- The paper presents a novel Split-then-Merge framework for video composition that automates layer decomposition using self-supervision on unlabeled data.
- It employs transformation-aware augmentation and identity-preservation loss to ensure accurate motion fidelity and spatial harmony between foreground and background.
- Quantitative metrics and user studies reveal that StM outperforms traditional methods in preserving motion, identity, and affordance across diverse scenes.
Layer-Aware Video Composition via Split-then-Merge: Technical Analysis
Introduction and Motivation
The paper "Layer-Aware Video Composition via Split-then-Merge" (2511.20809) introduces the Split-then-Merge (StM) framework for generative video composition, targeting the synthesis of a coherent video by integrating a dynamic foreground sequence into a separate background sequence. Traditional approaches for video compositing are limited by reliance on annotated datasets, static image-based methods, or laborious handcrafting for object insertion. These methods typically lack a rigorous treatment for motion preservation and render affordance-aware interactions infeasible.
StM departs from these paradigms by leveraging self-supervision on unlabeled video corpora, decomposing raw videos into foreground/background layers and then training a generative model to merge these layers for realistic composition. This enables scalable training without costly annotation, supports generalization across diverse domains, and crucially maintains motion, identity, and affordance consistency throughout the compositing process.

Figure 1: Comparative overview of video composition methods, illustrating StM’s capacity to preserve motion and achieve affordance-aware harmony where prior methods fail.
Framework: Split-then-Merge Architecture
Decomposition Pipeline
The StM Decomposer forms the backbone for scalable dataset creation, consisting of three main stages:
- Motion Segmentation: An off-the-shelf segmentation model (Segment-Any-Motion) is used to extract a binary mask delineating the foreground subject throughout the sequence.
- Background Inpainting: Masked regions are filled using a state-of-the-art video inpainting model (MiniMax-Remover), reconstructing plausible dynamic backgrounds.
- Video Captioning: A pretrained video-LLM (InternVL) generates descriptive captions augmenting the dataset for downstream conditioning.
This process bootstraps large-scale multi-layer video datasets from any unlabeled source, which is critical for training generative models at scale.
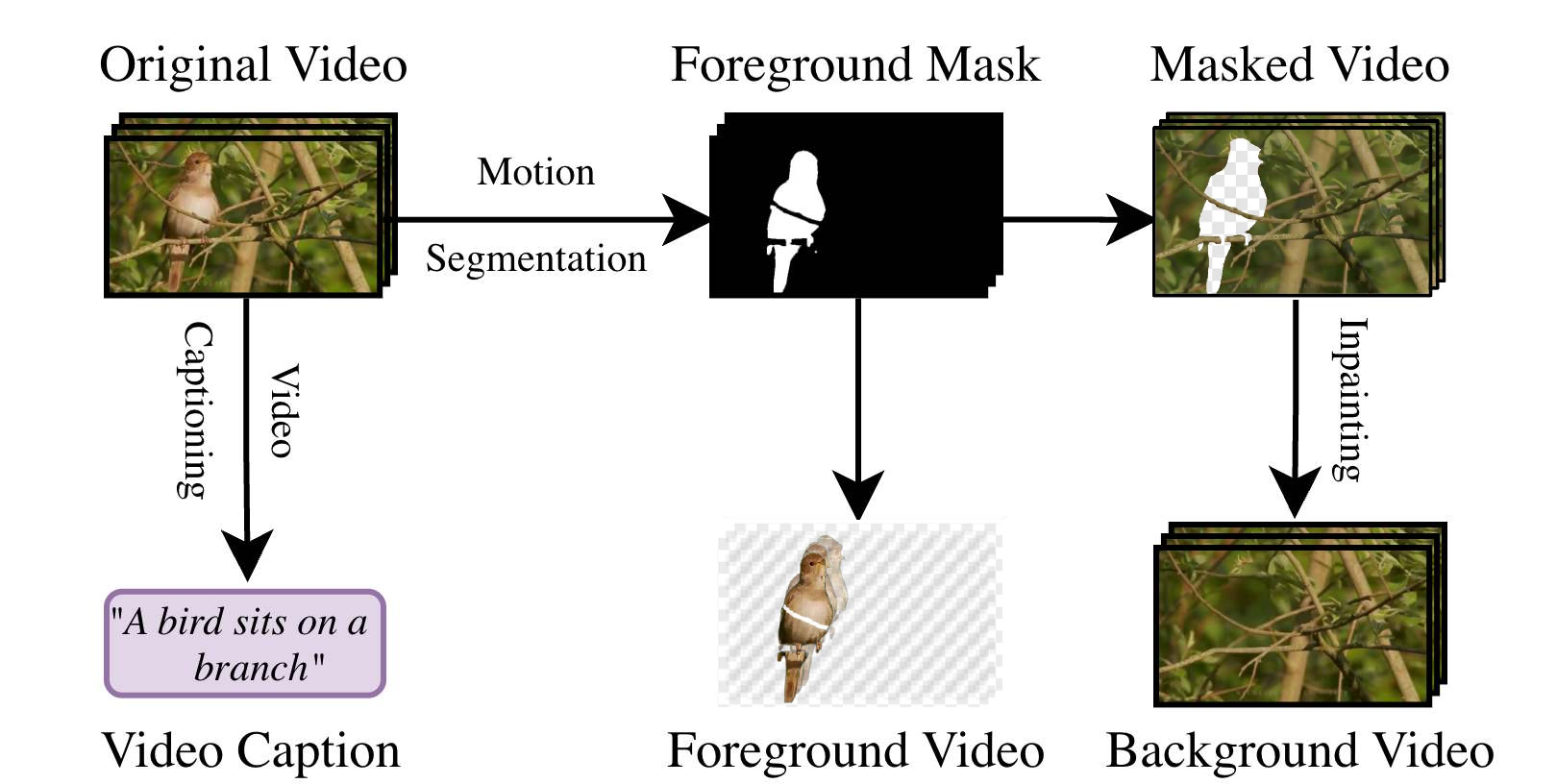
Figure 2: The StM Decomposer automates the splitting of unlabeled videos into foreground, background, mask, and caption layers by integrating segmentation, inpainting, and captioning models.
Generative Composition (Composer)
The StM Composer adapts the CogVideoX-I2V backbone for multi-layer video input, encoding augmented foregrounds and backgrounds to latent representations via a pretrained Space-Time VAE, and fusing them channel-wise with textual embeddings before input to a Diffusion Transformer.
Key innovations include:
- Transformation-Aware Augmentation: Foreground inputs are randomly augmented (e.g., flipping, cropping, color jitter), making the merging task nontrivial and incentivizing the model to reconstruct correct geometry and harmonization instead of memorizing placements.
- Multi-Layer Conditional Fusion: Visual latents from the (augmented) foreground and background are concatenated and projected for fine-grained compositional guidance at each spatiotemporal location.
- Identity-Preservation Loss: Composition loss is partitioned into foreground/background-aware reconstructions, enabling precise control over fidelity and harmony.
Inference simply replaces the ground-truth latent with noise, omitting data augmentation.
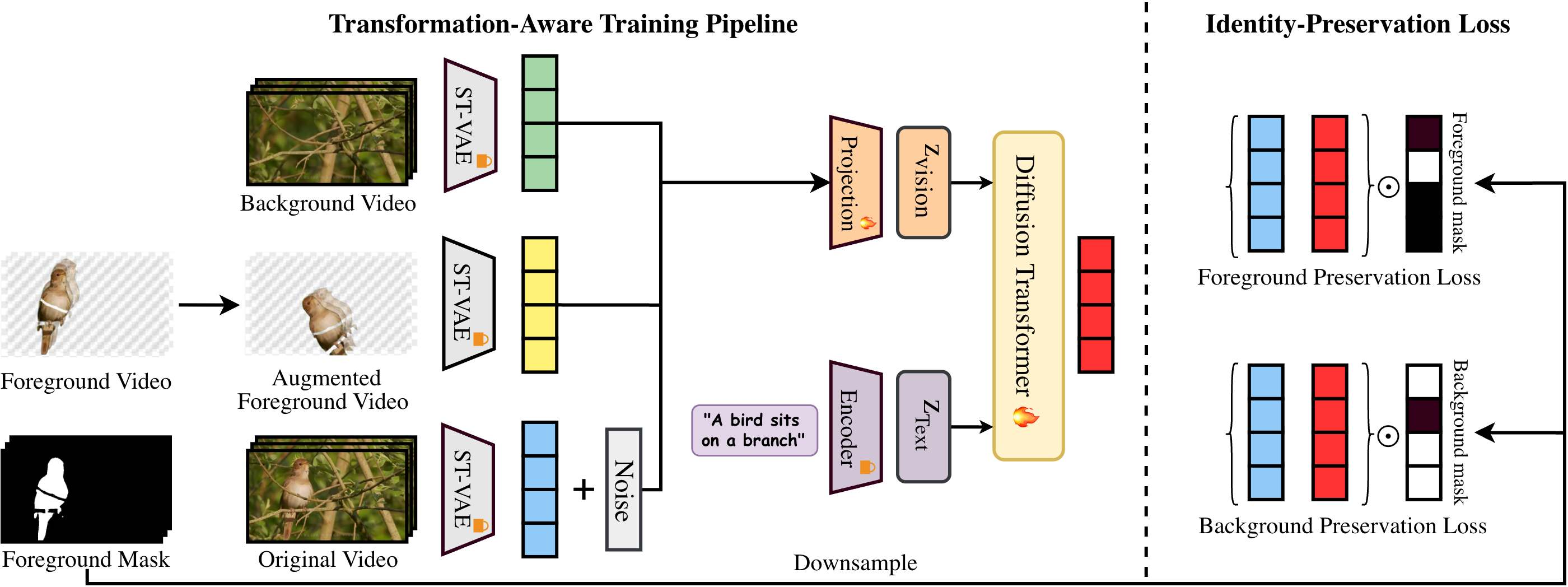
Figure 3: StM Composer training diagram highlighting joint encoding and fusion of foreground, background, and textual inputs, with identity-aware loss for targeted reconstruction.
Quantitative and Qualitative Evaluation
Automated Metrics
StM’s evaluation employs four automated metrics:
- Identity Preservation: ViCLIP embedding similarity for foreground and background.
- Semantic Action Alignment: KL divergence over action distributions via Video Swin.
- Background Motion Alignment: MSE between input and output optical flows.
- Textual Alignment: ViCLIP text-video similarity.
StM achieves state-of-the-art scores in foreground/background identity preservation and motion metrics. Notably, background motion preservation (MSE 16.36) outperforms all baselines by an order of magnitude, underscoring the effectiveness of multi-layer video conditioning. However, text-based adherence is marginally lower than specialized models with text-centric guidance, reflecting the prioritization of visual fidelity over semantic adherence.
User Studies and VLLM-Based Evaluation
A large-scale user study (50 subjects, 25 test cases) and a VLLM-based judge (Gemini 2.5 Pro) are deployed, each providing pairwise comparison against five baselines across six criteria. StM is preferred in >85% of cases for foreground motion, foreground-background harmony, and overall visual quality.

Figure 4: Qualitative comparison of composed outputs; StM uniquely harmonizes motion, placement, and lighting, correcting failures of alternative approaches.

Figure 5: Qualitative results display robust preservation of characteristic actions and seamless integration with contextual adaptation for affordance-aware composition.
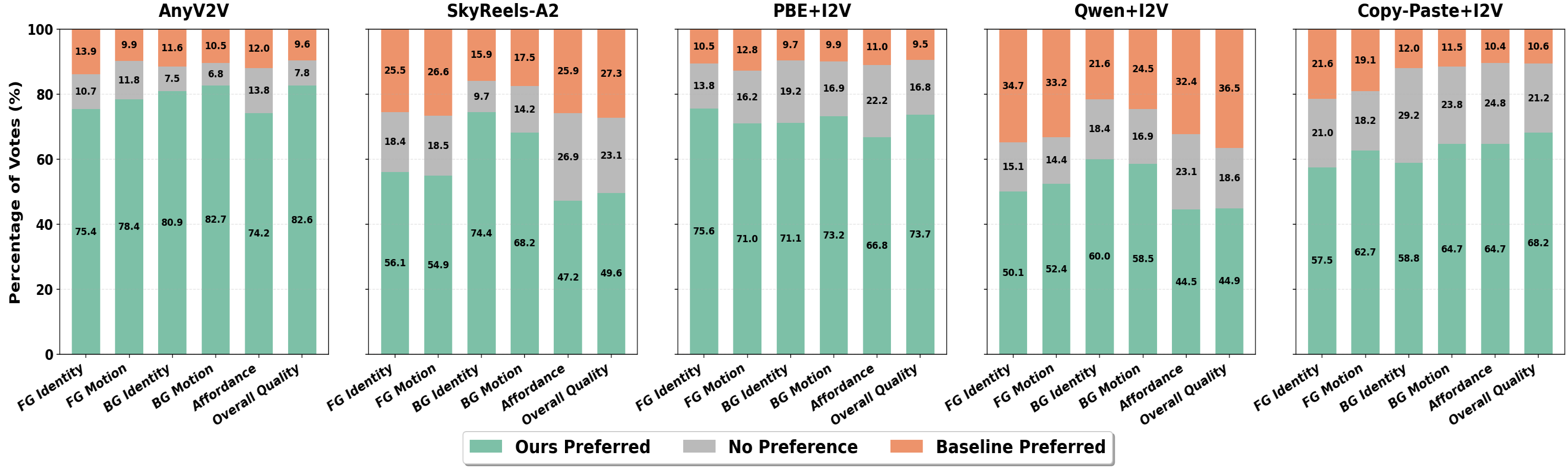
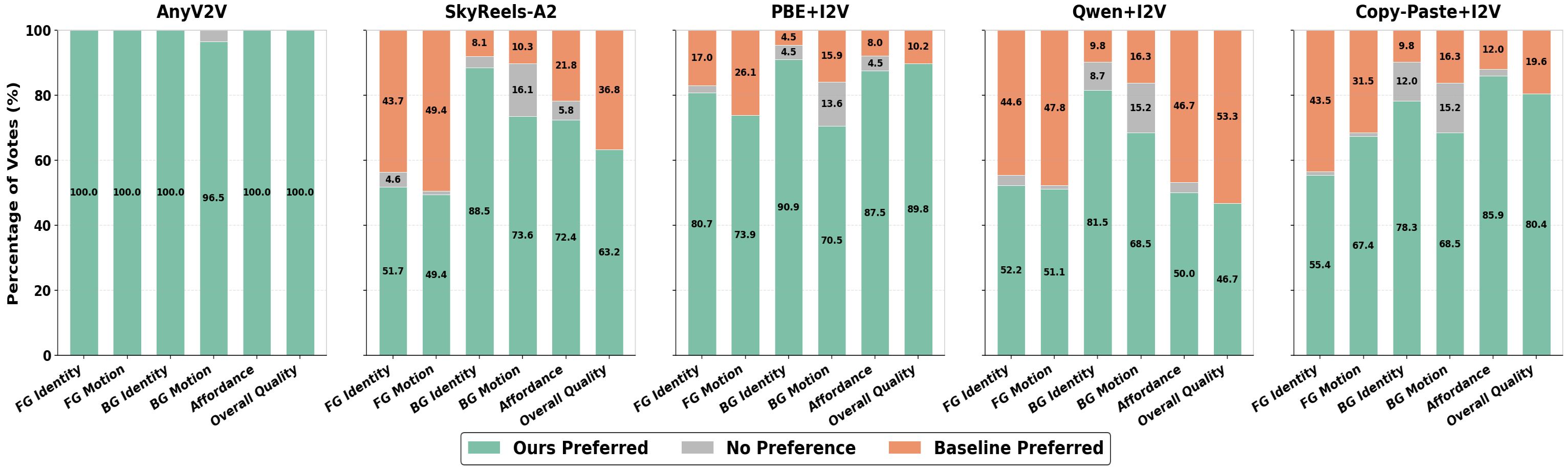
Figure 6: User study results show StM achieves consistently high preference rates over all baselines for motion, identity, and harmony.
Ablation Studies and Component Analysis
Ablation experiments confirm the necessity of both transformation-aware augmentation and identity-preservation loss. Removal of augmentation or targeted loss leads to shortcut learning, with the model simply replicating foreground masks or failing to generalize compositional strategies, evidenced by artificial improvements in foreground scores but overall decrease in compositional quality.
Discussion and Implications
StM demonstrates that scalable, annotation-free generative video composition is feasible, outperforming previous state-of-the-art methods in motion fidelity, identity retention, and semantic affordance. Its modular design, based on automated layer decomposition and fusion, provides an extensible framework for future compositional video synthesis tasks.
Practical implications include reliable insertion and harmonization of moving subjects into dynamic scenes, relevant for professional post-production, virtual content creation, and semantic video editing. Theoretically, StM advances multi-layer diffusion modeling, introducing compositionality, selective conditioning, and identity-aware representations into generative video synthesis research.
Notably, a trade-off between semantic textual adherence and strict motion/identity fidelity suggests avenues for future research, such as dynamic balancing of conditioning weights or improvement of off-the-shelf decomposition modules.
Conclusion
The Split-then-Merge framework establishes a data-driven paradigm for layer-aware video composition, efficiently exploiting unlabeled video corpora and automating the creation of compositional datasets. By rigorously preserving both motion and identity while achieving semantic harmonization and affordance awareness, StM sets a new standard for controllable, generative video synthesis, pointing towards next-generation compositional and multimodal video generation models.

