- The paper introduces an event-driven eligibility propagation algorithm that enables efficient, biologically plausible learning in large sparse spiking neural networks.
- It replaces synchronous updates with event-triggered weight adjustments, reducing computational overhead while maintaining performance on complex tasks.
- The approach scales to millions of neurons and supports both continuous dynamics and localized parameter dependencies to mimic brain-like activity.
Event-Driven e-prop in Large Sparse Networks: Efficiency and Biological Plausibility
Introduction and Context
The work "Event-driven eligibility propagation in large sparse networks: efficiency shaped by biological realism" (2511.21674) extends the eligibility propagation (e-prop) learning paradigm for recurrent spiking neural networks (SNNs) by translating it from the conventional time-driven setting to an event-driven formulation. Motivated by the sparse, asynchronous nature of biological brains and the computational demands of large-scale SNNs, the authors introduce an efficient event-driven e-prop algorithm, demonstrate its scalability, and align it more closely with biological constraints like continuous dynamics, strict locality, and sparse connectivity.
Technical Implementation
The core architectural shift involves replacing synchronous, stepwise weight updates with updates triggered asynchronously by events (spikes). Each synapse maintains an eligibility trace—a local variable tracking temporally filtered pre- and postsynaptic signals—while neurons maintain learning signal and surrogate gradient histories. Synaptic weight updates are performed by multiplying the eligibility trace (local credit assignment) with a global learning signal (error broadcasted from the output layer). This hybrid of time- and event-driven simulation allows substantial reduction in computational overhead in the regime of sparse activity.
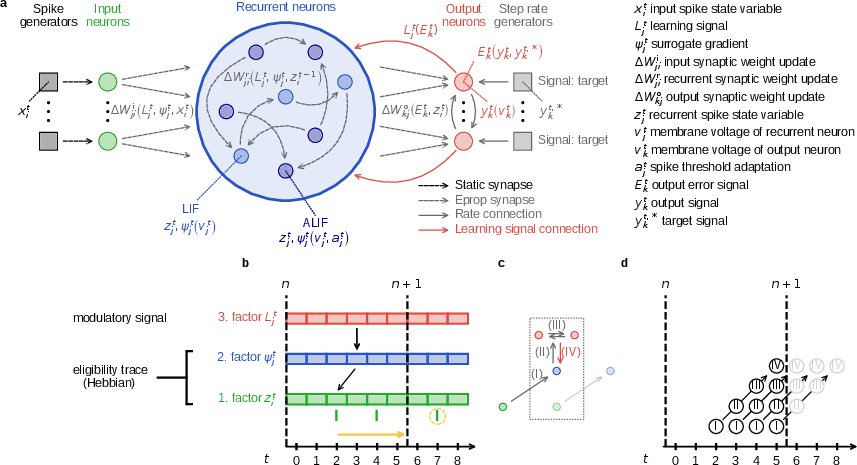
Figure 2: Mathematical structure and runtime pipeline of event-driven e-prop, including network and synaptic variable flows, trigger timings, and learning signal transmission.
The event-driven scheme introduces several innovations:
- Transmission delays between network layers and explicit pipeline modeling of spike and learning signal propagation.
- Mini-batch support via sample-archiving and sequential gradient accumulation, decoupling network state from global clock ticks.
- Efficient history management for postsynaptic variables, using only those required for triggered updates.
Empirical Validation and Comparison
The algorithm is validated across several tasks:
- Regression via temporal pattern generation.
- Classification via evidence accumulation (mimicking behavioral tasks).
- Large-scale, biologically relevant benchmarks with the N-MNIST dataset (converted vision data to spike events).
Direct comparison between time-driven and event-driven e-prop on regression and classification demonstrates that both methods yield essentially indistinguishable learning curves, with deviations only at the level of floating point noise or when minor differences induce divergent spike cascades due to network dynamics near the edge of chaos.
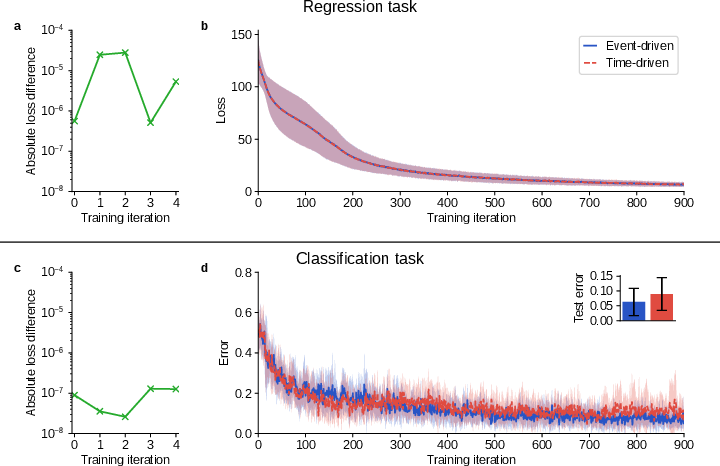
Figure 1: Comparison of learning trajectories and loss evolution between time-driven and event-driven models on simple regression and classification tasks.
For N-MNIST, event-driven e-prop attains classification accuracy and convergence speed on par with time-driven reference implementations.
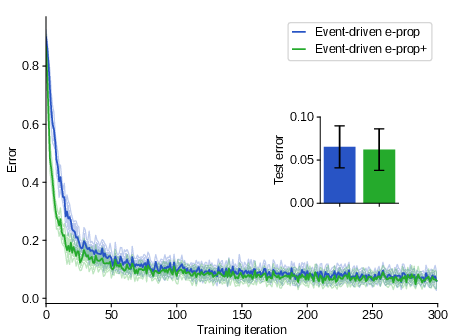
Figure 3: Learning curve for event-driven e-prop (and its biologically augmented version) on the N-MNIST task, demonstrating effective learning and comparable final errors.
Biological Enhancements and Plausibility
To further increase biological relevance, the authors introduce an enhanced version (symbol "+") incorporating:
- Continuous temporal dynamics, avoiding sample boundary resets.
- Local-only parameter dependencies, e.g., removing filter parameter coupling between eligibility traces and output time constants.
- Exponential moving average for firing rate regularization.
- Synaptically driven weight updates, triggered by every spike or inter-spike interval, aligning with STDP/biological plasticity mechanisms.
- Surrogate gradient functions with increased smoothness, as seen in some neuro-inspired models.
After training, class output neurons show correct stimulus selectivity, and major synaptic weight changes are concentrated in input and recurrent connections, consistent with task demands.
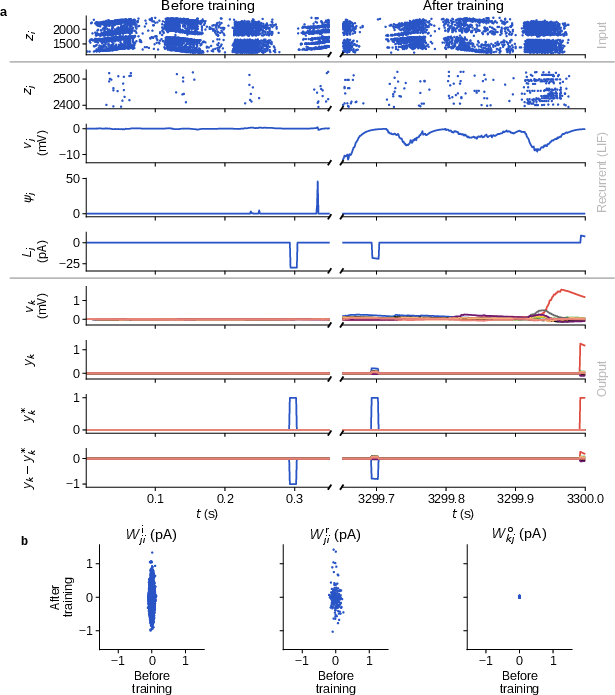
Figure 4: Dynamics (spike rasters, membrane potentials, learning signals) and synaptic weight adaptation before and after N-MNIST training in the biologically augmented model.
Strong and weak scaling experiments demonstrate effective distributed parallelization, with near-linear (weak) and sub-linear (strong) scaling observed for up to two million neurons. The third factor in plasticity rules introduces a modest runtime overhead versus pairwise (STDP) rules.
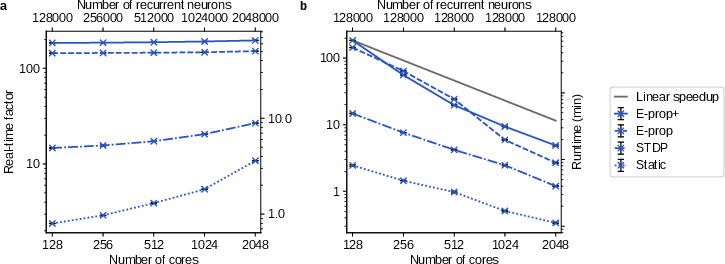
Figure 5: Parallel scaling properties of event-driven e-prop: wall-clock time and simulation speed versus number of compute cores, indicating scalability for large SNNs.
Theoretical and Practical Implications
The results empirically support the assertion that biologically grounded constraints (asynchrony, locality, event-driven updates, continuous dynamics) do not incur a learning performance penalty in SNNs—on several metrics, learning speed and accuracy are maintained or even improved under stricter constraints. The methodology enables scaling to millions of neurons and billions of synapses, making it suitable for simulations approaching mammalian cortex microcircuit scale, and facilitating future investigations into brain-like computation and learning at scale.
The elimination of global synchrony and fixed time grids enables SNNs to process variable-duration input samples, broadening real-world application potential. In addition, the implementation within the NEST simulation environment lowers the barrier for widespread neuroscientific adoption and benchmarking, potentially bridging the gap between theoretical neurobiology and scalable AI.
Future Prospects in AI and SNNs
This work positions event-driven e-prop as a foundational algorithm for future bio-inspired AI, especially in neuromorphic hardware and distributed simulation contexts. The event-driven paradigm opens the door to further reduction in energy and compute requirements, a crucial step for sustainable, scalable AI. Integrating reward-based variants, multi-factor plasticity rules, and neuromodulation could allow for more sophisticated, adaptive autonomous systems.
On a theoretical level, the study highlights the potential for further principled reductions of machine learning algorithms to biologically plausible forms without compromising functional efficacy. The approach encourages future research focused both on rigorous neuroscientific modeling and on developing deployable, resource-efficient AI systems.
Conclusion
The event-driven implementation of e-prop demonstrates that strict adherence to biological realism—incorporating asynchrony, locality, and plausible dynamics—yields SNNs that are both scalable and performant. The framework maintains competitive learning dynamics across diverse tasks and supports simulation of very large, sparse networks on modern compute clusters. These advances provide a substantive step toward both understanding brain-like learning and enabling high-performance, sustainable AI leveraging spiking computation.

