- The paper introduces an end-to-end transformer-based method that synthesizes photorealistic, relightable human avatars from as few as four RGB views.
- It combines physics-informed feature encoding in UV space with a mesh proxy to capture detailed geometry, albedo, and shading information for dynamic performances.
- Experimental results demonstrate up to 2-3 dB PSNR improvements over state-of-the-art, with robust generalization to novel poses and lighting conditions.
Relightable Holoported Characters: Photorealistic Dynamic Human Relighting from Sparse Views
Introduction and Motivation
Relightable Holoported Characters (RHC) represents an advance in free-viewpoint rendering and relighting of dynamic, full-body human performances using only sparse RGB observations at inference. Traditional approaches to person-specific human relighting typically depend on either exhaustive one-light-at-a-time (OLAT) data capture or strong priors on geometry and BRDFs, often limiting the relighting fidelity for highly dynamic or unseen poses. RHC introduces an end-to-end, transformer-based method that achieves photorealistic relighting and view synthesis from as few as four input views, and robustly generalizes to novel motions and illuminations. This capability, coupled with a new lightstage capture protocol and a physics-informed feature encoding, addresses core challenges of geometric/material-light disentanglement in non-rigid reconstructions.
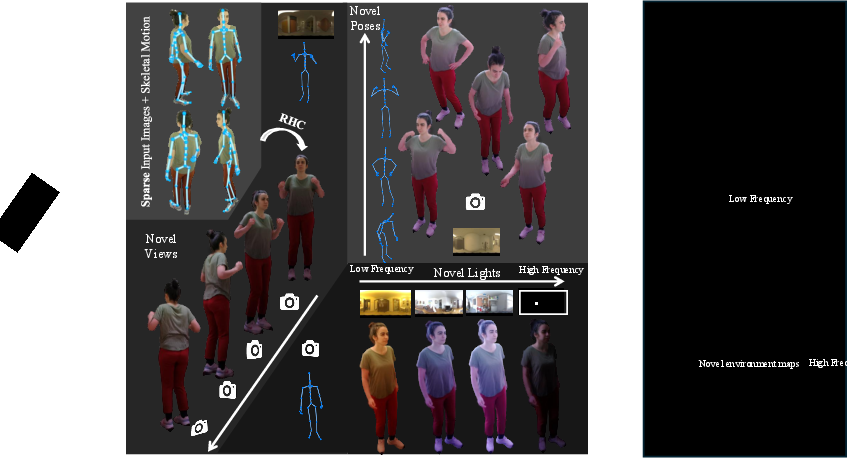
Figure 1: RHC produces photorealistic, relightable digital twins of humans from sparse RGB observations, enabling seamless avatar insertion into virtual environments.
Dataset and Capture Strategy
A key enabler for high-quality dynamic relighting is the devised data acquisition method. Instead of relying on costly and impractical full OLAT coverage for every pose, the RHC dataset alternates between randomized environment map illuminations for relighting supervision and uniformly lit frames to support robust motion tracking.
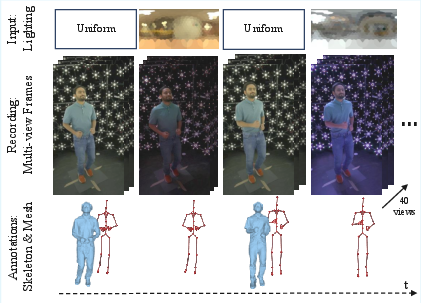
Figure 2: The framework alternates between tracking frames under uniform light and relit frames using randomized environment map projections, facilitating both accurate geometry/timing alignment and diverse illumination coverage.
This strategy, implemented in a multi-view lightstage, provides temporally aligned motion and relighting supervision, crucial for dynamic, non-rigid bodies where linear OLAT composition fails due to motion-induced misalignments. Each subject is recorded with 40 views under 1000+ HDR environment maps, ensuring the diversity required for robust generalization.
Methodology
Overview & Character Model
RHC leverages a subject-specific mesh proxy, animated with tracked skeleton poses using an embedded graph and vertex refinement, akin to Deep Dynamic Characters. Geometry and pose are mapped to a stable UV parameterization, forming the foundation for texture-space modeling of both appearance and lighting effects.
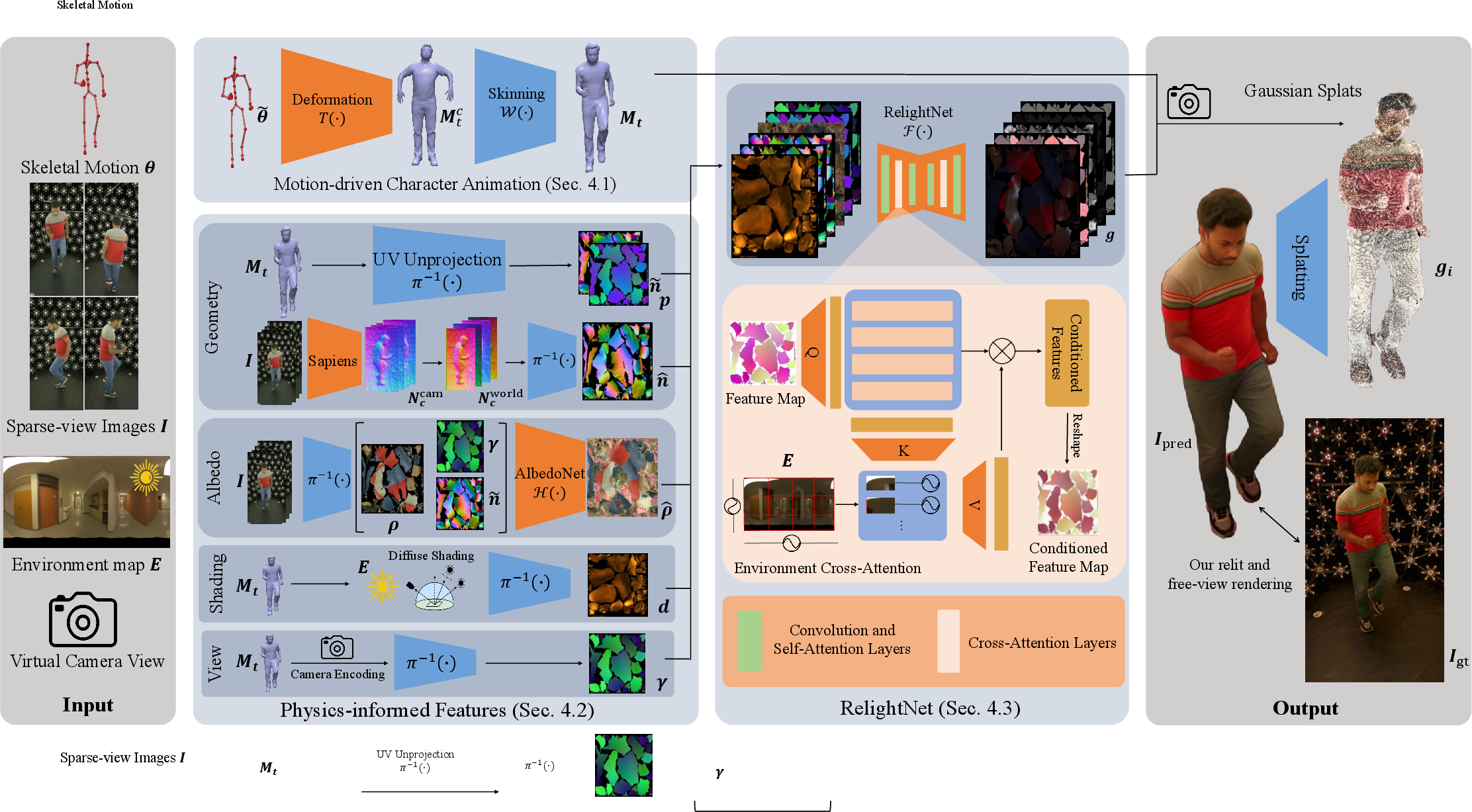
Figure 3: The end-to-end pipeline: four sparse input views and pose are used to animate a coarse mesh proxy; physics-informed features are extracted in UV space, cross-attended with the desired environment map, and then regressed to texel-aligned 3D Gaussian splats for photorealistic relighting.
Recognizing the impracticality of explicit BRDF and albedo estimation for dynamic humans, RHC derives UV-space feature maps approximating rendering equation components:
- Geometry: Stacks of mesh normals (for temporal/geometric context), high-frequency surface normals unprojected from input images, and global position maps to encode near-field and curvature cues.
- Albedo: Estimated from unprojected uniformly lit views and refined via a learned inpainting/inference network to handle occlusions and misalignments.
- Shading: Per-texel precomputed diffuse shading, considering environment lighting and visibility.
- View: Directional encoding from mesh position to camera, facilitating view-dependent effects such as specularities.
These features collectively allow RelightNet to circumvent explicit or highly parameterized BRDF modeling, letting the network instead learn a physically plausible mapping from data.
RelightNet Design
The central RelightNet employs a transformer-based architecture operating in UV space. By integrating self- and cross-attention, it fuses local spatial/material cues with the global structure of the input environment map. At each UV texel, cross-attention synthesizes the effect of all lighting directions with respect to scene geometry, position, and view, paralleling the conceptual structure of the rendering equation.
Output is formulated as parameters for a set of texel-aligned 3D Gaussian splats (position, scale, rotation, opacity, color), attached to the mesh proxy and rendered to the target view. This representation, shown recently to enable high-fidelity view synthesis with temporal consistency, supports both efficient rasterization and photorealistic detail.
Experimental Results
Quantitative and Qualitative Evaluation
Against several rigorous baselines—including Relighting4D, IntrinsicAvatar, MeshAvatar (all augmented with ground-truth environment data for fair comparison), and real-time Holoported Characters with or without Neural Gaffer—RHC systematically achieves the highest fidelity in canonical metrics (PSNR, SSIM, LPIPS), with improvements up to 2-3dB PSNR and >2% SSIM over second-best competitors.

Figure 4: RHC renders novel motions under novel illuminations from just four input views, preserving high-frequency details and temporal coherence.

Figure 5: Qualitative comparison to state-of-the-art, where RHC distinctly outperforms in shading accuracy and preservation of surface detail.
Critically, RHC's inferences consistently surpass competitors with respect to:
Ablation and Analysis
Substantial ablation studies verify the impact of each module:
Additional systematic experiments further highlight:
- View sparsity: Even a two-camera setup preserves much of RHC's superiority, though further reduction increases hallucinated detail.
- Lighting diversity: Reduced exposure during training degrades generalization, suggesting the necessity of broad illumination coverage.

Figure 8: Decreasing input views leads to increased detail hallucination and reduced reconstruction quality.

Figure 9: Reduced diversity in training illumination causes overfitting and poor test-time generalization.
Effect of Capture Strategy
OLAT-based dynamic captures, when feasible, yield degraded image quality relative to the proposed diverse, randomized illumination protocol. Errors accumulate with linear OLAT recombination in dynamic scenes, underscoring the value of the specific lightstage capture approach.

Figure 10: OLAT-based training is more error prone and less generalizable than the random environment capture strategy of RHC.
Limitations and Future Directions
While RHC closes several gaps left by previous relightable dynamic avatar pipelines, notable limitations remain:
- Identity specificity: Models are subject-specific. Cross-identity or clothing generalization would require population-wide priors or large-scale multi-subject training (e.g., extending with diffusion-generated priors).
- Handling topology changes/translucency/accessories: Hard cases like jackets removal, transparent apparel, or shiny accessories (e.g., glasses) remain challenging, as geometric proxies and training data cannot robustly represent all cases.
- Computational performance: Current pipeline operates at ~2FPS. Potential improvements include CUDA-accelerated ray tracing and neural distillation for real-time applications.
- Scalability: For applications in telepresence, identity-agnostic and interactive relighting are key milestones for future research.
Conclusion
RHC demonstrates that photorealistic, relightable, free-viewpoint human avatars are achievable from sparse RGB observations by combining data-driven feature design, attention-based illumination modeling, and mesh-based geometric priors. The introduction of a tailored lightstage protocol and transformer-based cross-attention network enables the direct, efficient evaluation of the rendering equation for arbitrary pose and lighting conditions, surpassing state-of-the-art in both numerical and qualitative metrics. The implications extend to videotelephony, VFX, digital doubles, and immersive AR/VR applications. Extensions toward subject-generalizable, real-time, and scene-adaptive relightable avatars represent important and plausible directions for subsequent research.

