- The paper presents a novel human-aware 3D semantic occupancy dataset that integrates RGB, LiDAR, and a hybrid mesh optimization pipeline.
- It employs ICP-based alignment and multi-term loss optimization to achieve a PVE of 50.5 mm and MPJPE of 39.1 mm, enhancing prediction accuracy.
- The dataset enables comprehensive benchmarking for occupancy prediction, pedestrian detection, and velocity estimation in crowded, dynamic environments.
MobileOcc: A Human-Aware Semantic Occupancy Dataset for Mobile Robots
Motivation and Distinctive Contributions
Dense 3D semantic occupancy prediction underpins robust navigation for mobile robots, yet prevailing datasets and frameworks have centered on autonomous driving and rigid objects, neglecting dynamic, deformable entities such as humans. "MobileOcc: A Human-Aware Semantic Occupancy Dataset for Mobile Robots" (2511.16949) directly addresses this gap by introducing a dataset and annotation pipeline targeted at human-rich, near-field environments where pedestrian interaction dominates the navigation workload of assistive and service robots.
The primary contributions include (1) MobileOcc, the first 3D semantic occupancy dataset with a focus on dynamic human modeling in crowded scenes, (2) a hybrid annotation pipeline that fuses RGB, LiDAR, and advanced mesh optimization to yield accurate non-rigid human occupancy labels, and (3) comprehensive benchmarking on occupancy prediction and pedestrian velocity forecasting, with strong baselines adaptable to the mobile robotics domain. The methodology is further validated on standard 3D human pose datasets, demonstrating its general robustness.
Dataset Construction and Annotation Pipeline
The dataset is constructed from the UT Campus Object Dataset (CODa), capturing the operational domain of mobile robots in pedestrian-dense settings. The annotation pipeline consists of four main modules: data preprocessing, static map generation, human mesh optimization, and voxelized 3D occupancy representation. Figure 1 illustrates the entire workflow, highlighting the multi-modal data fusion and modular annotation strategy.
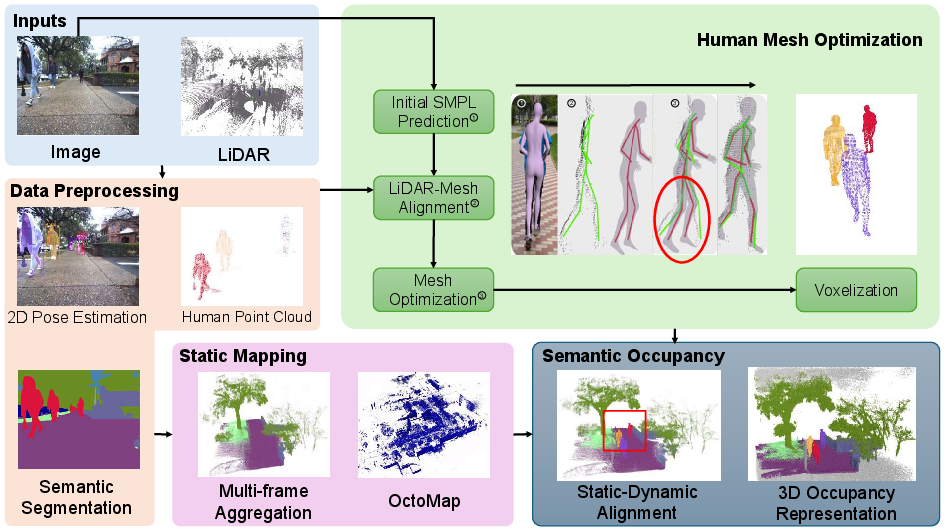
Figure 1: The MobileOcc pipeline: data preprocessing, static semantic mapping, human mesh optimization, and generation of the joint 3D occupancy representation using Cityscapes label priors.
The core technical novelty is the human mesh optimization procedure, which proceeds as follows:
- Initial 3D SMPL mesh prediction is inferred from monocular RGB using CLIFF, encoding both pose and anthropometric shape.
- This initial mesh is refined by fusing corresponding LiDAR returns using (i) visibility filtering, (ii) ICP-based global alignment, and (iii) joint optimization of pose and shape via a multi-term loss integrating 2D reprojection error, 3D LiDAR Chamfer distance, pose and shape priors, and occlusion consistency. This ensures robust mesh alignment in both absolute 3D space and articulated pose, mitigating scale/depth ambiguities, occlusion effects, and anatomical implausibility.
For static background, a LiDAR-camera fusion process aggregates multi-frame semantic point clouds, suppressing dynamic pedestrian traces to prevent ghosting and maintain fidelity in the static component. The human-resolved meshes and static voxels are then fused in a local frame to yield a fully aligned, per-frame 3D occupancy grid with both semantic segmentation and unique human instance IDs.
Quantitative and Qualitative Results
MobileOcc's mesh optimization pipeline is validated both on synthetic LiDAR (3DPW) and real-world datasets (SLOPER4D, HumanM3), employing standard metrics: Per-Vertex Error (PVE), MPJPE, Procrustes-Aligned MPJPE, and MPERE. With simulated dense LiDAR, the method achieves a PVE of 50.5 mm and MPJPE of 39.1 mm, outperforming all RGB/image-only HMR methods by a substantial margin, even without root alignment. Accuracy scales with LiDAR density, as denser returns facilitate better correspondence and error correction. On SLOPER4D and HumanM3, the approach remains competitive with dedicated LiDAR-trained HMR models, despite operating in a training-free, test-time optimization regime.
Figure 2 visualizes occupancy labels at both fine and coarse resolutions, demonstrating the fidelity of human mesh recovery and spatial alignment in complex, cluttered scenes.

Figure 2: MobileOcc qualitative results: input image (top), fine-resolution ($0.02$ m) occupancy (middle), coarse-resolution ($0.2$ m) occupancy (bottom); gray voxels indicate unknown space.
Semantic Occupancy and Panoptic Baselines
Extensive benchmarks are established using monocular (BEVDet4D, FlashOcc, Panoptic-FlashOcc), stereo (VoxFormer), and velocity-augmented (Panoptic-FlashOcc-vel) frameworks. FlashOcc achieves the highest mean IoU (mIoU) for semantic occupancy; VoxFormer demonstrates robust pedestrian detection, benefitting from stereo depth input. Panoptic-FlashOcc supports full panoptic segmentation, reporting pedestrian AP up to 45.5% at 1 m distance threshold, and PQdagger^ up to 28.1.
Qualitative comparisons under diverse lighting conditions, including challenging night and low-illumination settings, illustrate the resilience of the fused annotation pipeline and the panoptic segmentation frameworks (see Figure 3 and Figure 4).


Figure 3: Visual comparison of occupancy baselines (e.g., BEVDet4D, FlashOcc) under varying lighting, evidencing robustness in complex illumination.



Figure 4: Panoptic occupancy prediction with Panoptic-FlashOcc (8f): high spatial coherence and instance segmentation even for dynamic humans.
For the pedestrian velocity estimation task, the Panoptic-FlashOcc-vel model achieves absolute velocity error on par with object-detection-based methods (e.g., BEVDet4D), while additionally producing semantically segmented velocity fields (Figure 5). Failure cases, such as walking direction ambiguity, highlight open research challenges.
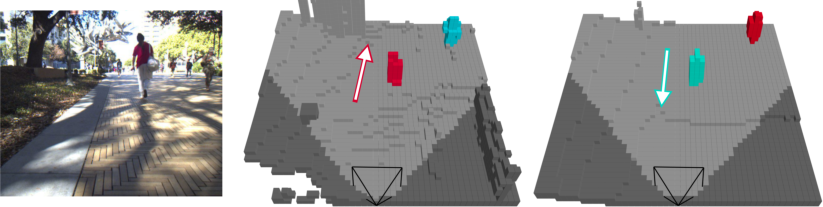
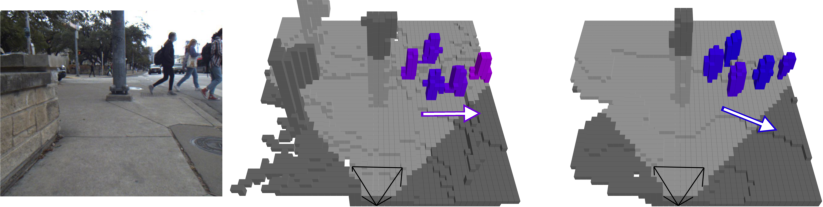
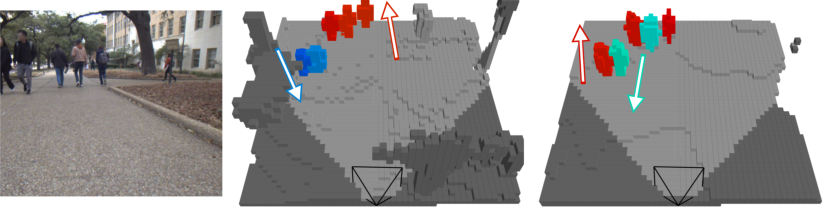
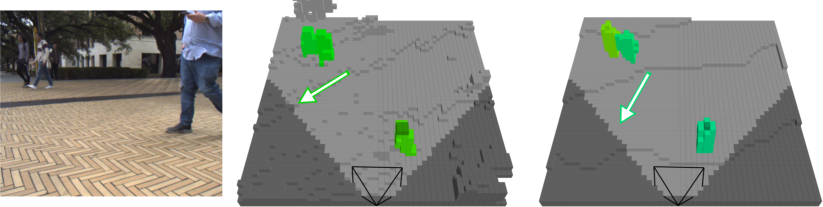
Figure 5: Pedestrian velocity prediction examples: velocity directions for detected pedestrians in voxelwise format, visualized with color encodings and arrows.
Implications and Future Directions
From a practical perspective, MobileOcc is positioned as a new benchmark for close-proximity robot navigation, where panoptic 3D reasoning about deformable agents is essential for motion planning and social compliance. The annotation pipeline is transferable, requiring little dataset-specific tuning due to its test-time optimization design, and is robust across sensor modalities and environments. The mesh optimization framework, especially its fusion of monocular and LiDAR cues, suggests that hybrid multi-modal models offer a tractable path to high-fidelity, real-world perception outside of controlled automotive settings.
Theoretically, the results demonstrate that direct optimization using LiDAR constraints can close the gap with fully supervised, LiDAR-trained end-to-end models, especially when visibility- and occlusion-aware priors are imposed. This opens opportunities for leveraging large-scale, weakly labeled or unlabeled datasets in future self-supervised 3D semantic perception.
Immediate research directions include:
- Domain extension to indoor scenes, variable environmental conditions, and interaction-rich contexts.
- Methodological improvements in velocity estimation and mutual human-robot intent prediction.
- Integration of learned priors from foundation models for enhanced panoptic and open-vocabulary semantic occupancy, as seen in emerging approaches [vobecky2023pop, boeder2024langocc].
- Investigation of semi-supervised and few-shot transfer learning using MobileOcc as a pretraining resource for mobile robot perception stacks.
Conclusion
MobileOcc establishes a new standard for human-aware, high-fidelity semantic occupancy datasets and benchmarking in mobile robotics. The combined advances in non-rigid mesh annotation, robust multi-modal fusion, and comprehensive baselines enable rigorous evaluation and continued progress toward trustworthy human-centered navigation in robotics (2511.16949).