Upsample Anything: A Simple and Hard to Beat Baseline for Feature Upsampling
Abstract: We present \textbf{Upsample Anything}, a lightweight test-time optimization (TTO) framework that restores low-resolution features to high-resolution, pixel-wise outputs without any training. Although Vision Foundation Models demonstrate strong generalization across diverse downstream tasks, their representations are typically downsampled by 14x/16x (e.g., ViT), which limits their direct use in pixel-level applications. Existing feature upsampling approaches depend on dataset-specific retraining or heavy implicit optimization, restricting scalability and generalization. Upsample Anything addresses these issues through a simple per-image optimization that learns an anisotropic Gaussian kernel combining spatial and range cues, effectively bridging Gaussian Splatting and Joint Bilateral Upsampling. The learned kernel acts as a universal, edge-aware operator that transfers seamlessly across architectures and modalities, enabling precise high-resolution reconstruction of features, depth, or probability maps. It runs in only $\approx0.419 \text{s}$ per 224x224 image and achieves state-of-the-art performance on semantic segmentation, depth estimation, and both depth and probability map upsampling.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Upsample Anything — Explained Simply
What this paper is about
This paper shows a simple way to turn blurry, low‑detail information from a computer vision model into sharp, high‑detail results — without doing any training beforehand. The method is called “Upsample Anything,” and it works fast (about 0.42 seconds per 224×224 image), works on many kinds of data (like features, depth maps, and even class probabilities), and works with many different models.
Why is this needed? Modern vision models (like big “foundation” models) understand images well, but they shrink images by about 14–16× inside the model. That makes their internal maps low‑resolution. When you need detailed, pixel‑perfect outputs (like a depth map or a segmentation mask), you usually add a big, heavy “decoder” network — which is slow, hard to train, and may not work well on new tasks. This paper’s method gives you the detail back without retraining and without heavy decoders.
The main questions the paper asks
- Can we restore fine details (sharp edges, small objects, precise boundaries) from low‑resolution features quickly and without training on a dataset?
- Can one simple method work across many tasks (segmentation, depth, probability maps) and many models (different backbones), and still give high‑quality results?
- Can we design an upsampling method that is both edge‑aware (respects boundaries) and flexible enough to adapt to each image on the fly?
How the method works (in everyday language)
Think of an image as a grid of tiny squares (pixels). Inside a vision model, that grid gets shrunk a lot, so you lose detail. The trick is to “color in” the missing details in a smart way. Upsample Anything does that using two classic ideas combined — but with a fresh twist.
- Joint Bilateral Upsampling (JBU): Imagine you’re smoothing or blending colors, but you don’t blur across edges. You use the original high‑res photo as a guide to avoid mixing across sharp boundaries. This keeps edges crisp.
- Gaussian Splatting: Picture placing many soft, oval‑shaped stamps (Gaussians) on the image that spread color or features smoothly, more in some directions than others (like brush strokes).
This paper blends these ideas: for every low‑res point, it learns a special “brush” (a Gaussian) that says how to mix nearby information. Each brush has:
- size in x and y (how wide/tall it spreads),
- direction (the angle it prefers to spread along),
- color sensitivity (how much it avoids mixing across different colors).
In symbols, these are the four learned values per pixel: σx, σy, θ, σr — but you can think of them as the brush’s width, height, tilt, and edge‑sensitivity.
Key steps, in simple terms:
- Take the high‑res image and make a small, low‑res version of it.
- Teach the brushes (one per pixel) to “paint back” the high‑res image from the low‑res one by mixing neighbors carefully, especially respecting edges (this is called test‑time optimization, and it takes about 0.42 s for a 224×224 image).
- Reuse those same learned brushes to upsample the model’s low‑res feature maps (or depth maps, or probability maps) to high‑res. Because the brushes learned where edges are and how to mix, they restore detail well.
Two important details:
- It doesn’t “invent” new values. It mixes what’s already there, just more cleverly and edge‑aware.
- It learns per image, so it adapts to each photo’s edges and textures without any dataset training.
Analogy: It’s like learning the perfect set of local, edge‑aware blending rules from the photo itself, then applying those rules to upsample anything tied to that photo (features, depth, or class probabilities).
What they found and why it matters
In their tests, Upsample Anything:
- Was fast: about 0.419 seconds per 224×224 image to learn the brushes (not counting the time to extract features from the backbone).
- Needed no dataset‑level training: it adapts on the fly to each image.
- Worked across many tasks and models:
- Semantic segmentation (COCO, PASCAL‑VOC, ADE20K): it achieved the best or near‑best accuracy among compared methods, with modest but consistent gains over simple bilinear resizing (especially when the backbone is strong).
- Depth estimation and surface normals (NYUv2): it showed larger improvements than other methods, suggesting geometry tasks benefit more from smart upsampling.
- Depth map upsampling and probability map upsampling: it produced sharper edges and strong performance; upsampling probabilities (instead of features) was both fast and surprisingly accurate.
- Scaled better to large images than attention‑based upsamplers: it avoided running out of memory at high resolutions and showed stable, predictable memory use.
Why this matters:
- You can get high‑resolution, edge‑sharp outputs without training an extra big decoder or retraining for every new dataset or model.
- It’s “plug‑and‑play” and model‑agnostic, making it easy to drop into different pipelines.
- For many tasks, especially depth and geometry, it brings meaningful accuracy gains with low overhead.
What this means for the future
- Simpler vision systems: With reliable upsampling, you might use a very small decoder (or even none), which saves compute and memory.
- Works across domains: Since it adapts per image and doesn’t depend on a specific dataset, it can generalize better to new scenes, cameras, or tasks.
- New pipelines: Upsampling final probability maps (instead of intermediate features) can be both cheaper and more accurate in some cases.
- 3D possibilities: The same idea can extend to 3D feature volumes guided by depth, hinting at future 3D reconstruction or understanding tools.
Limitations to keep in mind:
- If the guidance image is very noisy or has confusing occlusions, learning the brushes can be harder and less stable.
- While it’s fast, it still adds a short per‑image optimization step.
Overall, Upsample Anything shows that a carefully designed, edge‑aware mixing strategy — learned per image and inspired by classic filters plus “smart brushes” — can restore detail well across many tasks without heavy training or complex decoders.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, aimed at guiding future research.
- Reliance on high-resolution RGB guidance: performance and stability when HR guidance is noisy, low-light, low-SNR, motion-blurred, or absent is not quantified; methods for robust optimization under impaired guidance are needed.
- Guidance–signal misalignment: the impact of spatial/temporal misalignment between the guidance image and the LR signal (e.g., rolling shutter, handheld motion, multi-sensor setups) is not analyzed; alignment strategies or optimization that tolerates misalignment remain open.
- Bilinear downsampling vs. true encoder patchification: TTO uses bilinear downsampling to emulate VFM stride, but VFMs perform patch embedding with learnable projections; the mismatch and its effect on learned kernels and downstream performance is not studied.
- Kernel regularization and identifiability: per-pixel optimization of risks degenerate or overly anisotropic kernels; principled regularizers, constraints, or priors and their effect on robustness/generalization are unexplored.
- Neighborhood/support selection: the choice of spatial neighborhood , kernel support size, and their trade-offs in accuracy, runtime, and memory are not specified or ablated.
- High-resolution scalability and memory: reported peak memory at 1024×1024 (~82 GB) suggests practical constraints; tiling, streaming, or sparse approximations to attain 4K/8K scalability without OOM are open engineering questions.
- End-to-end latency: speed claims exclude VFM feature extraction; full pipeline latency (encoder + TTO + rendering + head) for realistic image sizes and batches is not reported.
- Quantitative cross-backbone generalization: while qualitative results span CLIP/DINO/ConvNeXt, rigorous quantitative comparisons across backbones, strides (14× vs 16×), and feature channel counts are missing.
- Dataset variation and fairness: segmentation experiments use extended training (100 epochs) that deviates from common linear-probe schedules; how different training schedules affect the relative gains of upsampling baselines remains unclear.
- Small gains on strong backbones: when backbones are high-capacity, segmentation improvements over bilinear are modest or vanish (e.g., Cityscapes); identifying regimes/tasks/metrics (e.g., boundary F-score, small-object metrics) where upsampling yields consistent gains is needed.
- Depth map upsampling underperformance on NYUv2: bilinear achieves lower RMSE than the proposed method; understanding when edge-aware upsampling harms smooth-depth datasets and designing adaptive/regularized variants is open.
- Probabilistic upsampling effects on uncertainty: the “segment-then-upsample (prob.)” pipeline improves mIoU, but its impact on probability calibration (ECE, Brier score), uncertainty propagation, and error modes is not evaluated.
- Robustness to domain shifts and non-RGB modalities: claims of universality lack tests on thermal/NIR, multispectral/SAR, medical imagery, or synthetic domains; extending guidance beyond RGB and quantifying cross-domain robustness is open.
- Temporal/video consistency: per-image TTO may produce flicker; methods to enforce temporal coherence, reuse kernels across frames, or incremental TTO for streaming scenarios are unexplored.
- 3D extension evaluation: the 3D upsampling variant is demonstrated qualitatively (PCA slices) without quantitative benchmarks on 3D tasks (e.g., semantic scene completion, 3D segmentation); memory/runtime scaling for 3D is not reported.
- Theoretical analysis: the formal link between JBU and 2D Gaussian Splatting is sketched but lacks rigorous conditions, guarantees, and convergence analysis for the TTO objective; understanding when kernels transfer across modalities/backbones is an open theory question.
- Sensitivity to optimization hyperparameters: beyond iteration count, sensitivity to learning rate, initialization, optimizer choice, and stopping criteria is not ablated; guidelines for stable TTO across diverse images are needed.
- Failure modes and diagnostics: beyond occlusions/low-SNR, systematic characterization of artifacts (oversharpening, haloing, color bleeding) and diagnostic tools to detect/mitigate them are missing.
- Channel-agnostic weights: the method applies identical spatial–range weights across feature channels; exploring channel-specific or class-aware weighting and its trade-offs is an open design question.
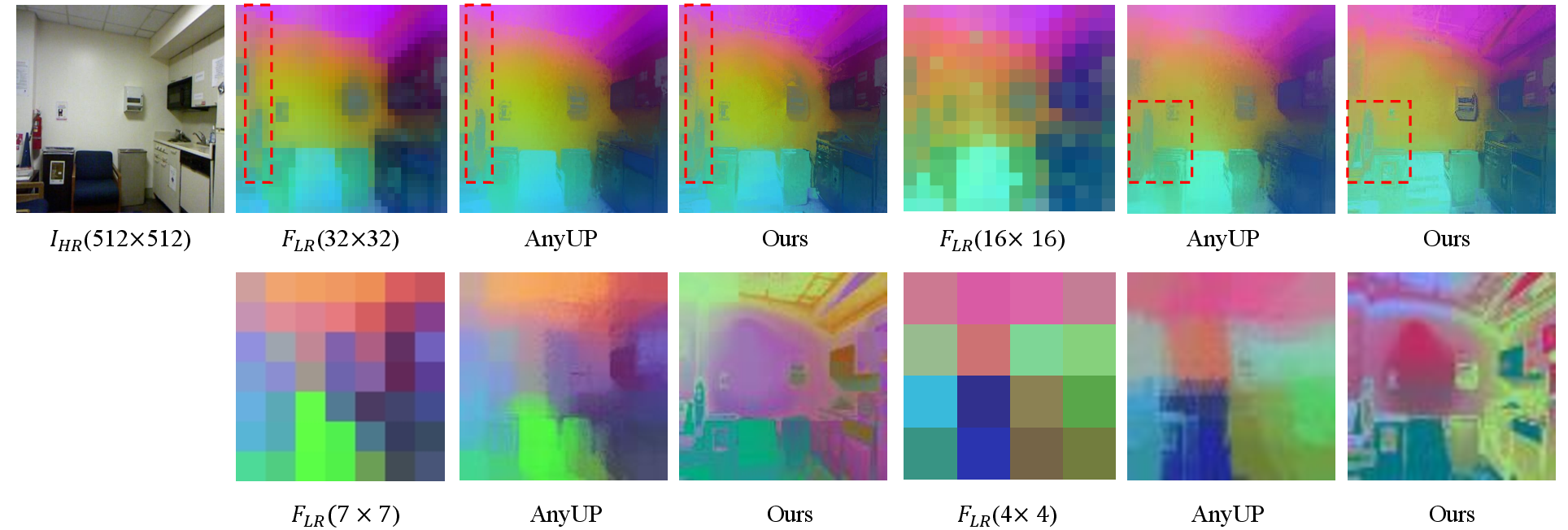
- Scale-factor generality: performance across varying downsampling factors (beyond 14–16×) and extremely low resolutions (≤4×4) is only qualitatively addressed; comprehensive quantitative stress tests are missing.
- Broader task coverage: evaluation is limited to semantic segmentation, depth, normals, and map upsampling; impacts on instance/panoptic segmentation, optical flow, edge detection, and dense correspondence are not studied.
- Kernel interpretability: preliminary blob visualizations suggest structure, but systematic analyses (e.g., orientation distributions vs. edge maps, correlations with semantic boundaries) and metrics for interpretability are absent.
- Integration with decoders: while “resolution-free” claims are made, best practices for combining GSJBU with existing decoders (UPerNet, SegFormer, Mask2Former) or lightweight heads for various tasks are not established.
- Reuse and transfer of kernels: whether per-image kernels learned from RGB can be cached/reused across tasks/backbones or adapted with minimal TTO is not evaluated.
- Misaligned supervision in TTO: optimizing solely on color reconstruction may misguide kernels when semantic boundaries do not align with color edges; multi-cue guidance (e.g., gradients, depth, self-supervised features) and their benefits are unexplored.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be integrated into existing products and workflows without additional dataset-level training.
- Lightweight, plug-and-play upsampler for existing vision pipelines
- Sectors: software, robotics, autonomous systems, mapping, manufacturing/inspection
- Potential tools/products/workflows:
- Swap heavy decoder upsampling blocks (e.g., in DPT/UPerNet/SegFormer-like stacks) for the proposed TTO upsampler to obtain high-resolution features from low-resolution backbone outputs.
- Add a reusable “Upsample Anything” operator to inference graphs (PyTorch/TensorRT/ONNX) to standardize edge-aware upsampling across tasks.
- Value: reduces model size and retraining costs; improves geometry-centric tasks (depth, normals) and boundaries with minimal latency overhead (~0.4 s per 224×224 image as reported).
- Assumptions/dependencies: availability of a high-resolution RGB guidance image aligned to the feature map; per-image TTO compute budget; modest to strong gains expected especially for tasks with fine boundaries or geometry.
- Probability-map upsampling for faster segmentation inference
- Sectors: mobile apps, AR, robotics/drones, smart cameras, embedded vision
- Potential tools/products/workflows:
- “Segment-then-upsample” pipeline: predict logits/probabilities at low resolution with a 1×1 head, then upsample probabilities to full resolution using the method.
- Mobile/edge segmentation services where latency and memory are critical.
- Value: comparable or better accuracy than feature upsampling with lower compute, enabling lighter heads and faster inference.
- Assumptions/dependencies: the segmentation head produces calibrated probabilities at LR; HR guidance must be available; final quality depends on LR head capacity and domain.
- Depth map upsampling for RGB-D cameras and low-resolution sensors
- Sectors: AR/VR, robotics/SLAM, smartphones, 3D scanning, construction/BIM
- Potential tools/products/workflows:
- Post-process ToF/LiDAR/stereo depth maps using HR RGB guidance to sharpen edges and preserve geometry.
- Smartphone portrait mode and 3D photo apps that need crisp depth boundaries for matting/bokeh.
- Value: edge-aware, guided upsampling of depth maps with improved sharpness over bilinear and guided filtering baselines in many scenarios; strong gains for high-frequency structure.
- Assumptions/dependencies: tight spatial alignment between RGB and depth; performance on heavily smoothed/low-SNR ground-truth may show smaller quantitative gains; per-image TTO time scales with resolution.
- Boundary-preserving mask refinement for labeling and post-processing
- Sectors: geospatial/GIS, medical imaging, VFX/compositing, document analysis
- Potential tools/products/workflows:
- Refine coarse masks (e.g., pseudo-labels, weak labels) to HR with sharper edges in annotation tools.
- Post-process segmentation outputs in VFX and photo editors to improve matting and cutouts.
- Value: improves boundary quality and visual fidelity without retraining; helps generate higher-quality pseudo-labels.
- Assumptions/dependencies: HR guidance fidelity; masks/logits at LR must be reasonably accurate.
- Cross-backbone, cross-resolution feature alignment for foundation model evaluation
- Sectors: academia, applied ML R&D
- Potential tools/products/workflows:
- A unified upsampling operator to compare different backbones (CLIP/DINO variants, ConvNeXt) at common HR without retraining.
- Rapid prototyping: ablate decoders while isolating effects of upsampling.
- Value: reduces confounds when benchmarking VFMs on pixel-level tasks; standardizes a strong, training-free baseline.
- Assumptions/dependencies: relies on per-image TTO; minor/variable gains on datasets with coarse labels or large, regular structures (e.g., Cityscapes).
- Remote sensing and scientific imaging: upsample coarse predictions using HR guidance
- Sectors: earth observation, agriculture, environmental monitoring
- Potential tools/products/workflows:
- Fuse coarse model outputs (e.g., land-cover probabilities) with HR optical or panchromatic imagery to produce sharper, HR maps.
- Value: improves spatial detail and edge preservation for mapping and change detection.
- Assumptions/dependencies: accurate geo-registration between modalities; HR guidance availability; domain shift may require careful QA.
- Privacy-preserving, on-device post-processing
- Sectors: public sector, healthcare, consumer devices
- Potential tools/products/workflows:
- Per-image TTO on-device to avoid dataset-level retraining or cloud uploads.
- Integrate as a privacy-friendly step in clinical or field settings where data sharing is restricted.
- Value: reduces data movement and training dependencies; enhances deployment flexibility.
- Assumptions/dependencies: compute headroom on device; robust performance requires good guidance signal.
- Document and form understanding: upsampling binarization/segmentation maps
- Sectors: finance, government, enterprise back-office, legal
- Potential tools/products/workflows:
- Upsample LR text/field probability maps to HR for OCR region segmentation and redaction tools.
- Value: better boundary fidelity for text blocks, tables, and signatures without retraining models on each layout domain.
- Assumptions/dependencies: HR scans as guidance; correct alignment; probability maps must capture coarse structure at LR.
Long-Term Applications
These use cases require additional research, engineering for scale/real-time operation, or new data/modality support before broad deployment.
- Real-time, hardware-accelerated edge-aware upsampling in camera ISPs and NPUs
- Sectors: consumer imaging, mobile SoCs, XR devices, drones
- Potential tools/products/workflows:
- Kernel fusion and CUDA/Metal/Vulkan kernels; NPU/ISP primitives implementing anisotropic Gaussian splatting with range guidance.
- System-on-chip “universal upsampler” block to replace multiple task-specific upscalers.
- Value: near–real-time edge-aware upsampling for video and interactive AR.
- Assumptions/dependencies: low-latency kernels, memory-efficient implementations; possibly approximations of TTO or amortized parameter prediction.
- Temporal/video-aware upsampling with consistency constraints
- Sectors: video analytics, autonomous driving, broadcast, telepresence
- Potential tools/products/workflows:
- Extend TTO to propagate or regularize kernels over time; streaming segmentation/depth upsampling with temporal stability.
- Value: reduces flicker; higher-quality video perception from LR predictions.
- Assumptions/dependencies: efficient temporal models; motion compensation; maintaining per-frame latency budgets.
- Multi-modal sensor fusion via guided upsampling (thermal, hyperspectral, SAR + RGB)
- Sectors: defense/security, precision agriculture, infrastructure monitoring, energy (grid/asset inspection)
- Potential tools/products/workflows:
- Use HR RGB or lidar intensity as guidance to upsample coarse thermal/hyperspectral predictions with sharp boundaries.
- Value: richer, spatially accurate maps without collecting paired HR labels across all modalities.
- Assumptions/dependencies: cross-sensor calibration and alignment; modality-specific robustness to noise and occlusions.
- 3D volumetric feature upsampling and scene representations
- Sectors: robotics/SLAM, digital twins, AR/VR, autonomous navigation
- Potential tools/products/workflows:
- From 2D LR features + RGB-D guidance, build HR 3D feature volumes for mapping, reconstruction, or downstream 3D tasks (e.g., semantic mapping).
- Coupling with Gaussian Splatting/NeRF pipelines to improve surface-aligned semantics at scale.
- Value: geometry- and semantics-aware 3D features without 3D dataset-level training.
- Assumptions/dependencies: reliable depth (or multi-view geometry) as guidance; substantial engineering to meet memory/runtime constraints for large scenes.
- Decoder-less or ultra-light decoder perception stacks
- Sectors: autonomous systems, mobile AI, IoT cameras, embedded analytics
- Potential tools/products/workflows:
- Standardize “low-res head + guided upsampling” across tasks (segmentation, depth, normals, optical flow).
- AutoML/model compression workflows that replace complex decoders with LR heads plus universal upsampler.
- Value: lowers training cost and model size; simplifies maintenance across backbones and domains.
- Assumptions/dependencies: further validation across diverse datasets; robust performance on OOD domains with weak guidance.
- Federated and privacy-first domain adaptation at test time
- Sectors: healthcare, public sector, finance
- Potential tools/products/workflows:
- Per-site/per-image TTO adapts mixing kernels to local data distributions without sharing data or models.
- Value: compliance-friendly adaptation and improved local performance.
- Assumptions/dependencies: secure on-device compute; standardization of TTO schedules and QA to avoid failure cases.
- National-scale geospatial analytics with cost-effective upsampling
- Sectors: policy, climate, disaster response, urban planning
- Potential tools/products/workflows:
- Upsample coarse probability maps (e.g., building footprints, flood risk) using HR imagery at country scale.
- Tooling for procurement: “training-free upsampler” modules to reduce compute and annotation demands.
- Value: improved spatial detail with limited labeling budgets; potentially lower energy consumption.
- Assumptions/dependencies: consistent HR imagery (cloud-free, up-to-date), large-scale orchestration, and rigorous QA.
- SDKs, standards, and ecosystem integration
- Sectors: software tooling, ML frameworks, hardware vendors
- Potential tools/products/workflows:
- “Upsample Anything SDK” with Python/C++ APIs, ONNX/TensorRT ops, and mobile bindings; reference implementations for PyTorch/JAX.
- Interoperability testing suites and metrics for edge-aware upsampling quality and energy.
- Value: accelerates adoption and reproducibility; enables vendor-neutral comparisons.
- Assumptions/dependencies: community buy-in; contributions of optimized kernels; standardized benchmarks.
- Consumer photo/video features: on-device portrait effects and background editing
- Sectors: consumer imaging, social media, creative tools
- Potential tools/products/workflows:
- High-quality, training-free refinement of depth/segmentation in camera apps and editors; real-time previews via amortized or hardware-accelerated TTO.
- Value: sharper edges, fewer artifacts on hair and fine structures; portable across camera models/backbones.
- Assumptions/dependencies: real-time constraints, energy limits, robust performance under low light and motion.
General assumptions and limitations across applications
- The method requires an HR guidance signal (typically the RGB image) accurately aligned to the LR signal/feature. Severe misalignment, occlusions, or low-SNR guidance degrade performance.
- Per-image TTO adds latency; although lightweight for 224×224 images, high-resolution or video-scale deployments need optimized kernels or amortized variants.
- Gains are task- and dataset-dependent; benefits are larger for geometry-centric tasks and fine-boundary scenes, and smaller where labels are coarse or structures are large/regular.
- Engineering is needed for real-time and large-scale scenarios (kernel fusion, memory-efficient implementations, temporal consistency).
Glossary
- 2D Gaussian Splatting (2DGS): A continuous image-plane representation that renders pixels/features by blending anisotropic Gaussian kernels without depth sorting. "Under this view, JBU corresponds to a discrete and isotropic instance of a guidance-modulated 2D Gaussian Splatting (2DGS) process, where the range term is provided by the HR guidance image."
- 3D Gaussian Splatting (3DGS): A volumetric rendering technique that represents scenes with 3D Gaussians and alpha-blends them to form radiance fields. "Recent works extend 3D Gaussian Splatting (3DGS)~\cite{kerbl20233d} from volumetric radiance fields to 2D image representations~\cite{zhang2024gaussianimage,zhang2025image,zhu2025large}."
- Adam optimizer: A stochastic gradient-based optimization algorithm that adapts learning rates using first and second moment estimates. "Gaussian parameters are initialized as , , and , and are optimized per-pixel using the Adam optimizer with a learning rate of ."
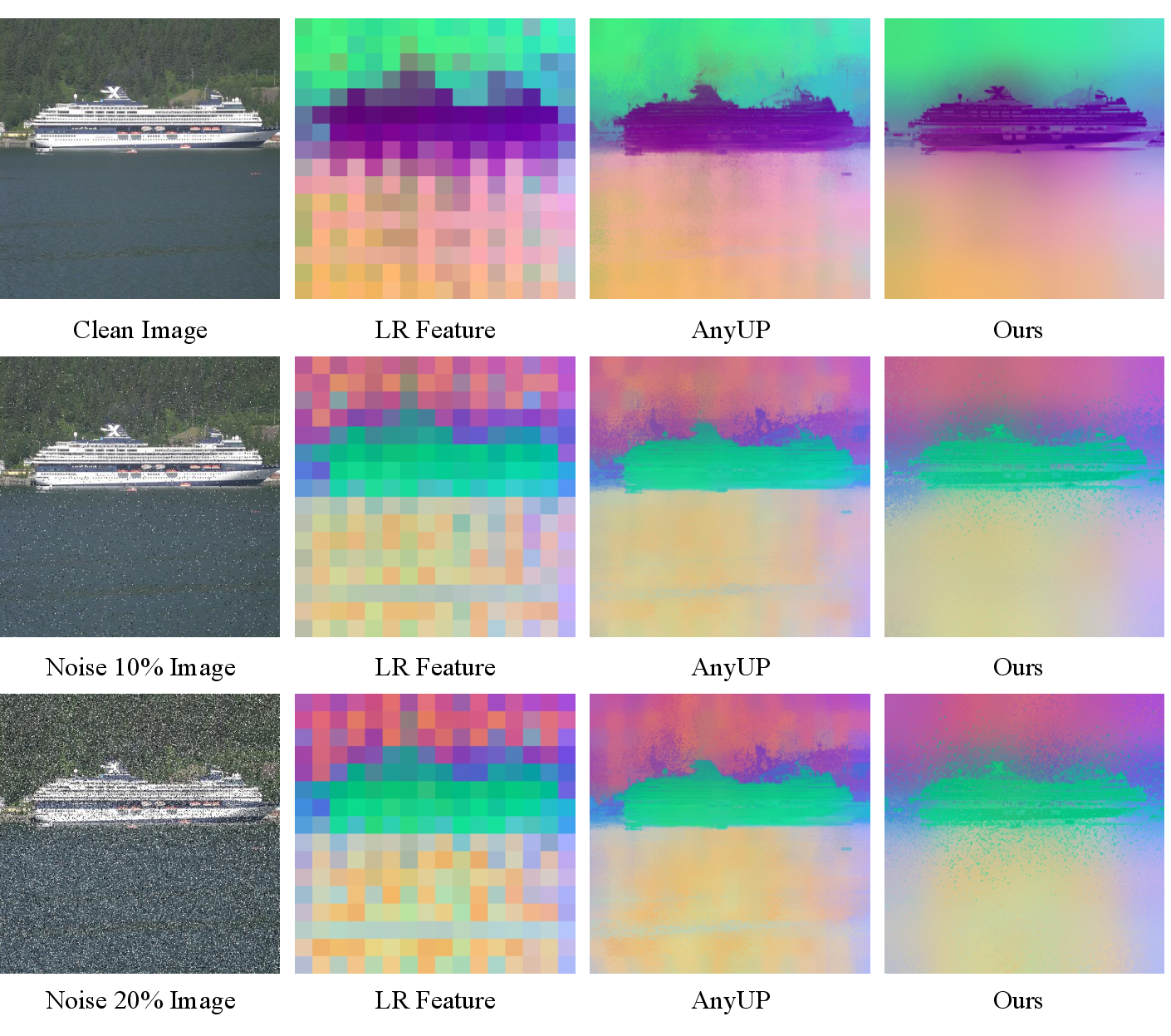
- ADE20K: A large-scale scene parsing dataset used for semantic segmentation benchmarking. "Following prior feature-upscaling works~\cite{fu2024featup,suri2024lift,huang2025loftuplearningcoordinatebasedfeature,couairon2025jafar,wimmer2025anyup}, we evaluate Upsample Anything on semantic segmentation (COCO, PASCAL-VOC, ADE20K) and depth estimation (NYUv2)."
- Alpha blending: A normalized compositing process that blends contributions of overlapping kernels by their alpha weights. "The rendered image (or feature map) is obtained by normalized alpha blending:"
- Anisotropic covariance: A covariance matrix encoding different scales and orientations along principal axes, enabling directionally sensitive kernels. "Upsample Anything assigns per-pixel anisotropic covariances and range scales through test-time optimization, enabling adaptive fusion across space and range."
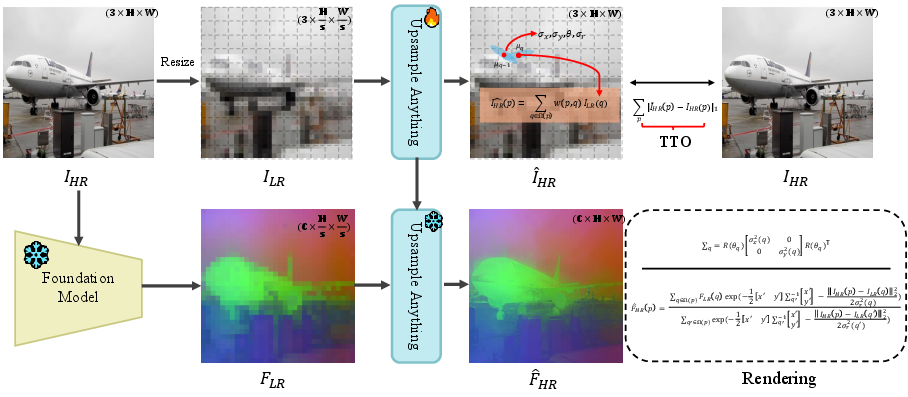
- Anisotropic Gaussian kernel: A Gaussian whose spread varies by direction, parameterized by per-pixel scales and orientation. "Given an input image, Upsample Anything resizes the RGB guidance to match the low-resolution (LR) feature-map size, reconstructs the high-resolution (HR) color image through optimization, and learns pixelwise anisotropic Gaussian parameters——that define a continuous spatial–range splatting kernel."
- Bilateral filtering: An edge-preserving filtering technique that combines spatial proximity and intensity similarity. "This formulation has inspired numerous modern variants and learnable extensions that generalize bilateral filtering~\cite{fu2024featup} to feature space and neural representations."
- Bilinear interpolation: A simple image resampling method using linear interpolation in both axes. "Specifically, the high-resolution image is downsampled to by bilinear interpolation with a stride ."
- Cityscapes: An urban scene dataset used for semantic segmentation and probability-map upsampling. "Accordingly, we further evaluate (i) depth-map upsampling on NYUv2 and Middlebury, and (ii) probability-map upsampling on Cityscapes—each guided by the corresponding high-resolution RGB image."
- Cosine learning-rate schedule: A training schedule that decays the learning rate following a cosine curve. "We therefore extend training to 100 epochs and apply a cosine learning-rate schedule to gradually decay the head’s learning rate."
- DINOv2: A self-supervised Vision Foundation Model backbone providing transferable visual features. "To compare backbones, we consider DINOv1, DINOv2, DINOv3, CLIP, and ConvNeXt, covering both transformer and convolutional families; unless otherwise specified, the default backbone is DINOv2-S."
- DPT (Dense Prediction Transformer): A transformer-based decoder architecture for dense prediction tasks like depth estimation. "However, despite these advantages, high-performing pixel-level systems still require large and complex decoders such as DPT~\cite{ranftl2021vision}, UPerNet~\cite{xiao2018unified}, or SegFormer~\cite{xie2021segformer} to recover spatial details from low-resolution features."
- Encoder–decoder paradigm: A framework where an encoder extracts features and a decoder reconstructs dense predictions at original resolution. "Modern computer vision systems for pixel-level prediction tasks such as semantic, instance, and panoptic segmentation ... often use an encoder–decoder paradigm."
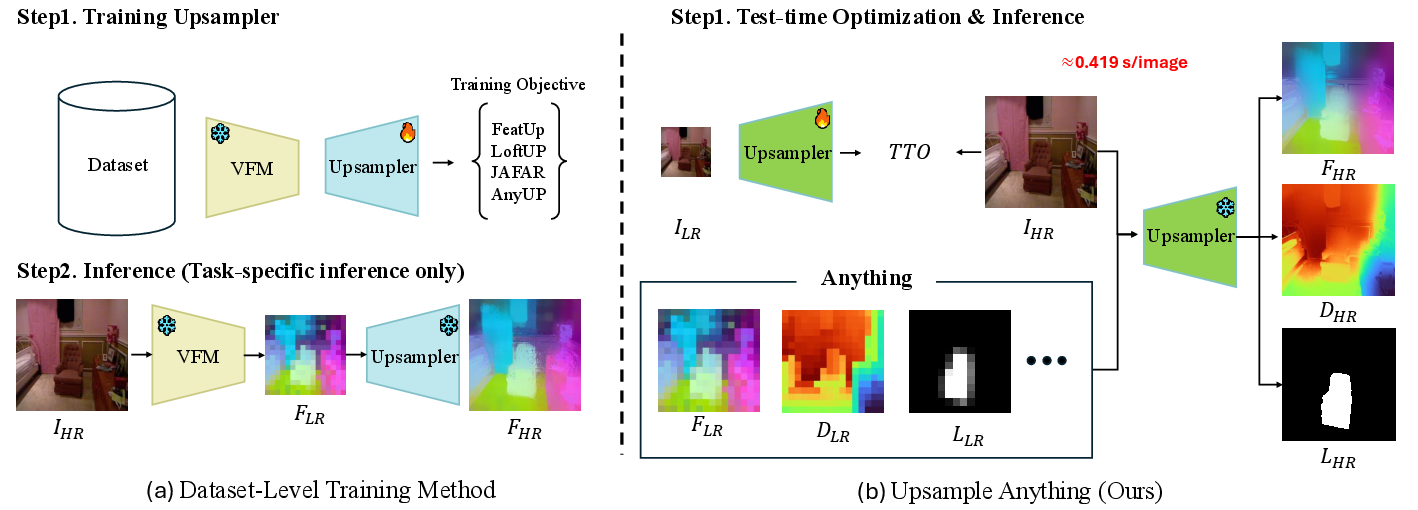
- Feature upsampling: Methods that restore spatial detail in low-resolution feature maps prior to decoding. "Feature upsampling approaches can be broadly categorized into two paradigms depending on how the upsampler is optimized: (a) dataset-level training ... and (b) test-time optimization (TTO)."
- Gaussian Splatting: Rendering by placing Gaussian kernels and blending them to reconstruct signals or features. "Upsample Anything addresses these issues through a simple per-image optimization that learns an anisotropic Gaussian kernel combining spatial and range cues, effectively bridging Gaussian Splatting and Joint Bilateral Upsampling."
- Guided Linear Upsample (GLU): A guided interpolation baseline that uses RGB guidance to upsample depth/maps. "GLU (Guided Linear Upsample)"
- Guidance image: A high-resolution image used to steer edge-aware upsampling of a low-resolution signal. "where denotes the high-resolution guidance image, and , control the spatial and range sensitivity, respectively."
- Implicit function: A continuous function (often MLP-based) that maps coordinates and guidance to high-resolution features. "the latter parameterizes high-resolution features as an implicit function optimized per image."
- Joint Bilateral Upsampling (JBU): An edge-preserving upsampling method coupling spatial and range weights to transfer HR structure. "Joint Bilateral Upsampling (JBU), first introduced by~\cite{kopf2007joint}, is a classic non-learning, edge-preserving upsampling technique designed to transfer structural details from a high-resolution guidance image to a low-resolution signal."
- Linear probe: A protocol that trains only a shallow linear head on frozen features to evaluate representation quality. "For a fair comparison, we adopt the conventional linear-probe protocol in which prior work fine-tunes only a convolutional head for 10 epochs."
- Logits: Pre-softmax scores representing class evidence used for probabilistic segmentation maps. "The segmentation logits are first generated at low resolution and then upsampled by using our method."
- mIoU (mean Intersection over Union): A segmentation metric averaging IoU across classes to assess accuracy. "Under this configuration, all methods, including LoftUp and ours, produced almost the same mIoU as bilinear interpolation, which differs from the improvements reported in the LoftUp paper."
- Multi-view training objectives: Training losses that leverage multiple views of data to learn robust upsamplers. "or by adopting multi-view training objectives~\cite{fu2024featup, suri2024lift, couairon2025jafar, wimmer2025anyup}."
- Normalized weighted summation: A blending formulation where weights are normalized to sum to one, yielding stable rendering. "Because all kernels lie on a single 2D plane, rendering reduces to a normalized weighted summation without depth sorting."
- Out-of-distribution (OOD) data: Data that differs significantly from the training distribution, challenging generalization. "They often generalize reasonably well but still exhibit suboptimal performance when facing novel architectures, resolutions, or out-of-distribution data."
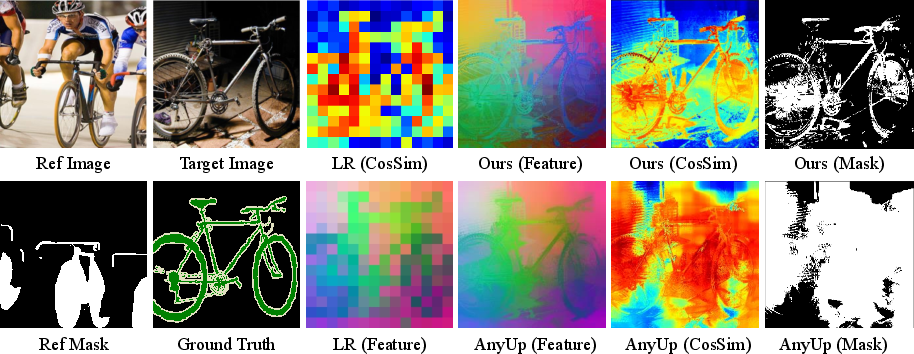
- Out-of-memory (OOM): A failure mode where GPU memory is exceeded during computation. "Consequently, AnyUp suffers from significant GPU memory overhead and fails with out-of-memory (OOM) errors beyond "
- Panoptic segmentation: A task unifying instance and semantic segmentation by assigning each pixel a class and instance ID. "Modern computer vision systems for pixel-level prediction tasks such as semantic, instance, and panoptic segmentation~\cite{everingham2010pascal,lin2014microsoft,cordts2016cityscapes,zhou2019semantic}"
- Patch-wise downsampled: A downsampling process mimicking patch extraction in transformers to create LR guidance/features. "by reconstructing the high-resolution image from its patch-wise downsampled version ."
- PCA projection: A dimensionality reduction technique used to visualize high-dimensional features as RGB images. "We visualize these 3D feature maps using PCA on each depth slice, revealing how distinct depth layers retain meaningful semantic separation while smoothly transitioning across depth."
- PSNR (Peak Signal-to-Noise Ratio): A signal reconstruction metric measuring fidelity between original and reconstructed images. "We measured PSNR between and , along with downstream segmentation performance on PASCAL-VOC."
- Resolution-conditioned kernels: Upsampling kernels that adapt to target resolution for scalable performance. "AnyUp~\cite{wimmer2025anyup} proposed resolution-conditioned kernels for scalable upsampling."
- Test-time optimization (TTO): Per-image optimization performed at inference to adapt parameters without dataset-level training. "We present Upsample Anything, a lightweight test-time optimization (TTO) framework that restores low-resolution features to high-resolution, pixel-wise outputs without any training."
- UPerNet: A hierarchical decoder architecture for segmentation that fuses multi-scale features. "large and complex decoders such as DPT~\cite{ranftl2021vision}, UPerNet~\cite{xiao2018unified}, or SegFormer~\cite{xie2021segformer}"
- Vision Foundation Models (VFMs): Large, general-purpose encoders trained with self-supervision, transferable across tasks. "This paradigm shift has led to the emergence of Vision Foundation Models (VFMs) such as DINO~\cite{oquab2023dinov2}, CLIP~\cite{radford2021learning}, SigLIP~\cite{zhai2023sigmoid}, and MAE~\cite{he2022masked}, which provide transferable and semantically rich features with minimal task-specific fine-tuning."
- Voxel-level signals: 3D grid-aligned data units used in volumetric representations and processing. "Upsample Anything not only enhances 2D feature resolution but also generalizes to other pixel- or voxel-level signals (e.g., depth, segmentation, or even 3D representations) without retraining."
- Window-based attention: Local attention mechanism operating within fixed windows, impacting memory/time complexity. "the window-based attention and dense similarity computation introduce quadratic growth in both memory and time complexity as the spatial size increases."
Collections
Sign up for free to add this paper to one or more collections.