audits when repurposing large generative priors.
Glossary
- Albedo: The measure of surface reflectivity used as a per-pixel physical property in vision tasks. "Geometric dense prediction aims to recover pixel-wise geometric or physical properties, such as depth, surface normal, or albedo, from a single image."
- AuraFlow: A modern generative model leveraging rectified-flow/flow-matching formulations, cited as part of the latest diffusion landscape. "More recently, the emergence of the rectified-flow~\cite{liu2022flow} and flow-matching~\cite{lipman2022flow} formulations, explored in models like Stable Diffusion 3.x~\cite{esser2024scaling}, AuraFlow~\cite{cloneofsimo2024auraflow}, and significantly, FLUX~\cite{bfl2024flux}, represents the latest technological frontier."
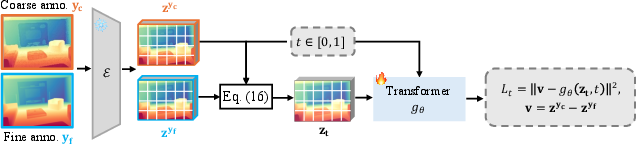
- Coarse-to-fine strategy: A two-stage approach that produces an initial coarse prediction followed by refinement for detail. "The third group attempts a coarse-to-fine strategy, exemplified by StableNormal~\cite{ye2024stablenormal}, which uses a two-stage approach combining initial prediction with subsequent refinement."
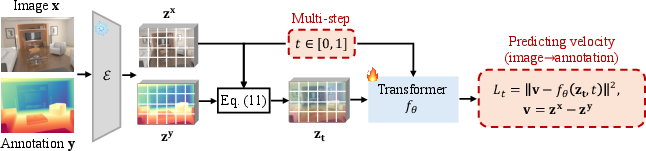
- Conditional generative flow: A generative process that transports noise to a target distribution conditioned on another input (e.g., an image). "This framework models a conditional generative flow by estimating the velocity field from a random noise latent to the annotation latent , conditioned on the image latent ."
- DDPM (Denoising Diffusion Probabilistic Models): A foundational diffusion training paradigm for generative modeling. "StabilityAI's release of Stable Diffusion 1.x and 2.x~\cite{rombach2022high,podell2023sdxl}, based on the DDPM~\cite{ho2020denoising} training paradigm and a UNet~\cite{ronneberger2015u} structure, initially revolutionizes the field."
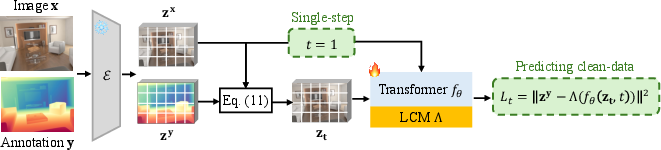
- Deterministic Direct Adaptation (Deterministic-DA): A noise-free rectified-flow adaptation directly mapping image latents to annotation latents for stable predictions. "We term this approach as Deterministic Direct Adaptation (Deterministic-DA) of the rectified-flow formulation."
- Detail Sharpener: The second-stage model performing constrained multi-step rectified-flow refinement to enhance fine-grained geometry. "In the second stage, the detail sharpener performs a constrained multi-step rectified-flow refinement within the manifold defined by the core predictor, enhancing fine-grained geometry through noise-free deterministic flow matching."
- DiT (Diffusion Transformer): A transformer-based architecture used as the backbone in modern diffusion models like FLUX. "FLUX adopts the DiT (Diffusion Transformer)~\cite{peebles2023scalable} architecture as its model ."
- Euler solver: A simple numerical ODE integrator used to step along the learned velocity field during inference. "During sampling (inference), the discrete Euler solver is used to iteratively generate the target sample () from the source ()."
- Flow matching: A formulation that learns velocity fields to transport one distribution to another via ODEs. "More recently, the emergence of the rectified-flow~\cite{liu2022flow} and flow-matching~\cite{lipman2022flow} formulations..."
- FLUX: A state-of-the-art diffusion model built on DiT and rectified-flow, used as the world prior in this work. "Given the visual quality and superior physical consistency, the pre-trained FLUX model is the optimal choice as the world prior for our geometric dense prediction."
- GELU activation: The Gaussian Error Linear Unit nonlinearity used in the Local Continuity Module. "LCM consists of two convolutional layers with an intermediate GELU activation~\cite{hendrycks2016gaussian} to introduce nonlinearity..."
- Geometric dense prediction: The task of estimating per-pixel geometric/physical properties (e.g., depth, normals) from an image. "Geometric dense prediction aims to recover pixel-wise geometric or physical properties, such as depth, surface normal, or albedo, from a single image."
- Geometric hallucination: Spurious, incorrect geometric structures introduced during modeling or refinement. "In contrast, multi-step flow (e.g., Deterministic-DA) retains the complexity to model high-frequency dynamics and can produce sharper details; however, due to its optimization difficulty and the accumulation of high errors across multiple steps, it is prone to geometric hallucination..."
- Grid artifacts: Checkerboard-like discontinuities resulting from parameter-free spatial rearrangements (e.g., Pack–Unpack). "which mitigates grid artifacts introduced by the non-parametric PackâUnpack operations in FLUX while maintaining architectural compatibility and efficiency."
- Lambertian reflectance model: A classical reflectance assumption where surfaces reflect light equally in all directions. "For instance, they often require multiple views of the scene, precise camera calibration, or strict adherence to the Lambertian reflectance model."
- Local Continuity Module (LCM): A lightweight convolutional module that restores local spatial coherency after Unpack to remove artifacts. "This single-step predictor is further enhanced with a lightweight local continuity module (LCM) to generate globally coherent structures without grid artifacts."
- Manifold: A constrained solution space or subspace within which refinement is performed to preserve structure. "the detail sharpener performs a constrained multi-step rectified-flow refinement within the manifold defined by the core predictor..."
- Multi-step sampling: Iterative sampling procedure in diffusion models that accumulates updates over many steps. "the former requires deterministic and accurate inference, whereas the latter optimizes for diverse and high-fidelity image generation through stochastic multi-step sampling."
- Non-injective mappings: Mappings where different inputs produce the same output, causing ambiguity in inverse problems. "Recovering pixel-wise geometric properties from a single image is fundamentally ill-posed due to appearance ambiguity and non-injective mappings between 2D observations and 3D structures."
- Out-of-distribution (OOD): Data or scenarios not covered by the training distribution, often challenging for discriminative models. "Consequently, they struggle severely with out-of-distribution (OOD) scenarios, including highly reflective surfaces, transparent objects, or rare scene compositions..."
- Pack–Unpack operations: Parameter-free spatial rearrangements that reduce compute by folding/unfolding spatial dimensions into channels. "This Pack-Unpack operation, while efficient, introduces a critical challenge: because it is parameter-free, it can introduce noticeable local pixel discontinuities (``grid-artifacts'')."
- Photometric consistency: The assumption that corresponding points across images have consistent intensity, used for geometric inference. "Early multi-view geometry and photometric consistency methods rely on strong assumptions about scene structure..."
- Photometric stereo: A technique estimating surface normals from multiple images under varying illumination. "photometric stereo~\cite{woodham1980photometric}"
- Rectified-flow (RF) formulation: An ODE-based generative formulation transporting samples along straight-line paths between source and target distributions. "The rectified-flow (RF) formulation~\cite{liu2022flow,lipman2022flow} provides a robust and deterministic framework for modeling the transformation between two arbitrary probability measures via an ordinary differential equation (ODE)."
- Structure from Motion (SfM): A method that reconstructs 3D structure and camera motion from multiple images. "such as structure from motion (SfM)~\cite{tomasi1992shape,snavely2008modeling}"
- Stochastic Direct Adaptation (Stochastic-DA): A conditional noise-to-annotation adaptation that retains stochasticity from generative diffusion. "We term this approach as Stochastic Direct Adaptation (Stochastic-DA)."
- Test-time ensembling: A post-processing technique that averages multiple predictions to reduce variance. "Post-processing (e.g., test-time ensembling~\cite{ke2024repurposing,fu2024geowizard}) doesn't solve it in a native manner..."
- UNet: A convolutional encoder–decoder architecture widely used in diffusion models for image generation. "based on the DDPM~\cite{ho2020denoising} training paradigm and a UNet~\cite{ronneberger2015u} structure"
- Variational Autoencoder (VAE): A generative model with encoder/decoder that learns a latent space for data; used here to operate in latent space. "We leverage the architecture and weights of FLUX\cite{bfl2024flux}, which utilizes a pre-trained variational autoencoder (VAE) to compress high-dimensional image data into a compact latent space ."
- Velocity vector field: The learned vector field guiding transport along the rectified-flow ODE. "Specifically, given a source distribution and a target distribution , the ODE on time-step is defined as: , which maps to under the velocity vector field ."
- World priors: Rich structural knowledge about geometry and semantics encoded by large generative models. "Recent diffusion models exhibit powerful world priors that encode geometry and semantics learned from massive imageâtext data..."
- Zero-shot generalization: The ability of a model to perform well on unseen tasks or domains without task-specific training. "This figure demonstrates Lotus-2's robust zero-shot generalization with sharp geometric details, especially in challenging cases like oil paintings and transparent objects."
Collections
Sign up for free to add this paper to one or more collections.

