- The paper introduces FoundationGait, a self-supervised model that leverages part-aware pretraining to effectively maintain local detail for scalable gait analysis.
- It achieves state-of-the-art zero-shot performance with 48.0% and 64.5% rank-1 accuracy on challenging datasets while outperforming prior self-supervised baselines.
- The model excels in healthcare analytics, demonstrating up to 97% accuracy in scoliosis detection and robust transferability across diverse clinical tasks.
Silhouette-based Foundation Model for Scalable and Unified Gait Understanding
Motivation and Challenges in Gait Foundation Modeling
Conventional vision-based gait analysis offers major advantages for identity recognition and healthcare analytics but has faced core scientific constraints: scalability and cross-task generalization. Gait models have historically failed to exhibit scaling-law behaviors as observed in other foundation models, with accuracy saturating or degrading as model parameters increase. This collapse was typically attributed to the low-resolution, binary nature of silhouette inputs and the loss of local part-specific details. Furthermore, gait tasks such as recognition and healthcare analysis have been developed largely in isolation, overlooking the potential benefit in unifying these domains within a single large-scale model.
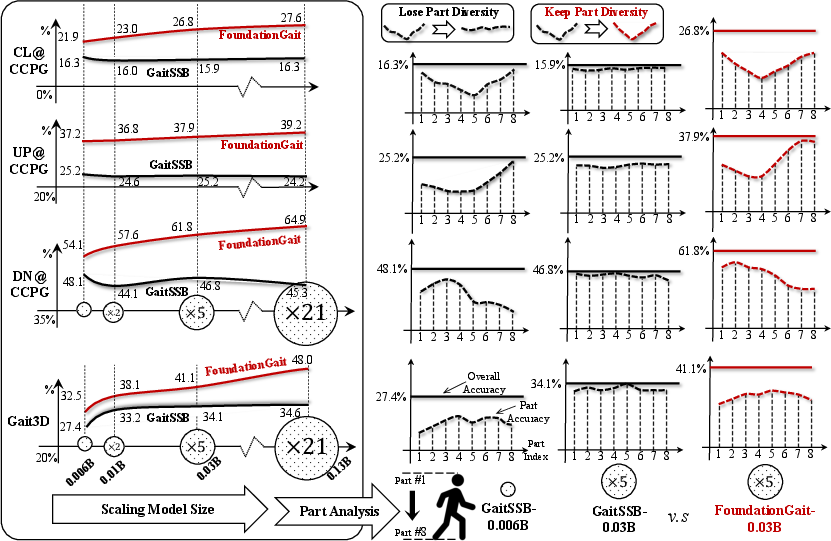
Figure 1: Performance collapse of self-supervised GaitSSB models with increased size, illustrating the central scalability barrier.
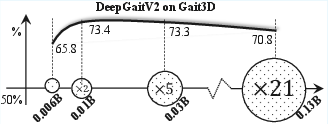
Figure 2: Supervised DeepGaitV2 models also fail to benefit from increased parameterization, evidencing a similar scalability issue.
This paper directly addresses these longstanding limitations by introducing FoundationGait: a self-supervised gait foundation model tailored for scalable pretraining and broad generalization across both recognition and healthcare tasks.
FoundationGait: Methodology and Scalable Pretraining
The central technical insight of FoundationGait is that maintaining fine-grained, body-part-specific diversity in feature representations is essential for successful scaling. Prior part-based approaches, despite declining popularity, offer a crucial inductive bias that prevents homogenization of learned features as model depth increases. FoundationGait introduces a part-aware pretraining strategy, where each silhouette sequence is decomposed into multiple local parts across student branches, preserving distinctive cues even in deep models.
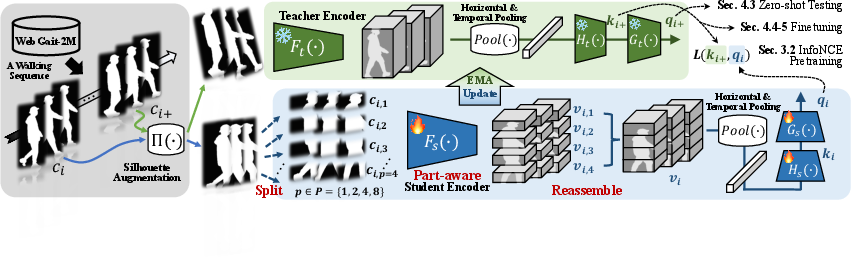
Figure 3: Schematic overview of the FoundationGait self-supervised pretraining framework with part-aware diversity enforcement.
Pretraining is conducted on WebGait-2M, a curated corpus with over 2.35 million walking sequences from 12 publicly available datasets spanning recognition and healthcare. FoundationGait evaluates two large configurations: 0.03B and 0.13B parameters, each reflecting significant capacity expansion over the traditional 5M parameter regime.
The self-supervised framework employs contrastive objectives between part-aggregated representations, and an augmented teacher-student scheme for stability. A part-aware hyperparameter P controls the granularity, ensuring the student encodes features at multiple spatial resolutions.
Experimental Results: Cross-domain Scalability and Generalization
Zero-shot recognition: FoundationGait achieves strong zero-shot performance across all major evaluation datasets. At 0.13B parameters, it yields 48.0% rank-1 accuracy on the challenging in-the-wild Gait3D set (1,000 subjects) and 64.5% on OU-MVLP (5,000+ subjects). These results outpace both prior self-supervised baselines (by +13.4% and +20.1% respectively) and remain competitive with state-of-the-art supervised approaches.
Healthcare analytics: Under linear probing and fine-tuning, FoundationGait establishes highly separable representations for scoliosis detection (up to 97.0% accuracy after fine-tuning), depression risk prediction, and fine-grained gait attribute estimation. Notably, for certain tasks, linear probe performance is comparable to or surpasses previous full-training baselines, demonstrating the model's inherent data-efficient transfer capabilities.
Fine-tuning Framework and Task Heads
Downstream adaptation is executed via task-specific heads that replace the pretrained predictor in the teacher, while preserving part-aware mechanisms.

Figure 4: Recognition head for fine-tuning, incorporating identity embeddings with triplet and cross-entropy objectives.

Figure 5: Healthcare head outputs categorical logits for clinical tasks, omitting intermediate feature projections.
The design allows seamless transfer for both identification and medical screening applications without architectural modifications to the core backbone.
Ablations and Model Insights
Ablation experiments substantiate the necessity of part-aware training for scalability. Naïvely scaling up existing architectures (e.g., DeepGaitV2, GaitSSB) leads to catastrophic performance drops, while incorporating the proposed strategy reverses this trend and aligns with expected scaling laws. Furthermore, attempts to replace CNN blocks with ViTs in this context result in substantial performance reduction, indicating the ongoing primacy of convolutional inductive biases for silhouette-based gait modeling at this time.
Cross-modality experiments reveal that FoundationGait generalizes well to previously unseen human parsing inputs and supports straightforward fusion strategies, highlighting its robustness as a foundation model.
Implications and Future Directions
FoundationGait provides empirical evidence that scaling laws apply to vision-based gait modeling, contingent on explicit enforcement of part-wise feature diversity. These findings offer a practical template for future research into scalable video-based foundation models in specialized domains with homogeneous and information-dense input distributions. Moreover, the model's ability to unify identity recognition and healthcare signal extraction in a single backbone advances the practicality of gait-based biometrics in unconstrained, real-world environments.
Scaling beyond 0.13B parameters is currently constrained by computational resources, but the observed trends indicate the viability of even larger models. However, further work is needed to recover competitive performance with ViT-based models, which will be required for converging gait foundation learning with other LVM/LLM architectures and cross-modal pretraining paradigms.
Conclusion
FoundationGait sets a new state-of-the-art for scalable, unified silhouette-based gait analysis. It demonstrates, via rigorous empirical validation, that size scalability and cross-task generalization are attainable within a single self-supervised framework. This work opens new directions in robust biometric identification and clinical gait analytics, while establishing essential methodological principles for the foundation modeling of human motion data (2512.00691).

