- The paper introduces a novel Mamba-DDQN framework that replaces traditional MLP layers with state-space models to better capture long-range dependencies in decentralized finance.
- It refines state, action, and reward representations using 32-dimensional features and variable liquidity position widths to optimize decision-making in volatile markets.
- Results show that Mamba-DDQN outperforms Buy-and-Hold and daily rebalancing strategies, yielding improved Profit-and-Loss metrics and robustness under rising market volatility.
Adaptive Dueling Double Deep Q-networks in Uniswap V3 Replication and Extension with Mamba
Introduction
This essay reviews the work detailed in "Adaptive Dueling Double Deep Q-networks in Uniswap V3 Replication and Extension with Mamba" (2511.22101), which addresses the application of deep reinforcement learning methods within decentralized finance, specifically through optimized liquidity provision on the Uniswap V3 platform. The study replicates the methods of the original research while extending them with a newly proposed Mamba-DDQN framework, which integrates Mamba's state-space models to capture long-range dependencies in the time series data inherent in DeFi environments.
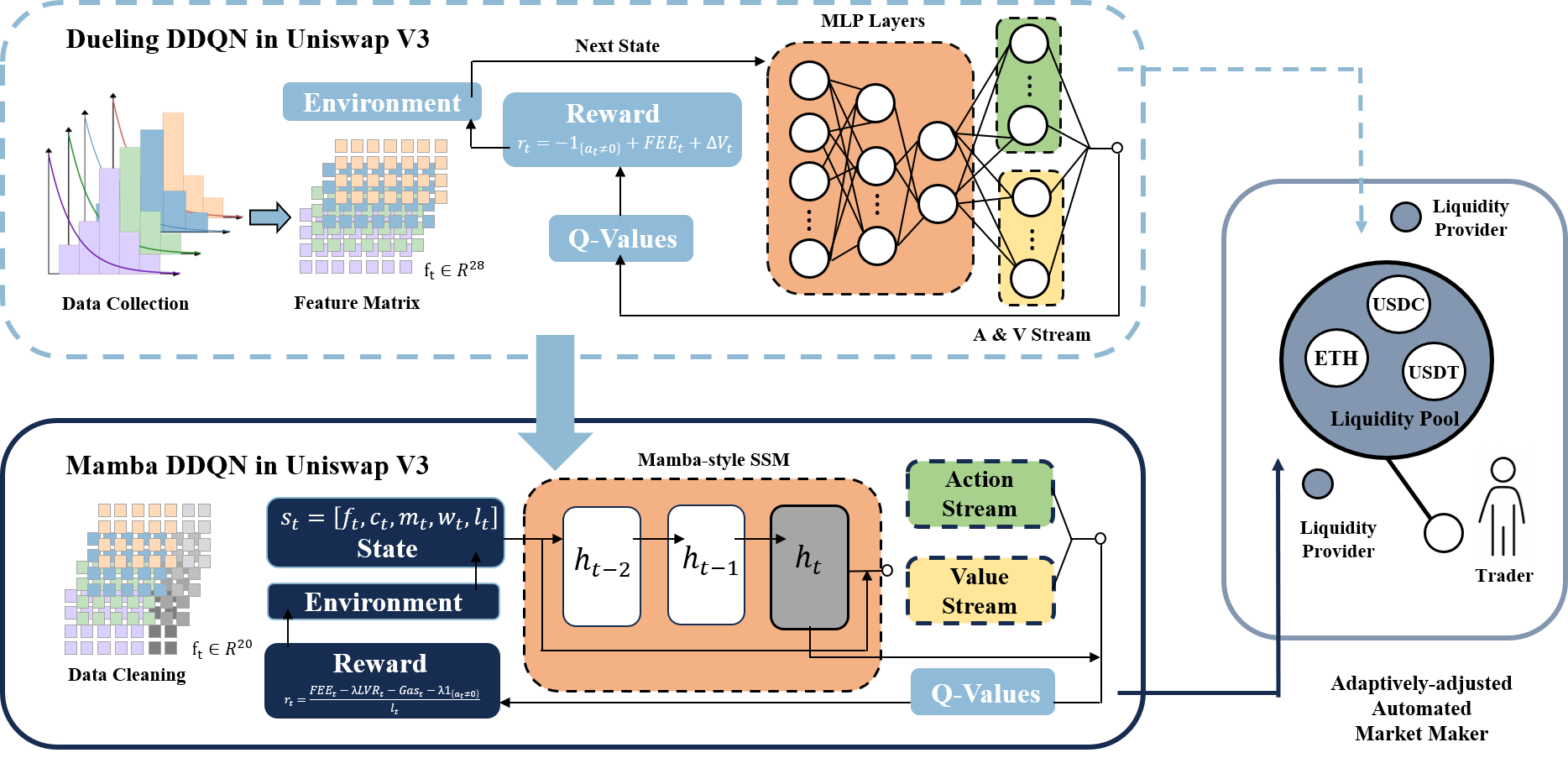
Figure 1: Overview of the work.
Replication of Dueling DDQN in Uniswap V3
The replication process commenced by sourcing historical data on ETH/USDC and ETH/USDT pools from The Graph. The paper meticulously recalculates necessary features such as contract_price and others not readily provided in the data snapshot. Following data cleaning processes to ensure each timestamp was represented once and devoid of NaN values, datasets were divided into training, validation, and testing periods according to the original paper's specifications.
Key enhancements in implementation involved refining state, action, and reward representations to align with market characteristics. States were defined over 32 dimensions including financial derivatives, while the action space varied liquidity position width. Unique to the reward function was an explicit accounting for liquidity versus rebalancing (LVR) alongside gas fee dynamics.
Modeling and Implementation
The core of the replication effort entailed deploying a Dueling DDQN architecture that improved liquidity provision strategies by evaluating action advantages separately from state values. This decoupling facilitated more nuanced policy learning over complex financial dynamics. An experience replay mechanism was central, utilizing a replay buffer to shuffle and learn from past transitions, thus alleviating bias from correlated observations.
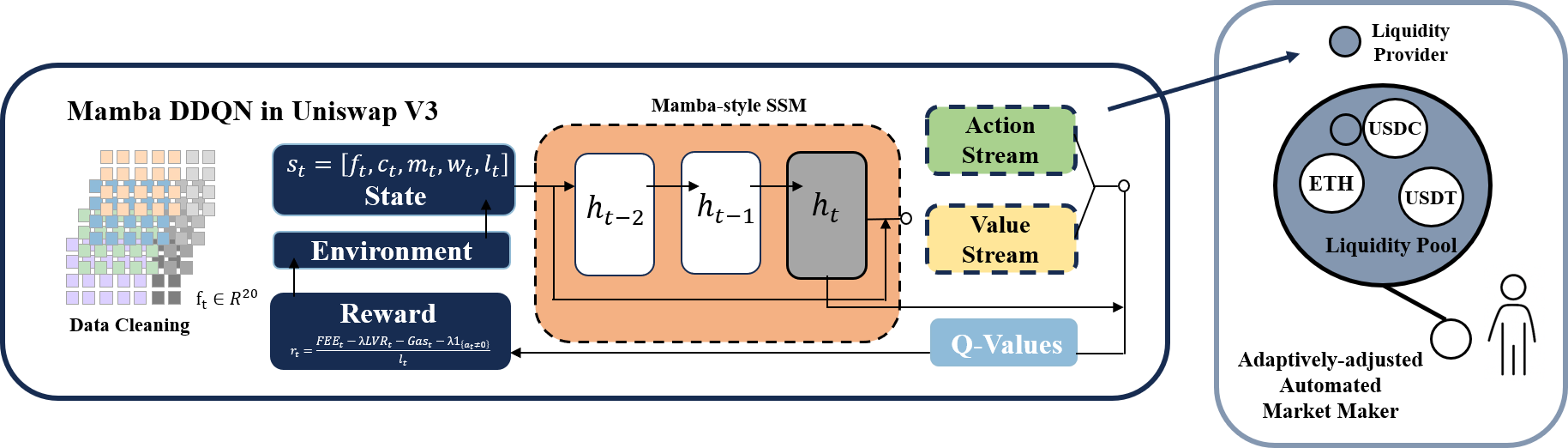
Figure 2: Framework of Mamba DDQN.
Novel Mamba-DDQN Framework
The paper extends the existing model by replacing the Dueling DDQN's MLP layers with state-space models from Mamba, enhancing the system’s ability to learn temporal dependencies and manage erratic market data. The Mamba’s capability in sequence modeling is particularly pertinent in DeFi's stochastic environment, where envisaging historical trends is crucial. Implementation-wise, the Mamba layer leverages a recurrent formulation that ingests fixed-length historical snapshots for informed decision-making.
Improvements in the new model also included feature pruning based on correlation analysis and conventional ML techniques like Lasso and ElasticNet. This refinement ensured that the resulting features were both independent and relevant, reducing noise and improving model focus.
Results and Evaluation
Replication of the original model confirmed consistency across several performance metrics, such as relative trading fees and LVR, although some variances were noted, possibly due to discrepancies in historical data snapshots and other stated or latent assumptions within the original protocols. Mamba-DDQN showcased superior performance in sustaining Profit-and-Loss metrics, particularly under rising l0 conditions, indicating its enhanced robustness and adaptability compared to Dueling DDQN.
New baseline evaluations against conventional Buy-and-Hold and Daily Rebalancing strategies illustrated the model's superior practical efficacy, particularly given the buy-and-hold's vulnerability to market volatility and daily rebalancing’s cost inefficiency in DeFi.
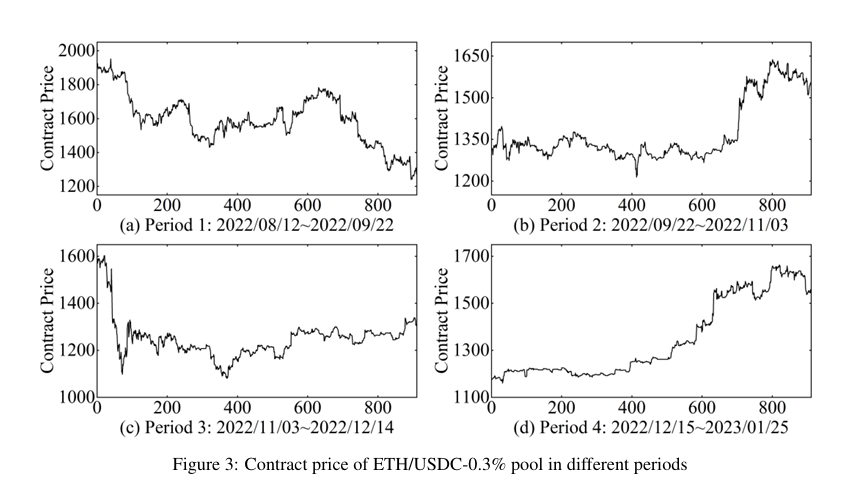
Figure 3: Origin figure.
Conclusion
This paper not only reconstructs but also meaningfully extends Dueling DDQN applications within Uniswap V3 by integrating Mamba's state-space models, thereby advancing the strategic trade-offs between computational fidelity and practical outcomes in liquidity provision. The proposed extensions elucidate pathways for future research, not only in enhancing reinforcement learning architectures but also in applying sophisticated sequence modeling techniques across DeFi ecosystems. Future prospects may explore the integration of novel architectures and learning paradigms to further optimize financial strategies in increasingly complex electronic markets.

