Bi-AQUA: Bilateral Control-Based Imitation Learning for Underwater Robot Arms via Lighting-Aware Action Chunking with Transformers
Abstract: Underwater robotic manipulation is fundamentally challenged by extreme lighting variations, color distortion, and reduced visibility. We introduce Bi-AQUA, the first underwater bilateral control-based imitation learning framework that integrates lighting-aware visual processing for underwater robot arms. Bi-AQUA employs a hierarchical three-level lighting adaptation mechanism: a Lighting Encoder that extracts lighting representations from RGB images without manual annotation and is implicitly supervised by the imitation objective, FiLM modulation of visual backbone features for adaptive, lighting-aware feature extraction, and an explicit lighting token added to the transformer encoder input for task-aware conditioning. Experiments on a real-world underwater pick-and-place task under diverse static and dynamic lighting conditions show that Bi-AQUA achieves robust performance and substantially outperforms a bilateral baseline without lighting modeling. Ablation studies further confirm that all three lighting-aware components are critical. This work bridges terrestrial bilateral control-based imitation learning and underwater manipulation, enabling force-sensitive autonomous operation in challenging marine environments. For additional material, please check: https://mertcookimg.github.io/bi-aqua


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Bi-AQUA, a new way to teach underwater robot arms to do tasks (like picking up a block and placing it in a basket) even when the lighting underwater keeps changing. Think of how a swimming pool looks different when the sun moves or when colored lights shine—things can quickly look red, blue, or dim. That makes it hard for a robot that relies on cameras. Bi-AQUA helps the robot handle these lighting changes while also using a sense of touch (force) to be gentle and precise.
What questions are the researchers trying to answer?
- How can an underwater robot arm learn from human demonstrations in a way that uses both vision (cameras) and touch (forces), instead of vision alone?
- Can the robot stay reliable when the colors and brightness underwater change a lot—even mid-task?
- Do we need to change only the robot’s “eyes” (its image features), or also the way it decides actions, to cope with changing lights?
- Which parts of the solution matter most for success?
How did they do it? (Explained simply)
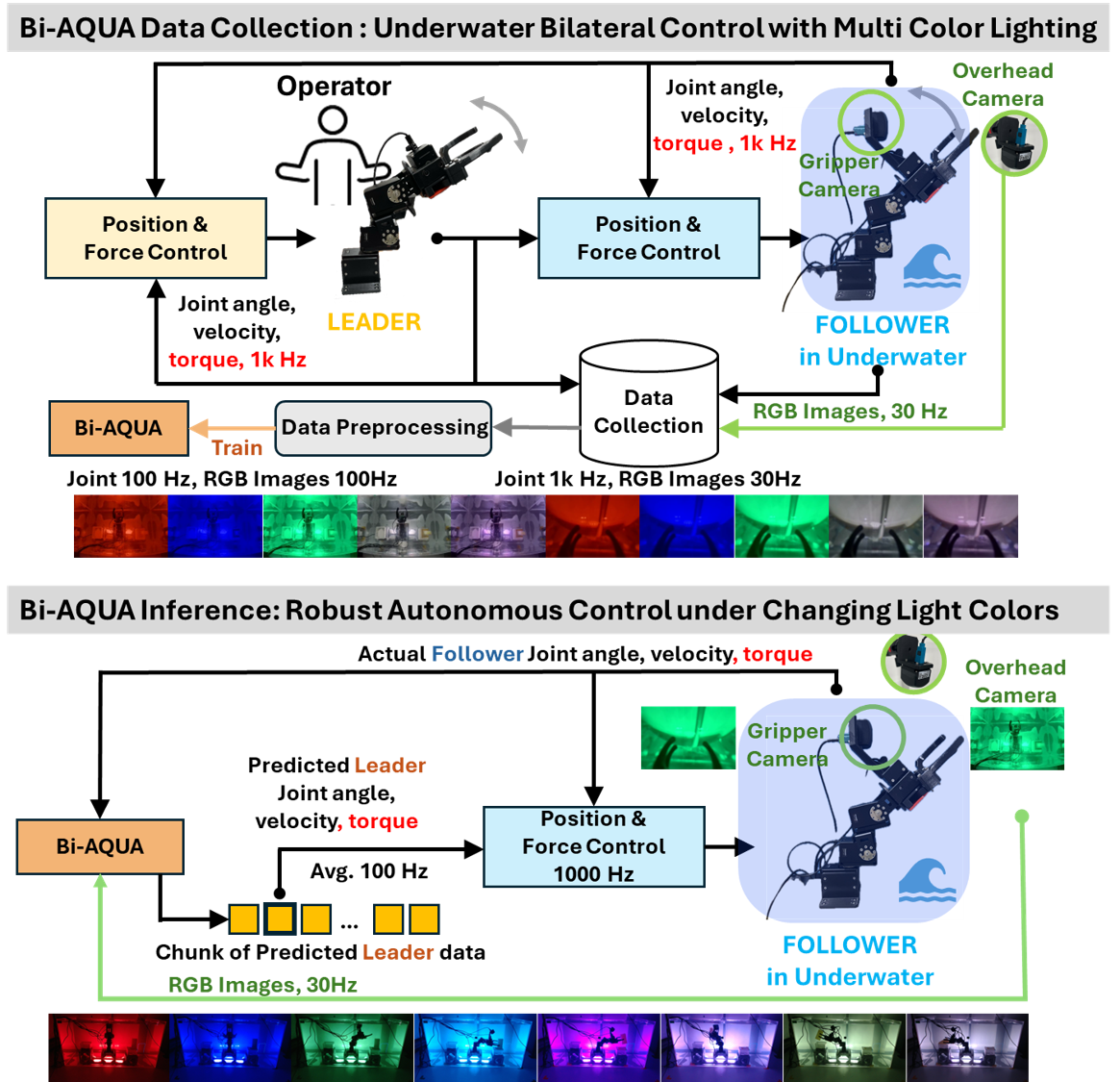
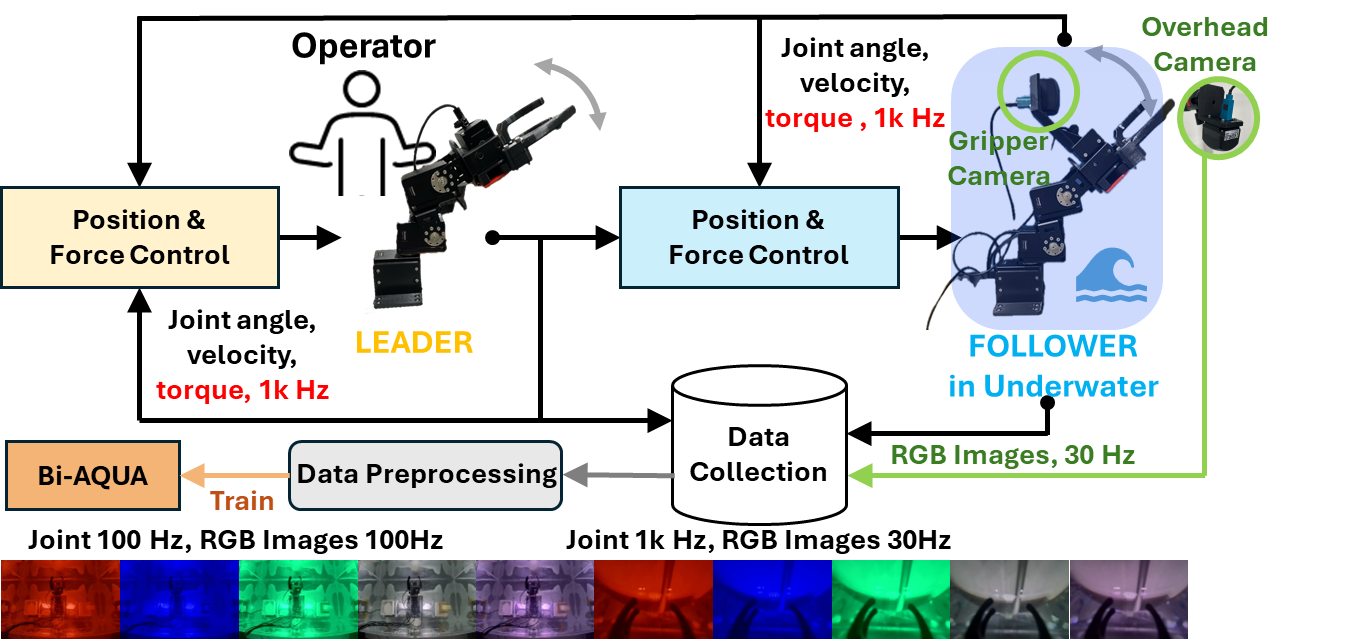
The team trained the robot by having a person control a “leader” robot arm in the air while a “follower” robot arm copied the motions underwater. This setup is called bilateral control:
- “Bilateral” means information flows both ways: the human moves the leader arm, and the underwater robot mirrors it—but the human also feels forces back, so they can be gentle when the underwater arm touches things. The robot records these positions and forces, which teach it how to act later by itself.
They then built a learning system that pays attention to lighting in three smart ways:
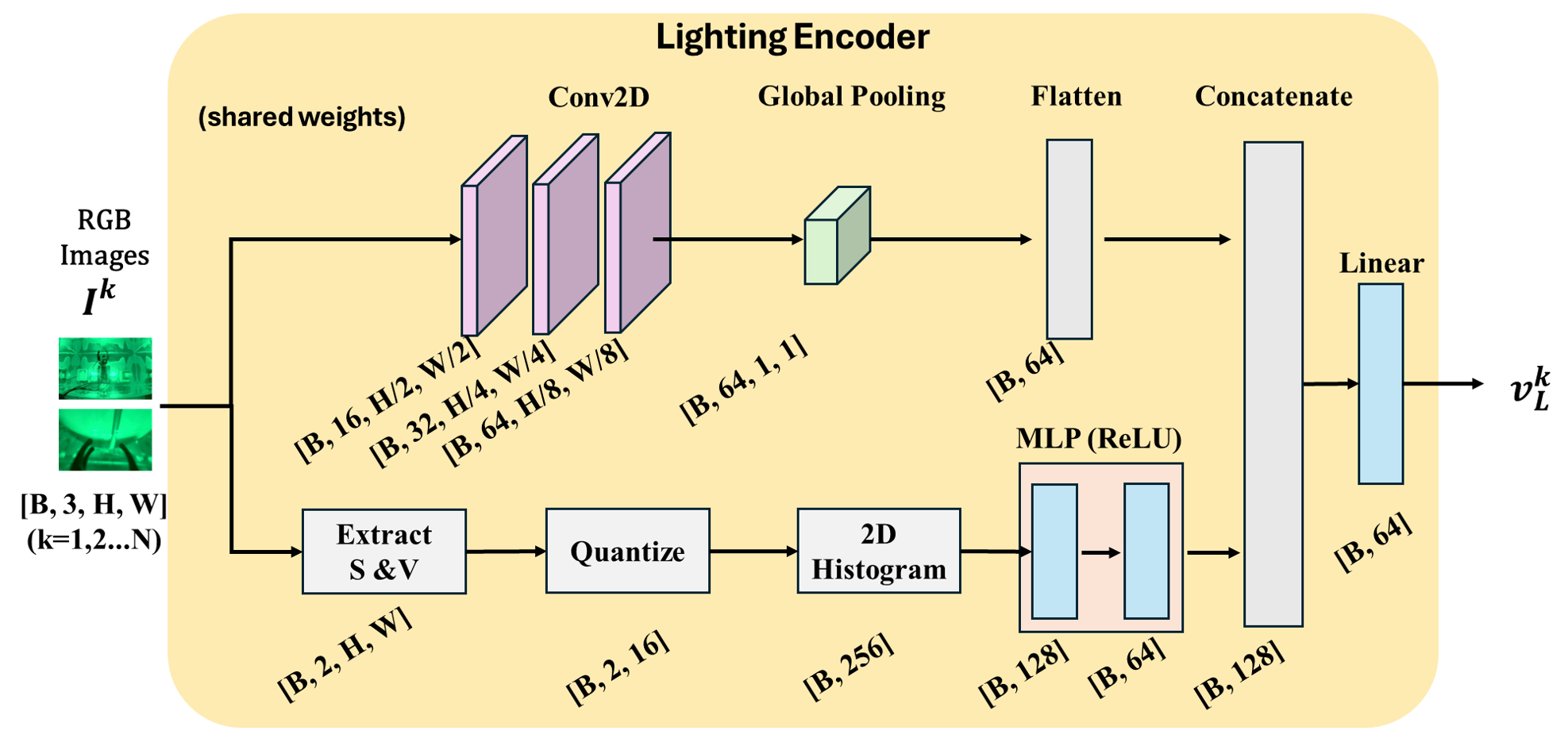
- Lighting Encoder
- This is like the robot’s “light detector.” From each camera image, it learns a short summary of what the lighting currently looks like (color, brightness).
- Importantly, nobody labels the lights (e.g., “this is red light”). The robot figures out lighting patterns by itself because it’s trained to copy good actions under those lights.
- FiLM (Feature-wise Linear Modulation)
- Imagine photo-editing sliders that adjust colors and contrast. FiLM lets the robot’s vision features be “tuned” based on the current lighting summary from the Lighting Encoder.
- That way, the robot’s “eyes” don’t get confused by blue, red, or dim scenes; they adapt on the fly.
- Lighting Token in a Transformer
- A transformer is a kind of model that’s good at understanding sequences (like planning a few steps ahead).
- The “lighting token” is like a sticky note the robot passes into its planning brain: “Hey, remember the light is blue right now.” This helps the robot choose the right actions for the current lighting, not just process images better.
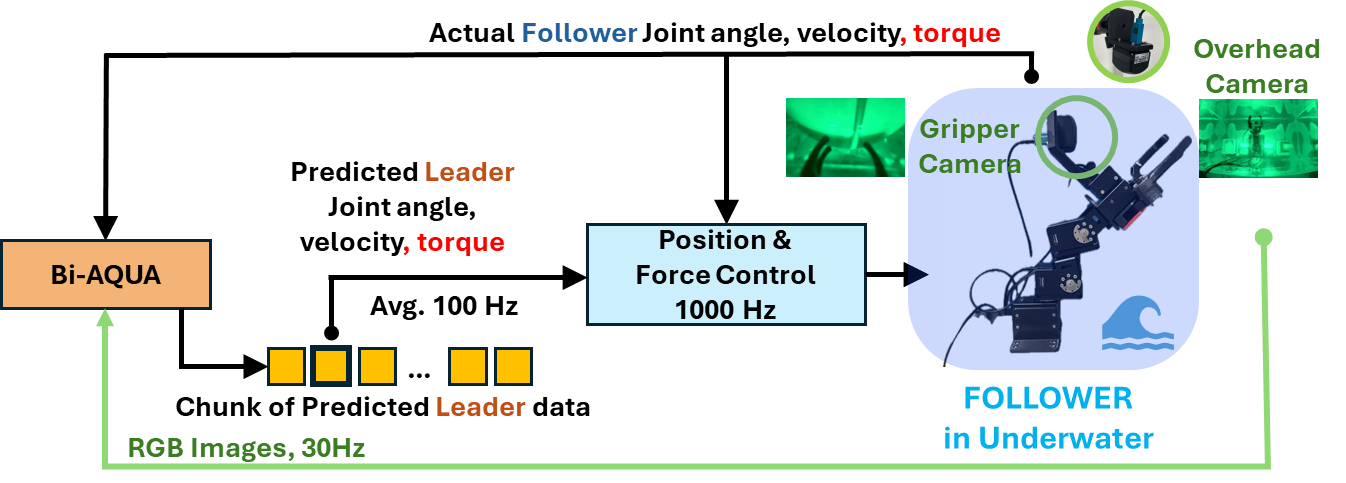
They also use “action chunking,” which means the robot doesn’t decide every tiny movement separately. Instead, it plans short “mini-scripts” of motions. This makes actions smoother and more stable.
In short: the robot learns by watching and feeling (imitation learning with forces), and it adapts both its vision and its action planning to the current lighting.
What did they find, and why is it important?
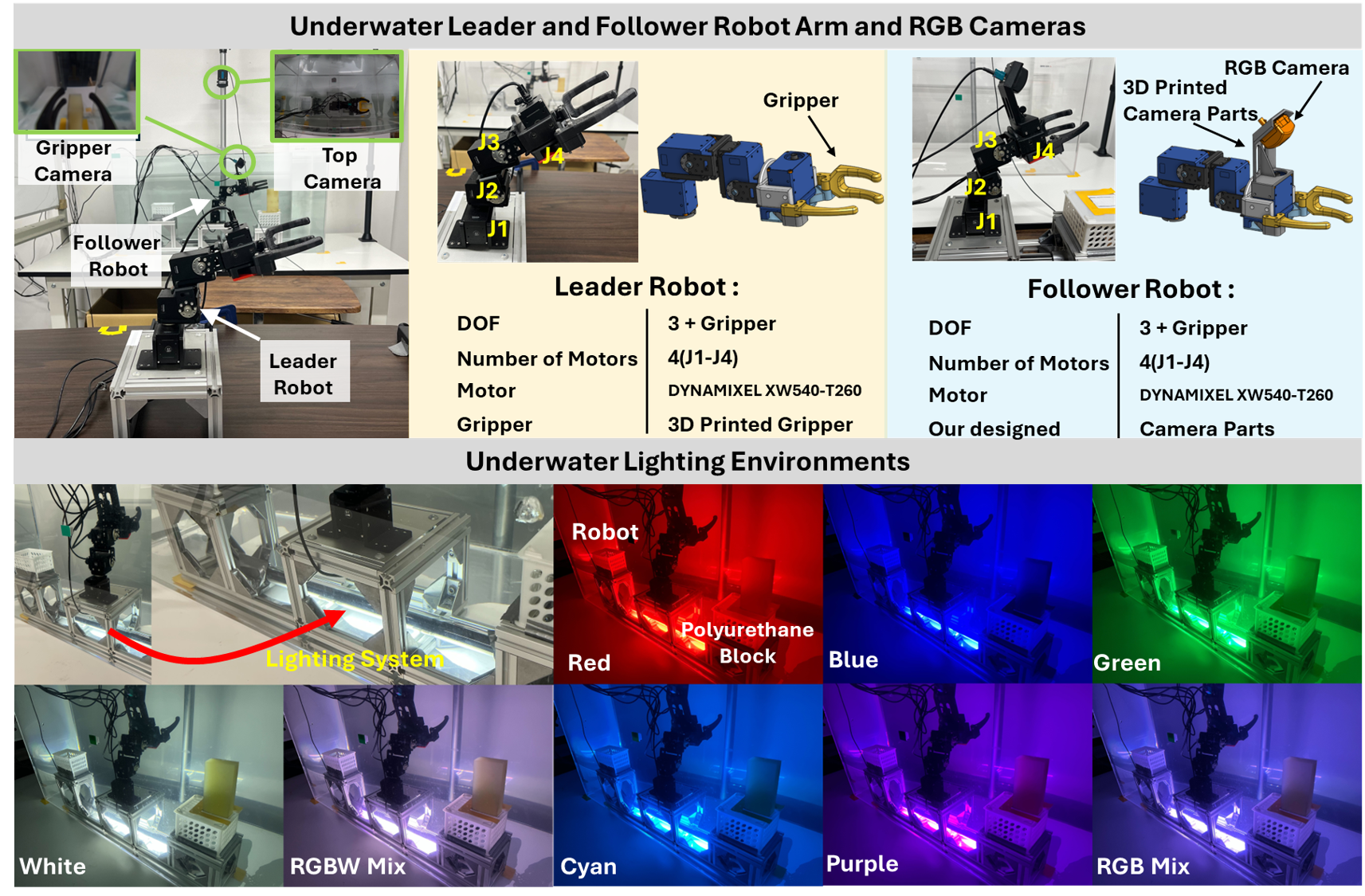
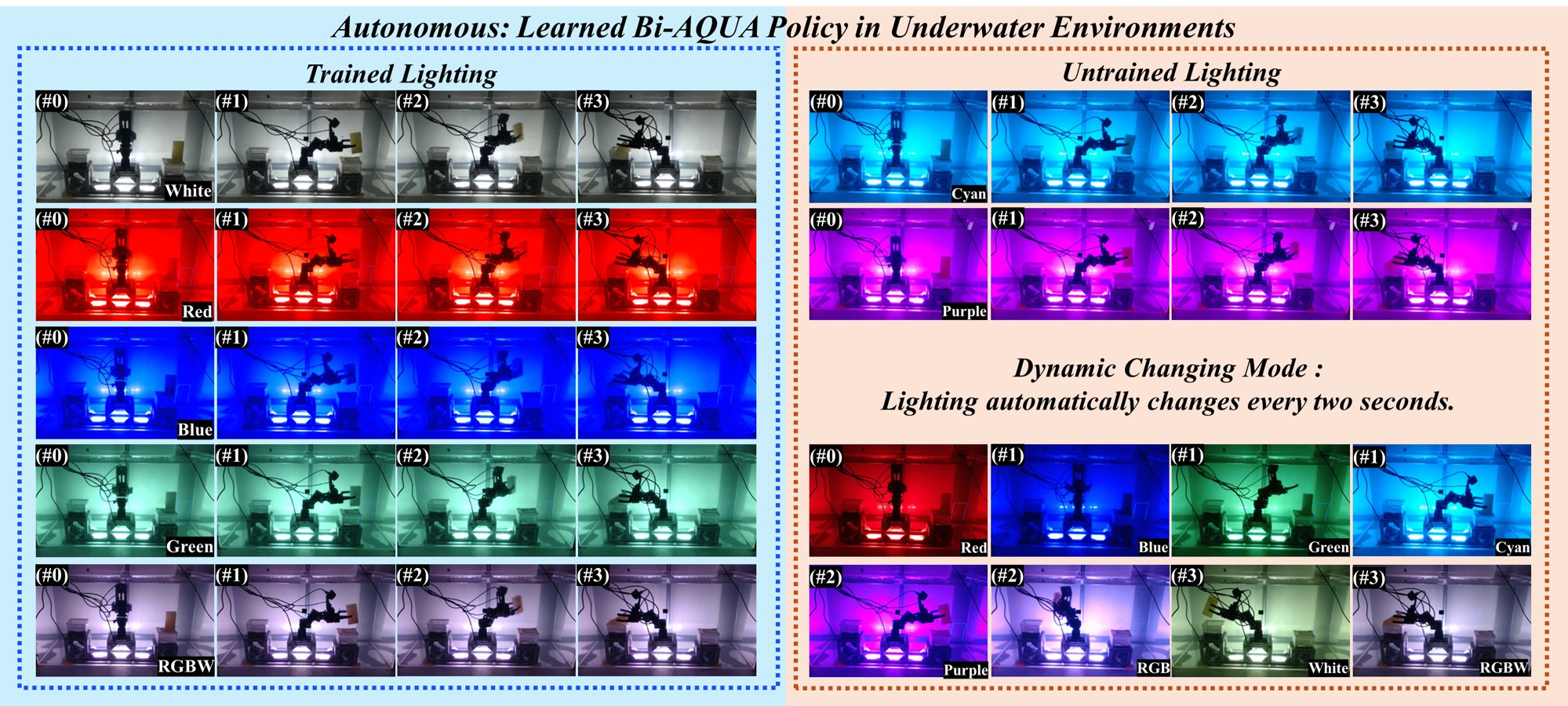
They tested the robot on a real underwater pick-and-place task under many lights: red, blue, green, white, multi-color, two new colors it hadn’t seen during training (cyan, purple), and a fast “changing” mode that cycles colors every 2 seconds.
Key results:
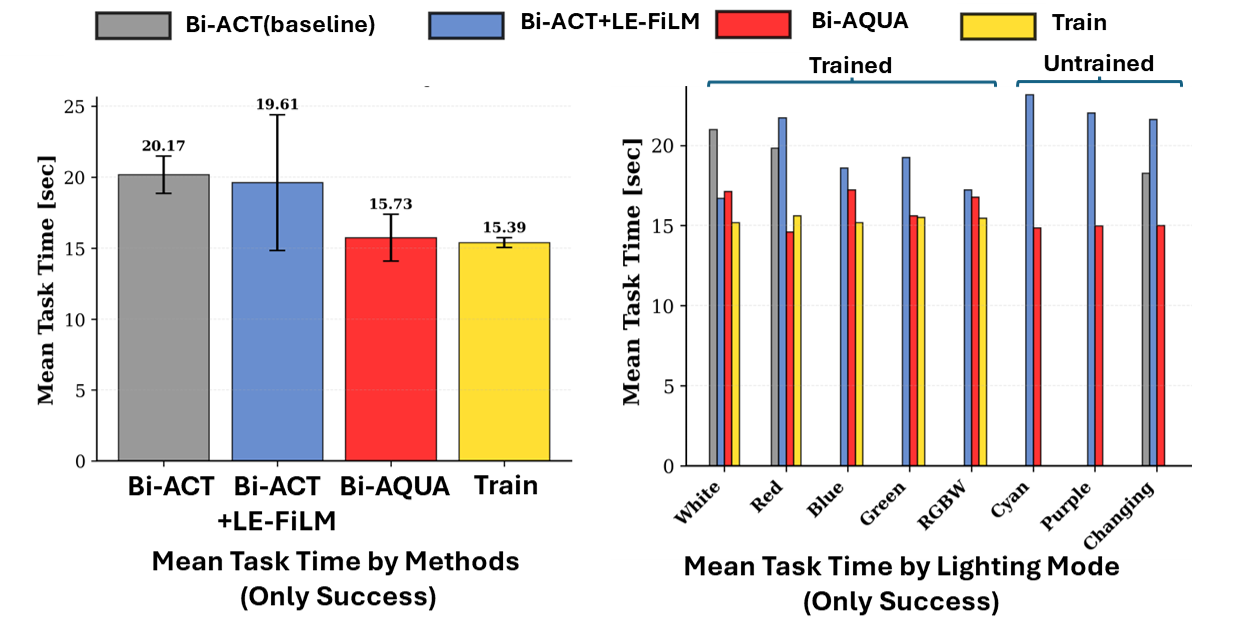
- Bi-AQUA worked very well in almost all lighting conditions—often 100% success, including in the fast changing-light mode where most methods fail.
- A version without lighting modeling (the baseline) failed in most colored lights and only worked reliably under white light.
- If they only added the lighting token (without FiLM), it still failed. If they only used FiLM (without the lighting token), it did better, but struggled when the lights changed quickly.
- The full combo (Lighting Encoder + FiLM + Lighting Token) was needed for top performance in both static and rapidly changing lighting.
- The robot also handled new objects and disturbances it wasn’t trained on—like a black block, a blue sponge, and bubbles—showing some ability to generalize.
- It performed close to human speed and didn’t need special force sensors (it estimated forces from the motors), making the setup simpler and cheaper.
Why this matters:
- Underwater images change a lot because water absorbs and scatters light. If the robot can’t adapt, it will grab the wrong thing or miss the target. Bi-AQUA keeps perception and actions steady even when the scene looks very different moment to moment.
What’s the bigger impact?
- Safer, more reliable underwater robots: Better at grasping, inspecting, or placing objects even when lights change suddenly (like in the ocean with shadows, clouds, or colored lights).
- Less dependence on perfect visuals: The robot combines “seeing” with “feeling,” making it more robust in murky or colored water.
- Practical uses: Marine research, ship or pipeline inspection, environmental cleanup (like picking trash), and repairs—tasks where lighting is unpredictable.
- A foundation for future work: The idea of treating lighting as something the robot explicitly models—not just something to ignore—could help other robots (not just underwater ones) work better in tricky lighting. Future steps include testing in bigger, messier environments and with more tasks.
In short: Bi-AQUA teaches underwater robot arms to learn from humans and stay steady under shifting, colorful lighting by recognizing and adapting to the light itself—both in what the robot sees and how it decides what to do next.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Limited task diversity: evaluation restricted to a single pick-and-place skill; unclear whether the approach scales to contact-rich assembly, deformable manipulation, multi-step tasks, or dynamic targets.
- Single platform and morphology: only a 3-DOF arm with a gripper is tested; transfer to higher-DOF arms, bimanual setups, or vehicle-manipulator systems is unverified.
- Tank-only experimentation: no pool, harbor, or open-water trials; robustness to currents, waves, pressure, biofouling, and long-distance tethering is unknown.
- Constrained lighting setup: eight LED presets from a single source beneath the arm may not reflect real subsea lighting (multi-source, moving, caustics, sun glint, backscatter); generalization to natural illumination is untested.
- No turbidity/backscatter variation: water clarity is held constant; performance under suspended particulates, high scatter, and low visibility remains unquantified.
- Small dataset (10 demos): no scaling curves for data efficiency; sensitivity to demonstration count, operator variability, and demonstration quality is unstudied.
- Image–control rate mismatch: images (30 Hz) are aligned to 100 Hz by nearest-frame selection, introducing repeated frames; impacts on temporal perception and control stability under rapidly changing lighting are not analyzed.
- Latency and rate budgeting: end-to-end inference rate, end-to-end latency, and interaction with control-loop frequency are not reported; stability under compute budgets typical of embedded AUV compute is unknown.
- Lighting representation interpretability: the learned lighting embedding is not validated against measurable photometric quantities (intensity/spectrum) or disentanglement from object color/texture.
- Disentanglement concerns: without lighting labels, the Lighting Encoder may conflate illumination changes with object/scene coloration; no controlled experiments separating object color from lighting spectra.
- Temporal modeling of lighting: no explicit temporal smoothing or recurrent model for lighting state; robustness to fast flicker or abrupt illumination transitions beyond 2 s cycling is untested.
- Injection design choices: FiLM is only applied to the final ResNet block; effects of multi-layer modulation, early vs. late fusion, and alternative conditioning (e.g., cross-attention gating, adapter layers) are not explored.
- Lighting token placement: conditioning is applied via an encoder token; comparative studies of injecting at the decoder, multi-token schemes, or hierarchical tokens are missing.
- Multi-view lighting fusion: per-view lighting embeddings are averaged; the optimal fusion strategy (e.g., learned weighting, attention fusion, view-dependent tokens) is not investigated.
- Camera robustness: effects of auto-exposure/white-balance, lens condensation, refraction at flat ports, and bubble adhesion on lenses are not evaluated; camera calibration under refraction is not discussed.
- Sensor modality gaps: only RGB is used; potential gains from polarization, depth, sonar, event cameras, or water-quality sensors (e.g., turbidity meters) are untested.
- Preprocessing baselines: the method is not compared against strong image enhancement/relighting pre-processors (e.g., Sea-Thru, DeepSeeColor) integrated with Bi-ACT or as joint training baselines.
- Learning baselines: no comparison to diffusion policies, RT-style transformers, or recent recurrent/mamba-based models with lighting-aware conditioning in the same setting.
- Augmentation and sim2real: systematic evaluation of domain randomization, physics-based relighting, or synthetic pretraining for underwater conditions is absent.
- Online adaptation: no experiments with test-time adaptation, meta-learning, or self-supervised updates to track lighting and visibility drift during deployment.
- Force/interaction analysis: no ablation isolating the contribution of bilateral force cues versus lighting-aware vision; the specific benefit of bilateral control under severe visual degradation is not quantified.
- Torque estimation fidelity: DOB/RTOB-based torque estimation accuracy underwater is not validated (e.g., hydrodynamic loads, added mass); effect of misestimation on policy learning/execution is unknown.
- Action chunking under non-stationarity: the impact of chunk horizon on performance under rapidly changing lighting is not studied; adaptive horizon or replanning frequency may be necessary.
- Safety and stability guarantees: no analysis of passivity/stability of the closed-loop bilateral system when driven by a learned policy under perception uncertainty.
- Failure mode taxonomy: only success rate and execution time are reported; no detailed categorization of failure cases (e.g., misgrasp vs. mislocalization vs. lighting-induced hallucination) to guide targeted improvements.
- Generalization breadth: while three novel object/disturbance conditions are tested, broader variations (textures, shapes, translucency, specular materials, clutter) are not systematically covered.
- Robustness to viewpoint changes: camera poses are fixed; resilience to camera misalignment, vibration, or partial occlusion is not tested.
- Hyperparameter sensitivity: no sweeps for lighting embedding dimension, number of cameras, FiLM strength, or KL weight; sensitivity and reproducibility are unclear.
- Reproducibility and assets: details on releasing data, calibration parameters, and code for the Lighting Encoder/FiLM integration are not specified; external replication may be limited.
- Energy and compute footprint: power consumption and thermal constraints relevant for underwater platforms are not discussed; feasibility on embedded GPUs is uncertain.
- Long-horizon autonomy: no assessment of drift over extended missions or cumulative error under prolonged lighting variability.
- Domain shift across days/sites: robustness to day-to-day shifts (e.g., different tanks, backgrounds, sediments) or to different water chemistries (fresh vs. salt) is untested.
- Integration with planning: the approach is purely reactive; benefits from combining lighting-aware perception with task/trajectory planning or uncertainty-aware control are unexplored.
- Theoretical grounding: no formal analysis of identifiability or invariance properties of lighting-aware conditioning; conditions under which the learned representation improves control are not characterized.
Practical Applications
Immediate Applications
These are deployable now in controlled or semi-controlled aquatic environments, given modest engineering integration and a small number of teleoperated demonstrations.
- Healthcare, energy, research labs: Underwater or in-pool tooling and sample handling
- Use case: Pick-and-place of tools and specimen containers in tanks, test pools, or spent-fuel pools where spectral lighting is nonstandard (e.g., Cherenkov-blue).
- Product/workflow: Retrofit existing ROV/manipulator arms with a Bi-AQUA-trained visuomotor policy; collect 10–20 bilateral demonstrations per task; deploy closed-loop with bilateral controller.
- Assumptions/dependencies: Clear to moderately turbid water, two RGB camera views (e.g., gripper and overhead), sensorless torque estimation (DOB/RTOB), edge GPU (≈8 GB VRAM), 3–6 DoF manipulator; site safety review required for nuclear contexts.
- Aquaculture: Object transfer and routine pen maintenance
- Use case: Move feed cartridges, place sensors, adjust clips on nets in fish pens with variable lighting and bubbles.
- Product/workflow: Low-cost bilateral teleoperation for data collection in a pen-side tank; train Bi-AQUA policy; deploy during maintenance windows.
- Assumptions/dependencies: Moderate currents only; predictable net geometry; multi-view cameras; protection against biofouling on optics.
- Aquarium operations and marine research stations: Curatorial and experimental manipulations
- Use case: Place substrates, relocate lightweight artifacts, position cameras or probes in exhibit tanks with colorful lighting.
- Product/workflow: Bench-top manipulation kit (leader arm in air, follower arm underwater) plus Bi-AQUA training; repeatable lighting stress tests using RGBW LED rigs.
- Assumptions/dependencies: Tank-accessible workspace; operator-led bilateral demonstrations; safety interlocks to prevent damage to specimens.
- Industrial water treatment and manufacturing: In-tank inspection and light-duty manipulation
- Use case: Turn small valves, lift grates, place test strips or sensors in settling tanks with uneven illumination.
- Product/workflow: Integrate Bi-AQUA with existing service ROVs; build a small task library via bilateral demos; run periodic QA under color-cycling lighting to verify robustness.
- Assumptions/dependencies: Low current environments, known fixtures, regular maintenance to keep optics clean, edge compute.
- Environmental monitoring (nearshore): Shallow-water specimen collection under variable color and turbidity
- Use case: Grasp and deposit water-sampling bottles or tagged items in baskets during surveys at docks/estuaries.
- Product/workflow: Boat-deployed ROV with 2 cameras; short demonstration collection in a controlled tank; transfer policy to field with conservative safety envelope.
- Assumptions/dependencies: Similar lighting statistics between tank and field; fallback teleoperation in high turbidity; stable manipulator and buoyancy control.
- Software and robotics development: Lighting-aware policy components as drop-in modules
- Use case: Improve robustness of existing visuomotor pipelines (ACT/Bi-ACT, diffusion policies) by conditioning perception and action on learned lighting embeddings.
- Product/workflow: Pluggable Lighting Encoder, FiLM modulation blocks for ResNet backbones, and a “lighting token” interface for transformers; end-to-end retraining with existing demos.
- Assumptions/dependencies: Access to training code and datasets; modest hyperparameter tuning; no lighting labels required.
- QA and benchmarking: Lighting stress-test harness for underwater manipulation policies
- Use case: Systematically evaluate failure modes under static colors and dynamic color-cycling.
- Product/workflow: Standard LED rig and protocol; report success rates, execution time profiles, and failure taxonomy; use Bi-AQUA as a baseline.
- Assumptions/dependencies: Reproducible lighting presets; synchronized multi-view capture; unified logging across vision and joint states.
- Education and training: Hands-on bilateral IL for underwater robotics
- Use case: University lab modules on sensorless force control and lighting-aware visuomotor learning.
- Product/workflow: Low-cost leader–follower kit, small tank, two cameras; course materials showing action chunking, FiLM, and lighting-token conditioning.
- Assumptions/dependencies: Safety protocols for wet labs; entry-level GPU; open-source materials.
Long-Term Applications
These require further research, scaling, certification, or extended datasets before reliable field deployment.
- Energy (offshore oil/gas, wind): Autonomous subsea maintenance under harsh lighting and hydrodynamics
- Use case: Valve turning, connector mating, cable routing on subsea structures with silt, biofouling, and dynamic illumination.
- Product/workflow: Bi-AQUA extended to higher-DoF manipulators on work-class ROVs/AUVs; multi-modal sensing (stereo, sonar, depth) fused with lighting-aware vision; task libraries trained from expert bilateral demos.
- Assumptions/dependencies: Robust to currents and turbidity; certification for safety-critical operations; on-board compute and power budgets; extensive field trials.
- Marine construction and salvage: Delicate and heavy-object manipulation
- Use case: Recover artifacts, install brackets, cut and place lines where visibility and lighting shift rapidly.
- Product/workflow: Multi-arm systems with coordinated bilateral IL; learning from demonstrations in large test pools with domain randomization and physics-based relighting.
- Assumptions/dependencies: Scalable datasets across object categories; enhanced force sensing; reliability guarantees and contingency teleoperation.
- Underwater archaeology and cultural heritage: Non-destructive artifact handling
- Use case: Lift, clean, and reposition fragile items under color-distorted illumination.
- Product/workflow: Policy libraries tuned for low-force thresholds and compliant control; “white-glove” safety constraints encoded in the controller.
- Assumptions/dependencies: Ethical approvals; strict safety and logging standards; fine-grained force feedback and compliance modeling.
- Environmental restoration: Coral gardening and seagrass planting
- Use case: Plant, cable-tie, and position nursery fragments in variable light and surge.
- Product/workflow: Bi-AQUA combined with task-specific grippers and online adaptation (meta-learning) for changing conditions.
- Assumptions/dependencies: Habitat protection policies; collaborative workflows with divers; resilience to biofouling and currents.
- Defense and public safety: Underwater EOD and inspection
- Use case: Manipulate ordnance or inspect hulls with low visibility and dynamic lighting.
- Product/workflow: Hardened, certifiable manipulation policies with explainable failure modes and strict rules of engagement.
- Assumptions/dependencies: Classified datasets; extensive validation; robust fallback teleoperation.
- Consumer and service robotics: Pool cleaning and aquarium maintenance with manipulators
- Use case: Retrieve items, adjust fixtures, place decor in home or public aquaria with colorful lighting.
- Product/workflow: Cost-reduced hardware, compressed models (quantization/pruning), simplified bilateral demo collection via app-guided teleoperation.
- Assumptions/dependencies: Manufacturing cost constraints; user safety and waterproofing; minimal calibration workflows.
- Cross-domain robotics (non-underwater): Low-light, non-uniform illumination manipulation
- Use case: Night-time industrial work, endoscopic or laparoscopy assistance, metallurgical processes with glare.
- Product/workflow: Adapt the Lighting Encoder/FiLM/token stack to new spectra and sensors (IR, endoscope optics), retraining with domain-specific demos.
- Assumptions/dependencies: New sensing modalities and optics; clinical/industrial certification; domain-specific failure analysis.
- Data and benchmarks: Standardized underwater IL dataset ecosystem
- Use case: Shared benchmarks for lighting-aware manipulation across tasks and platforms.
- Product/workflow: Community datasets with labeled tasks but unlabeled lighting; standard LED stress protocols; leader–follower logs and evaluation metrics.
- Assumptions/dependencies: Data governance and licensing; multi-institution collaboration; reproducibility infrastructure.
- Policy and regulation: Safety and performance standards for autonomous underwater manipulation
- Use case: Procurement guidelines and certification tests for lighting robustness and force-aware safety.
- Product/workflow: Test protocols covering static/dynamic lighting, turbidity, bubbles; minimum success-rate and time-to-complete thresholds; logging and black-box recorder requirements.
- Assumptions/dependencies: Engagement with standards bodies (ISO/IEC); evidence from multi-site trials; clear liability frameworks.
- Edge AI platforms: Embedded, power-efficient deployment
- Use case: Real-time inference on ROV-class compute with constrained power.
- Product/workflow: Model distillation, mixed-precision/INT8, streaming-friendly transformers; hardware accelerators.
- Assumptions/dependencies: Thermal design; reliable power; maintaining control-loop latencies under action chunking.
Common assumptions and dependencies across applications
- Hardware: Bilateral leader–follower setup; underwater manipulator with at least 3–6 DoF; two RGB cameras (gripper + global view).
- Sensing/control: Sensorless force estimation (DOB/RTOB) or force sensors; synchronized vision and joint states; reliable waterproofing and optics maintenance.
- Compute: On-board or tethered GPU (≈8 GB VRAM for current models) or accelerated edge hardware; real-time control integration with action chunking buffers.
- Data: Task-specific bilateral demonstrations; training in tank-like environments; no lighting labels required, but representative lighting variation is needed.
- Environment: Performance degrades with extreme turbidity, strong currents, cluttered backgrounds; additional modalities (stereo/sonar/depth) may be necessary for field deployment.
- Safety and governance: Human-in-the-loop teleoperation fallback; interlocks for force and motion limits; compliance with site-specific safety standards.
Glossary
- Ablation study: A controlled experiment removing or altering components to assess their impact on performance. "Ablation studies further confirm that all three lighting-aware components are critical."
- Action chunk buffer: A buffered sequence of upcoming actions output at a higher rate between policy inferences to ensure smooth control. "we maintain an action chunk buffer of length and output actions at $f_{\text{train}$ between inference calls,"
- Action chunking: Predicting short sequences (chunks) of actions at once instead of single-step commands. "Bi-AQUA builds upon Bi-ACT--style action chunking"
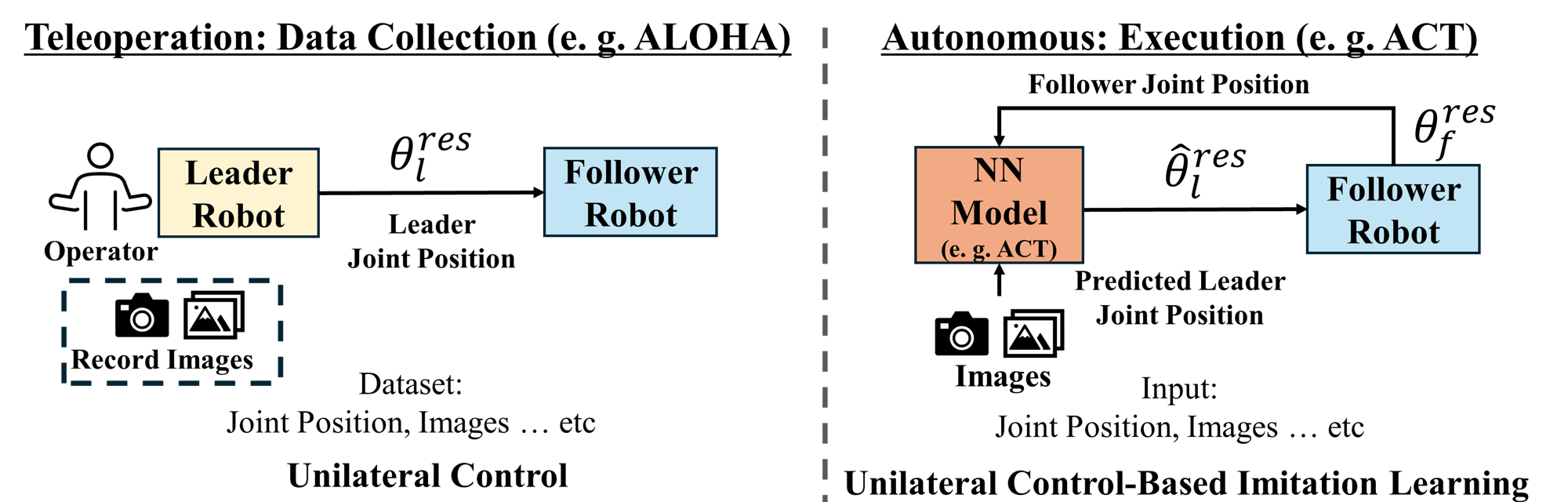
- Action Chunking with Transformers (ACT): A transformer-based method for learning to predict action sequences in manipulation tasks. "Action Chunking with Transformers (ACT)"
- Affine transformation (feature-wise): A per-channel scaling and shifting of feature maps used for conditioning neural features. "via a feature-wise affine transformation whose parameters are generated from the lighting embedding."
- ALOHA: A low-cost teleoperation platform/framework for learning manipulation, often used with ACT. "ALOHA and Action Chunking with Transformers (ACT)"
- Behavior cloning: Supervised learning of a policy by imitating expert demonstrations. "We train Bi-AQUA end-to-end using behavior cloning with a CVAE-style latent space:"
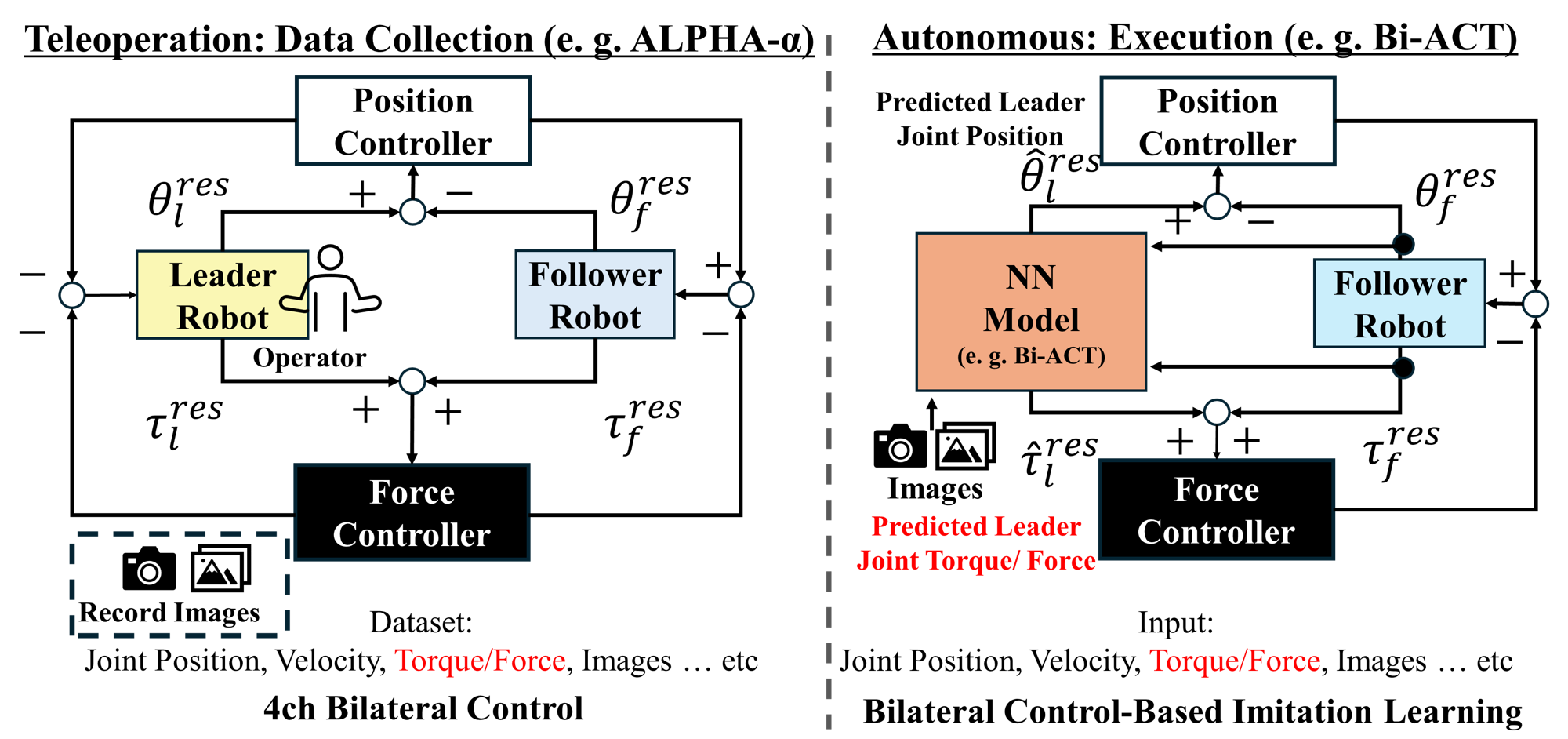
- Bilateral control: A control paradigm that exchanges both position and force between a leader and follower robot. "Bilateral control addresses this limitation by exchanging both position and force,"
- Bilateral control-based imitation learning (Bi-IL): Imitation learning that uses bilateral control signals (position and force) from teleoperation. "bilateral control-based imitation learning (Bi-IL)"
- Bi-ACT: A bilateral-control extension of ACT for force-sensitive visuomotor learning. "Among bilateral IL frameworks, Bi-ACT~\cite{buamanee2024biactbilateralcontrolbasedimitation} plays a central role"
- Closed-loop manipulation policy: A control policy that continuously uses feedback (e.g., vision, force) to adjust actions during execution. "closed-loop manipulation policies must adapt both perception and action generation to rapidly varying lighting."
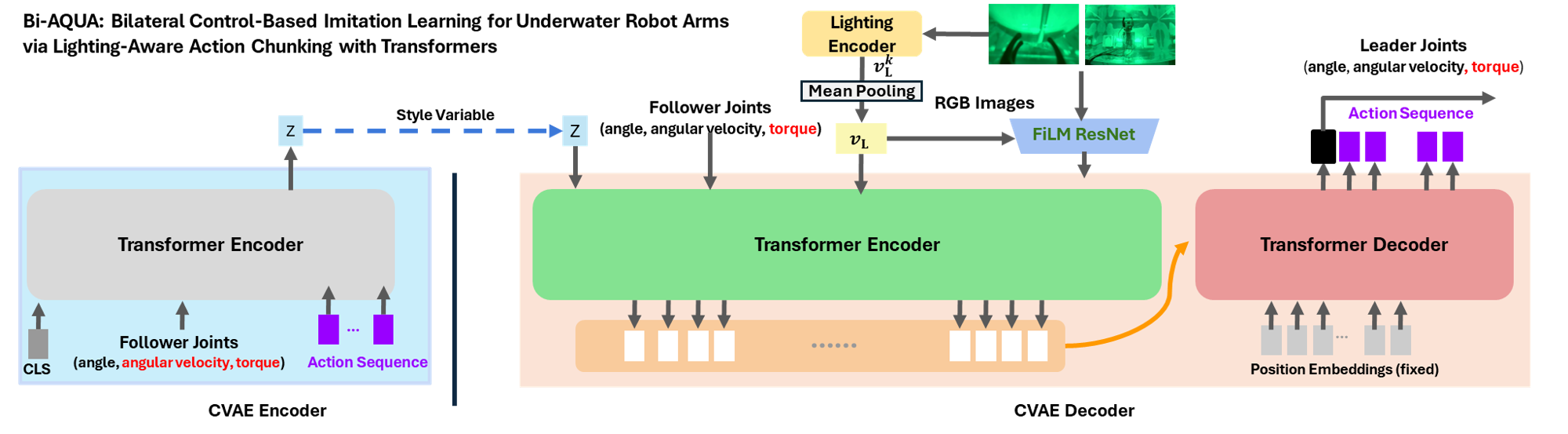
- Conditional Variational Autoencoder (CVAE): A generative model that learns a conditional latent space for structured outputs, here used for action chunks. "Bi-AQUA employs a Conditional Variational Autoencoder (CVAE) with a transformer backbone,"
- Cross-attention: An attention mechanism where a decoder attends to encoder memory to condition its outputs. "accessed by the transformer decoder via cross-attention,"
- Disturbance observer (DOB): An observer that estimates external disturbances (e.g., unmodeled forces) from system dynamics. "torques by a disturbance observer (DOB)"
- Domain randomization: Training-time randomization of visual/physical factors to improve robustness to real-world variation. "domain randomization"
- Feature map: A tensor of activations produced by a convolutional layer representing learned features. "For a feature map at layer "
- FiLM (Feature-wise Linear Modulation): A conditioning method that scales and shifts feature channels based on a context vector. "FiLM modulation of visual backbone features for adaptive, lighting-aware feature extraction,"
- Force feedback: Sensing and using force/torque information to inform control, especially in contact-rich tasks. "Without force feedback, these methods struggle in contact-rich or visually ambiguous interactions."
- Global average pooling: A pooling operation that averages spatial dimensions to obtain a compact channel descriptor. "followed by ReLU and global average pooling to yield spatial features"
- Imitation learning (IL): Learning control policies by imitating expert demonstrations rather than optimizing a reward. "imitation learning (IL)"
- KL divergence: A measure of difference between two probability distributions, used here for latent regularization. "KL divergence between the learned latent distribution and a standard normal prior,"
- Latent action code: A sampled latent variable that conditions the policy’s action chunk generation. "samples a latent action code from the prior,"
- Latent space: The learned space of latent variables that capture underlying factors for action generation. "a CVAE-style latent space:"
- Latent variable: An unobserved variable inferred by the model that explains variation in observations or control. "treats lighting as a latent variable inside the visuomotor policy,"
- Leader–follower bilateral control: Teleoperation setup where a human-operated leader robot and an autonomous follower robot exchange position and force. "leader--follower bilateral control"
- Letterboxing: Resizing images by padding to preserve aspect ratio without distortion. "via letterboxing."
- Lighting Encoder: A network module that extracts a compact representation of scene lighting from RGB inputs. "a Lighting Encoder that extracts lighting representations from RGB images without manual annotation"
- Lighting token: A dedicated token injected into the transformer to condition sequence generation on lighting. "a lighting token added to the transformer encoder input"
- Mamba-based motion encoders: Sequence modeling components using the Mamba architecture for motion encoding. "Mamba-based motion encoders"
- Positional embeddings (2D sinusoidal): Deterministic embeddings that encode spatial positions for transformer inputs. "2D sinusoidal positional embeddings"
- Proprioception: Internal sensing of the robot’s joint positions, velocities, and torques. "proprioception-only Bi-IL becomes perceptually blind,"
- Reaction torque observer (RTOB): An observer that estimates joint reaction torques without dedicated sensors. "a reaction torque observer (RTOB)"
- ResNet-18: A 18-layer residual neural network backbone commonly used for visual feature extraction. "ResNet-18 backbone"
- Teleoperation: Remote operation of a robot by a human operator. "Traditional underwater manipulation is dominated by teleoperation"
- Transformer decoder: The part of a transformer that generates outputs conditioned on encoder memory and/or previous outputs. "uses the transformer decoder to generate an action chunk for the leader robot."
- Transformer encoder: The part of a transformer that processes input tokens into a memory representation for the decoder. "added to the transformer encoder input"
- Turbidity: Cloudiness of water due to suspended particles that scatter light and degrade visibility. "turbidity"
- Unilateral control: Control relying only on position/velocity commands without exchanging force information. "These method yet all rely on unilateral control,"
- Visuomotor policy: A control policy that maps visual observations to motor actions. "Lighting variability is one of the dominant factors degrading visuomotor policy performance,"
- Wavelength-dependent attenuation: Differential loss of light intensity by color as it propagates underwater. "wavelength-dependent attenuation"
Collections
Sign up for free to add this paper to one or more collections.