Loomis Painter: Reconstructing the Painting Process
Abstract: Step-by-step painting tutorials are vital for learning artistic techniques, but existing video resources (e.g., YouTube) lack interactivity and personalization. While recent generative models have advanced artistic image synthesis, they struggle to generalize across media and often show temporal or structural inconsistencies, hindering faithful reproduction of human creative workflows. To address this, we propose a unified framework for multi-media painting process generation with a semantics-driven style control mechanism that embeds multiple media into a diffusion models conditional space and uses cross-medium style augmentation. This enables consistent texture evolution and process transfer across styles. A reverse-painting training strategy further ensures smooth, human-aligned generation. We also build a large-scale dataset of real painting processes and evaluate cross-media consistency, temporal coherence, and final-image fidelity, achieving strong results on LPIPS, DINO, and CLIP metrics. Finally, our Perceptual Distance Profile (PDP) curve quantitatively models the creative sequence, i.e., composition, color blocking, and detail refinement, mirroring human artistic progression.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper presents Loomis Painter, an AI system that can show the step-by-step process of making a painting from a single finished image. It can do this in a realistic, human-like way and even switch between different art materials such as oil paint, acrylic, and pencil. The name comes from the Loomis method, a classic way to draw heads with correct proportions. This system can recreate that kind of structured process too.
What questions does the paper try to answer?
The authors focus on three simple goals:
- How can an AI recreate a believable, smooth painting process, not just the final image?
- How can it handle different art materials (like oil, acrylic, pencil) and still keep the content consistent?
- How can we measure whether the step-by-step process looks like how humans actually paint?
How does it work? (Methods in simple terms)
The system uses a “video-making” AI and teaches it to produce painting steps as a short video. Here are the key ideas, explained with everyday analogies:
- Video diffusion model: Imagine starting with a TV full of static (random noise) and slowly “sculpting” it into a clear video, frame by frame. The AI learns how to turn noise into a sequence of images that look like a painting being made.
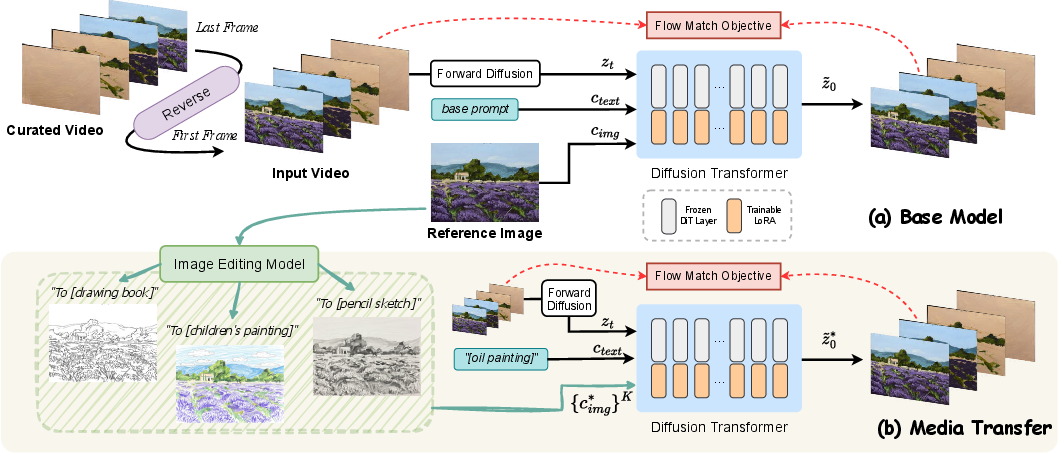
- Media-aware control (telling the AI which art material to use): The AI is given a short text description like “oil painting” or “pencil sketch.” This works like giving the AI a “style instruction,” so it knows how textures and strokes should evolve over time for that medium (for example, thick layered color for oil, light hatching for pencil).
- Cross-media style training: Think of dressing the same person in different outfits to teach the AI that “under the style, the person is the same.” The authors transform the look of the input image into different styles but keep the objects and structure the same. This helps the AI learn how to keep the content consistent while changing the art medium.
- Reverse-painting strategy (learning backwards): Instead of learning to go from a blank canvas to the final image, the AI learns the process backwards—from the finished painting back to a blank canvas. This matches how the video AI is designed (it expects the first frame to be the given image), and it makes the steps flow more smoothly without weird jumps.
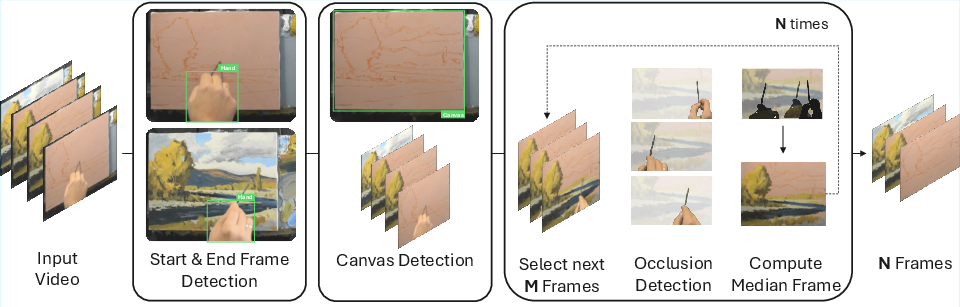
- A clean, real-world dataset: The authors collected many real painting tutorial videos (acrylic, oil, pencil, and Loomis head drawing). They built a pipeline to:
- Find the start and end of the painting part,
- Keep the camera and canvas area consistent,
- Remove hands, brushes, and logos so the AI can clearly see each step on the canvas.
What did they find, and why does it matter?
- More realistic painting steps: The AI produces sequences that look like how artists work—starting with structure, then blocking in colors, then adding details. This is important for learning and teaching.
- Works across multiple media: The same input image can be “painted” as an oil work, an acrylic painting, or a pencil sketch, with believable strokes and textures for each material.
- Better scores than other methods: On tests that check how similar images look (LPIPS), how well they match content (CLIP, DINO), and overall quality, this system scores higher than previous methods. In simple terms: its results are more faithful and consistent.
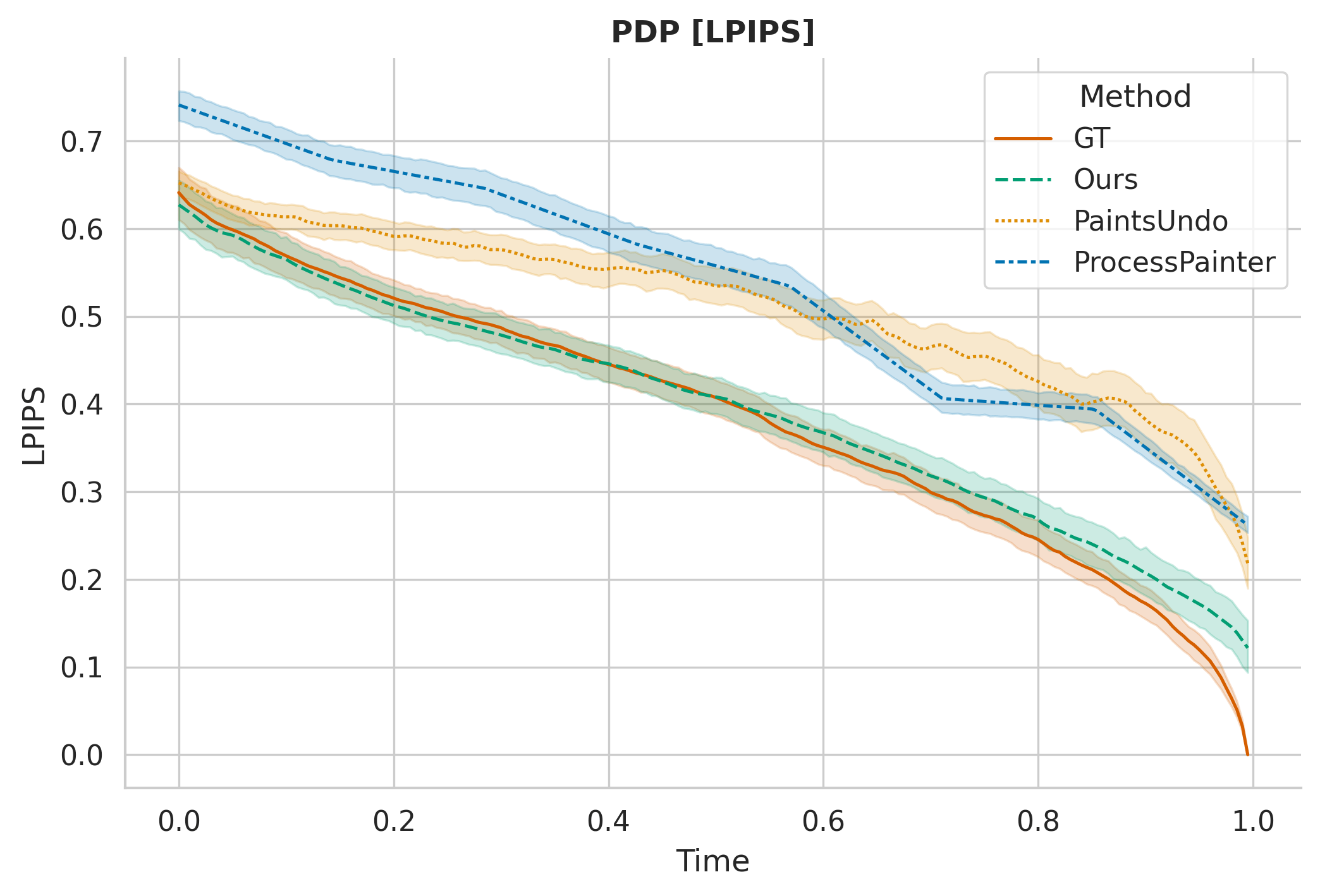
- New way to measure “process quality”: They introduce the Perceptual Distance Profile (PDP), a curve that tracks how each step moves closer to the final image. It shows that their AI follows a human-like path: composition → color blocking → detail refinement.
- Reverse learning helps: Training the model to “unpaint” (go from finished to blank) makes the forward, human-viewing process (blank to finished) much smoother and more accurate.
Why is this useful? (Implications)
- Better art learning: Instead of watching a passive video, students could get customized, interactive painting steps for any reference photo and any medium. It could become a smart, personal art tutor.
- Cross-style creativity: Artists and learners can see how the same subject would be built up in oil vs. acrylic vs. pencil, helping them understand techniques across media.
- Broader potential: The idea of reconstructing a process step-by-step could help in other areas too—like teaching crafts, design workflows, or animation.
The authors also note some limitations: artifacts from hand shadows can slip through, and the model may struggle with content-media combinations it didn’t see during training. In the future, they want the system to explain more practical details—like which brushes to use, how to mix colors, and how to apply them—making it even more helpful for real-world learning.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, stated concretely to guide future work.
- Dataset coverage and balance: The curated data spans only acrylic, oil, pencil, and Loomis-style portraits, with heavy imbalance (e.g., pencil-heavy) and no watercolor, gouache, pastel, charcoal, ink, or digital media; assess generalization and extend to broader, balanced media sets.
- Static setup bias: The dataset deliberately excludes camera motion and canvas movement; evaluate robustness to real-world setups (handheld cameras, perspective changes, zooms, rotations, lighting shifts).
- Occlusion handling: The occlusion-removal pipeline fails on hand shadows and persistent occlusions, introducing dark artifacts and potential temporal blur; develop shadow-aware detection, long-occlusion modeling, and quantify the impact on training.
- Loss of tool semantics: Removing hands/brushes eliminates critical cues about tool usage, pressure, speed, and stroke direction; collect and model tool-state signals (brush type, pressure, angle) and evaluate whether retaining tool visibility improves process realism.
- Cross-media augmentation specifics: The “image editing models” used to generate style-transformed inputs (I*) are unspecified; detail the exact models, transformation parameters, and guarantees of semantic preservation, and analyze their effect via ablations.
- Text conditioning transparency: The text encoder E_text and prompt engineering strategy are not specified; report the encoder choice, prompt templates, sensitivity analyses, and mechanisms for medium-aware prompt construction.
- Cross-media transfer limitations: Failures occur for unseen content–medium pairs (e.g., Loomis on non-portraits, acrylic on portraits); investigate zero-shot transfer, domain adaptation, and curriculum strategies to expand viable pairings.
- Portrait competency gap: The base model struggles with portraits due to insufficient exposure; quantify coverage gaps and evaluate targeted data augmentation or specialized portrait modules.
- Evaluation alignment ambiguities: “Closest corresponding ground-truth frame” matching is not rigorously defined; formalize frame alignment criteria, provide code to reproduce alignment, and compare against alternative alignment strategies (e.g., DTW, phase segmentation).
- PDP metric validity: PDP uses distances to the final frame and may be medium/style-sensitive; validate PDP with expert annotations of process phases, test medium-invariance, and add baselines like FVD/temporal consistency metrics tailored to process plausibility.
- Lack of user studies: No evaluation of pedagogical effectiveness, interactivity benefits, or perceived realism by artists/learners; conduct controlled user studies with artists and novices to assess instructional utility and learning outcomes.
- Baseline fairness: Compared methods may be domain-mismatched (e.g., anime-focused), with limited frames or without fine-tuning on the same dataset; run fair, same-data fine-tunes and matched inference settings to strengthen comparative claims.
- Scalability and efficiency: Inference speed, memory footprint, and resolution scaling (beyond 480×832) are not reported; benchmark runtime, latency for interactive use, and high-resolution generation.
- Forward vs. reverse-generation realism: Training in reverse and flipping outputs at inference may distort causal stroke dynamics; empirically test whether forward-trained models with temporally aligned conditioning yield more realistic stroke order.
- Conditioning alignment design: The temporal/channel concatenation mismatch is sidestepped by reverse training rather than redesign; explore architectures that temporally align the I2V conditioning without reversing sequences.
- Component-wise ablations: Only the reverse-order ablation is shown; add ablations isolating medium-aware semantic embedding, cross-media structural alignment, occlusion removal, and prompt conditioning to quantify each contribution.
- Ground truth for cross-media: Cross-media transfer lacks a real ground-truth process for the transformed style; create paired, multi-medium records of the same scene to objectively evaluate cross-media procedural fidelity.
- Reproducibility constraints: The dataset will not be released due to licensing; clarify availability of LoRA weights, detailed training recipes, and synthetic substitutes to enable independent replication.
- Ethical and legal considerations: The use of YouTube/tutorial content and style/process replication raises consent and attribution issues; propose data governance, licensing compliance, and opt-out mechanisms for artists.
- Tool/color pedagogy: The future-work vision (colors, mixing, brushes) is not operationalized; design data collection (palette tracking, pigment states), sensors or annotations, and modeling heads to predict tool actions and color recipes.
- Prompt and scene semantics: Prompts are handcrafted and may bias outputs; develop automatic scene description from the input image (object/region/lighting extraction) and study prompt robustness to wording variability.
- Sequence length control: The method does not expose controls over number of steps or phase durations; add knobs for pacing (composition/blocking/detail), and evaluate their pedagogical impact.
- Loomis method evaluation: No quantitative measure of proportion accuracy or adherence to Loomis guidelines; devise metrics (landmark ratios, construction line alignment) and test on portrait benchmarks.
- De-occlusion artifacts: Masked medians may smear temporal details; investigate generative layer separation, temporal inpainting, or optical flow-based de-occlusion and compare artifact rates quantitatively.
- Generalization beyond single-image input: The system is image-to-video only; explore text-to-process, multi-view references, or video-to-process reconstruction, and assess data needs for these modes.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s generative video and fine-tuning stacks, leveraging the paper’s reverse-painting training, cross-media conditioning, dataset curation pipeline, and PDP evaluation.
- Industry (Creative software): AI “Process-from-Image” plugin
- Description: Given a finished artwork or photo, generate a temporally coherent, step-by-step painting process (sketch → block-in → refinement) that users can scrub through, export, or follow.
- Potential tools/workflows: Plugins for Photoshop, Procreate, Krita, Blender’s Grease Pencil; scrubbable timelines; side-by-side “reference vs. process” panels.
- Dependencies/assumptions: Access to an I2V diffusion base (e.g., Wan 2.1) and LoRA fine-tuning; compute for inference; rights to input images; current limitations on portraits and some media-content combinations noted in the paper.
- Industry (Creative software, EdTech): Cross-medium process transfer
- Description: Render any input scene as “oil,” “acrylic,” or “pencil (Loomis)” with the corresponding procedural steps and textures.
- Potential tools/workflows: “Medium Transfer Painter” module for DCC tools; educational presets that show “how an oil painter would do this.”
- Dependencies/assumptions: Model reliability varies by medium-content combination (paper notes failures on certain pairings); prompt design and curated prompts per medium help.
- Education (Art pedagogy): Interactive, personalized painting tutorials
- Description: Transform static references or class exemplars into interactive tutorials aligned with human workflows (composition → color blocking → detail), adjustable by skill level, pacing, and medium.
- Potential tools/workflows: LMS integrations (Canvas, Moodle) with per-lesson process videos; teacher dashboards to generate “variant” demos for the same subject.
- Dependencies/assumptions: Licensing for source content; on-prem or cloud GPU for batch generation; accessibility features for different learners.
- Education/Research (Assessment): PDP-based process feedback and grading rubrics
- Description: Use the Perceptual Distance Profile (PDP) to compare a student’s recorded process against an exemplar’s progression, flagging structural jumps or missing stages.
- Potential tools/workflows: PDP scoring widget; analytics dashboards; alerts when temporal coherence deviates from target workflows.
- Dependencies/assumptions: Requires student process capture (video or frame sampling); PDP depends on the chosen perceptual metric (LPIPS/DINO/CLIP) and is not a substitute for expert judgment.
- Media/Marketing (Creator economy): Process reels from finished art
- Description: Auto-generate engaging “time-lapse” painting sequences for social platforms (YouTube Shorts, TikTok, Instagram) from final images.
- Potential tools/workflows: Batch pipeline to ingest portfolios → produce short-form “process” clips with captions; A/B test different media styles.
- Dependencies/assumptions: Content rights; inference cost vs. volume; QC to avoid failure modes.
- Cultural Heritage/Museums: Visitor-facing reconstructions of historical painting workflows
- Description: Produce exhibit videos that hypothesize how a known artwork could have been constructed, with medium-specific staging and commentary.
- Potential tools/workflows: Kiosk viewers; AR overlays next to the original piece; curator-led annotations aligned to process frames.
- Dependencies/assumptions: Outputs are didactic reconstructions, not ground truth; curator review for historical accuracy; high-res imagery access.
- E-commerce (Art materials): Medium-specific “how this brush/paint behaves” demos
- Description: Generate synthetic demonstrations showing how a given product (e.g., sable brush, heavy-body acrylic) changes the process and texture evolution.
- Potential tools/workflows: Product pages with interactive process demos; bundled lesson downloads.
- Dependencies/assumptions: Requires domain prompts and potentially small fine-tunes per product line; calibration with real demos improves credibility.
- Academia (CV/Graphics): Benchmarking and ablation analysis with PDP
- Description: Adopt PDP to evaluate temporal plausibility in process-generation research beyond painting (e.g., procedural CAD, 3D sculpting sequences).
- Potential tools/workflows: Open-source evaluation scripts; paper reproducibility checklists featuring PDP curves.
- Dependencies/assumptions: Consistent protocol for frame alignment and metric choice; community agreement on benchmarks.
- Data Engineering (Content pipelines): Occlusion-free tutorial dataset preparation
- Description: Use the paper’s start/end detection, canvas localization, and masked-median occlusion removal to prepare training and publication-grade tutorial data.
- Potential tools/workflows: Batch video processors for YouTube/VOD content; dataset QA dashboards.
- Dependencies/assumptions: Rights to source videos; hand-shadow artifacts can persist (paper limitation); variable performance with moving cameras.
- Daily Life (Hobbyists): At-home “coach” for step-by-step practice
- Description: Turn a user’s reference into a medium-aware, stepwise plan they can follow, pause, and replay.
- Potential tools/workflows: Mobile app with offline caching; printable “process cards” with key frames and notes.
- Dependencies/assumptions: Cloud inference may be needed for higher quality; portrait performance caveats.
- Software/Platform Ops: Cost-optimized LoRA fine-tuning workflows
- Description: Rapidly specialize a base I2V model to studio or school datasets via LoRA for consistent house styles and mediums.
- Potential tools/workflows: MLOps recipes (training on 4×H100 ≈24h); versioned LoRA registries; prompt libraries per medium.
- Dependencies/assumptions: Access to base model weights; licensing of training data; monitoring to avoid overfitting.
Long-Term Applications
These applications require further research, scaling, or integration (e.g., real-time constraints, richer supervision, additional sensors, or new datasets).
- Education/EdTech: Intelligent tutoring systems with material/tool guidance
- Description: Real-time “next-stroke” recommender that also suggests brush type, color mix, load, and stroke direction.
- Potential tools/workflows: Multi-modal tutor that listens (voice), sees (camera), and overlays guidance; lesson plans that adapt to user PDP trajectories.
- Dependencies/assumptions: New data capturing tool choices and color mixing; UX for safe, non-intrusive assistance; on-device or low-latency cloud inference.
- AR/XR (Spatial computing): Live overlay of step-by-step instructions on a physical canvas
- Description: Headset or phone AR aligns generated process frames with the user’s canvas and guides execution in situ.
- Potential tools/workflows: Pose-tracking and canvas registration; dynamic correction when the user deviates from plan.
- Dependencies/assumptions: Robust real-time tracking; low-latency video diffusion or distilled models; safety and ergonomics.
- Robotics (Creative automation): Stroke planning for robot painters
- Description: Convert generated process sequences into executable stroke trajectories for robotic arms with brush dynamics.
- Potential tools/workflows: Simulator-augmented training; control stacks that map textures to force/velocity profiles; closed-loop vision feedback.
- Dependencies/assumptions: High-fidelity physical modeling of paint and substrates; safety; sim-to-real transfer.
- Cultural Heritage (Research/Restoration): Hypothesis testing for lost layers and underdrawings
- Description: Combine cross-media process modeling with spectral imaging to propose plausible historical workflows and layer orders.
- Potential tools/workflows: Multi-spectral data fusion; conservator-in-the-loop evaluation of candidate sequences.
- Dependencies/assumptions: Access to technical imaging; careful validation to avoid spurious claims; ethical guidelines.
- Healthcare (Rehabilitation, Art therapy): Fine-motor training and progress tracking
- Description: Use stepwise painting plans to scaffold motor tasks; PDP-like metrics to quantify improvement over sessions.
- Potential tools/workflows: Therapist dashboards; adaptive difficulty; haptic-assisted tools.
- Dependencies/assumptions: Clinical validation; safety reviews; domain-specific datasets and protocols.
- Enterprise L&D (Design/Concept art): Curriculum auto-generation and skills mapping
- Description: Generate progression-aligned courses and exercises for specific house styles or mediums; analyze learner PDPs to tailor assignments.
- Potential tools/workflows: Course builders; skill-gap analytics; certification paths linked to process quality.
- Dependencies/assumptions: Larger, licensed institutional datasets; long-term model maintenance.
- Policy and Governance: Guidelines for process-generative educational content
- Description: Standards for attribution, disclosure, and dataset licensing when synthesizing tutorials from third-party videos or artworks.
- Potential tools/workflows: Policy templates for schools/museums; procurement checklists; transparency labels indicating synthetic processes.
- Dependencies/assumptions: Cross-stakeholder consensus (educators, rights holders); evolving copyright case law.
- Provenance and Forensics: Process-aware authenticity checks
- Description: Use process signatures or PDP patterns to differentiate genuine recorded workflows from synthesized ones, or to embed benign, process-level watermarks.
- Potential tools/workflows: Forensic analyzers; watermarking schemes in temporal latent space.
- Dependencies/assumptions: Research into robust, hard-to-spoof process features; alignment with platform moderation policies.
- Cross-domain procedural modeling: Beyond painting (calligraphy, sculpting, CAD, cooking)
- Description: Apply reverse-process training and PDP evaluation to other structured creation domains where outputs evolve from coarse to fine.
- Potential tools/workflows: Domain adapters; task-specific condition signals (e.g., toolpaths, recipes).
- Dependencies/assumptions: Domain datasets with clean process capture; custom perceptual metrics beyond LPIPS/CLIP/DINO.
- Real-time, low-cost deployment: On-device process generation
- Description: Distill large video diffusion models into efficient, mobile-friendly variants for classroom or hobbyist use without cloud.
- Potential tools/workflows: Knowledge distillation, caching, quantization; progressive rendering.
- Dependencies/assumptions: Research into compact video diffusion; acceptable quality-speed trade-offs.
Notes on general assumptions across applications:
- Model quality depends on base model capacity, LoRA fine-tuning, and prompt engineering; current limitations include portrait reconstruction in the base model and certain medium-content pairings in the media-transfer model.
- Data licensing is critical; the paper’s dataset cannot be released due to rights. Any scaled deployment must implement compliant data collection and consent workflows.
- PDP is a useful comparative metric for temporal plausibility but should complement expert evaluation, not replace it.
Glossary
- Ablation: An experimental analysis that removes or alters components to assess their impact on results. "Comparison of final frame. On the left, we see that the Ablation is not able to reconstruct the input image fully; several details are still missing, i.e., the bottom right part is not complete."
- Autoregressive: A sequential modeling approach where each output depends on previous outputs. "Inverse Painting~\cite{chen2024inverse} advanced this painting workflow reconstruction with an autoregressive three-stage pipeline that compares intermediate frames with the reference, masks the next operation area, and updates pixels through diffusion."
- BiRefNet: A model for high-resolution dichotomous image segmentation used to detect or segment occlusions. "Occlusions (e.g., hands, brushes) are segmented using InSPyReNet \cite{kim2022revisiting} or BiRefNet \cite{BiRefNet}."
- CLIP: A vision-LLM and metric measuring image-text similarity, used for evaluating fidelity and consistency. "achieving strong results on LPIPS, DINO, and CLIP metrics."
- ControlNet: A conditioning framework that adds control signals (e.g., edges, poses) to text-to-image diffusion models. "pretrained diffusion models can be fine-tuned using various lightweight techniques to adapt them to new concepts or personalize outputs, e.g., LoRA \cite{hu2022lora}, ControlNet \cite{zhang2023adding}, and IPAdapter \cite{ye2023ip}, all of which are more computationally efficient than training a model from scratch."
- Cross-attention: An attention mechanism that injects conditioning information (e.g., text embeddings) into a model’s latent features. "During diffusion-based temporal generation, $\mathbf{c_{text}$ is injected through cross-attention:"
- Cross-media training: A strategy that aligns structural content across styles by training with style-transformed inputs while keeping the same target video latent. "For cross-media training, we keep the same target video latent but replace with its transformed counterpart :"
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion models that predicts velocity fields or noise. "This latent is used to train a Diffusion Transformer (DiT) \cite{peebles2023scalable} with the Flow Matching objective"
- DINO: A self-supervised vision transformer representation used as a perceptual similarity metric. "achieving strong results on LPIPS, DINO, and CLIP metrics."
- Dinov2: An improved version of DINO used as a perceptual similarity metric. "We evaluate our method against state-of-the-art baselines using LPIPS, CLIP and Dinov2 (to assess perceptual similarity to human workflows)"
- FID: Fréchet Inception Distance, a metric for distributional similarity between generated and real data. "and FID \cite{DOWSON1982450} (to measure distributional alignment with ground-truth painting sequences)."
- Flow Matching: A generative modeling objective that trains models to match the velocity field of an interpolation between noise and data. "with the Flow Matching objective \cite{lipman2022flow, esser2024scaling}"
- GroundingDINO: An open-set object detection model used for detecting hands, canvases, logos, and text in videos. "using GroundingDINO \cite{liu2024grounding} to isolate the core painting process."
- Image-to-Video (I2V): Approaches that extend a single image into a temporally coherent video by conditioning on the image. "Image-to-video (I2V) approaches \cite{wan2025wan, lin2024open, peng2025open} extend an input image into a sparse video tensor "
- InSPyReNet: A salient object detection model used to segment transient occlusions like hands or brushes. "Occlusions (e.g., hands, brushes) are segmented using InSPyReNet \cite{kim2022revisiting} or BiRefNet \cite{BiRefNet}."
- IPAdapter: An adapter that enables image-based prompts for diffusion models to personalize outputs. "pretrained diffusion models can be fine-tuned using various lightweight techniques to adapt them to new concepts or personalize outputs, e.g., LoRA \cite{hu2022lora}, ControlNet \cite{zhang2023adding}, and IPAdapter \cite{ye2023ip}"
- LaMa: A large-mask inpainting model used to remove logos and text overlays from frames. "Finally, in post-processing, we detect logos and text with GroundingDINO \cite{liu2024grounding} and inpaint them using LaMa \cite{suvorov2022resolution}."
- LoRA: Low-Rank Adaptation, an efficient fine-tuning technique for large models. "The model can be fine-tuned with LoRA adapters on the dataset in 24h on 4 Nvidia H100 GPUs"
- Loomis Method: A structured portrait drawing technique focusing on correct proportions and construction. "A prominent example is the Loomis Method \cite{loomis2021drawing}, developed by Andrew Loomis, which demonstrates a structural approach to drawing a head with correct proportions."
- Masked median: A robust aggregation over frames that computes the median while ignoring masked occluded regions. "A clean frame for each segment is generated by computing a masked median of its samples; this calculation iteratively incorporates prior frames to fill persistent occlusions."
- Perceptual Distance Profile (PDP): A metric that models the temporal progression of perceptual distance to the final image across frames. "To evaluate the temporal consistency and plausibility of the painting process, we introduce the Perceptual Distance Profile (PDP), a novel metric designed to compare the sequence of a generated video against its ground truth counterpart."
- Temporal compression: Reduction of the number of temporal frames in the latent representation to enable efficient multi-frame generation. "the temporal compression is set to 4 or 8"
- Video-VAE: A variational autoencoder for videos that encodes pixel-space sequences into compact latent representations. "consisting of a video-VAE to encode a given video from pixel space into latent space"
Collections
Sign up for free to add this paper to one or more collections.

