- The paper presents a novel powerset alignment method that exhaustively aligns image regions with parsed textual phrases.
- It introduces Non-Linear Aggregators to reduce computational complexity from O(2^M) to O(M), ensuring efficient multimodal learning.
- Experimental results show state-of-the-art performance across 22 of 28 benchmarks, enhancing compositional reasoning in vision-language tasks.
PowerCLIP: Powerset Alignment for Contrastive Pre-Training
Introduction
The paper, "PowerCLIP: Powerset Alignment for Contrastive Pre-Training" (2511.23170), introduces a novel framework designed to enhance visual and linguistic understanding through an improved contrastive vision-language pre-training protocol. Traditional methods like CLIP primarily focus on aligning images and texts globally, yet they often fall short when dealing with complex compositional semantics that involve multiple image regions. PowerCLIP proposes an innovative solution by exploring exhaustive region-to-phrase alignments, thereby optimizing the alignment with phrases parsed from textual descriptions.
Methodology
PowerCLIP's methodology hinges on a powerset alignment strategy. This strategy contrasts significantly with typical single-region or masked-region alignment approaches by systematically examining all possible subsets of image regions. This exhaustive exploration is computationally intensive, with a naive approach reaching exponential complexity. To counter this, the authors propose Non-Linear Aggregators (NLAs) that reduce the complexity from O(2M) to O(M), where M is the number of image regions.
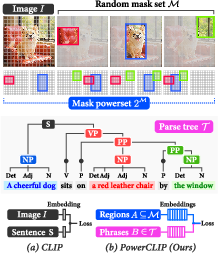
Figure 1: Overview of PowerCLIP's alignment strategy.
The framework integrates these NLAs into a three-phase process: extracting region embeddings from powersets, deriving phrase embeddings from textual parse trees, and aligning these using a composite loss function. The pipeline aims at minimizing a triplet margin loss based on bidirectional similarities, fostering better compositional understanding.
Experimental Results
Extensive experiments underscore PowerCLIP’s superiority over existing state-of-the-art methods. In zero-shot classification and retrieval tasks, the framework consistently outperformed its peers, demonstrating remarkable gains in compositional reasoning and robustness tests.

Figure 2: Performance comparison between PowerCLIP and other state-of-the-art methods, highlighting performance improvements in red.
The paper's extensive trials on diverse benchmarks validate the effectiveness of their approach. PowerCLIP achieved state-of-the-art performance across 22 of 28 evaluated benchmarks, significantly enhancing semantic delineations between image regions and textual components.
Theoretical Contributions
The core theoretical contribution is the introduction of NLAs, which provide computationally tractable approximations for powerset alignment. The paper provides proofs (Theorems 1 and 2) ensuring the aggregation method can approximate the exact loss with arbitrary precision. This development is crucial for enabling comprehensive alignment without the prohibitive computational cost traditionally associated with such comprehensive approaches.
Implications and Future Work
The implications of this research are significant for advancing multimodal machine learning capabilities. By improving the alignment comprehensively, PowerCLIP not only enhances current vision-LLMs but also sets a foundation for future advancements in complex scene interpretations and 3D spatial-semantic alignments.
Future work could extend PowerCLIP's methodology to 3D domains, emphasizing spatial alignment and semantic integration in more dynamic multimodal contexts. Such advancements could substantially enrich applications in augmented reality and real-time interactive systems.
Conclusion
PowerCLIP presents a substantial advancement in the field of contrastive pre-training for vision-language applications. Its innovative approach to powerset alignment offers a robust solution to existing compositionality challenges, bolstered by effective theoretical underpinnings and extensive empirical validations. This paper positions PowerCLIP as a leading methodology in the evolution of multimodal learning strategies, fostering more sophisticated interactions between textual cues and visual data.

