- The paper introduces a VAE model that explicitly integrates censoring and mixed-type covariates to generate synthetic clinical trial data with survival endpoints.
- The methodology improves data fidelity and utility by matching survival curves and mitigating inflated type I error through a post-generation selection procedure.
- Experimental results demonstrate enhanced inferential calibration and privacy preservation, although challenges remain for achieving regulatory-grade synthetic control arms.
Variational Autoencoder-Based Generation of Synthetic Clinical Trial Data with Survival Endpoints
Introduction and Motivation
Traditional late-phase clinical trials face increasing obstacles, including slow enrollment and unsustainable costs, especially in domains like oncology and rare diseases where population sizes are small and endpoints are often time-to-event (survival) outcomes. The use of synthetic data is emerging both as a solution for privacy-preserving data sharing and as a mechanism to augment or replace control arms in trials with insufficient accrual. However, generating valid synthetic datasets for survival analysis is significantly more challenging than for standard tabular data due to censoring and small sample sizes, as well as the need for accurate reproduction of treatment effect estimands like type I error and statistical power.
While GAN-based approaches have proliferated in the literature, they have substantial limitations in the survival context, most notably instability, sensitivity to training set size, and the strong assumption of independent censoring. The paper "Toward Valid Generative Clinical Trial Data with Survival Endpoints" (2511.16551) introduces a variational autoencoder (VAE) based approach, tailored for the unique demands of generating patient-level clinical trial data with survival endpoints, with explicit modeling of censoring and mixed-type covariates in a unified latent framework.
Model Architecture and Methodological Innovations
The authors expand the Heterogeneous and Incomplete VAE (HI-VAE) architecture by explicitly incorporating time-to-event outcomes and censoring within the latent structure. The generative process embeds categorical, positive, and continuous covariates, as well as survival outcomes, with a hierarchical latent Gaussian mixture (continuous zi, discrete si). Rather than assuming independent censoring—a strong and oft-violated assumption—this model enforces no such constraint, which enhances applicability for realistic clinical scenarios.
For survival outcomes, the joint likelihood models event and censoring times via neural parameterizations, supporting both continuous (Weibull) and piecewise-constant (discretized) distributions. The encoder uses the Gumbel-Softmax and Gaussian reparameterization tricks for differentiable sampling, ensuring tractable optimization of the ELBO. This architecture enables the simultaneous capture of covariate, event time, and censoring dependencies within a single model, which contrasts sharply with prior two-stage approaches (e.g., SurvivalGAN).
Experimental Protocol and Evaluation Metrics
Experiments are conducted on both simulated datasets (allowing ground-truth assessment of type I error and statistical power) and real phase III trials from oncology and HIV (ACTG320, NCT00119613, NCT00113763, NCT00339183). The authors consider two major generative scenarios:
- Privacy-preserving data sharing: The entire control arm is synthetically regenerated for downstream sharing or meta-analysis, adhering to privacy constraints.
- Control-arm augmentation: Synthetic patients are generated to augment small control arms, thereby correcting imbalances and improving inferential robustness.
Competing models include SurvivalGAN and SurvivalVAE, both implemented as modular architectures within the synthcity framework, and employing independent two-stage modeling of covariates and survival outcomes.
Evaluation goes beyond standard ML metrics and includes:
- Fidelity: Jensen-Shannon (J-S) distance
- Utility: Survival curve (Kaplan-Meier) distance
- Privacy: K-map score and NNDR
- Downstream inference: Calibration of type I error and statistical power via log-rank testing, with empirical and theoretical benchmarks rooted in classical survival analysis.
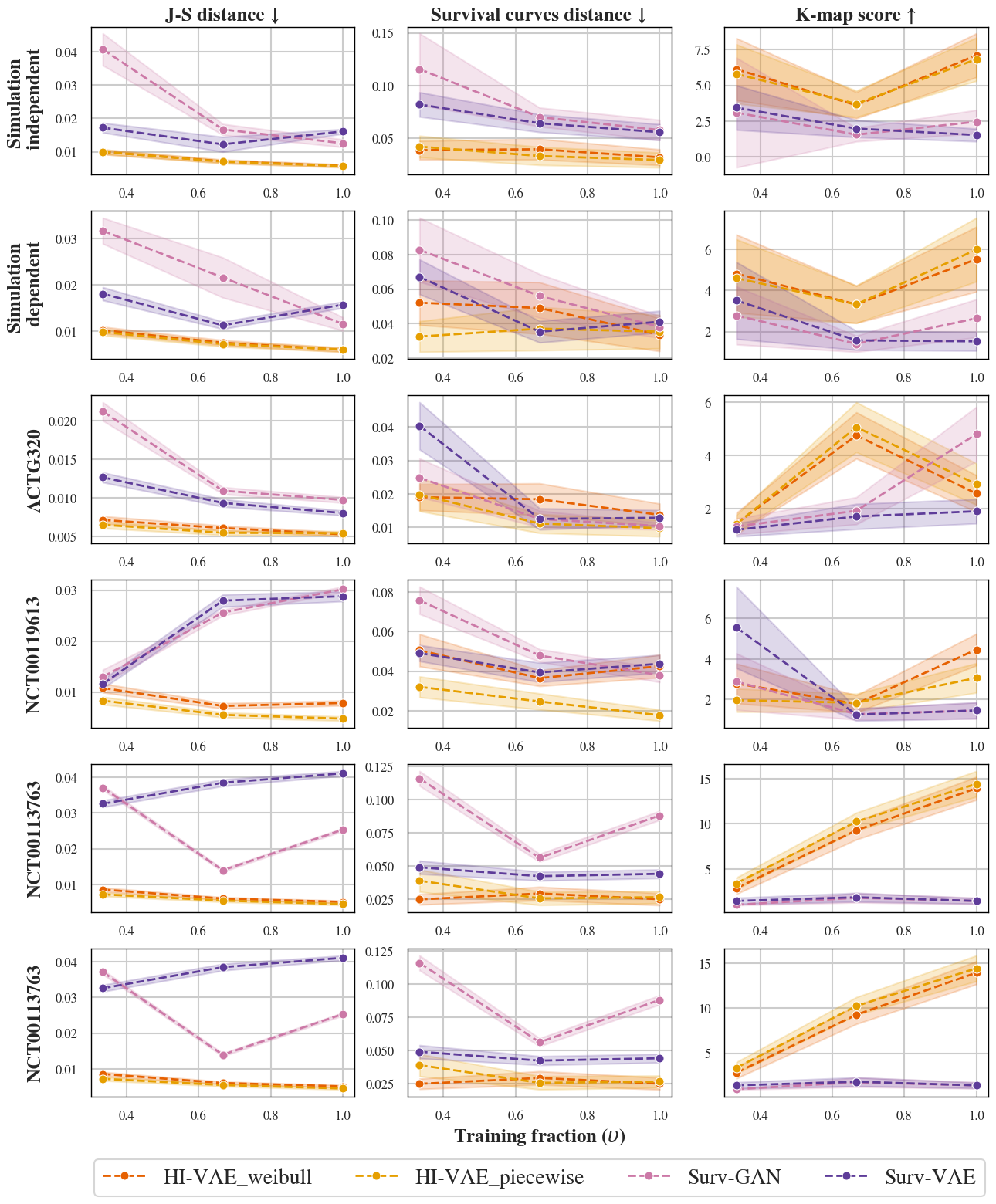
Figure 1: Performance comparison on simulated and real datasets, using J-S distance, survival curve distance, and K-map score. Arrows indicate directions of better performance.
Key Results
Fidelity, Utility, and Privacy
The HI-VAE approach yields L1 minimal J-S distance and survival curve distance on both synthetic and real clinical datasets, outperforming both SurvivalGAN and SurvivalVAE on measures of resemblance and utility (Figure 1). Privacy analysis reveals that while improvements are made, K-map values from posterior sampling remain below regulatory thresholds for public release (EMA Policy 0070 recommends K-map ≥ 11). NNDR values indicate a partial, not total, protection against re-identification.
Type I Error and Power Calibration
A critical highlight is the systematic inflation of type I error and miscalibrated empirical power across all generative models, even those achieving maximal fidelity on classical metrics (Figure 2). This observation contradicts assumptions common in the literature, underscoring the disparity between distributional resemblance and inferential validity in survival endpoints.
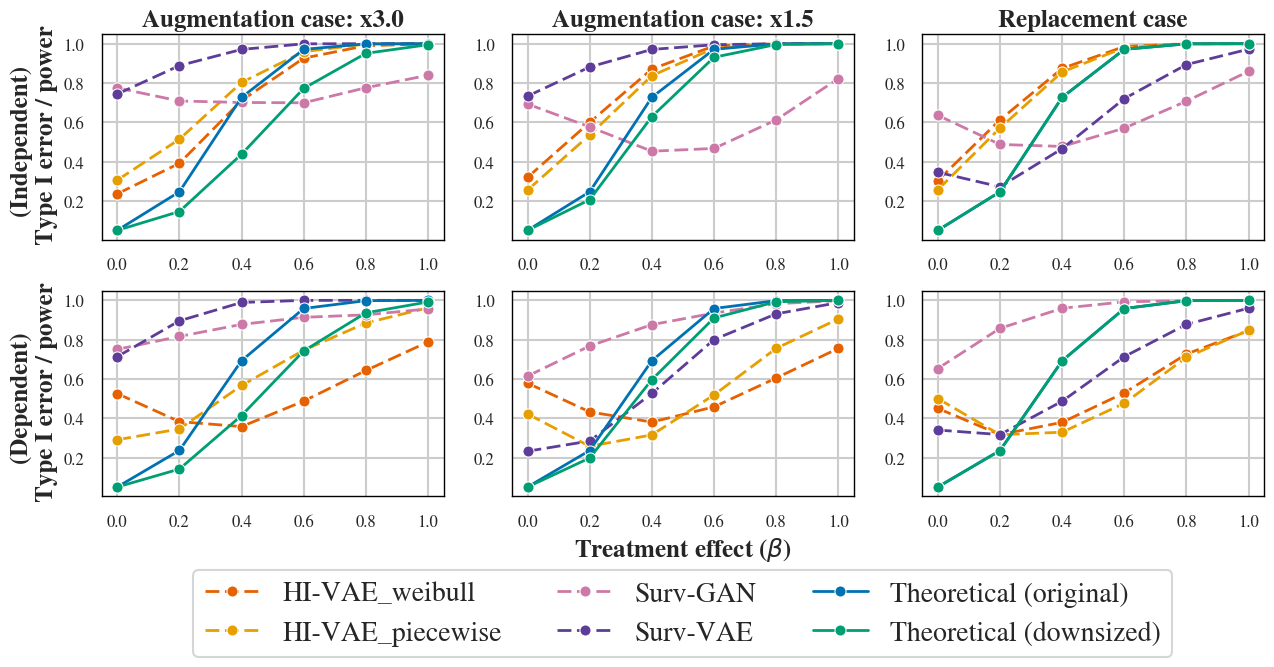
Figure 2: Type I error and power estimation for independent case (top) and dependent case (bottom). Dashed lines: empirical power. Green: theoretical power with reduced control size. Blue: theoretical power with generated control size.
Despite accurate reproduction of summary statistics, generated datasets can undermine the validity of downstream hypothesis testing, posing direct regulatory and scientific risks in clinical research applications.
Post-Generation Selection Procedure
To address inferential miscalibration, the authors introduce a post-generation selection procedure. Out of hundreds of generated replicates, the dataset most closely matching the observed control in survival distribution (as measured by highest log-rank p-value) is retained.
This method substantially improves empirical power and brings the observed type I error closer to nominal values, particularly in independent simulation settings. The procedure achieves a greater than 80% chance, across Monte Carlo replications, of generating at least one synthetic control arm not rejected by multiple-testing-adjusted log-rank analysis (Figure 3).
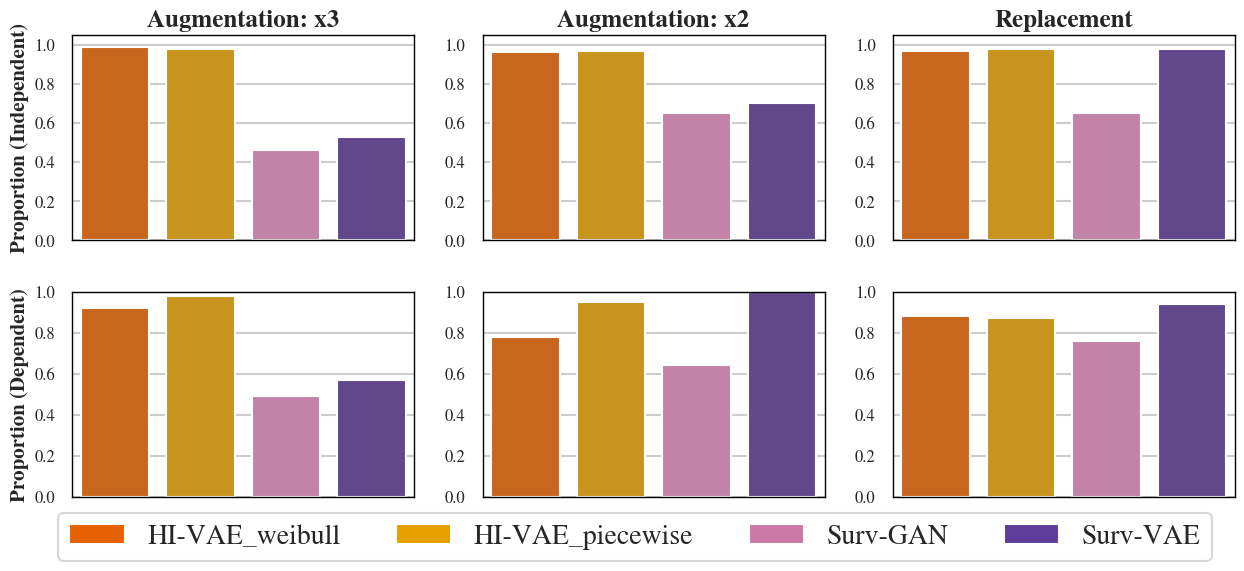
Figure 3: Proportion of Monte Carlo replications with at least one generated dataset not rejected by the adjusted log-rank test (at the 5% level) against the original controls.
Still, some inflation of type I error persists, especially when the generative augmentation factor is large or in datasets with dependent censoring. Power approximates theoretical values when training is restricted to the control arm, but is degraded when model selection is performed on top percentiles rather than on the single best generator (Figures 4, 14, 15).
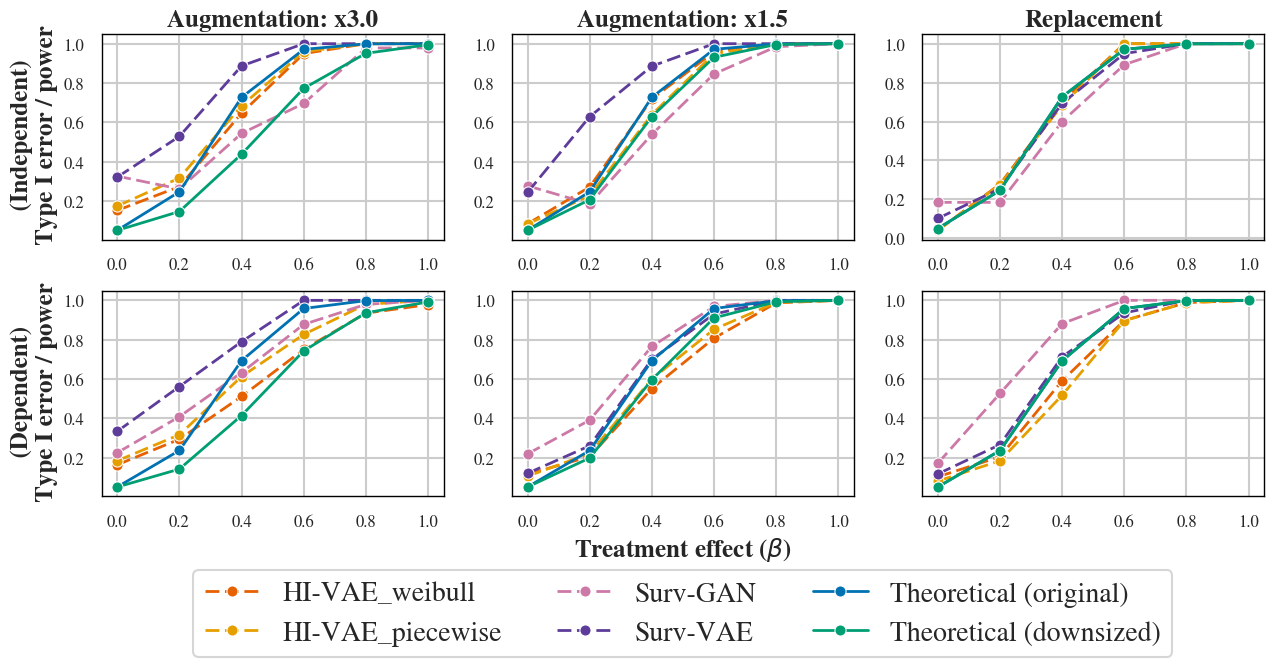
Figure 4: Type I error and power estimation after post-generation selection for independent case (top) and dependent case (bottom). Dashed lines: empirical power. Green: theoretical power with reduced control size. Blue: theoretical power with generated control size.
Alternative Training and Privacy Strategies
Contrary to expectation, training on both treated and control arms offers no consistent benefit over control-only training for data resemblance, and only marginal gains in privacy, confirming the trade-off specificity of small sample generative inference (Figure 5).
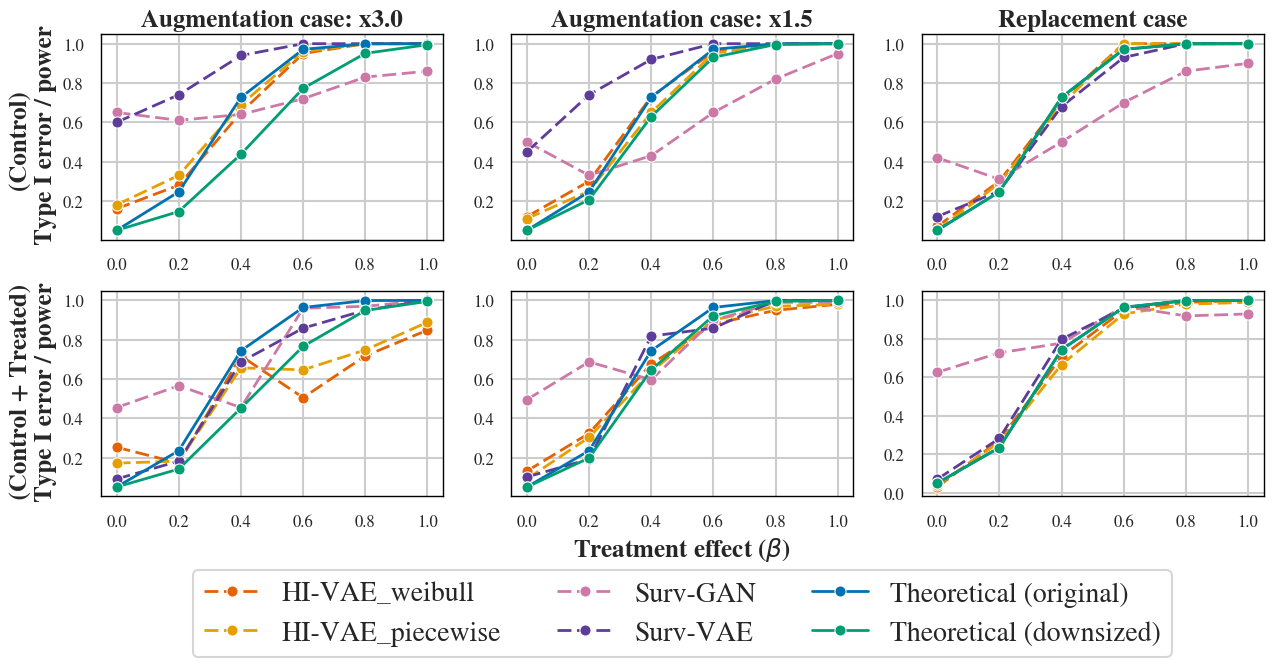
Figure 5: Type I error and power estimation after post-generation selection for independent case under two training strategies: using only available control samples (top) and using both control and treated arms (bottom).
Furthermore, switching from posterior to prior-based sampling yields negligible privacy gains and in some cases degrades utility. Preliminary differential privacy injections, using the Opacus PyTorch framework, fail to increase privacy metrics without pronounced loss in fidelity, emphasizing the challenge of operationalizing formally private generative modeling in sparse, high-stakes settings.
Discrimination and Calibration in Downstream Models
The HI-VAE-generated data enables Cox models with discrimination (C-index) and calibration (integrated Brier score) comparable to those trained on real controls, while competing methods tend to exhibit inferior calibration despite adequate discrimination (Figures 16, 17).
Implications and Future Directions
This systematic analysis demonstrates that standard ML generative performance metrics are not sufficient in the context of clinical survival data. Downstream inferential calibration—particularly type I error and power—must be evaluated directly to prevent misleading conclusions. The evidence illustrates that joint VAE-based modeling provides improvements in data utility and privacy but is still not fully adequate for regulatory-grade synthetic control arm data without explicit post-generation calibration steps.
Moving forward, principled, calibration-oriented generative training, and enforcement of privacy constraints compatible with utility (such as differentially private diffusion models [li2025diffusion]), represent key targets. Bridging deep generative models with survival-specific inferential properties will require further methodological progress, potentially leveraging domain knowledge, robust calibration objectives, and advanced privacy frameworks.
Regulatory frameworks in both the EU (AI Act, EMA Policy 0070) and US (21st Century Cures Act, FDA AI guidance) will increasingly require such rigorous, use-case-driven validation for acceptance of synthetic, AI-generated control arms in clinical trials.
Conclusion
The presented VAE-based approach marks significant methodological progress in the generation of synthetic clinical trial data with survival endpoints. While advancing state-of-the-art performance on standard fidelity, utility, and privacy metrics, the analysis exposes critical limitations in inferential validity. Post-generation selection partially restores statistical calibration, but persistent challenges remain, especially in balancing utility and privacy. Real-world deployment in regulated clinical research will depend on the development of generative models that explicitly target downstream inferential properties and robust privacy guarantees, coupled with careful evaluation frameworks that extend beyond conventional ML benchmarks.