NAF: Zero-Shot Feature Upsampling via Neighborhood Attention Filtering
Abstract: Vision Foundation Models (VFMs) extract spatially downsampled representations, posing challenges for pixel-level tasks. Existing upsampling approaches face a fundamental trade-off: classical filters are fast and broadly applicable but rely on fixed forms, while modern upsamplers achieve superior accuracy through learnable, VFM-specific forms at the cost of retraining for each VFM. We introduce Neighborhood Attention Filtering (NAF), which bridges this gap by learning adaptive spatial-and-content weights through Cross-Scale Neighborhood Attention and Rotary Position Embeddings (RoPE), guided solely by the high-resolution input image. NAF operates zero-shot: it upsamples features from any VFM without retraining, making it the first VFM-agnostic architecture to outperform VFM-specific upsamplers and achieve state-of-the-art performance across multiple downstream tasks. It maintains high efficiency, scaling to 2K feature maps and reconstructing intermediate-resolution maps at 18 FPS. Beyond feature upsampling, NAF demonstrates strong performance on image restoration, highlighting its versatility. Code and checkpoints are available at https://github.com/valeoai/NAF.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new method called NAF (Neighborhood Attention Filtering) that makes blurry, low-detail “feature maps” from big vision models sharp and detailed again. It does this without needing to retrain for each model, and it works fast—even on very large models. The goal is to help tasks that need pixel-level precision, like segmentation (labeling each pixel) or estimating depth (how far things are), by improving the quality of the features those models produce.
Key Objectives and Research Questions
The authors wanted to answer simple but important questions:
- Can we upsample (enlarge and sharpen) the features from any vision model without retraining for each one?
- Can we do this both accurately and efficiently?
- Can a single, general method beat specialized methods that are tailor-made for particular models?
- Will this approach also help other tasks, like cleaning up noisy images?
Methods and Approach
To understand the approach, here are the core ideas in everyday language.
What are “features” and why upsample them?
- Vision Foundation Models (VFMs) are powerful models that analyze images and produce “feature maps,” which are like compressed versions of the image that capture important information (edges, textures, objects).
- These feature maps are smaller than the original image because that makes them faster to compute. But small feature maps make it harder to do precise pixel-level tasks.
- Upsampling is the process of making those feature maps larger and more detailed, so we can make accurate pixel-level predictions.
What is NAF?
NAF is a smart upsampler that:
- Looks at the original high-resolution image to guide how it should enlarge the feature map.
- Focuses its attention on small neighborhoods (nearby pixels) across different scales to find the most relevant information.
- Uses a trick called Rotary Position Embeddings (RoPE) to understand where pixels are relative to each other, so it doesn’t get confused when matching areas at different resolutions.
- Is “zero-shot” and “VFM-agnostic,” meaning once trained, it can be applied to features from any vision model without retraining.
Think of NAF like a super-smart “magnifying glass” that compares what the original image looks like in different nearby regions and decides how to mix and enhance the features to match the actual details.
How does the attention work?
- The method uses “queries” and “keys” (common terms in attention-based models) derived only from the original high-res image.
- For each high-res pixel, NAF compares it to nearby low-res areas and assigns weights (how much each neighbor should contribute).
- It then blends feature values based on those weights, producing a detailed high-res feature map.
A helpful analogy
Imagine trying to redraw a blurry picture. You look at the original photo (the guidance image) to understand where edges and textures are. Then you carefully fill in details in a smaller, blurry version by borrowing clues from the sharp photo, especially from nearby regions that look similar. That’s what NAF does—guided by the real image, it smartly refines and enlarges the model’s features.
Training in simple terms
- During training, the model sees pairs of high-res and artificially downsampled (low-res) images.
- It learns to upsample the low-res features back to the high-res features using the original image as a guide.
- The only loss is “make the upsampled features look like the real high-res features”—no extra bells and whistles.
Why is NAF efficient?
- It only attends to local neighborhoods, not the entire image, making it much faster and lighter on memory.
- It uses a simple dual-branch encoder that captures both per-pixel detail and local context.
- It doesn’t depend on the feature format of any specific VFM, so there’s no retraining or heavy customization.
Main Findings and Results
The paper reports strong results across different tasks and models. In short:
- NAF beats both classic upsampling (like bilinear or bicubic) and modern, model-specific upsamplers on key tasks.
- It works across many VFMs (like DINOv2, RADIOv2.5, Franca, DINOv3)—even huge 7-billion-parameter models—without retraining.
- It improves:
- Semantic segmentation: higher accuracy in labeling each pixel.
- Depth estimation: better precision in predicting how far objects are.
- Open-vocabulary segmentation and video segmentation: better transfer and consistency across frames.
- It’s fast and scales well: up to 2K resolutions with reconstruction at about 18 frames per second, and supports big upscaling ratios.
- Beyond upsampling, it also works impressively on image denoising (cleaning noisy images), despite having far fewer parameters than some specialized restoration models.
These results matter because they show you can have one simple, general tool that works better than specialized ones in many situations.
Implications and Potential Impact
- For developers and researchers: You can plug NAF into different vision systems without retraining for each model, saving time and compute.
- For real-world applications: Better pixel-level performance in areas like medical imaging, autonomous driving, mapping, and video analysis—especially when handling large models or high resolutions.
- For the field: NAF bridges a gap between old-school filters (fast but rigid) and modern learned methods (accurate but model-specific), offering a fast, flexible, and powerful alternative.
- Future directions: Its success in denoising hints that the same neighborhood-attention idea could help in other image restoration tasks like super-resolution, deblurring, or enhancing low-light images.
In short, NAF is a practical, general-purpose way to make visual features precise and useful for detailed tasks—quickly and across many different models.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper leaves several aspects unresolved; below is a list of concrete gaps that future work could address.
- Training regimen transparency and VFM dependence: It is unclear on which VFM(s), datasets, and scales NAF is trained “once,” and whether the reported zero-shot generalization stems from training on one VFM, multiple VFMs, or a VFM-agnostic objective. Provide a clear description and test generalization to truly unseen VFMs (different architectures, patch sizes, tokenization, and normalization) not used during training.
- Scale generalization mismatch: NAF is trained with downsampling factor 2 but evaluated at upsampling ratios as high as ×16–×72. Quantify performance as a function of scale, evaluate multi-scale training, and analyze failure modes at extreme ratios (e.g., aliasing, ringing, boundary artifacts).
- Sensitivity to guidance quality: The upsampler relies solely on the input image for guidance. Assess robustness to real-world degradations (noise, blur, compression, lighting changes, occlusions) and domain shifts (e.g., medical, aerial, thermal, multispectral), including cases where guidance is partially mismatched to the LR features (e.g., rolling shutter, motion).
- Alignment assumptions between image and VFM features: The key construction via average pooling assumes perfect geometric alignment between the HR image pixels and the LR feature grid. Investigate misalignment due to VFM preprocessing (resizing/cropping), patch boundary biases, non-integer strides, or non-grid tokens, and develop alignment correction (offset estimation, anti-aliasing/pre-filtering).
- Neighborhood size and topology: The locality window is fixed (e.g., 9 for upsampling, 15 for restoration). Systematically study the trade-offs of neighborhood radius, shape (square vs. circular), dilation, and adaptive windows per pixel, including learned or content-adaptive neighborhood selection.
- Need for long-range context: Local attention may be insufficient for repetitive textures, large structures, or remote dependencies. Evaluate hierarchical/multi-scale neighborhoods or sparse global connections and quantify gains vs. compute overhead.
- Positional encoding choice and stability: RoPE is favored in ablation, but its behavior under very large relative offsets (high upsampling ratios) and different image sizes/aspect ratios is not analyzed. Compare RoPE to alternative 2D relative encodings (ALiBi, learned relative bias) for stability, accuracy, and numerical conditioning.
- Frequency-domain claim (IDFT interpretation): The paper asserts NAF implicitly predicts spectral coefficients to reconstruct spatial kernels but provides no main-text derivation or empirical verification. Rigorously prove the IDFT formulation, visualize learned kernels, measure frequency responses, and test whether spectral regularization improves performance.
- Channel-wise and multi-head design: Current aggregation applies scalar attention weights to all feature channels. Explore per-channel or per-head weighting, cross-channel mixing strategies, and multi-head neighborhood attention to handle heterogeneous feature dimensions and semantics.
- Loss design beyond L2: Training uses only an L2 reconstruction loss. Evaluate edge-aware, spectral, perceptual, or task-driven losses (e.g., boundary-preserving terms) and multi-task supervision to reduce oversmoothing and enhance fine structures.
- Efficiency on diverse hardware: Claims report GFLOPs/FPS on A100 GPUs. Profile memory bandwidth, latency, and energy on varied hardware (consumer GPUs, CPU, mobile/edge), assess mixed precision/quantization, and provide deployment guidelines.
- Quality vs. maximum upsampling ratio: Table reports maximum ratios that fit in GPU memory but not accuracy at those ratios. Provide accuracy–ratio curves, artifact analysis, and guidelines for safe operating ranges per VFM and task.
- End-to-end training integration: NAF is evaluated mostly as a frozen module with linear probes or downstream pipelines that replace bilinear upsampling. Study end-to-end training (e.g., segmentation networks) with NAF in the loop to assess gradient stability, convergence, and task-specific gains.
- Baseline coverage completeness: Task-specific upsamplers (CARAFE, DySample, SAPA) are discussed but not compared in the VFM-agnostic setting. Include these baselines—adapted appropriately—to validate NAF’s advantages beyond classical filters and VFM-specific methods.
- Dataset and task breadth: Evaluations focus on segmentation, depth, open-vocabulary segmentation, and video propagation. Extend to instance segmentation, optical flow, stereo, surface normals, boundary detection, tracking, and retrieval to test generality of spatial detail recovery.
- Guidance modalities and fusion: NAF uses only RGB guidance. Investigate fusion with auxiliary guidance (edges, gradients, saliency, depth priors), multi-modal inputs (IR, LiDAR), or self-supervised guidance to improve edge preservation and robustness.
- Boundary handling and padding: The paper does not detail treatment near image borders. Analyze border effects, padding strategies, and their impact on edge fidelity and artifacts.
- Scaling laws and hyperparameter selection: Ablations cover C and L but do not provide scaling laws or principled selection strategies. Offer performance–compute trade-off curves and automatic hyperparameter tuning for diverse VFMs and resolutions.
- Pooling strategy nuances: Although average pooling outperforms max and bilinear for keys, the channel alignment rationale is hypothesized rather than tested. Investigate keyed channel alignment, learned pooling, and content-aware aggregation for keys.
- Restoration extension breadth: Image restoration experiments target denoising only. Evaluate deblurring, super-resolution, deraining, dehazing, compression artifact removal, and mixed degradations to validate generality of neighborhood attention filtering.
- Large-model evaluations beyond linear probes: For 7B VFMs, experiments show gains in linear probing and two downstream tasks. Assess broader tasks (e.g., detection, panoptic segmentation, retrieval, in-context segmentation) and measure scalability limits in memory/time for end-to-end pipelines.
- Adversarial sensitivity: Guidance-driven weights may be vulnerable to adversarial perturbations of the input image. Quantify adversarial robustness and explore defenses (e.g., robust encoders, certified bounds on attention weights).
- VFM preprocessing interaction: Different VFMs use different normalization/resizing pipelines, yet NAF’s guidance encoder operates on the raw image. Study whether matching the VFM’s preprocessing in NAF improves alignment, and provide a principled recipe for cross-VFM compatibility.
- Multi-stage feature integration: NAF upscales final-stage features; effects on intermediate layers or multi-scale fusion are not explored. Evaluate applying NAF to earlier stages or aggregating multiple VFM scales to improve fine-grained detail.
Practical Applications
Immediate Applications
Below is a concise set of concrete, deployable use cases that leverage NAF’s zero-shot, VFM-agnostic feature upsampling and image-restoration capabilities.
- Vision pipelines upgrade without retraining
- Sectors: software, robotics, automotive, healthcare, geospatial, retail
- Use case: Replace bilinear/nearest upsampling with NAF in existing segmentation and depth-estimation pipelines (e.g., DINOv2/DINOv3/RADIO/Franca backbones) to immediately improve pixel-level accuracy in semantic segmentation, depth, open-vocabulary segmentation, and video object segmentation.
- Tools/workflows: “NAF UpSampler” as a drop‑in PyTorch/TensorRT module in inference graphs; swap-in for ProxyCLIP or video mask propagation tools.
- Assumptions/dependencies: Access to HR input images and LR VFM features; GPU resources for 18 FPS at target resolutions; compatibility with current preprocessing of chosen VFMs.
- Autonomous driving and robotics perception refinement
- Sectors: robotics, automotive
- Use case: Improve road-scene segmentation and depth estimation using NAF, enhancing drivable-area delineation, lane boundaries, pedestrians/vehicles, and short-range geometry for planning.
- Tools/workflows: ROS/Autoware module that upsamples backbone features before heads; tested on Cityscapes-style scenes.
- Assumptions/dependencies: Real-time constraints (hardware budget, memory); validation under domain shifts (night, weather); integration with current perception stacks.
- Medical image analysis with VFM-agnostic upsampling
- Sectors: healthcare
- Use case: Apply NAF with RADIOv2.5 or similar VFMs to sharpen organ/tumor boundaries for segmentation in radiology or endoscopy without retraining the upsampler per backbone.
- Tools/workflows: PACS-integrated inference where NAF precedes segmentation heads; research-grade pipelines for linear probing and downstream heads.
- Assumptions/dependencies: Clinical validation and regulatory review; image modality differences (grayscale, multi-channel); GPU availability.
- Remote sensing and mapping
- Sectors: geospatial, energy, public works
- Use case: Use NAF to improve feature fidelity for land-cover segmentation and depth/height proxies from aerial/satellite imagery, aiding urban planning and infrastructure monitoring.
- Tools/workflows: Geospatial tiling pipelines (e.g., Raster Vision, TorchGeo) with NAF as the upsampling stage; post-processing for vectorization and GIS ingestion.
- Assumptions/dependencies: Handling very large images via tiling; alignment with georeferencing workflows; compute/memory sizing.
- Industrial inspection and manufacturing QA
- Sectors: manufacturing
- Use case: Enhance fine defect detection (scratches, micro-cracks) by upsampling VFM features for pixel-precise segmentation/classification on production lines.
- Tools/workflows: NAF embedded in vision nodes on edge PCs; integration with MES for defect logging.
- Assumptions/dependencies: Throughput requirements; robustness to lighting/reflectivity variations; camera calibration.
- Video editing and surveillance mask propagation
- Sectors: media, public safety
- Use case: Improve temporal consistency of segmentation masks in video object tracking/propagation tasks.
- Tools/workflows: Plugins for After Effects/Nuke or VOS toolchains where NAF replaces bilinear upsampling; batch processing pipelines for surveillance footage.
- Assumptions/dependencies: Frame rate and latency constraints; dataset-specific tuning of neighborhood size.
- Annotation tooling for dataset creation
- Sectors: software, education, research
- Use case: Sharpen boundaries in interactive annotation tools (e.g., Label Studio) by upsampling features before mask proposals, reducing manual corrections.
- Tools/workflows: “NAF-assisted pre-annotations” in labeling UIs; export masks with better edges.
- Assumptions/dependencies: Integration with tool APIs; human-in-the-loop verification.
- Lightweight image denoising in consumer and enterprise apps
- Sectors: mobile, photography, healthcare
- Use case: Use NAF’s restoration mode for Gaussian and salt‑and‑pepper denoising in camera pipelines, archival image cleanup, or medical image preprocessing.
- Tools/workflows: On-device denoising library with neighborhood attention; server-side cleanup in DAM/CMS systems.
- Assumptions/dependencies: Trained restoration weights for target noise regimes; runtime on mobile NPUs/GPUs; user privacy and image retention policies.
- MLOps resilience to backbone changes
- Sectors: software, finance, e-commerce
- Use case: Standardize an upsampling layer that remains VFM-agnostic, enabling rapid backbone upgrades (e.g., swapping DINOv2→DINOv3) without retraining the upsampler.
- Tools/workflows: CI/CD with NAF in model graphs; A/B testing of backbones with consistent upsampling.
- Assumptions/dependencies: Versioning and compatibility with framework runtimes; reproducible preprocessing across VFMs.
- Academic probing and interpretability
- Sectors: academia
- Use case: Use NAF for feature probing (segmentation/depth linear heads) and for teaching the bridge between classical filtering (JBU, bilateral) and attention via RoPE/IDFT interpretation.
- Tools/workflows: Course labs and benchmarks; ablation suites leveraging NAF’s minimal training setup.
- Assumptions/dependencies: Access to open-source code/checkpoints; datasets and compute.
Long-Term Applications
The following applications are plausible but require further research, scaling, engineering, or validation.
- Real-time HD/4K perception with large VFMs
- Sectors: automotive, robotics, AR/VR
- Use case: End-to-end 4K semantic/depth inference with 7B VFMs and NAF at high FPS for autonomy and AR overlays.
- Tools/workflows: Hardware-accelerated neighborhood attention kernels; mixed-precision inference; model sharding.
- Assumptions/dependencies: Specialized kernels, memory optimization, thermal/power constraints, extensive field testing.
- General image restoration suite (deblur, dehaze, derain, super-resolution)
- Sectors: mobile, media, healthcare
- Use case: Extend NAF’s restoration mode beyond denoising to a unified, interpretable filter-attention framework for multiple degradations.
- Tools/workflows: Modular “NAF-Restore” library with task-specific training heads; camera ISP integration.
- Assumptions/dependencies: Training on diverse degradation distributions; benchmarking vs. SOTA restorers; handling domain shifts.
- Multi-modal sensor fusion via neighborhood attention
- Sectors: robotics, defense, smart cities
- Use case: Use image-guided filtering to fuse LiDAR/RGB, thermal/RGB, radar/RGB features for robust perception under adverse conditions.
- Tools/workflows: Multi-sensor encoders feeding NAF; cross-scale alignment layers; calibration-aware attention.
- Assumptions/dependencies: Accurate sensor calibration; synchronization; robustness to missing modalities.
- Geospatial “NAF-Tiler” for continent-scale inference
- Sectors: geospatial, climate, agriculture
- Use case: Distributed pipelines that run NAF across massive tiled imagery for land-use mapping, crop monitoring, and disaster assessment.
- Tools/workflows: Cloud-native microservices; streaming inference; Dask/Ray orchestration; vector export to GIS.
- Assumptions/dependencies: Efficient tile stitching and halo handling; cost controls; data governance.
- Medical-grade, interpretable upsampling modules
- Sectors: healthcare, policy
- Use case: Regulatory-compliant upsamplers with filter-based interpretability (via IDFT analogy) embedded in clinical decision systems.
- Tools/workflows: Model cards with interpretability reports; audit logs for spatial kernels; clinical trials.
- Assumptions/dependencies: Regulatory pathways (FDA/CE); bias and safety assessments; secure deployment.
- Graphics and game engines: content-aware upsampling
- Sectors: graphics, gaming
- Use case: Integrate NAF to improve texture/detail upsampling and occlusion-aware AR compositing without heavy re-training for different vision backbones.
- Tools/workflows: Engine plugins (Unreal/Unity) with runtime NAF passes; shader-language implementations.
- Assumptions/dependencies: Real-time budgets; GPU-friendly kernels; visual artifact testing.
- Edge AI acceleration and silicon support
- Sectors: semiconductors, mobile, IoT
- Use case: Design NAF-friendly hardware blocks (local attention + RoPE) for efficient feature upsampling/restoration on NPUs.
- Tools/workflows: Compiler support (TVM, XLA), kernel fusion, quantization-aware training.
- Assumptions/dependencies: Vendor adoption; performance/area trade-offs; toolchain maturity.
- Standardization in CV frameworks
- Sectors: software ecosystem
- Use case: Inclusion of NAF as a standard VFM-agnostic upsampler in OpenMMLab/Detectron2/TorchVision, enabling consistent benchmarking and deployment.
- Tools/workflows: API design, ops registration, tutorials, model zoo integration.
- Assumptions/dependencies: Community governance; maintenance and backward compatibility.
- Document understanding and OCR layout refinement
- Sectors: finance, legal, public sector
- Use case: Use NAF to improve fine-grained segmentation of page elements (tables, stamps, signatures) for compliance and automation workflows.
- Tools/workflows: NAF-enhanced vision backbones in OCR stacks (LayoutLMv3 variants + CV VFMs).
- Assumptions/dependencies: Domain adaptation to scans/photos; throughput on enterprise servers.
- Policy and procurement guidance for interoperable AI modules
- Sectors: policy, public procurement
- Use case: Recommend VFM-agnostic, interoperable components (like NAF) to reduce lock-in and compute costs when upgrading models in public-sector AI systems.
- Tools/workflows: Interoperability checklists; cost-efficiency benchmarks; best-practice guides.
- Assumptions/dependencies: Stakeholder coordination; measurable ROI; alignment with privacy and audit requirements.
Glossary
- Average pooling: A pooling operation that computes the average value within a region, often used to downscale or align features. "Attention keys are obtained by average pooling the same features to the low-resolution grid, ensuring geometric alignment with the low-resolution features :"
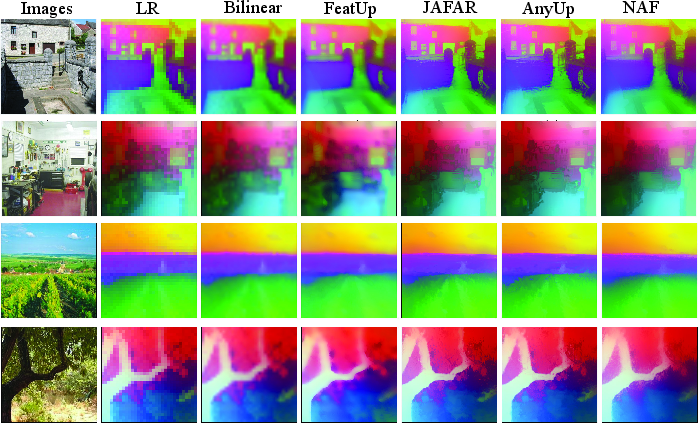
- Bicubic interpolation: A classical image resizing method using cubic polynomials, often used as a strong baseline for upsampling. "surprisingly, recent upsamplers such as JAFAR \citep{jafar}, FeatUp \citep{featup}, and AnyUp \citep{wimmer2025anyup} fail to outperform the bicubic baseline"
- Bilateral filter: An edge-preserving filter that weights neighbors by spatial and intensity similarity. "Classic examples include the bilateral filter~\citep{tomasi1998bilateralfilter}"
- Bilinear interpolation: A simple image resizing method that uses linear interpolation in two dimensions. "We evaluate NAF against both VFM-specific upsamplers \citep{featup,jafar} and VFM-agnostic approaches such as bilinear interpolation"
- CARAFE: A content-aware reassembly module that predicts upsampling kernels conditioned on features. "CARAFE \citep{carafe} and DySample \citep{dysample} predict content-aware kernels or sampling points"
- Channel-wise salt-and-pepper noise: A corruption that randomly flips or nulls individual color channels with some probability. "channel-wise salt-and-pepper noise, meaning we randomly activate or desactivate some channels with corruption probability ."
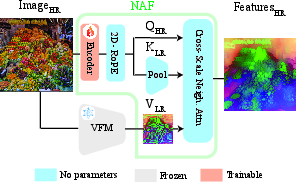
- Cross-Scale Neighborhood Attention: An attention mechanism that restricts interactions to local neighborhoods across different resolutions. "NAF employs a Cross-Scale Neighborhood Attention mechanism where each high-resolution query attends only to a compact neighborhood around its corresponding low-resolution location"
- Denoising: The process of recovering a clean image from a noisy observation. "We focus on image denoising, where the goal is to recover a clean RGB image of size from its corrupted version."
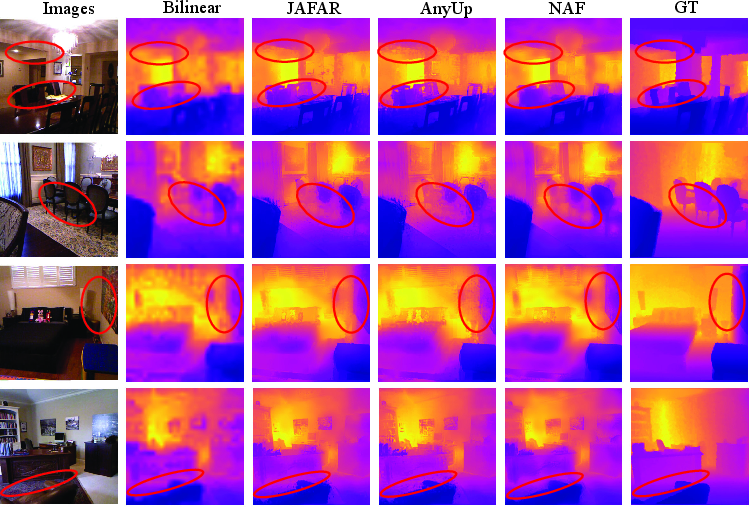
- Depth estimation: Predicting per-pixel scene depth from visual features or images. "A linear layer is then trained on top of the upsampled features to predict per-pixel semantic labels or depth values, depending on the task."
- Delta-1 (δ1): A depth accuracy metric measuring the percentage of predictions within a relative threshold of ground truth. "Depth (NYUv2)"
- Dot-product attention: An attention scoring mechanism using the dot product between queries and keys. "The dot-product attention weights between high-resolution queries and low-resolution keys define an adaptive content kernel"
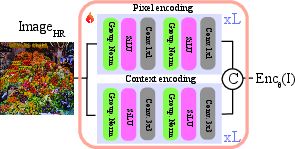
- Encoder–decoder architecture: A neural design with an encoder that compresses inputs and a decoder that reconstructs spatial details. "LiFT uses a CNN-based encoder-decoder architecture."
- Feature map: A multi-channel spatial representation produced by a neural network. "a vision foundation model (VFM) produces a low-resolution feature map $\mathbf{F}^{\mathrm{LR}$"
- GFLOPs: Giga floating-point operations; a measure of computational cost. "achieving about 40\% fewer GFLOPs compared to JAFAR ~\cite{jafar}"
- Guidance image: A high-resolution signal used to steer filtering or upsampling of features. "NAF then upsamples $\mathbf{F}^{\mathrm{LR}$ into $\widehat{\mathbf{F}^{\mathrm{HR} := \operatorname{NAF}(\mathbf{I^\mathrm{HR}, \mathbf{F}^\mathrm{LR})$, using $\mathbf{I}^{\mathrm{HR}$ as the guidance image."
- Image restoration: A family of tasks (e.g., denoising) that recover high-quality images from degraded inputs. "Beyond feature upsampling, NAF demonstrates strong performance on image restoration"
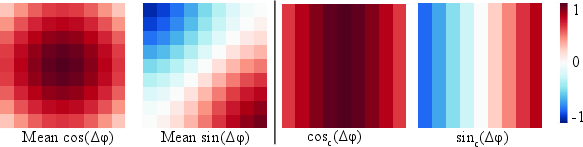
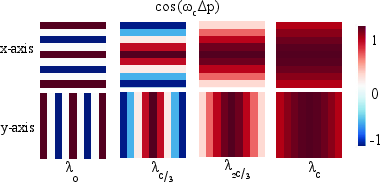
- Inverse Discrete Fourier Transform (IDFT): A transform that reconstructs a spatial signal from frequency-domain coefficients. "We show that this design implicitly learns an Inverse Discrete Fourier Transform (IDFT) of the aggregation"
- Joint Bilateral Filtering: A bilateral filter that uses a separate guidance image to compute weights. "Our architecture parallels classical joint filtering methods, such as Joint Bilateral Filtering and its upsampling variant (JBU)"
- Joint Bilateral Upsampling (JBU): An upsampling method that transfers edge-aware structure from a high-resolution guidance image. "The Joint Bilateral Upsampling (JBU) module \citep{featup} is inherently VFM-agnostic"
- Linear probing: Evaluating feature quality by training a simple linear layer on top of frozen features. "we conduct linear probing experiments on semantic segmentation and depth estimation."
- mIoU (mean Intersection over Union): A common metric for semantic segmentation accuracy. "Semantic segmentation (mIoU )"
- Neighborhood Attention Filtering (NAF): The proposed method that performs zero-shot, VFM-agnostic feature upsampling via local attention guided by the image. "Neighborhood Attention Filtering (NAF) as a Zero-Shot Feature Upsampler: train once, apply efficiently to any Vision Foundation Model"
- Open-vocabulary segmentation: Segmenting categories specified by text prompts rather than a fixed label set. "the transferability of upsampled features to open-vocabulary segmentation"
- Pixel unshuffling: A re-arrangement operation used in up/downsampling pipelines to change spatial resolution. "transposed convolutions or pixel unshuffling \citep{li2018pyramid,ronneberger2015unet,shi2016pixelunshuffling,zhao2017pspnet,long2015fcn}"
- Positional embeddings: Representations added to encode location information for attention mechanisms. "To enable spatial relationship reasoning in the attention formulation, uses positional embeddings on its guidance features."
- ProxyCLIP: A model that evaluates open-vocabulary segmentation using CLIP-like proxies. "We use ProxyCLIP \citep{lan2024proxyclip} to evaluate upsampled representations"
- PSNR (Peak Signal-to-Noise Ratio): A fidelity metric measuring reconstruction quality relative to noise. "Gaussian Denoising ({PSNR} / {SSIM} (\%))"
- Queries and keys: Components of attention; queries retrieve relevant keys to compute weighted combinations. "where , denote queries and keys"
- Receptive fields: The spatial extent of input that influences a feature's response. "aligning receptive fields across resolutions while keeping attention localized and efficient."
- Restormer: A transformer-based image restoration model used as a strong baseline. "a state-of-the-art transformer-based model, Restormer~\citep{Zamir2021Restormer}"
- Rotary Position Embeddings (RoPE): A positional encoding method that rotates features to encode relative positions. "To encode relative positional information, we apply 2D Rotary Positional Embeddings (RoPE)"
- Scale invariance: The property of producing consistent outputs across different input scales. "only few VFMs exhibit scale invariance and handle non-standard resolutions effectively"
- Semantic segmentation: Assigning a semantic label to each pixel in an image. "we conduct linear probing experiments on semantic segmentation and depth estimation."
- Spectral coefficients: Frequency-domain parameters used to reconstruct spatial filters via inverse transforms. "NAF predicts spectral coefficients that reconstruct an adaptive, data-dependent upsampling filter."
- SSIM (Structural Similarity Index): A perceptual metric for assessing image similarity and quality. "Gaussian Denoising ({PSNR} / {SSIM} (\%))"
- Transposed convolutions: Learnable upsampling layers that invert the spatial effect of convolutions. "Early techniques rely on standard methods like transposed convolutions or pixel unshuffling"
- Upsampling factor: The scale by which a feature map’s spatial resolution is increased. "for an upsampling factor ."
- VFM-agnostic: Independent of the specific Vision Foundation Model used to produce features. "We introduce Neighborhood Attention Filtering (NAF), a VFM-agnostic upsampling module"
- Vision Foundation Models (VFMs): Large pre-trained vision backbones used across diverse tasks. "Vision Foundation Models (VFMs) extract spatially downsampled representations"
- Video object segmentation: Tracking and segmenting objects across frames in a video. "Video Object Segmentation"
- Zero-shot: Performing a task without task-specific retraining or supervision on the target model/data. "NAF operates zero-shot: it upsamples features from any VFM without retraining"
Collections
Sign up for free to add this paper to one or more collections.