- The paper presents a novel dual-path autoencoder framework that achieves near-perfect attack success rates while preserving audio quality.
- It demonstrates robust transferability by effectively removing watermarks from both speech (LibriSpeech) and music (FMA) domains.
- Ablation studies confirm that omitting key losses, such as psychoacoustic and adversarial components, significantly degrades performance.
HarmonicAttack: An Adaptive Cross-Domain Audio Watermark Removal
Introduction and Motivation
The proliferation of AI-generated audio, fueled by recent advances in generative models, has introduced critical security risks including large-scale voice-cloning fraud and misinformation. Audio watermarking methods such as AudioSeal, WavMark, and Silentcipher have emerged as central defenses by enabling detectors to distinguish AI-generated audio from genuine speech or music. However, robust assessment of watermark resilience mandates the development and evaluation of effective removal attacks operating under realistic threat models. HarmonicAttack presents a learning-based watermark removal framework that exploits both temporal and spectral representations and generalizes across watermarking schemes and data domains.
HarmonicAttack Architecture and Training Paradigm
HarmonicAttack comprises an adversarial generator-discriminator framework with two principal innovations: a dual-path autoencoder generator and a GAN-style discriminator. The generator integrates a waveform encoder for temporal feature extraction and a spectrogram encoder for time-frequency analysis. These encoder pathways converge in a shared bottleneck, feeding into an attention-based decoder to reconstruct audio with watermarks removed. The discriminator guides the generator toward perceptual fidelity and watermark suppression by distinguishing between generator output and clean audio, co-trained in an adversarial regime inspired by GANs.
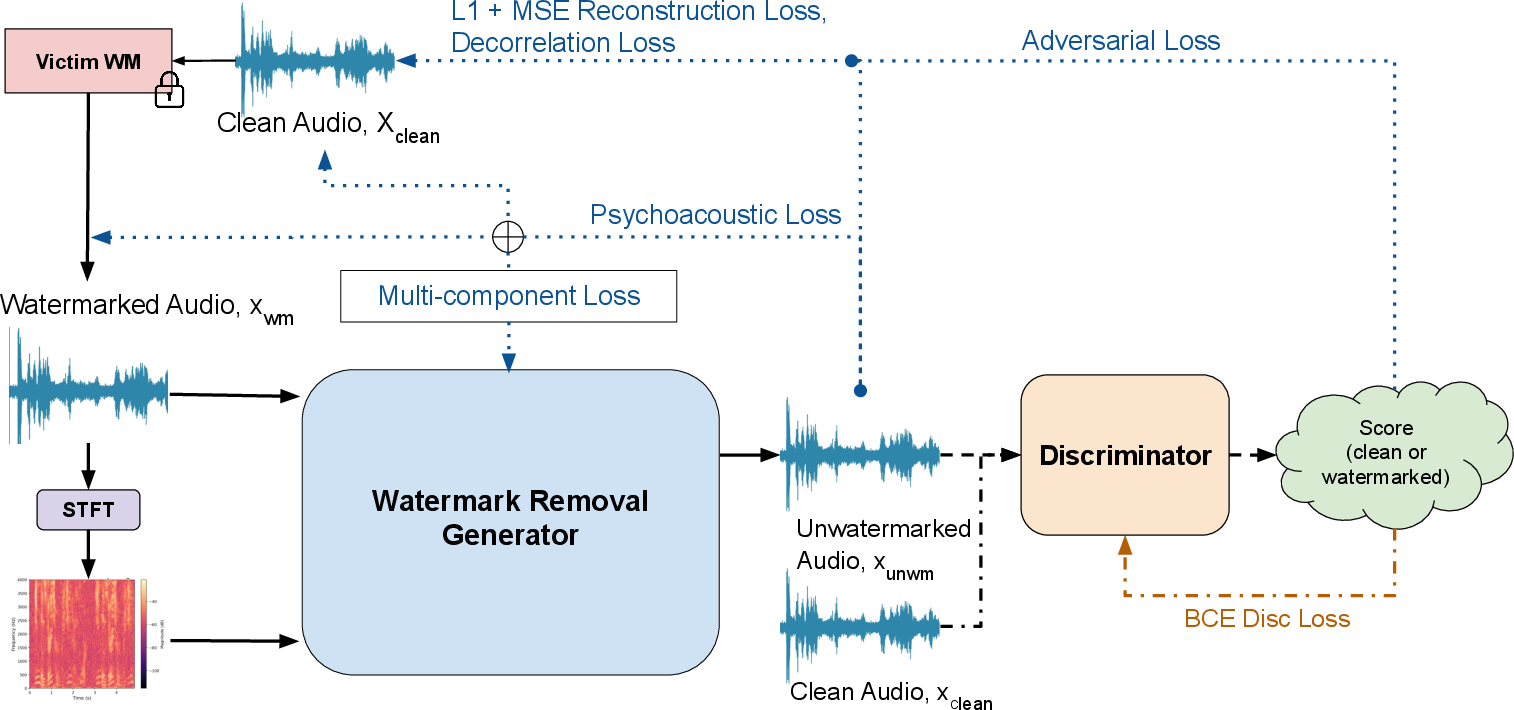
Figure 1: HarmonicAttack's overview—dual-path autoencoder generator and GAN-style adversarial discriminator jointly facilitate watermark removal with perceptual quality preservation.
The watermark-removal generator architecture leverages multiscale convolutional encoders and attention-enabled decoders, capturing diverse watermark embedding strategies used in modern watermarking schemes.
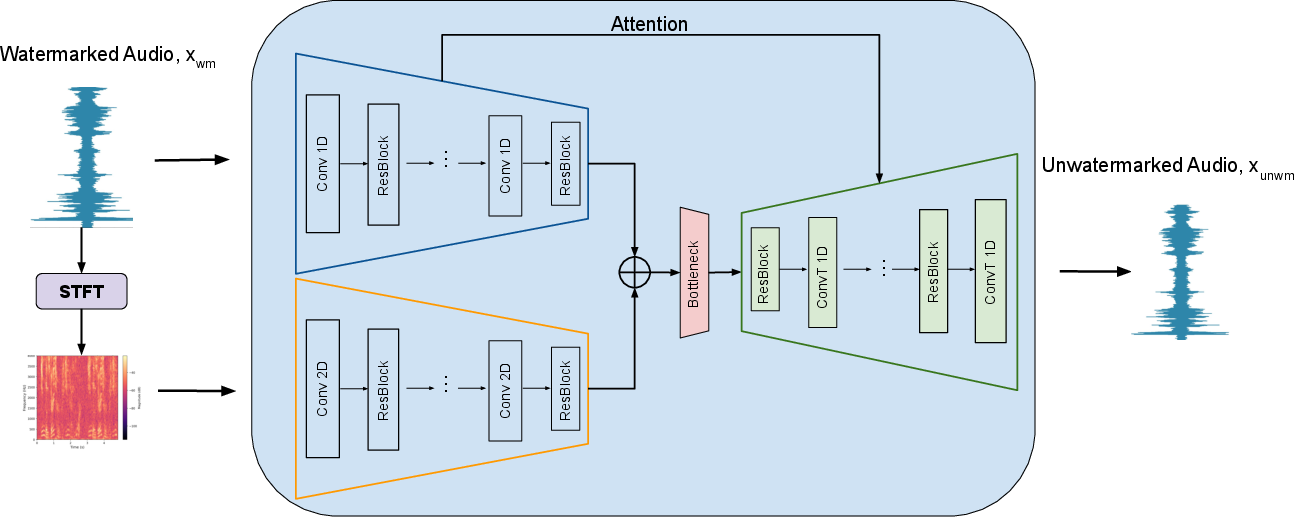
Figure 2: The detailed network for HarmonicAttack's generator utilizes parallel time and frequency domain analysis for domain invariance.
The discriminator employs convolutional layers with binary classification loss, acting as the adversarial critic in training to drive generator outputs toward indistinguishability from authentic samples.
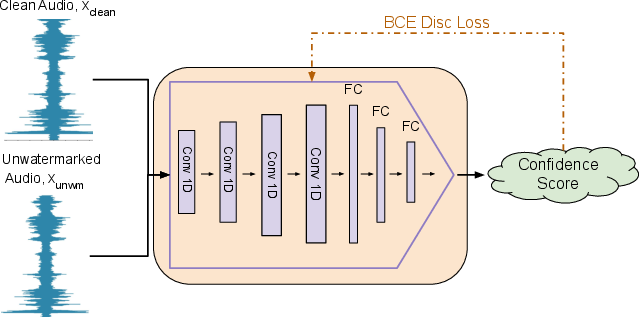
Figure 3: HarmonicAttack's adversarial discriminator architecture forces generator outputs to match clean audio distributions.
Loss Functions and Optimization Objectives
The generator's loss function integrates four components: (i) waveform-based reconstruction loss, (ii) psychoacoustic loss with adaptive frequency weighting, (iii) decorrelation loss penalizing alignment with watermark patterns, and (iv) adversarial loss from the discriminator. Psychoacoustic loss focuses optimization on perceptually masked frequency bands—where watermark energy is concentrated due to human auditory limitations—drawing on established masking literature [swansonRobustAudioWatermarking1998, spreadspectral].
The adversarial loss, pivotal for perceptual realism, is computed via binary cross-entropy with discriminator feedback. Ablation experiments show that the exclusion of any loss component degrades Attack Success Rate (ASR) or audio quality, confirming their complementary roles.
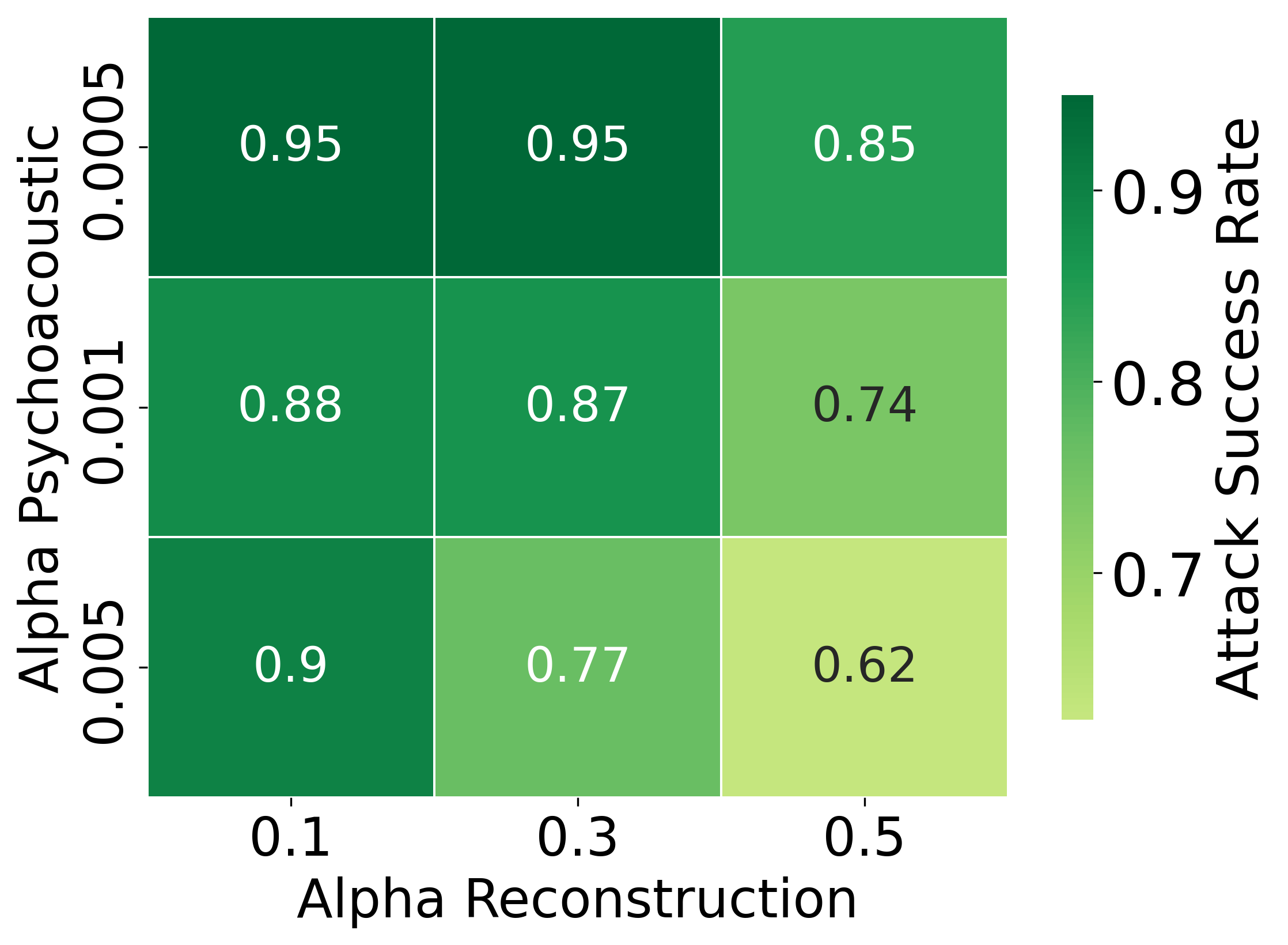
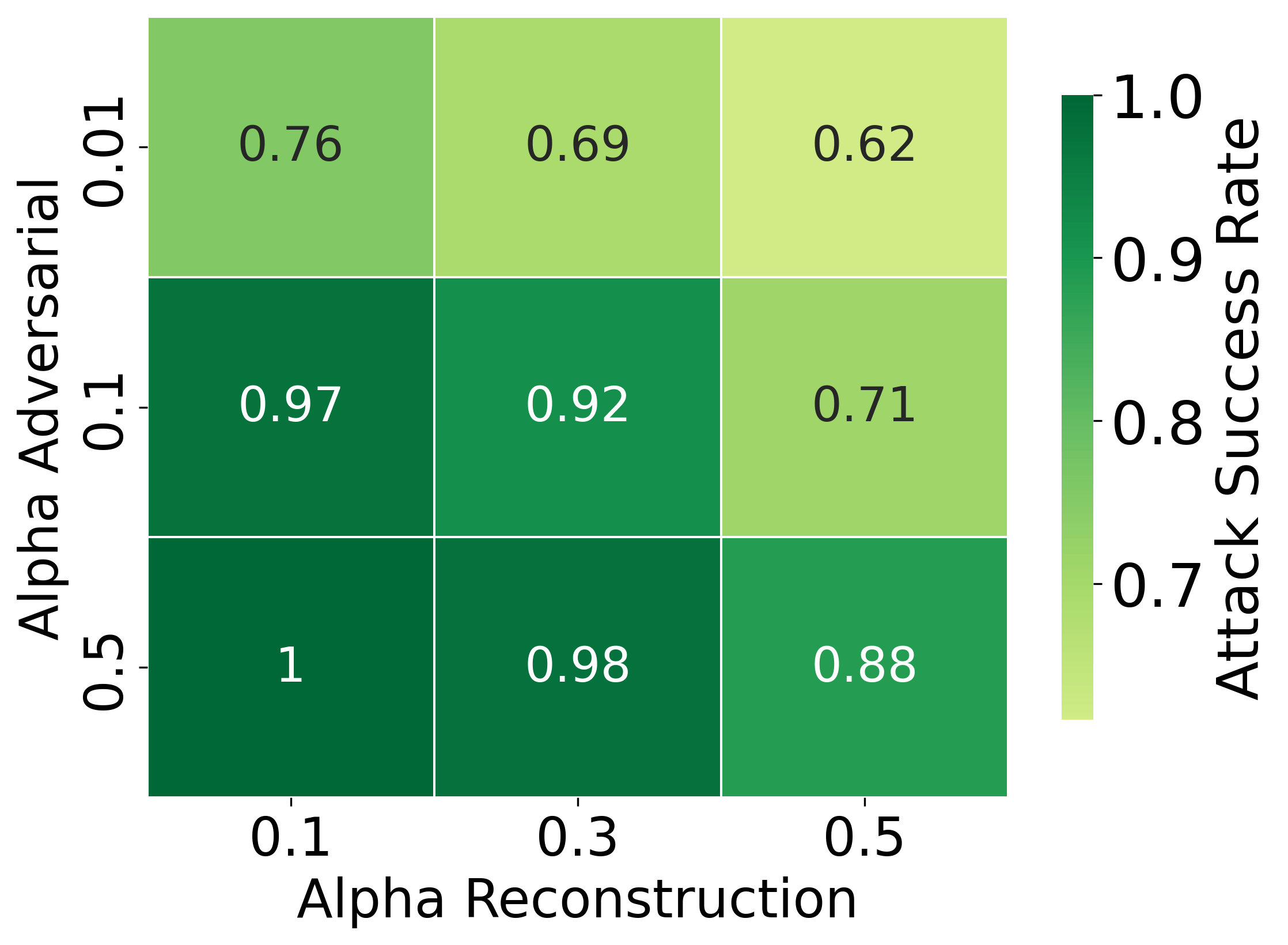
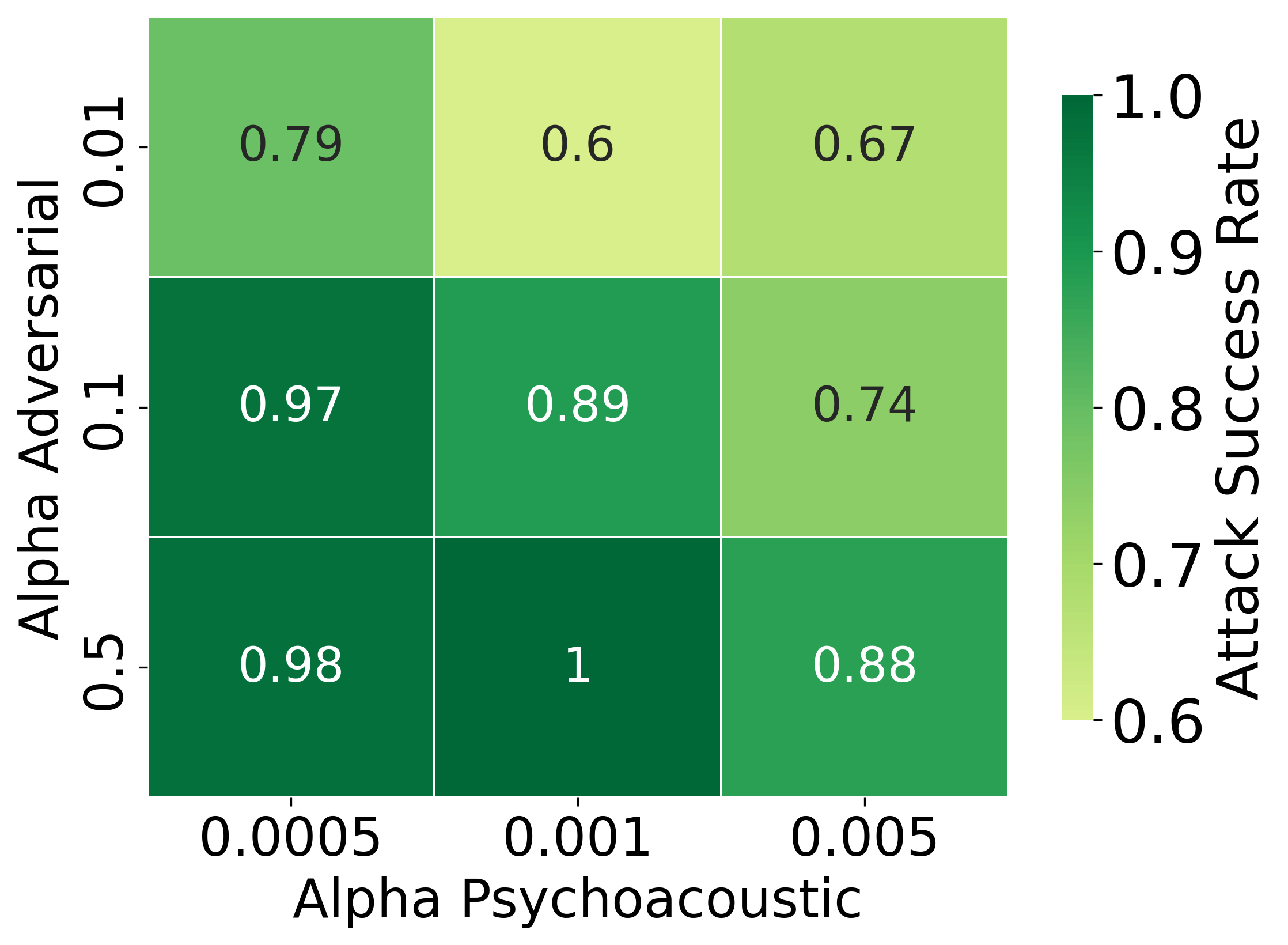
Figure 4: ASR empirically varies with weightings for reconstruction (αr), psychoacoustic (αp), and adversarial (αa) objectives.
Experimental Evaluation
Cross-Domain and On-Domain Performance
HarmonicAttack was evaluated on diverse datasets: LibriSpeech (speech) and FMA (music). It was tested against state-of-the-art watermarks including AudioSeal, WavMark, and Silentcipher, with baselines from optimization-based attacks (AudioSquareAttack) and signal-processing-based attacks (MP3/OGG/EnCodec compressions). Results show near-perfect ASR (up to 100%), high PEAQ scores (>0.9), and sub-0.06s attack time per sample, including for out-of-distribution transfers (e.g., trained on speech, tested on music).
Transferability Properties
HarmonicAttack demonstrates robust transferability across audio domains and watermarking schemes. When transferred from a speech domain (LibriSpeech) to music (FMA), HarmonicAttack still achieves 100% ASR on AudioSeal and Silentcipher watermarks, and maintains competitive quality metrics. This invariance originates from the psychoacoustic constraints—watermarks must embed within frequency bands offering perceptual masking, which is similar across domains.
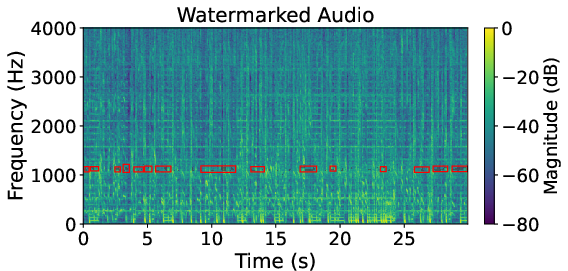
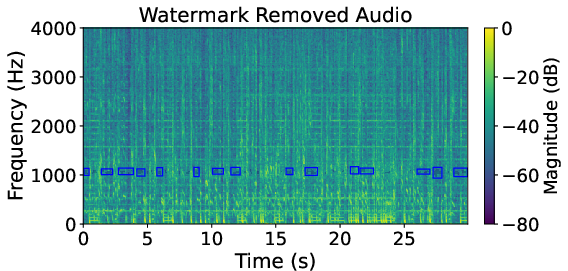
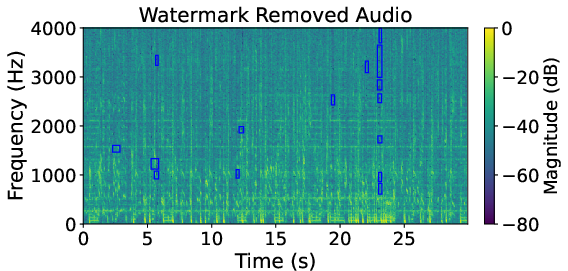
Figure 5: Comparison of spectrograms—watermarked sample, HarmonicAttack removal, and AudioSquareAttack removal—showing focused watermark suppression by HarmonicAttack on FMA AudioSeal data.
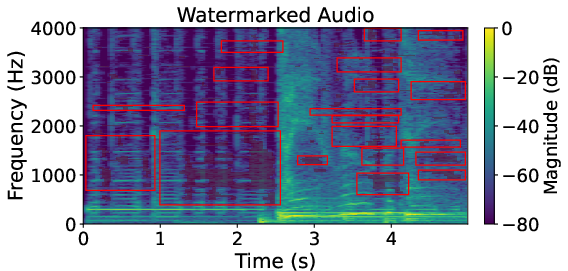

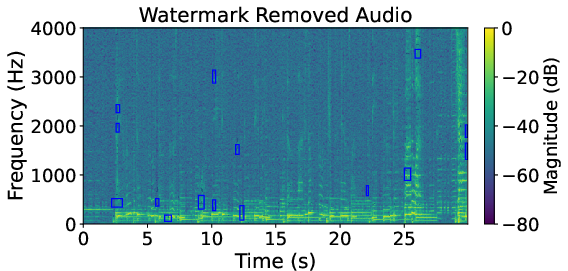
Figure 6: Comparison for FMA WavMark sample, confirming transfer performance with HarmonicAttack successfully removing watermark signals.
Spectrogram analysis corroborates that HarmonicAttack effectively targets watermark-dense regions while baselines display indiscriminate, inefficient perturbation.
Impact of Audio Length
Empirical results indicate that HarmonicAttack's computational cost remains constant irrespective of sample length, whereas AudioSquareAttack costs scale linearly or super-linearly, rendering it impractical for long audio or real-time settings.
Ablation and Component Analysis
Ablation studies reveal that removing either the adversarial discriminator or psychoacoustic loss reduces watermark removal efficacy (e.g., ASR drops to 66% without decorrelation loss), and perceptual quality is compromised if reconstruction loss is omitted. The discriminator regularizes the generator against aggressive noise, ensuring perceptual quality, while the psychoacoustic loss guides removal toward spectrally dense watermark bands.
Theoretical and Practical Implications
HarmonicAttack invalidates the assumption that current watermarking schemes protected by glass-box or optimization-based attacks are robust. Its learning-based approach, targeting underlying embedding patterns without detector access, identifies fundamental vulnerabilities stemming from psychoacoustic design choices in watermarking algorithms. Cross-domain invariance implies that watermark defense must evolve beyond signal domain and embedding location obfuscation.
Practically, HarmonicAttack enables real-time voice cloning attacks and impersonation scenarios, challenging current detection frameworks. The theoretical implication is the need for watermarking algorithms with nonstationary, adversarially robust, and semantically entangled embeddings, potentially inspired by cross-modal or latent fingerprint schemes [Wen2023_TreeRingWatermarks, Wang2024_SleeperMark].
Prospective Directions and Limitations
Future defenses should adapt image watermarking techniques—latent watermarks, multi-key identification, adversarial optimization—to the audio modality, enhancing robustness against deep learning removal. Limitation exists when watermark embedding principles or masking rules deviate substantially, which may require retraining or fine-tuning HarmonicAttack models. Admissible audio degradation in niche scenarios may also limit the attack's efficacy.
Conclusion
HarmonicAttack represents the first general-purpose, learning-based, transferable watermark removal method for audio, achieving high ASR and perceptual quality in both speech and music domains while outperforming prior signal processing and optimization-based baselines (2511.21577). The research exposes structural weaknesses in psychoacoustically-constrained watermark designs and necessitates advancement toward adversarially robust, cross-domain watermarking. As generative audio models continue to evolve, the arms race between watermark embedding and removal will increasingly depend on adaptive, semantic, and distributionally aware mechanisms.