- The paper introduces Inv, a novel data-efficient inversion method that leverages invariant latent space properties for accurate prompt reconstruction.
- It employs a cyclic and source invariance hypothesis with contrastive alignment and supervised reinforcement to boost semantic fidelity across outputs.
- Experiments show Inv achieves a 4.77% BLEU improvement and reduces data requirements by 80% compared to conventional inversion approaches.
Invariant Latent Space Hypothesis and Efficient LLM Inversion
Motivation and Background
LLM Inversion (LMI) refers to reconstructing hidden prompts from outputs produced by LLMs. This capability is increasingly significant given the proliferation of LLMs across distributed inference systems and web-based APIs, where both user prompts and system prompts can carry sensitive information. Conventional inversion approaches, such as Logit2text and Output2prompt, primarily depend on training external inverse models on extensive output-prompt pairs, which can be impractical due to scale and limited generalization. The paper proposes a principled latent space perspective for LMI, introducing the Invariant Latent Space Hypothesis (ILSH), and presents Inv—a novel, data-efficient, end-to-end inversion framework leveraging the intrinsic invariant structure of LLMs.

Figure 1: Overview of Inv. An inverse encoder maps one or more outputs into denoised pseudo-representations in the LLM's latent space, and the LLM is reused to recover the prompt. The threat model covers both user prompt and system prompt.
ILSH: Cyclic and Source Invariance
ILSH posits that the LLM's latent space (Z) exhibits two invariance properties:
- Source Invariance: Outputs sampled from the same prompt contain consistent semantic information. Their latent representations should remain similar, enabling inversion by capturing semantic clustering.
- Cyclic Invariance: The latent space supports reciprocal mappings: both X→Z→Y and Y→Z→X, implying that round-trip inversion is feasible within Z.
Empirical analyses confirm sufficiency and necessity of cyclic invariance. Perturbations to output distributions (e.g., synonym replacement, random swaps, random noise) sharply degrade inverse mapping metrics (entropy, probability, BLEU), demonstrating that robust inverse mapping is contingent upon the inherent coupling between forward and inverse flows. Moreover, explicit reinforcement of the inverse path enhances forward mapping, further validating the bidirectional latent geometry.

Figure 2: Evaluation of cyclic invariance under various output perturbations; metrics shift significantly when outputs deviate from the trained distribution.
Inv: Architecture and Training Paradigm
Inv formalizes inversion using an asymmetric encoder-decoder strategy:
- Inverse Encoder: A lightweight, trainable module projects one or more outputs into a denoised pseudo-representation c within the LLM's native latent space.
- Invariant Decoder: The original LLM (frozen) decodes c to recover the prompt. The embedding layer is omitted, enabling direct latent space utilization.
For multi-output settings (system prompt attacks), a semi-sparse concatenation maximizes information density while constraining computational cost to O(Nl2). Training proceeds in two stages:
- Contrastive Alignment: Enforces source invariance through InfoNCE loss, aligning representations across outputs from the same prompt while ensuring separation from negatives.
- Supervised Reinforcement: Strengthens cyclic invariance via reconstruction loss on inverse pairs, first warming up projection layers, then jointly fine-tuning both encoder and projector.
An optional neighborhood search (dynamic filter) refines inversion by exploring semantic variants of outputs, using iterative Monte Carlo sampling conditioned on semantic equivalence.
Experimental Results
Inv is evaluated across nine datasets (user/system prompt scenarios) using LLaMA2-7B-Chat as the forward LLM. Robust comparisons reveal the following:
- Quantitative Gains: Inv achieves an average BLEU improvement of 4.77% over Output2prompt, and reduces data requirements by approximately 80%. Metrics indicate high semantic fidelity (Cosine Similarity, GPT-4o eval), with surface-level exact matches trailing but still outperforming baselines.
- Robustness: Inv demonstrates stable performance across variations in prompt length, output perturbations, and sampling diversity. Performance degrades mainly with extreme temperature sampling, underscoring the reliance on output distributions consistent with the forward model.
- Transferability: Inversion results generalize well to out-of-domain prompts and alternate LLM architectures, especially within the same model family, confirming the latent space invariance.
- Efficiency: Inv attains comparable performance with only 20–30% of inverse data, and requires fewer trainable parameters (encoder only) compared to full encoder-decoder baselines.
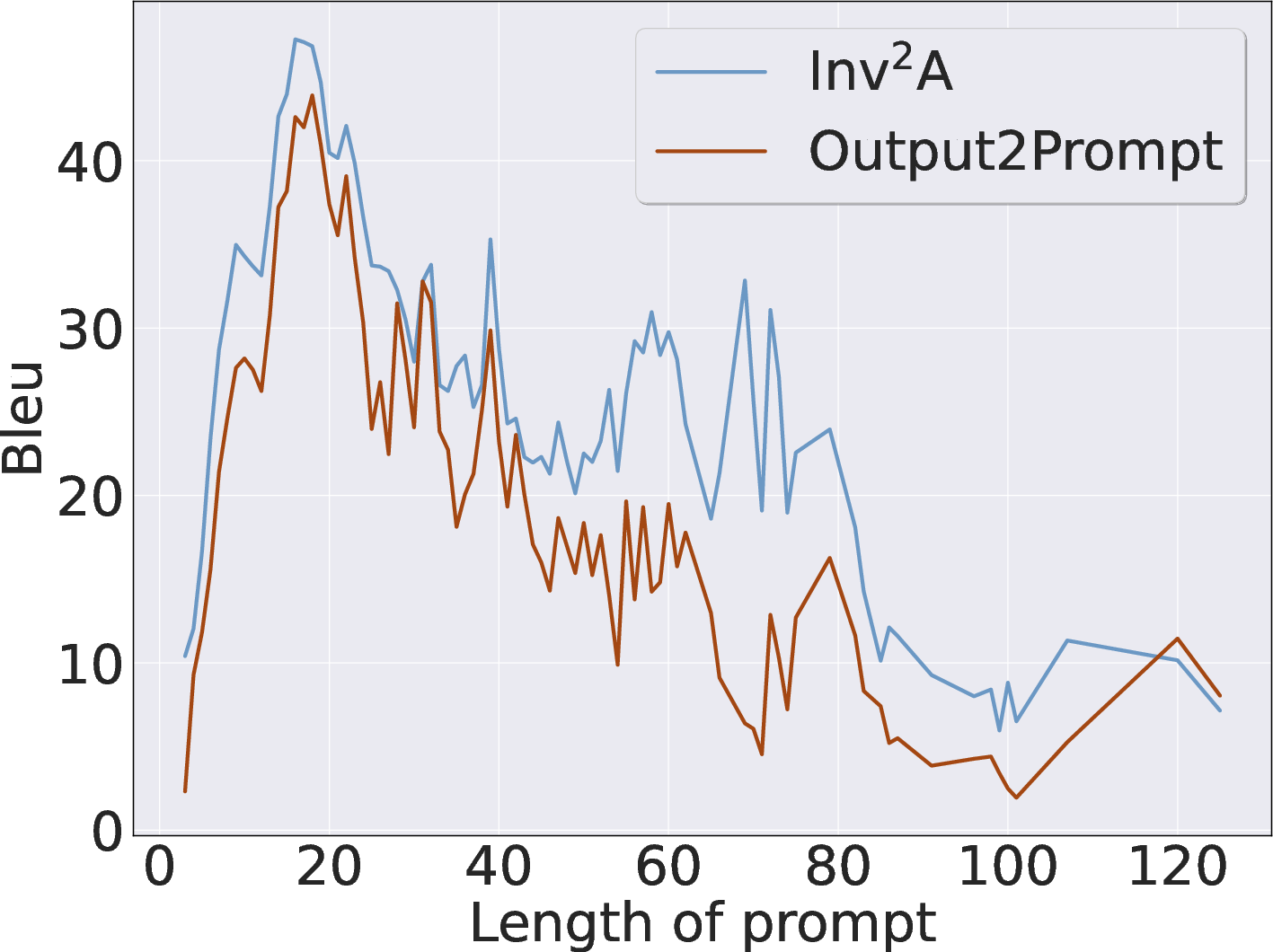
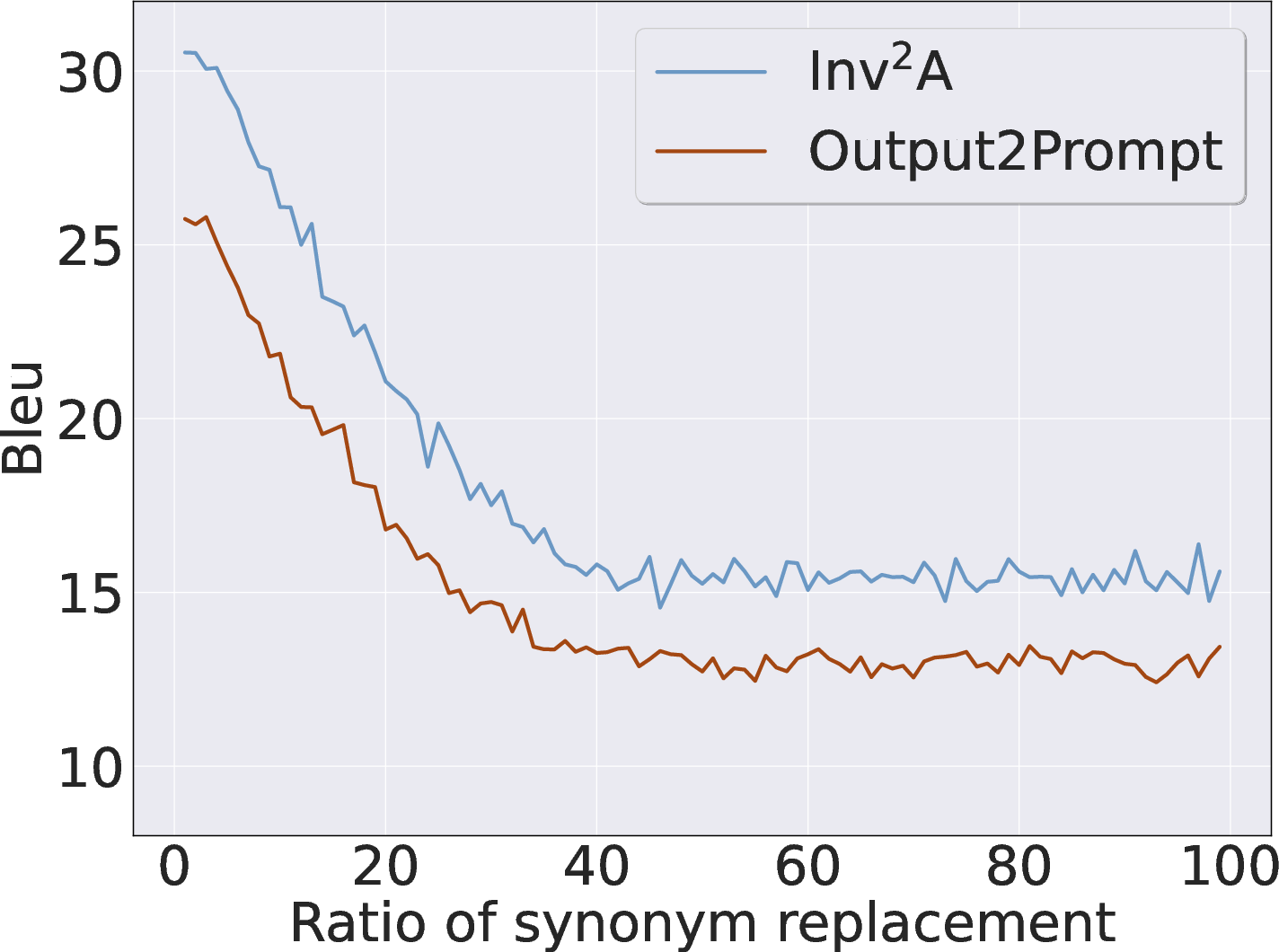
Figure 3: Prompt length robustness—Inv maintains superior BLEU scores across varying input lengths.
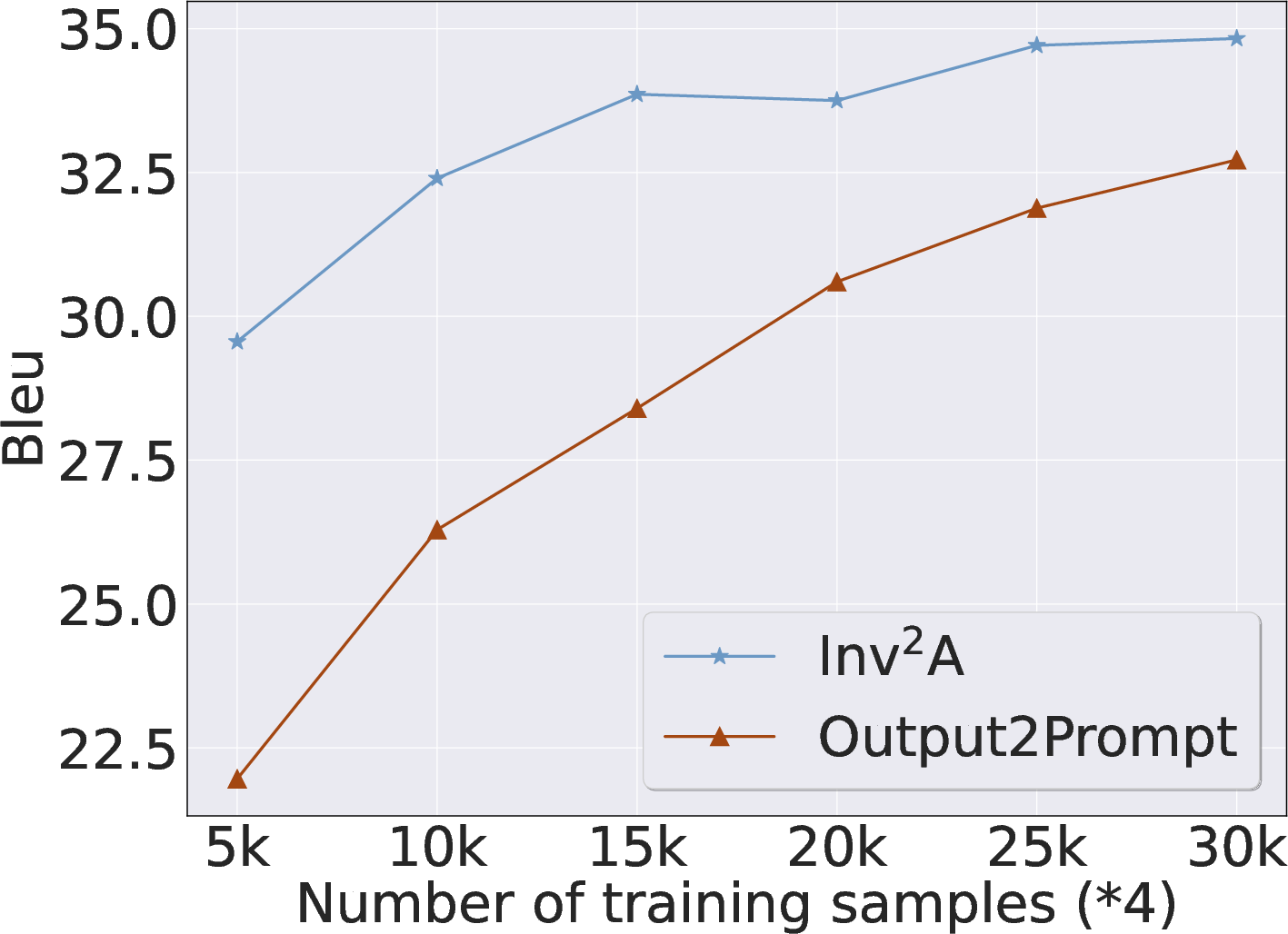
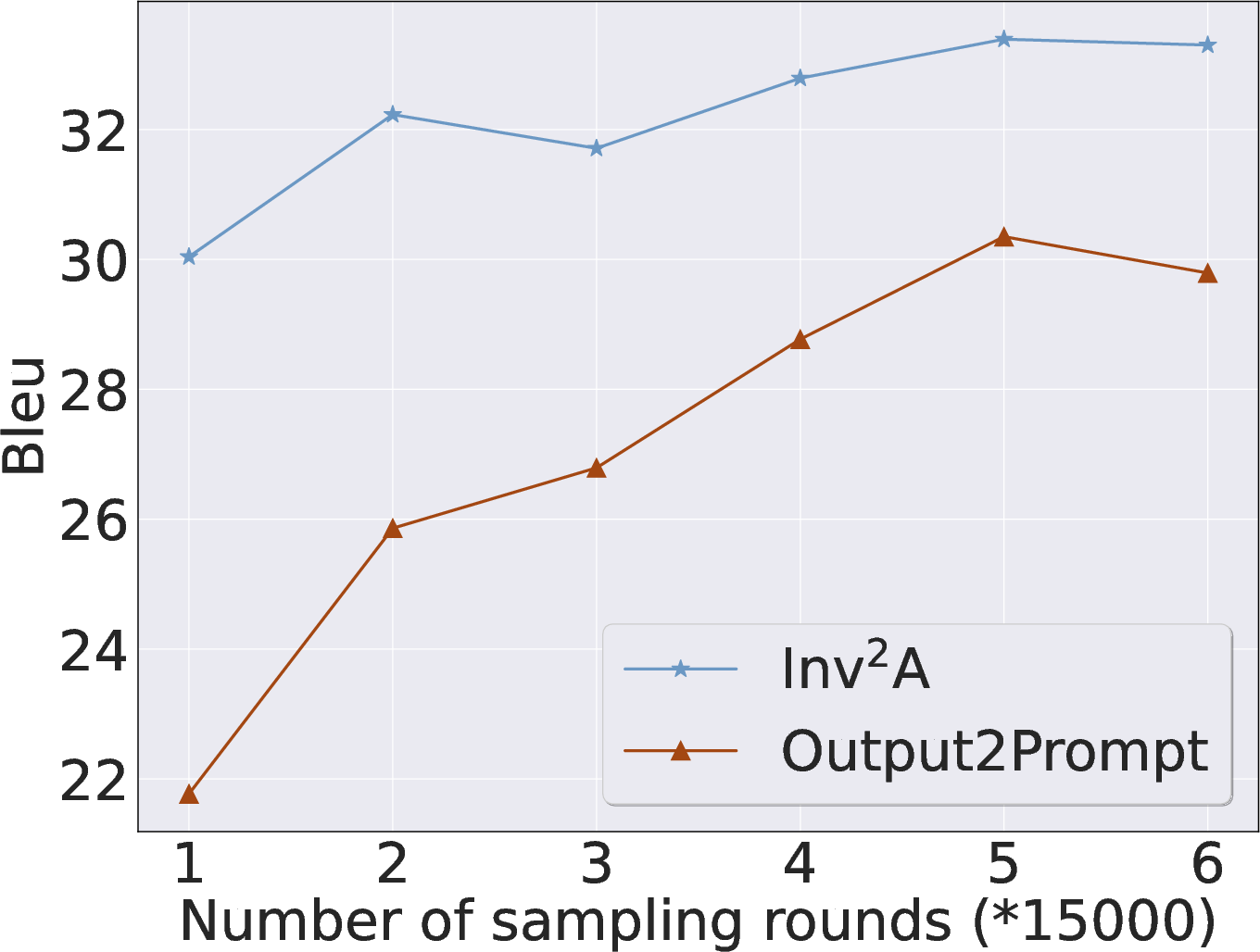
Figure 4: Training data scale—Inv achieves performance plateau at a fraction of data compared to baselines.
Ablation and Theoretical Insights
Structural and module-wise ablation studies confirm the necessity of both the inverse encoder and source-aware contrastive learning. Removal of the encoder or the alignment phase leads to sharp performance drop, establishing the key denoising and invariance mechanism.
Attention analyses indicate that Inv's encoder shifts the decoder's attention distribution toward tokens shared between output and prompt, exploiting semantic cues for robust inversion.


Figure 5: Importance visualization shows encoder-driven attention shift, with increased focus on semantic key tokens.
Mutual information quantification reveals early decoder layers capture the highest invariant information flow from the encoder, motivating targeted defenses via layer-wise noise injection.
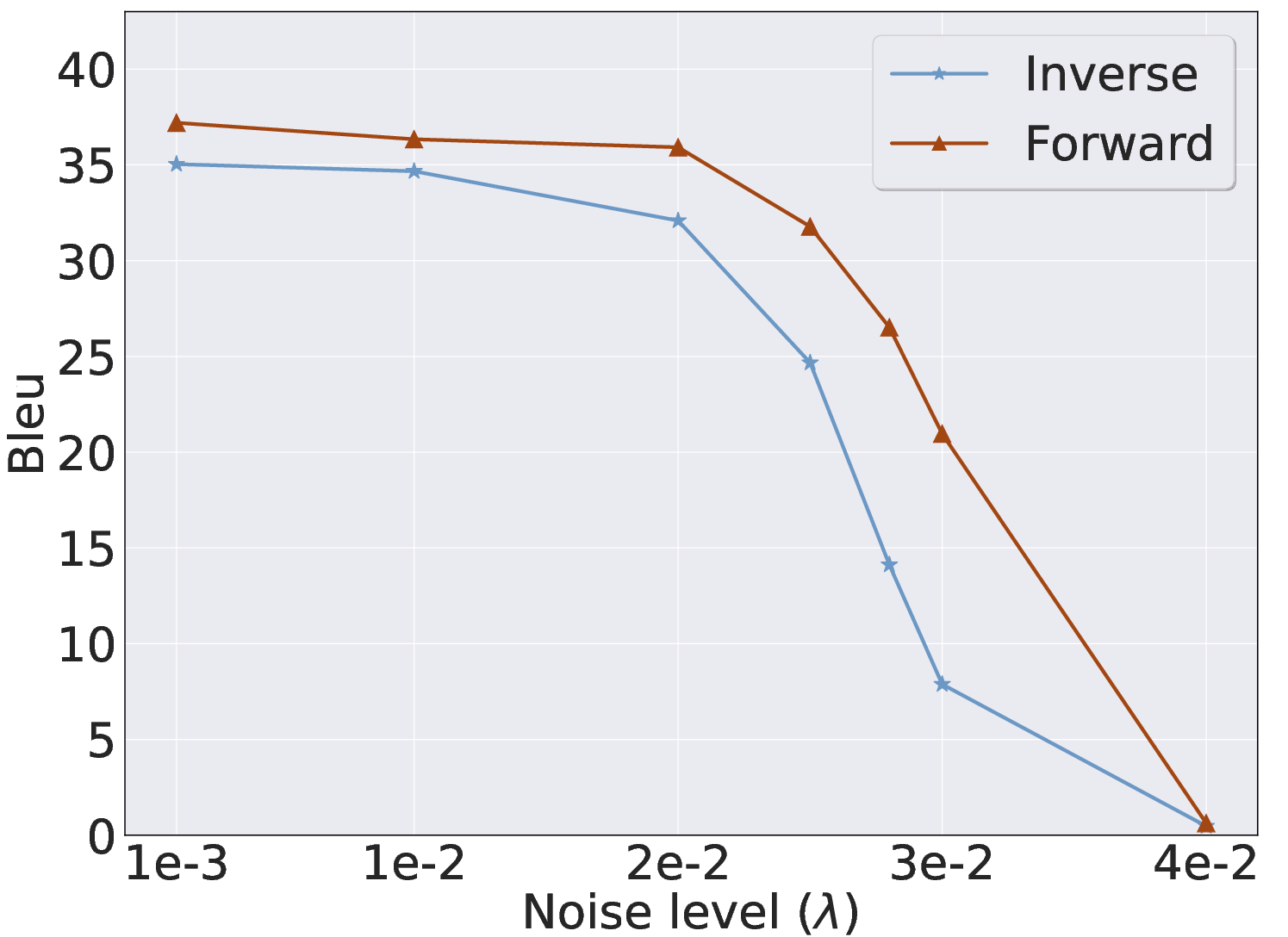
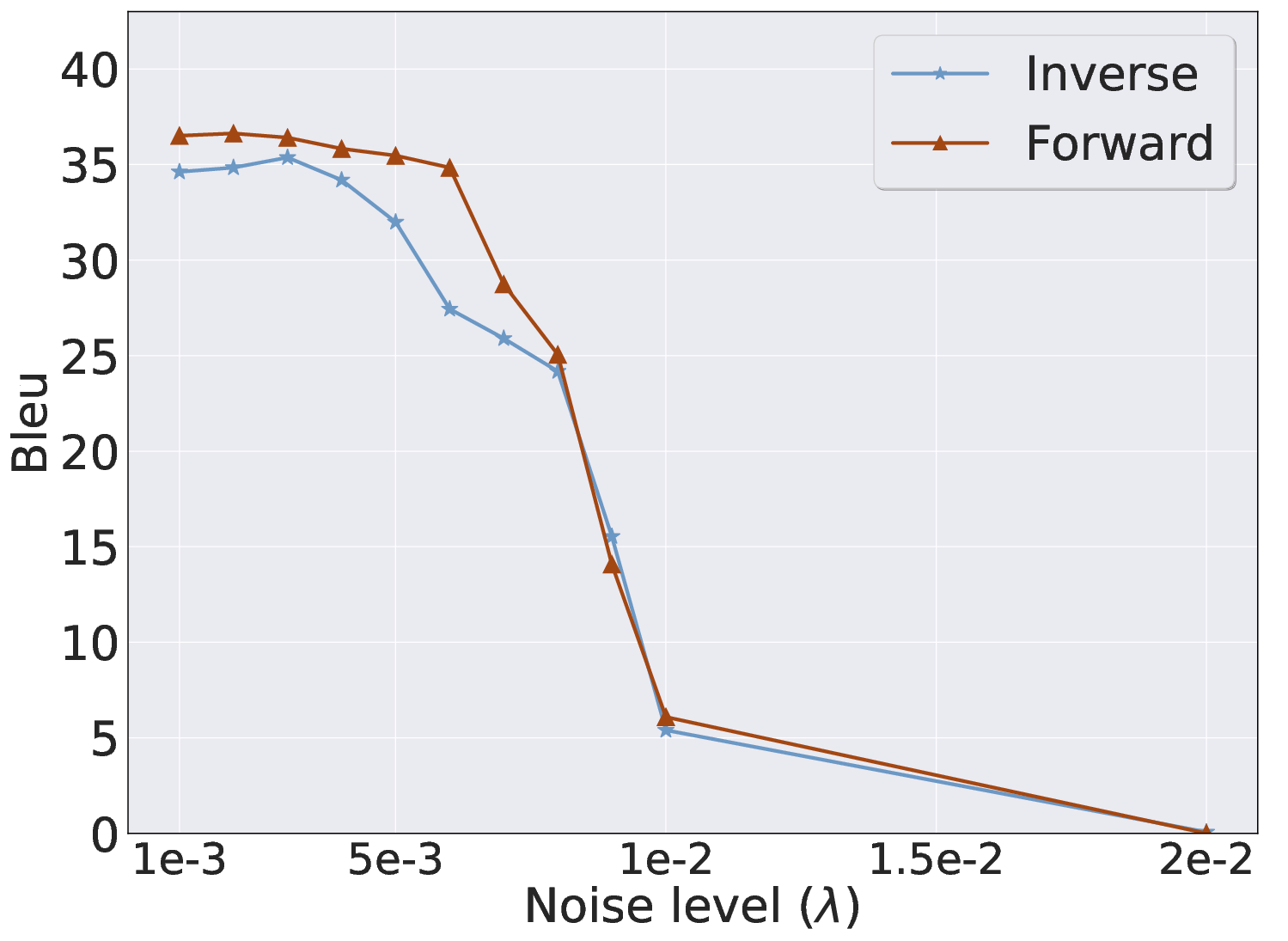
Figure 6: Effect of MLP layer noise injection—defensive strategies impact latent invariance and inversion quality.
Security and Privacy Implications
Inv exposes practical threats to user and system prompt confidentiality, including proprietary, personal, and compliance-related information. Existing defenses based on output diversity offer limited protection due to Inv's exploitation of invariant latent geometry. Layer-wise latent noise injection shows partial effectiveness but often compromises forward model utility, highlighting the challenge of designing robust, non-disruptive defenses.
Limitations and Future Directions
The primary limitations are reliance on white-box model access, sensitivity to semantic clarity (ambiguity in prompt-output mapping), and incomplete robustness of defense mechanisms. Further work is needed to extend inversion to strict black-box settings, improve latent space interpretability under ambiguous mappings, and develop scalable privacy-preserving defenses.
Conclusion
This paper establishes a principled, invariant latent space perspective for LMI, demonstrating that the internal geometry of LLMs can be efficiently leveraged to reconstruct prompts with high fidelity. The Inv framework achieves superior performance, robustness, and efficiency compared to prior art, raising critical security and privacy questions. The continued development of strong defenses remains an open and urgent area for both theoretical and practical research in AI security.