- The paper introduces a novel branch-based reparameterization method that significantly reduces the number of transformer layers without losing accuracy.
- It employs exact branch consolidation in FFN and MHSA modules to merge parallel training paths into a single efficient inference model.
- The approach achieves up to 64% throughput improvements and 37% reduced latency on mobile CPUs, challenging the need for deep architectures in ViTs.
Introduction
The research presented in "Rethinking Vision Transformer Depth via Structural Reparameterization" (2511.19718) addresses the computational inefficiencies of Vision Transformers (ViTs), particularly their deep architectures, by introducing a novel framework that reduces transformer layers while maintaining representational capacity. Traditional methods that focus on pruning and attention speedup don't fully address the depth-induced overhead. Instead, the proposed method introduces a branch-based structural reparameterization technique aimed at maintaining comparable accuracy with significantly fewer layers.
ViTs have become a staple in computer vision, offering superior performance by modeling long-range dependencies. However, their application is hampered by the high computational cost due to their deep architectures and quadratic attention mechanisms, particularly problematic for devices with limited resources like mobile and edge platforms. As highlighted, existing small variants, such as TinyViT, still contain multiple layers (e.g., 12 layers) and millions of parameters, falling short of being truly efficient for real-time applications on resource-constrained devices.
Proposed Method: Structural Reparameterization
The authors propose a method that leverages parallel branches during training, which are progressively merged into single-path models for inference. This structural reparameterization ensures no approximation loss at test time, a significant advantage over existing approximation-based methods.
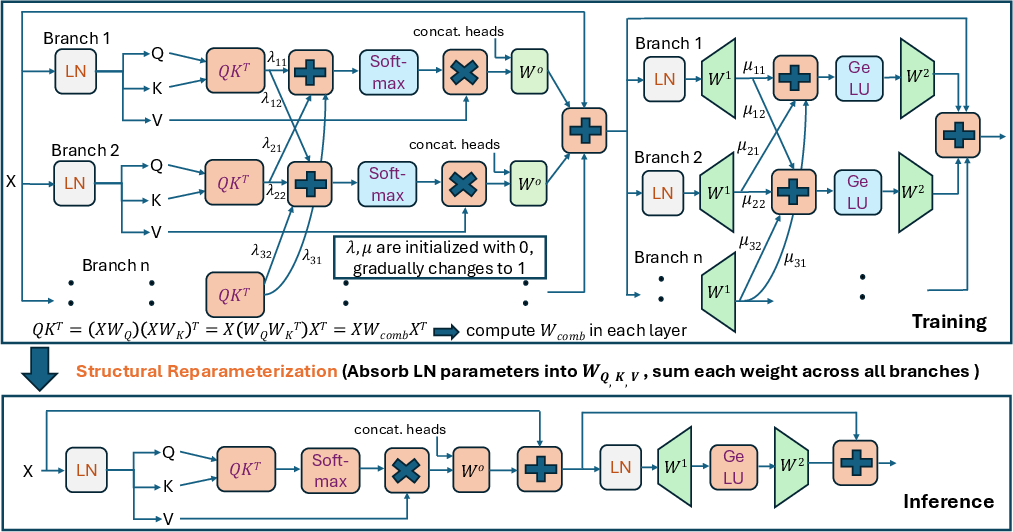
Figure 1: Proposed Depth Compression Framework for ViTs
Key aspects of the method include:
- Branch Consolidation: The method involves merging branches at the entry points of nonlinear functions, enabling exact mathematical transformations within both FFN and MHSA modules.
- Exact Reparameterization: Ensures no accuracy degradation during inference by maintaining algebraic equivalence between training and deployment models.
- Deployment Efficiency: The resulting models, when applied to structures like ViT-Tiny, demonstrate significant speedups in mobile CPU deployments, with up to 37% reduction in latency.
Experimental Results
The work showcases empirical evaluations on ImageNet-1K where the reparameterized models achieve up to 64% improvements in throughput at isometric accuracy levels compared to their deeper counterparts. Specifically, reducing the ViT-Tiny from 12 to 3 layers still retained classification performance, indicating that extreme depth is not essential for maintaining model efficacy.
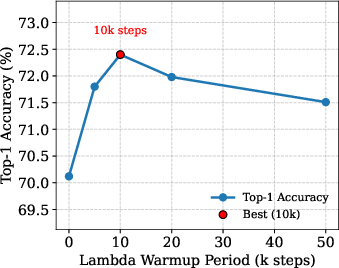
Figure 2: Effect of different Lambda Warmup Periods on ImageNet-1K D-MAE-6-R fine-tuning accuracy with linear lambda scheduler. The red point indicates the best performing warmup (10k steps).
This study challenges the prevalent assumption that increasing depth is necessary for improving performance in transformers. The research contrasts with past approaches that incrementally optimized deep models. By adopting a radical reduction in depth, the study opens avenues for deploying ViTs in memory-constrained environments and unconventional computing platforms like in-memory and photonic computing, where deep models are traditionally limited.
Implications and Future Directions
This paper's implications extend beyond the current landscape of hardware acceleration for transformers. By proving that ultra-shallow architectures can compete with traditionally deep models, it sets a precedent for future work on ViT efficiency. For real-time applications across diverse hardware platforms, this approach provides a new horizon of exploration for deploying machine learning at the edge.
Future research could explore further merging of modalities within the transformer architecture, expanding beyond visual tasks to encompass applications in video processing and possibly integrating computationally efficient mechanisms into emerging analog processing units.
Conclusion
The method introduced demonstrates a significant paradigm shift in constructing efficient transformer models. The findings encourage a reconsideration of existing architectural norms across computer vision research, highlighting that model depth should be re-evaluated in the context of deployment constraints and practical efficiencies. The study provides a foundational approach for structural reparameterization in ViTs, thus broadening the scope for future transformations in AI model design.