Beyond URLs: Metadata Diversity and Position for Efficient LLM Pretraining
Abstract: Incorporating metadata in LLMs pretraining has recently emerged as a promising approach to accelerate training. However prior work highlighted only one useful signal-URLs, leaving open the question of whether other forms of metadata could yield greater benefits. In this study, we investigate a wider range of metadata types and find other types of metadata, such as fine-grained indicators of document quality that can also accelerate pretraining when prepended. We identify a common feature among effective metadata: they encode information at a finer granularity. We further introduce metadata appending as a means of improving training efficiency, where predicting an appropriate metadata as auxiliary task can help speed up pretraining. In addition, learnable meta-tokens trained with masked loss can recover part of the speedup by inducing quality-aware latent structure. Using probing, we analyze latent representations to understand how metadata shapes learning. Together, these results yield practical guidelines for integrating metadata to improve both the efficiency and effectiveness of LLM pretraining.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of “Beyond URLs: Metadata Diversity and Position for Efficient LLM Pretraining”
1) What is this paper about?
This paper is about teaching LLMs faster by giving them extra hints called “metadata” while they learn. A URL (like “https://en.wikipedia.org/...”) is one example of metadata. The authors ask: are there other kinds of hints, and other ways to add them, that help models learn more quickly and better?
2) What questions do the authors try to answer?
- Which kinds of metadata help most, besides URLs?
- Does being more specific (fine‑grained) or more general (coarse‑grained) make a difference?
- Is it better to put the metadata at the start of a document (prepend) or at the end (append)?
- Can we create special learnable “meta tokens” that act like blank sticky notes the model learns to use?
- How does metadata change what the model stores in its “hidden notes” (its internal representations)?
3) How did they study this? (Methods in simple terms)
- The team trained a medium‑sized LLM on lots of web text. During training, they added different kinds of metadata to each document in two ways:
- Prepending: putting metadata before the text, like a label at the top.
- Appending: putting metadata after the text, like a mini‑quiz where the model must guess the label at the end.
- Types of metadata they tried:
- URL (the web address)
- Quality score of the document:
- Coarse‑grained: rough categories (like 3, 4, or 5)
- Fine‑grained: more precise numbers (like 25–50)
- Domain information (what the text is about and its format):
- Coarse‑grained: chosen from a fixed set of categories
- Fine‑grained: open‑ended, more detailed labels
- Learnable meta tokens: five new special tokens with no meaning at first; the model learns how to use them.
- Two important setup details:
- For prepending, they didn’t ask the model to predict the metadata tokens (so those tokens didn’t affect the training loss).
- For appending, they did ask the model to predict the metadata at the end (turning it into a small extra task, called an “auxiliary task”).
- Measuring progress:
- They tested the model on standard question‑answering and reasoning benchmarks to see how good it became as it trained.
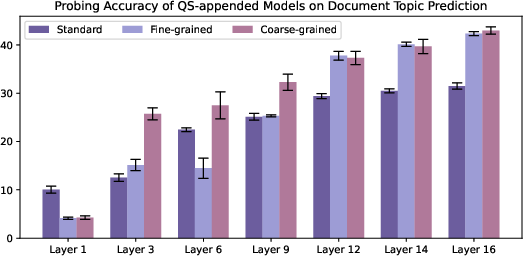
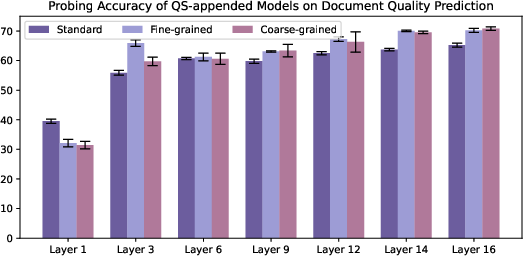
- They also checked “attention” (what the model focuses on) and used “probing” (simple classifiers that read the model’s internal states) to see what information the model learned inside, like topic, quality, and writing style.
Helpful analogies:
- Token: a small piece of text (like a word or part of a word).
- Attention: what the model is “looking at” while reading.
- Probing: a quick quiz of the model’s hidden notes to see what it understands.
- Auxiliary task: an extra mini‑task (like “guess the document’s quality”) that helps the model learn better representations.
4) What did they find, and why does it matter?
Here are the key takeaways, with brief reasons they matter:
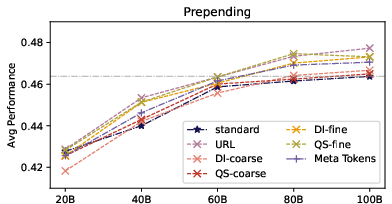
- Fine‑grained metadata at the start speeds up learning; coarse metadata does not.
- Think of a detailed label like “biology—cell division—tutorial” vs. a vague label like “science.” The detailed one helps the model organize information better.
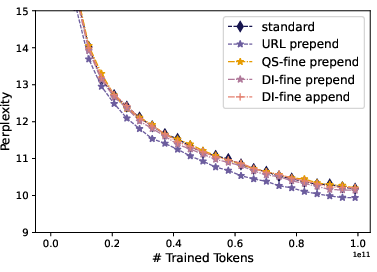
- In their tests, prepending fine‑grained quality scores and fine‑grained domain info sped up training similarly to URLs. For example, some runs matched the performance of a 100B‑token baseline after only about 60B tokens.
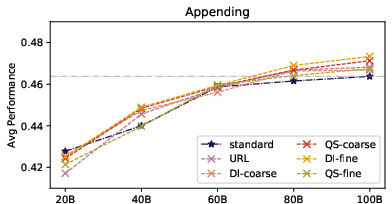
- Appending metadata (asking the model to predict it) can also help—especially for fine‑grained domain info and coarse quality scores.
- This “mini‑quiz” encourages the model to summarize the important parts internally.
- However, making the quiz too specific (like very fine‑grained quality scores) can distract the model, helping it ace the quiz but not helping as much on other tasks.
- Combining helpful metadata (like URL + fine‑grained quality) did not produce additive gains at the end.
- It sped up learning early on but didn’t end better than using either metadata alone.
- Not all parts of a URL help equally.
- The model often focuses a lot on the URL prefix (“https://”), but that part isn’t what boosts performance.
- The domain (like “en.wikipedia.org”) and the rest of the path (the page name) are the useful parts, and they work together.
- Faster training loss doesn’t always mean better real‑world performance.
- Training loss dropped faster with URL prepending, but for other metadata the link between loss and task performance was weak.
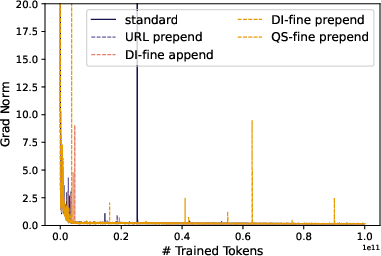
- Still, using metadata tended to make training more stable (fewer big spikes in gradients).
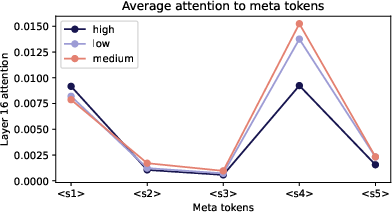
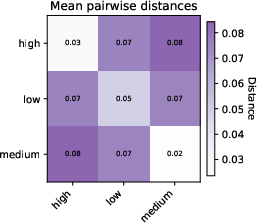
- Learnable meta tokens (blank sticky notes) also helped a bit.
- Even without built‑in meaning, the model learned to use them to sort documents by quality. Different quality levels produced distinct attention patterns to these tokens.
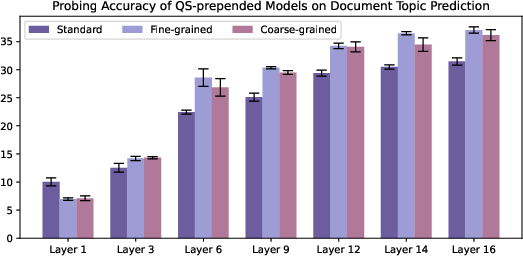
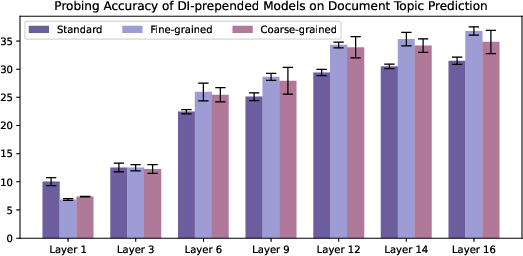
- Metadata changes what the model stores inside.
- Probing showed that including URLs (prepended or appended) improved the model’s internal sense of writing style and quality.
- Fine‑grained domain labels also improved style/topic signals in the model’s hidden layers.
Why this matters: Training LLMs is very expensive. If adding the right kind of tiny hints reduces the number of tokens needed by 20–40% (in some cases), that saves time, money, and energy, while keeping or improving quality.
5) What’s the impact? (Why should we care?)
- Practical guidelines for training LLMs:
- Use detailed (fine‑grained) metadata when prepending to the text.
- If prepending isn’t possible, appending fine‑grained domain labels or coarse quality scores as a mini‑quiz can still help.
- Don’t overcomplicate auxiliary tasks: extremely fine‑grained scores can distract from broader learning.
- Consider a small dropout (occasionally leaving out metadata) so the model doesn’t become dependent on it.
- If you don’t have clean metadata, learnable meta tokens can still give a smaller but real boost by letting the model invent useful “labels” internally.
- Bigger picture:
- Smart use of metadata can cut training costs and improve how models organize knowledge.
- It may also make models easier to steer (e.g., by topic, style, or quality).
- Open questions remain: Can metadata also improve later stages like fine‑tuning? And exactly why do certain metadata types work better? This paper offers strong clues and practical recipes, but invites more research to fully understand the “why.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following gaps remain unresolved and suggest concrete directions for future work:
- Scaling and generalization: Validate whether the observed acceleration holds for larger models (e.g., 7B–70B+ parameters), different architectures (MoE, GQA/MQA), and diverse corpora (Dolma, RedPajama, multilingual, code, books), beyond the single 1.5B model and FineWeb-Edu used here.
- Compute accounting: Quantify FLOP-normalized and wall-clock gains, including the overhead of extra metadata tokens, to determine true efficiency improvements per unit compute rather than per training token.
- Inference dependency and cool-down: Test cool-down or metadata-removal stages and measure whether prepended/appended metadata induces inference-time dependence; characterize performance when metadata is absent or partially available at inference.
- Position and integration strategies: Systematically compare additional integration schemes (mid-document repeats, segment headers, side-channels, retrieval-style metadata, multiple placements) beyond prepend/append, and analyze their trade-offs.
- Metadata dropout schedule: Vary and ablate the fixed 10% metadata dropout (rate, curriculum, stochastic scheduling) to determine optimal exposure and robustness.
- Multi-metadata composition: Study how to combine multiple helpful metadata types (e.g., URL + QS-fine + DI-fine), including joint vs. alternating conditioning, learned weighting, and potential interference; the non-additivity observed for URL + QS-fine remains unexplained.
- Granularity vs. noise: Disentangle the benefits of “fine granularity” from label noise by constructing controlled granular labels with known noise levels; measure how granularity, entropy, and noise interact to produce acceleration.
- Label provenance and quality: Audit DI-fine and QS labels generated by LLMs/regressors for bias, noise, and domain coverage; quantify their accuracy and reliability and how this affects training dynamics and downstream results.
- Auxiliary loss design: For appending, explore loss weighting, label smoothing, uncertainty-aware weighting, and multi-task schedules to mitigate over-specialization (e.g., QS-fine) while preserving generalization.
- URL component causality: Extend URL-part ablations beyond attention correlates—test causal interventions (e.g., domain+suffix without prefix, synthetic shuffles, adversarial edits) to identify which components drive gains and why attention sinks on prefixes do not translate to performance.
- Attention sink mitigation: Evaluate techniques to reduce attention sinks (e.g., sink token suppression, positional reweighting, special-token masking) and measure whether this improves metadata utilization and downstream performance.
- Learnable meta tokens: Systematically vary the number, placement, training objective (masked vs. supervised), and regularization of meta tokens; test whether they can encode other latent axes (topic, time, format) and whether their clusters are stable and controllable.
- Long-context behavior: Assess how metadata effects change with much longer sequences (>4k), document splitting strategies, and cross-chunk metadata propagation.
- Data selection synergy: Measure how metadata conditioning interacts with data filtering/selection (perplexity-based, importance weighting, deduplication levels); identify whether metadata can replace or complement learned selection.
- Representation mechanisms: Go beyond simple MLP probes—use CKA/CCA, mutual information estimates, head-level interpretability, and subspace analyses to explain how metadata reshapes geometry, reduces interference, and alters transfer.
- Stability and optimization: Replicate gradient-norm stabilization across seeds and setups; test optimizer variants, schedules, and regularizers to confirm whether metadata consistently reduces training instabilities.
- Evaluation breadth: Include generative tasks (factuality, long-form QA), safety/toxicity, calibration, attribution, and controllability metrics to understand broader impacts of metadata conditioning, not just multiple-choice benchmarks.
- Fairness and bias: Investigate whether metadata like URLs, domains, or LLM-derived quality scores introduce or amplify biases (domain, geography, language), and develop mitigation strategies.
- Post-training and finetuning: Evaluate whether metadata can improve SFT/RLHF efficiency, alignment, and controllability, and whether metadata-aware pretraining benefits persist through post-training.
- Reproducibility: Release code, prompts (e.g., DI-fine), and ablation scripts; report seed variance for all configurations and provide precise dataset splits for probes to facilitate reproducible comparisons.
Practical Applications
Immediate Applications
Below is a concise set of actionable applications that can be deployed now, derived from the paper’s findings on metadata types, positions, and training dynamics. Each item includes sector tags and key assumptions or dependencies affecting feasibility.
- Accelerate LLM pretraining by prepending fine-grained metadata (software/AI infrastructure)
- Description: Prepend fine-grained URL, quality score (QS-fine), or domain information (DI-fine) wrapped in
<boc> ... <eoc>, mask these tokens from the loss, and apply ~10% dropout to achieve substantial token savings (e.g., reaching 100B-token baseline with ~60–80B tokens; 20–40% savings contextualized by prior URL-only work). - Tools/products/workflows: “Metadata Injector” module for Megatron-LM/PyTorch training loops; tokenizer updates to add
<boc>/<eoc>; masking utilities; training config templates. - Assumptions/dependencies: Availability of reliable fine-grained metadata (URLs retained, quality regressor outputs, DI-fine via Llama-3.1 or equivalent); compatibility with current data pipeline; masking implemented correctly; inference “cool-down” or prefix-removal strategy if needed.
- Description: Prepend fine-grained URL, quality score (QS-fine), or domain information (DI-fine) wrapped in
- Use metadata appending as an auxiliary prediction task (software/AI infrastructure; education)
- Description: Append DI-fine or QS-coarse at sequence end and include their loss for backprop so the model learns to predict metadata, yielding modest but consistent acceleration (about 20% fewer tokens to match standard training).
- Tools/products/workflows: “Auxiliary Metadata Head” for prediction; evaluation hooks to verify predictive accuracy; training recipes for appending.
- Assumptions/dependencies: Auxiliary loss must not dominate (risk of over-specialization with QS-fine); correctly balanced training objective; high-quality labels for DI-fine or QS-coarse.
- Deploy learnable meta-tokens to recover part of metadata speedup when labels are unavailable (software/AI infrastructure; data ops)
- Description: Add a small set of new tokens (e.g.,
<s1>…<s5>) prepended and masked from loss to induce quality-aware latent clustering and partial efficiency gains. - Tools/products/workflows: “MetaToken Learner” module; attention auditing scripts; quality-aware gating in data loaders.
- Assumptions/dependencies: Requires careful monitoring to ensure learned tokens capture meaningful structure; consistent insertion strategy and dropout.
- Description: Add a small set of new tokens (e.g.,
- Improve training stability by integrating masked prepended metadata (software/AI infrastructure; energy/sustainability)
- Description: Reduce loss spikes and gradient instability during pretraining by introducing masked metadata conditioning, yielding smoother optimization and lower compute waste.
- Tools/products/workflows: Stability dashboards; gradient norm monitors; “Training Stability Guardrails” integrating metadata and schedulers.
- Assumptions/dependencies: Stability gains may be setup-dependent; benefits observed with 1.5B Llama-like models and FineWeb-Edu.
- Avoid attention-sink pitfalls in URL conditioning (software/AI infrastructure; data ops)
- Description: Do not rely on URL prefixes alone; ensure both domain and suffix components are included because they provide complementary, performance-relevant signals despite lower raw attention weights.
- Tools/products/workflows: “Attention Sink Checker” to detect attention sinks; URL-component ablation tests; policy to retain domain/suffix even if prefix is stripped.
- Assumptions/dependencies: Datasets must store full URLs; privacy and policy compliance for URL retention.
- Quality-aware data curation for educational or enterprise corpora (education; enterprise data ops)
- Description: Use QS-fine to prioritize high-value content and DI-fine to balance topic/format coverage; integrate these as conditioning/appending signals to save tokens and improve downstream performance.
- Tools/products/workflows: WebOrganizer (DI-coarse) and Llama-3.1-based DI-fine labeling; quality regressors; “Decanting” pipelines that incorporate metadata conditioning.
- Assumptions/dependencies: Label quality and granularity strongly affect gains; deduplication integrity; adequate compute to run classifiers/generators for metadata.
- Latent representation auditing and robustness checks via probing (academia; model governance)
- Description: Run layer-wise probes for topic, quality, and authorship to understand how metadata reshapes representations, informing dataset design, curriculum, and compliance audits.
- Tools/products/workflows: “Latent Probe Suite” (MLP probes per layer); dashboards for task-specific probe accuracy and changes across training checkpoints.
- Assumptions/dependencies: Requires curated probe datasets (e.g., DI-coarse, QS-coarse/fine, authorship corpora); probes must be carefully validated.
- Sector-specific domain steering in pretraining (healthcare; finance; software engineering)
- Description: Prepend fine-grained domain tags (clinical subdomain, financial instrument/ticker, programming language/framework) to shape learned representations, improving controllability and possibly efficiency in vertical LLMs.
- Tools/products/workflows: Domain taxonomies and labelers; sector-specific metadata schemas; controllability evaluation harnesses.
- Assumptions/dependencies: High-quality, fine-grained domain labels; risk of over-narrow specialization; compliance constraints (e.g., PHI in healthcare).
- Provenance and attribution improvements using appended URLs (policy/compliance; publishing)
- Description: Append source identifiers to enable post hoc attribution or intrinsic citation features, leveraging auxiliary prediction capabilities.
- Tools/products/workflows: “Source-Aware Training” add-on; provenance logs; inference-time citation utilities.
- Assumptions/dependencies: Legal/ethical policies for URL/provenance use; need to balance attribution features with pretraining performance goals.
- Energy and cost reporting tied to token savings (energy/sustainability; enterprise ops)
- Description: Quantify reductions in tokens (and thereby FLOPs) from metadata conditioning/appending, integrate into sustainability reports and cost models.
- Tools/products/workflows: “Carbon/Cost Calculator” that estimates emissions and spend saved when adopting metadata-aware pretraining.
- Assumptions/dependencies: Accurate mapping from tokens to energy; consistent hardware efficiency baselines; organizational willingness to report.
Long-Term Applications
The following applications require further scaling studies, standardization, or development to realize their full potential.
- Metadata-aware routing in Mixture-of-Experts (software/AI infrastructure; architecture)
- Description: Use fine-grained metadata or learned meta-tokens as routing signals to select experts, potentially compounding pretraining efficiency and domain specialization.
- Tools/products/workflows: “MetaRouter” for MoE; co-training of routers with metadata.
- Assumptions/dependencies: Needs large-scale validation; careful balance to avoid overfitting to metadata; router stability under noisy labels.
- Self-supervised metadata inference at scale (software/AI infrastructure; academia)
- Description: Replace or supplement explicit labels with learned meta-tokens and attention patterns to infer quality/domain clusters automatically and gain speedups without curated metadata.
- Tools/products/workflows: “Metadata-by-Discovery” training regimes; cluster consistency monitors.
- Assumptions/dependencies: Risk of spurious clustering; needs robust evaluation; sector-specific validation.
- Standardized, fine-grained metadata schemas for open corpora (policy/standards; data ops)
- Description: Cross-ecosystem standards for domain, format, quality, time, and provenance to unlock interoperable metadata-conditioning pipelines and comparability across LLMs.
- Tools/products/workflows: Community-driven “Metadata Schema Consortium”; validation suites; dataset cards with mandatory metadata fields.
- Assumptions/dependencies: Broad adoption; governance and privacy safeguards; harmonization with existing datasets (Dolma, FineWeb, RefinedWeb).
- Quality-aware curricula and schedulers (software/AI infra; education)
- Description: Curriculum learning that stages data by QS-fine and DI-fine to optimize learning dynamics (e.g., starting with high-quality, expanding to diverse domains then cooling down).
- Tools/products/workflows: “Quality Curriculum Planner” integrating schedulers and label distributions.
- Assumptions/dependencies: Requires strong empirical tuning; potential domain bias; interaction with warm-up and cosine schedules.
- Inference steerability via metadata controls (product features; safety)
- Description: Expose user-facing knobs (quality, domain, style) learned during pretraining to steer outputs at inference without harming generalization.
- Tools/products/workflows: “Domain/Quality Knobs” APIs; guardrails for misuse.
- Assumptions/dependencies: Needs reliable cool-down strategies so models don’t over-depend on metadata; safety evaluations to prevent bias amplification.
- Provenance-first LLMs with intrinsic citation (policy/compliance; publishing)
- Description: Combine appended metadata with post-training alignment to produce models that can cite pretraining sources and support audit trails.
- Tools/products/workflows: “Intrinsic Citation” inference modules; provenance registries.
- Assumptions/dependencies: Legal/IP frameworks; user trust; consistent retention of source identifiers.
- Attention-pattern analytics for data QA and bias detection (academia; governance)
- Description: Leverage attention signatures to detect quality clusters, anomalies, or bias in training data before/while training, using learned meta-tokens or explicit metadata.
- Tools/products/workflows: “Attention Forensics” dashboards; anomaly and bias detectors.
- Assumptions/dependencies: Robustness of attention as a diagnostic; may require complementary probes/metrics.
- Sector-scale vertical pretraining programs (healthcare; finance; software engineering; robotics)
- Description: Build large vertical LLMs preconditioned on fine-grained sector metadata (e.g., clinical subspecialties; instrument classes/time slices; code ecosystems; task domains) to cut costs and improve domain fidelity.
- Tools/products/workflows: Vertical taxonomies; labeling pipelines; sector-specific evaluation harnesses.
- Assumptions/dependencies: Privacy, compliance (HIPAA, financial regulations); reliable fine-grained labels; domain shift management.
- Streaming/time-aware pretraining using temporal metadata (software/AI infrastructure; finance; news/media)
- Description: Integrate timestamps and time-sliced domain metadata to maintain recency and reduce catastrophic forgetting.
- Tools/products/workflows: “Time-Aware Router” and schedulers; time-slice datasets.
- Assumptions/dependencies: Requires careful evaluation of temporal drift; may interact with appending/prepending strategies.
- Benchmarking and scaling laws for metadata conditioning (academia; software/AI infrastructure)
- Description: Establish robust scaling studies across model sizes (1.5B → 70B+), contexts, and datasets to quantify when metadata yields gains, and why loss curves may not correlate with downstream improvements.
- Tools/products/workflows: Metadata-conditioned LM-Eval Harness extensions; reproducible protocol packs.
- Assumptions/dependencies: Access to large-scale compute and diverse corpora; community consensus on metrics.
- Organizational policies for metadata retention and privacy (policy; legal/compliance)
- Description: Define norms for retaining/using URLs and provenance during training, balancing performance with privacy/IP constraints and transparency.
- Tools/products/workflows: “Metadata Governance Playbook”; retention policies; privacy audits.
- Assumptions/dependencies: Evolving regulatory environment; internal risk appetite; contractual obligations with data providers.
Glossary
- Appending (metadata appending): Placing metadata at the end of a sequence so the model learns to predict it; used as an auxiliary objective to improve efficiency. "We introduce and evaluate metadata appending as a method for accelerating pretraining"
- Attention sink: Tokens that attract disproportionate attention due to position or consistency, without providing useful signal. "which can act as an “attention sink” without providing a meaningful signal for the task"
- Auxiliary task: A secondary prediction objective trained alongside the main language modeling objective. "where predicting an appropriate metadata as auxiliary task can help speed up pretraining"
- Beginning-of-context (<boc>): Special token marking the start of the metadata segment within a sequence. "metadata is wrapped between beginning-of-context (<boc>) and end-of-context (<eoc>)"
- Control codes: Explicit tokens indicating attributes (e.g., domain or date) to steer model generation. "CTRL conditions on control codes derived from data structure (domain, dates, etc.) to steer generation"
- Cool-down phase: A phase where conditioning signals are removed to ensure the model no longer depends on them at inference. "with a “cool-down” phase to remove the dependency at inference"
- Cosine scheduler: A learning-rate schedule that decays following a cosine curve. "We use cosine scheduler with a maximum learning rate of 3e-4"
- Decanting: Aggressive data curation and filtering applied to web crawls to improve dataset quality. "scales this idea to \textasciitilde15T tokens with stronger decanting and deduplication at crawl-snapshot scale"
- Deduplication: Removing near-duplicate content to reduce redundancy and improve training efficiency. "scales this idea to \textasciitilde15T tokens with stronger decanting and deduplication at crawl-snapshot scale"
- Domain Information (DI): Labels describing a document’s topic and format domains used for conditioning or analysis. "In total, we have 576 different Domain Information types"
- End-of-context (<eoc>): Special token marking the end of the metadata segment within a sequence. "metadata is wrapped between beginning-of-context (<boc>) and end-of-context (<eoc>)"
- Grouped-Query Attention (GQA): Attention variant that groups KV heads to reduce cache and bandwidth costs. "Grouped-Query Attention (GQA, \citet{ainslie2023gqa}) share or group KV heads to reduce KV cache and bandwidth costs;"
- KV cache: Stored key/value tensors used to speed attention computation and reduce memory traffic. "reduce KV cache and bandwidth costs"
- Layer-wise probing: Technique that trains simple classifiers on representations from each layer to analyze encoded information. "We conduct layer-wise probing of latent representations for topic, quality, and authorship"
- LM-Eval-Harness: A framework for standardized few-shot evaluation of LLMs on multiple benchmarks. "we evaluate models on general knowledge understanding using LM-Eval-Harness"
- Masked loss: Training setup where loss on specified tokens (e.g., metadata) is excluded from backpropagation. "learnable meta-tokens trained with masked loss can recover part of the speedup by inducing quality-aware latent structure"
- Megatron-LM: A framework for efficient large-scale training of transformer LLMs. "we use the Megatron-LM framework"
- Meta tokens: Learnable special tokens prepended to sequences that can encode latent structure via attention. "We introduce five new meta tokens, <s1> through <s5>."
- Metadata conditioning: Prepending metadata tokens so the model conditions its representation learning on document attributes. "Recent work formalizes this idea as “metadata conditioning,”"
- Mixture-of-Experts (MoE): Architecture activating a sparse subset of expert modules per token to scale capacity efficiently. "Sparse Mixture-of-Experts architectures (e.g., Switch Transformer,~\citet{fedus2022switch}) activate only a small subset of parameters per token"
- Multi-Query Attention (MQA): Attention variant sharing key/value across multiple query heads to reduce memory and bandwidth. "Multi-Query Attention (MQA, \citet{shazeer2019fasttransformerdecodingwritehead}) and Grouped-Query Attention (GQA, \citet{ainslie2023gqa}) share or group KV heads to reduce KV cache and bandwidth costs;"
- Perplexity: A metric reflecting LLM loss; lower values indicate better modeling of the data. "we show the training perplexity curves for all runs that outperform the standard pretraining"
- Prepending (metadata prepending): Adding metadata at the start of sequences during pretraining while masking its loss. "In the metadata-prepending setup, we mask the metadata tokens from the loss both for reporting and during backpropagation"
- Routing by query time: Directing inputs to experts based on timestamps to improve temporal awareness. "pretrain experts on time-sliced corpora with routing by query time, boosting time awareness while preserving downstream performance"
- Source-Aware Training: Method injecting document identifiers to enable attribution and citation of pretraining sources. "Source-Aware Training injects document IDs in a light post-pretraining stage to enable intrinsic citation of pretraining sources"
Collections
Sign up for free to add this paper to one or more collections.