Kandinsky 5.0: A Family of Foundation Models for Image and Video Generation
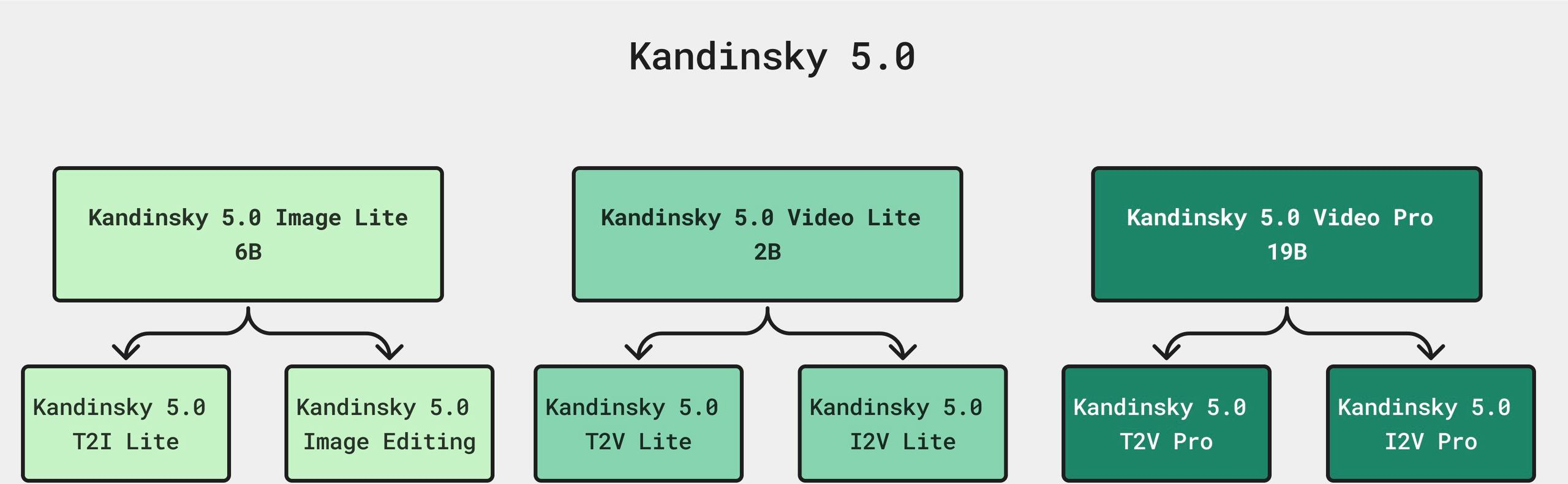
Abstract: This report introduces Kandinsky 5.0, a family of state-of-the-art foundation models for high-resolution image and 10-second video synthesis. The framework comprises three core line-up of models: Kandinsky 5.0 Image Lite - a line-up of 6B parameter image generation models, Kandinsky 5.0 Video Lite - a fast and lightweight 2B parameter text-to-video and image-to-video models, and Kandinsky 5.0 Video Pro - 19B parameter models that achieves superior video generation quality. We provide a comprehensive review of the data curation lifecycle - including collection, processing, filtering and clustering - for the multi-stage training pipeline that involves extensive pre-training and incorporates quality-enhancement techniques such as self-supervised fine-tuning (SFT) and reinforcement learning (RL)-based post-training. We also present novel architectural, training, and inference optimizations that enable Kandinsky 5.0 to achieve high generation speeds and state-of-the-art performance across various tasks, as demonstrated by human evaluation. As a large-scale, publicly available generative framework, Kandinsky 5.0 leverages the full potential of its pre-training and subsequent stages to be adapted for a wide range of generative applications. We hope that this report, together with the release of our open-source code and training checkpoints, will substantially advance the development and accessibility of high-quality generative models for the research community.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces Kandinsky 5.0, a family of smart AI models that can create high‑quality pictures and short videos (up to 10 seconds) from text, or by transforming existing images. Think of them as very advanced “digital artists” that learn from huge amounts of visual data and then generate realistic, creative results quickly.
The Kandinsky 5.0 family
There are three main model types, each designed for different needs:
- Kandinsky 5.0 Video Pro: The most powerful video model (19 billion parameters) for the highest quality videos.
- Kandinsky 5.0 Video Lite: A faster, lighter video model (2 billion parameters) that still makes good 10-second clips.
- Kandinsky 5.0 Image Lite: A strong image model (6 billion parameters) for text-to-image and image editing at high resolution.
Key goals and questions
In simple terms, the paper tries to answer:
- How can we make AI that draws and films better, faster, and more realistically?
- How do we collect and clean massive amounts of image and video data so the AI learns only from good examples?
- What model design helps handle videos (which are many frames over time) without becoming too slow or expensive?
- How can we train and fine-tune the models so they follow text directions closely and look great?
- Can we compress or “distill” slow models into faster ones without losing quality?
- Do people actually prefer the results compared to other top models?
How they did it: methods explained simply
To build Kandinsky 5.0, the team combined smart data curation, careful training, and clever model design. Here’s what that means in everyday language:
1) Giant, clean training datasets
- The models learn from hundreds of millions of images and videos gathered from many sources.
- They use filters to remove low-quality content: detect watermarks, too much text, blurry frames, near-duplicates, or overly simple pictures.
- They add captions (short descriptions) using other AI models, so the generator can link words to visuals.
- They group similar videos using clustering, which helps balance what the AI sees during training.
- They also built special datasets:
- Image editing pairs: two related images plus an instruction (like “open the car’s butterfly doors”), carefully checked to be real edits, not just crops.
- Russian Cultural Code: hand-picked images/videos that reflect Russian culture, with detailed Russian and English descriptions, so the model better understands that domain.
- SFT (Supervised Fine-Tuning) data: a smaller, expert-curated collection of very high-quality images and scenes to polish the model’s sense of aesthetics and composition.
Think of this like training a chef: first they try lots of dishes (big dataset), then focus on the best recipes (SFT) with expert guidance.
2) Training in stages
- Pretraining: The model first learns general “visual patterns of the world” from huge datasets.
- Self-supervised fine-tuning (SFT): It then practices on top-quality examples to improve realism and style.
- RL-based post-training: A final stage uses feedback (comparing outputs to curated examples) to make results look more natural and better match the prompt.
Analogy: First you learn to draw from lots of pictures (pretrain), then practice with the best references (SFT), and finally a coach critiques your drawings so you improve the final look (post-training).
3) A video-friendly architecture (CrossDiT + NABLA)
- CrossDiT: A Diffusion Transformer designed to generate images and videos by “cleaning” random noise into clear visuals guided by text. Diffusion/flow matching is like slowly removing static from a TV screen until a crisp picture appears, following instructions.
- Attention optimization (NABLA): Regular attention looks everywhere in every frame, which gets super expensive for long, high-resolution videos. NABLA focuses on smart “neighborhood blocks” across space and time, so the model looks where it needs to, not everywhere at once. This cuts compute time by about 2.7× while keeping quality high.
Analogy: Instead of scanning every pixel of every frame with a giant spotlight, NABLA uses small spotlights that jump to the most relevant nearby areas, like reading a comic strip panel by panel instead of trying to see every page at once.
4) Speed and efficiency tricks
- VAE optimization: Compress images/videos into a smaller “latent” space (like zipping a file) to save memory and speed up training/inference.
- Text encoder quantization: Store numbers with fewer bits (like saving a photo in slightly lower precision) to run faster without noticeable quality loss.
- Smart training across multiple GPUs (sharding) and activation checkpointing: Split the workload and recompute some parts on the fly to fit bigger models into memory.
5) Distillation: making fast students from slow teachers
- The team used methods that transfer knowledge from a slow, high-quality model to a smaller, faster one.
- This reduced the number of generation steps from 100 to just 16 while keeping visual quality similar.
Analogy: A master painter teaches an apprentice shortcuts that still produce beautiful art, so they paint faster with similar results.
6) Testing quality
- They checked results using automatic metrics (like CLIP-score for text-image matching, FVD and VBench for video quality).
- Most importantly, they ran side-by-side human evaluations where people pick which result looks better or matches the prompt more closely.
Main findings and why they matter
Here are the standout results and their importance:
- High-resolution 10-second videos: The models can generate longer, sharper videos with convincing motion and detail.
- Faster generation: Using NABLA attention and distillation, the models are significantly faster (about 2.7× speedup), which means less waiting and lower costs.
- Better alignment to text: Outputs follow the prompt more closely, making the models more useful for creative work and instruction-based tasks.
- Strong human preference: In side-by-side tests, people often preferred Kandinsky 5.0’s videos for motion consistency, visual quality, and how well they matched the prompt.
- Open-source release: The team released code and training checkpoints, making it easier for researchers, students, and creators to build on this work.
What this means going forward
Kandinsky 5.0 pushes the boundaries of what open models can do in video and image generation. In simple terms:
- Creators can make realistic videos and images more quickly, from short films and trailers to art and design concepts.
- Educators and students can study and improve generative AI using high-quality open tools.
- Researchers gain a strong foundation to build next-gen multimedia systems, including “world models” that understand visual sequences over time.
- Cultural understanding improves by including curated datasets like the Russian Cultural Code.
- The paper also addresses safety and ethics (filtering watermarks, tackling text-heavy frames, careful data curation), but real-world use still needs responsible guidelines.
Overall, Kandinsky 5.0 shows that with the right data, smart architecture, and careful training, we can make AI artists that are both talented and efficient—and share them with the wider community.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following gaps and open questions that future researchers could address:
- Quantitative evaluation details are missing (exact FVD/VBench/CLIP-score numbers, prompt sets, sample sizes, seeds, variance, significance tests), limiting reproducibility and comparative assessment.
- Human side-by-side evaluation design is under-specified (rater recruitment, calibration, inter-rater reliability, protocol, cultural/language balance, and statistical power).
- No direct, controlled comparisons to leading proprietary systems (e.g., Sora, Veo) using standardized benchmarks and blind SBS—leaving relative performance uncertain.
- NABLA sparse spatio-temporal attention lacks a thorough ablation study (sparsity schedules, neighborhood sizes, block layouts, failure modes), robustness under fast motion, complex occlusions, and long-range dependencies.
- Scalability of NABLA beyond 10-second videos and >1024px resolutions is not characterized; computational trade-offs vs. quality for longer durations remain unclear.
- Guidance on choosing NABLA hyperparameters per resolution, aspect ratio, and motion profile is missing; adaptive schemes are not explored.
- Distillation pipeline details are incomplete (teacher/student architectures, loss balance for CFG-distillation vs. TSCD, adversarial post-training setup, discriminator design, stability), hampering replication.
- Impact of reducing NFE from 100 to 16 on temporal coherence, diversity, rare-event fidelity, and motion complexity is not quantified across domains.
- RLHF post-training method is under-specified (reward model design, signal source, training stability, preference data, adversaries, evaluation)—unclear how realism and prompt alignment gains are achieved.
- The role of human preference data vs. SFT-only comparisons in RLHF is unclear; risks of overfitting to SFT distribution and reduced diversity are not analyzed.
- Text encoder choice, multilingual coverage, and quantization effects on alignment, prompt-following accuracy, and cross-lingual performance are not reported.
- VAE optimization is described without reconstruction error analyses (PSNR/SSIM/LPIPS), temporal consistency tests, bitrate/latent shape for video, or artifacts induced by compression.
- Architecture for image editing (conditioning pathways, source-image fusion in CrossDiT, Instruct token format, control granularity) is not documented.
- Identity preservation in image-to-video and image editing tasks (faces, objects, scenes) lacks quantitative evaluation (ID similarity metrics, face recognition consistency).
- Control modalities for video (depth, segmentation, optical flow, camera path, pose, audio beat) are not detailed; how CrossDiT handles structured controls is unknown.
- Prompt controllability for camera and scene attributes (trajectory, focal length, exposure, grading) is not formally evaluated or benchmarked.
- Physics and world-modeling aspects (object permanence, collisions, gravity, fluid dynamics, lighting causality) are not tested, leaving physical plausibility uncertain.
- Longer-form video generation (multi-shot, transitions, narrative consistency >10s) is not addressed; mechanisms for scene continuation or stitching are missing.
- Audio generation/conditioning in Kandinsky 5.0 (present in 4.x) is not discussed; synchronicity and AV alignment remain open.
- Inference speed claims lack hardware-specific benchmarks (latency, throughput, VRAM footprints, batch scaling) across typical GPUs; energy and cost profiles are absent.
- Effects of text encoder quantization on prompt accuracy, rare token handling (proper nouns), and robustness to long prompts are unreported.
- Dataset composition transparency is partial (exact sources, licensing statuses, consent, geographic and demographic distributions, domain balance), hindering data governance assessment.
- Deduplication admits residual duplicates; cross-modality duplication (image-video overlaps) and near-duplicate detection across resolutions are not quantified.
- Filtering criteria may induce biases (removing text-heavy scenes undermines typography/poster tasks; watermark removal filters certain creators; complexity filters bias against minimalism), but bias analyses are missing.
- Synthetic caption quality (InternVL/Qwen/Tarsier/Qwen3 pipelines) is not benchmarked; noise rates, hallucinations, and language mixing effects are not quantified.
- Russian Cultural Code (RCC) specialization introduces potential cultural skew; balancing strategies for other cultures and multilingual evaluation are not provided.
- Safety evaluations (harmful content, deepfake risks, political persuasion, NSFW leakage, jailbreak resilience) are not reported with quantitative stress tests.
- Model watermarking/provenance tagging in generated outputs (for downstream trust/safety) is not discussed.
- Person and child privacy handling (faces, minors, identifiable information) and corresponding filters are not detailed.
- Domain classification via VLM vs. k-means: decision rules for training-time sampling using both signals and their impact on performance are not validated.
- SFT-soup mixing (weights averaging) lacks principled weight selection, stability analysis, and post-mix evaluation; risks of catastrophic forgetting are not assessed.
- SFT dataset curation thresholds (v1 strict, v2 relaxed) are not linked to downstream gains per domain; ablations to optimize selection criteria are missing.
- Data contamination checks (overlap with public benchmarks/test sets) are absent; leakage risks remain unknown.
- Release clarity is lacking: which models/checkpoints are fully open (especially 19B Video Pro), under what licenses, and with what usage restrictions.
- Fine-tuning pathways for end-users (LoRA/PEFT recipes, data requirements, safety constraints) are not provided; adaptation for domain-specific tasks remains opaque.
- Robustness to adversarial or compositional prompts (negation, multi-constraint instructions, multilingual mixed prompts) is not stress-tested.
- Generalization to non-photorealistic domains (cartoons, anime, scientific visualization) is only categorized, not separately benchmarked with domain-specific metrics.
- 3D consistency and camera trajectory correctness (e.g., SfM-style multi-view consistency, depth continuity) are not evaluated.
- I2V evaluation protocols are missing (temporal fidelity to source image, motion realism, background preservation); standardized metrics are not provided.
- Compute budgets (GPU hours, training time by stage, carbon footprint) and scalability limits for the multi-stage pipeline are not reported.
- Failure case catalog is absent (prompt classes or content types where models break: text rendering, fine patterns, hands, fast action, low light).
- Reproducibility risks exist due to reliance on proprietary or large-scale captioners/annotators; minimal, open, end-to-end recipes are not outlined.
Practical Applications
Immediate Applications
The following applications can be deployed now using Kandinsky 5.0’s released models, open-source code, and checkpoints, and with existing workflows and infrastructure.
- Industry — Creative production (advertising, film, TV, game studios)
- Use case: Rapid storyboarding and animatics with 10-second clips; generation of high-resolution concept frames and iterative edits aligned to prompts.
- Workflow: Video Lite (2B) for fast ideation; Image Lite (6B) to produce detailed keyframes; optional refinement via SFT-tuned checkpoints; human-in-the-loop review.
- Tools/products: Plugins for Adobe Premiere/After Effects and Blender; “Storyboard Generator” powered by CrossDiT; Figma/Photoshop extensions for instruction-based edits.
- Assumptions/dependencies: Quality depends on prompt engineering; Pro model (19B) requires larger GPUs; runtime safeguards for synthetic media must be enabled.
- Industry — Marketing and e-commerce
- Use case: Batch generation of product hero images and 10-second showcase videos; A/B variants (backgrounds, colors, angles) using instruction-following edits.
- Workflow: Pull product metadata from CMS, generate image variations with Image Lite, short clips with Video Lite; integrate QA checks (Q-Align, TOPIQ) before publishing.
- Tools/products: “Auto-Content Studio” for marketplaces; API-first service for batch asset generation leveraging NFE-reduced inference (100→16) to cut costs.
- Assumptions/dependencies: Brand compliance review; licensing for product imagery; dataset bias considerations; human approval in regulated campaigns.
- Industry — Localization and cultural adaptation
- Use case: Region-specific visuals leveraging RCC (Russian Cultural Code) dataset for culturally accurate imagery and short-form video.
- Workflow: Prompt templates with domain-aware SFT “soup” models; multilingual captioning pipelines (English/Russian).
- Tools/products: “Cultural Style Packs” and preset prompt libraries; local market QA team for cultural sensitivity.
- Assumptions/dependencies: Cultural review process; careful handling of proper names and historical references; model adaptation for other locales if needed.
- Software — Platform integration and developer tooling
- Use case: Integrate T2I/T2V pipelines into apps via Hugging Face diffusers and Kandinsky 5.0 checkpoints; on-prem inference for privacy-sensitive workloads.
- Workflow: Deploy Lite models for low-latency endpoints; use text encoder quantization and VAE acceleration; shard training with F/HSDP for team fine-tuning.
- Tools/products: “Kandinsky SDK” for app developers; CI/CD pipelines with dataset curation modules (watermark detection, deduplication, clustering).
- Assumptions/dependencies: Access to GPU instances; S3-compatible storage for Parquet datasets; monitoring for safety and throughput.
- Academia — Research and teaching
- Use case: Courses and labs on diffusion/flow matching, DiT architectures, sparsity strategies (NABLA), distillation (CFGD, TSCD), and RLHF-like post-training.
- Workflow: Reproduce training stages; run ablations on attention sparsity; evaluate with FVD/VBench/CLIP-score; human side-by-side studies.
- Tools/products: Reusable dataset curation templates; evaluation dashboards; open benchmarks with released prompts (e.g., MovieGen set).
- Assumptions/dependencies: Moderate compute for Lite models; ethical guidelines for dataset building and content generation.
- Policy — Content moderation and compliance operations
- Use case: Deploy watermark detection, text filtering, and quality checks to moderate user-generated visuals; label synthetic outputs; implement runtime safeguards.
- Workflow: Integrate the paper’s filtering stack (watermarks, OCR text, complexity, quality) into a Trust & Safety pipeline; threshold tuning per platform policy.
- Tools/products: “Synthetic Media Gatekeeper” services for upload moderation; audit trails for synthetic content labeling.
- Assumptions/dependencies: Clear platform policies; calibrated thresholds to balance false positives/negatives; transparent user notices.
- Daily life — Personal creativity and communication
- Use case: Photo-to-video transformations; precise image edits (add/remove objects, pose/camera changes); short greeting clips, memes, and social posts.
- Workflow: Mobile or desktop apps using Video Lite for quick clips; Image Lite for high-resolution edits; safe defaults (NSFW filtering, watermarking).
- Tools/products: “Photo-to-Clip” consumer app; lightweight on-device generation via quantized encoders; template-based prompt helpers.
- Assumptions/dependencies: Device performance (prefer GPU/NPU for real-time); usage policies to prevent misuse; content rights awareness.
- Industry/Academia — Synthetic data generation for CV/vision tasks (non-sensitive domains)
- Use case: Generate labeled scenes for retail shelves, manufacturing parts, or general object contexts to augment training datasets.
- Workflow: Use object/scene classifiers to steer prompts; validate with downstream metrics; iterate with domain-specific SFT.
- Tools/products: “Vision Augmentor” pipelines; synthetic set report cards (bias, coverage, realism).
- Assumptions/dependencies: Domain validation against real-world data; avoid medical/forensic/legal domains without expert oversight.
Long-Term Applications
These applications will benefit from further research, scaling, longer-duration generation, domain adaptation, and stronger governance frameworks before broad deployment.
- Industry — Extended-duration, high-fidelity video generation
- Use case: Coherent scenes beyond 10 seconds (minutes), with consistent characters, complex motion, and camera dynamics for professional productions.
- Workflow: Scale temporal modeling; extend NABLA-based sparsity; curriculum training with more long-form, diverse datasets; robust storyboard-to-shot pipelines.
- Tools/products: “Generative Previs Suite” for end-to-end pre-production; shot continuity validators.
- Assumptions/dependencies: Larger compute budgets; long-form, high-quality data; new temporal consistency metrics and guardrails.
- Software/Robotics — Simulation and “world models” for training agents
- Use case: Physics-aware, controllable video environments for robotics, autonomy, and interactive agents; scenario generation for edge cases.
- Workflow: Integrate controllable dynamics and constraints; multimodal conditioning (text, sensor data); feedback loops with RL and human preference scoring.
- Tools/products: “Sim-Gen Engine” for policy training; scenario libraries with domain tags.
- Assumptions/dependencies: Accurate physical modeling; safety testing; sector-specific validation (e.g., automotive).
- Healthcare — Domain-specific synthetic imagery and educational content
- Use case: Augmented datasets for medical imaging research; patient education animations.
- Workflow: Fine-tune on licensed, expert-curated medical data; strict evaluation by clinicians; watermarking and disclosure.
- Tools/products: “Med-Gen Lab” for controlled research; CME educational modules with generated visuals.
- Assumptions/dependencies: Regulatory compliance (HIPAA/GDPR); expert oversight; bias and error risk management; not for diagnosis without rigorous validation.
- Finance/Enterprise — Document-style visual synthesis and compliance testing
- Use case: Synthetic visual assets for internal training and compliance (e.g., illustrative documents, UI mockups, KYC scenarios).
- Workflow: Domain-specific fine-tuning with controlled templates; red-team evaluations for failure modes; governance dashboards.
- Tools/products: “Compliance Content Sandbox”; synthetic scenario libraries for training staff and systems.
- Assumptions/dependencies: Strong safeguards against misuse (e.g., deepfake IDs); clear labeling and auditability.
- Education — Interactive, multimodal learning environments
- Use case: Generative labs, explorable historical scenes, and science simulations combining text-to-video with guided tasks and assessments.
- Workflow: Curriculum-linked prompts; teacher dashboards for oversight; adaptive content generation based on student progression.
- Tools/products: “GenClassroom” platforms; content provenance tracking.
- Assumptions/dependencies: Age-appropriate safeguards; factual accuracy layers; alignment with educational standards.
- Culture and heritage — Digital preservation and experiential media
- Use case: Recreating or illustrating cultural narratives, architecture, costumes, and rituals for museums and cultural institutions.
- Workflow: Domain-curated datasets (like RCC) per locale; expert reviews; multilingual captions and annotations.
- Tools/products: “Cultural Experience Generator”; guided tours with generated visual reconstructions.
- Assumptions/dependencies: Ethical frameworks; community collaboration; careful handling of sensitive topics and identities.
- Software/Infrastructure — Standardized dataset curation platforms
- Use case: Turning the paper’s filtering and clustering pipeline (watermarks, text detection, quality scores, dedup) into reusable, auditable tooling.
- Workflow: Modular microservices with metadata stores, S3-backed Parquet, vector indexes; domain-aware sampling and “SFT-soup” composition utilities.
- Tools/products: “Data Curation OS”; reproducible pipeline templates for MLOps.
- Assumptions/dependencies: Organizational data governance; compute/storage budgets; compliance for data sources.
- Safety and policy — Synthetic media provenance, labeling, and detection standards
- Use case: Frameworks for watermarking synthetic outputs, detecting manipulated content, and informing users; risk assessment and incident response.
- Workflow: Integrate provenance signals into platforms; continuous calibration against new generative models; public transparency reports.
- Tools/products: “Synthetic Media Registry”; standardized watermarking APIs; platform policies codified in automated checks.
- Assumptions/dependencies: Multi-stakeholder standards; legal harmonization across regions; evolving adversarial detection methods.
- Edge/on-device generation — Low-power, privacy-preserving creativity
- Use case: Real-time image/video generation on mobile and edge devices, preserving user privacy and lowering latency.
- Workflow: Aggressive quantization, pruning, and distillation (beyond current NFE reduction); efficient attention mechanisms like NABLA adapted for edge.
- Tools/products: “Pocket Kandinsky” apps; NPUs/GPU-accelerated runtimes.
- Assumptions/dependencies: Hardware acceleration; energy constraints; safety controls and local content moderation.
- Multi-agent, human-in-the-loop content pipelines
- Use case: End-to-end pipelines that combine generative stages (T2I/T2V), automated quality checks, human preference modeling, and final approval.
- Workflow: RLHF-like post-training enhanced with domain-specific SFT; agent orchestration for prompt refining and compliance checks.
- Tools/products: “Creative Ops Orchestrator”; preference learning dashboards.
- Assumptions/dependencies: Organizational buy-in; measurable quality KPIs; robust audit trails.
Cross-cutting assumptions and dependencies
- Compute and infrastructure: Pro (19B) models require significant GPU memory; Lite models enable faster, lower-cost deployments. NABLA attention offers approximately 2.7× speedups with high sparsity, which is beneficial but still compute-dependent.
- Dataset licensing and ethics: Compliance with data source licenses; explicit policies for synthetic media labeling and user notification.
- Safety and guardrails: Runtime safeguards, watermarking, bias audits, and cultural sensitivity reviews are essential, especially for public and regulated use cases.
- Quality and reliability: Visual quality and prompt alignment improve with SFT and adversarial post-training but still require human oversight for high-stakes contexts.
- Scope limits: Current 10-second video generation imposes duration constraints; extended coherence requires further research and scaling.
Glossary
- Activation checkpointing: A memory-saving training technique that recomputes a subset of activations during backpropagation to reduce GPU memory usage. "activation checkpointing, among others."
- Adversarial Diffusion Distillation: A distillation method that trains a faster diffusion-style generator using adversarial objectives while preserving quality. "reduced the number of generation steps from 50 to 4 using the Adversarial Diffusion Distillation approach"
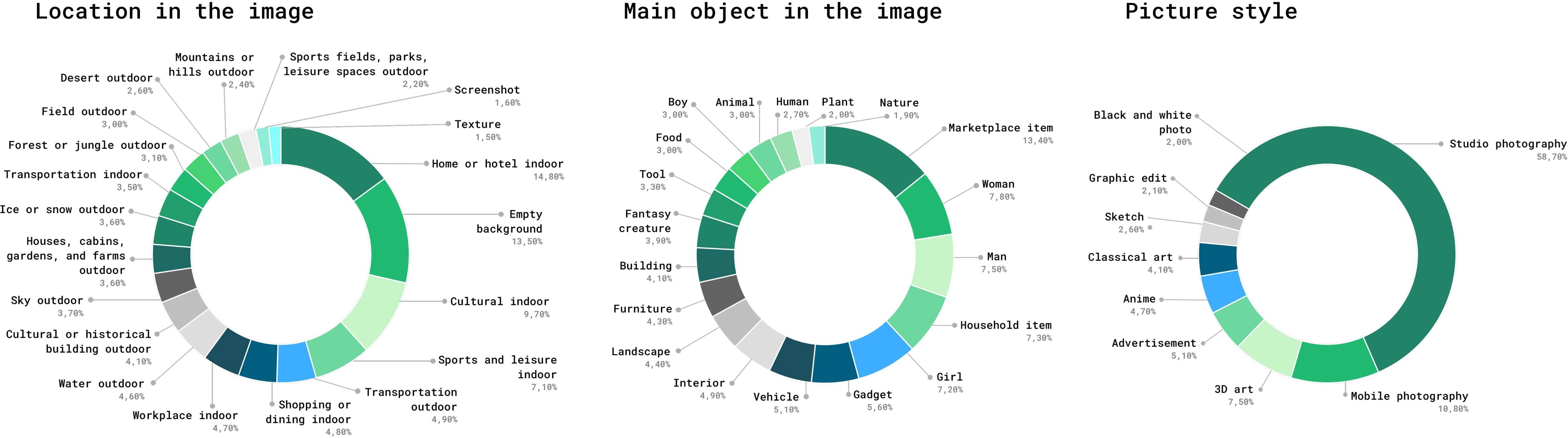
- CLIP: Contrastive Language–Image Pretraining; a model that learns joint text–image representations used for classification and alignment. "A CLIP-based classifier categorizes the image's location, style, main subject, and detailed place type based on CLIP embeddings."
- CLIP-score: A metric that measures semantic alignment between generated images and their input text using CLIP embeddings. "as confirmed by FVD, VBench, CLIP-score and human evaluation through side-by-side testing."
- Classifier-Free Guidance Distillation: A technique that distills classifier-free guidance into a student model to retain conditioning strength with fewer sampling steps. "we employ a combined approach that integrates Classifier-Free Guidance Distillation, Trajectory Segmented Consistency Distillation (TSCD), and subsequent adversarial post-training"
- ControlNet: A mechanism that conditions generation on auxiliary inputs (e.g., edges, poses) to enable localized editing or control. "the introduction of a ControlNet mechanism for local editing"
- Cross-Attention Diffusion Transformer (CrossDiT): The paper’s core diffusion transformer that incorporates cross-attention for conditioning on text and other inputs. "The core components include a Cross-Attention Diffusion Transformer (CrossDiT), a corresponding CrossDiT-block scheme, and the Neighborhood Adaptive Block-Level Attention (NABLA) mechanism"
- CrossDiT-block: A modular block within the CrossDiT architecture that structures attention, normalization, and feed-forward operations. "a corresponding CrossDiT-block scheme"
- Diffusers library: A popular open-source library for diffusion and transformer-based generative models, providing pipelines and pretrained weights. "and provide access through the diffusers library."
- Diffusion models: Generative models that learn to reverse a noise-adding process to synthesize data (e.g., images, video). "diffusion models and the subsequent flow matching approaches have led to a qualitative breakthrough in image generation"
- Diffusion Transformer (DiT): A transformer-based diffusion architecture designed for scalable, efficient image and video generation. "architectures like the Diffusion Transformer (DiT), which provided the necessary scalability and efficiency"
- Euclidean transformation: A geometric transformation (rotation, translation) used to align image pairs without changing scale or shape. "Applied RANSAC algorithm to estimate fundamental matrix and Euclidean transformation"
- F/HSDP (Fully or Hybrid Sharded Data Parallel): Distributed training strategies that shard model states or gradients across devices to scale and reduce memory. "Fully or Hybrid Sharded Data Parallel (F/HSDP)"
- FID: Fréchet Inception Distance; a metric for evaluating image generation quality by comparing feature distributions of real and generated images. "on the FID metric on the COCO 30k dataset"
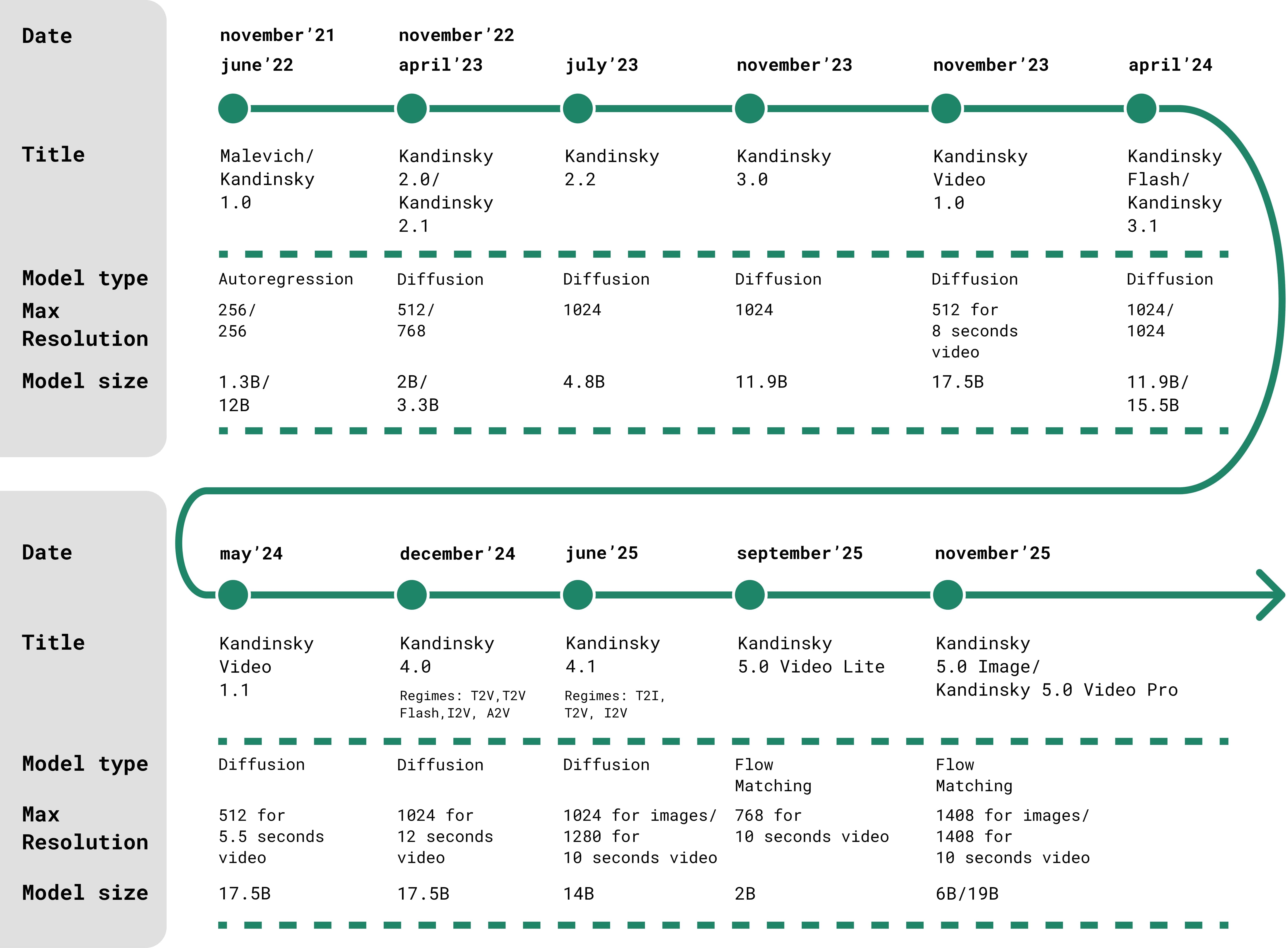
- Flow Matching: A training framework that learns transport maps between noise and data distributions, offering efficient, stable generative modeling. "This is the first Kandinsky models based on the Flow Matching"
- FVD: Fréchet Video Distance; a metric for video generation quality, extending FID to temporal data. "as confirmed by FVD, VBench, CLIP-score and human evaluation through side-by-side testing."
- Fundamental matrix: A matrix relating corresponding points in two images for epipolar geometry, estimated in pair verification. "Applied RANSAC algorithm to estimate fundamental matrix and Euclidean transformation"
- Inpainting: Filling in or regenerating missing or masked regions of an image guided by a model’s learned priors. "natively supports inpainting, outpainting, image blending, synthesis of variations of an input image, and text-guided image editing."
- LoFTR: A detector-free local feature matching method for robust correspondence between images. "Used LoFTR to find matching points between images"
- Model Soup: Averaging weights from multiple fine-tuned models to improve generalization without extra training. "SFT-soup models by weights averaging"
- MoVQ image autoencoder: A vector-quantized autoencoder variant that modulates quantized vectors for efficient image representation. "a MoVQ image autoencoder"
- MS-SSIM: Multi-Scale Structural Similarity; a perceptual metric that evaluates similarity across scales, used to gauge scene dynamics. "Multi-Scale Structural Similarity (MS-SSIM) index"
- NABLA (Neighborhood Adaptive Block-Level Attention): A sparsified attention mechanism that reduces quadratic spatio-temporal attention cost while preserving quality. "Neighborhood Adaptive Block-Level Attention (NABLA) mechanism"
- Number of Function Evaluations (NFE): The count of solver steps or evaluations needed during sampling/inference for generative models. "This reduces the Number of Function Evaluations (NFE) from 100 to 16 while preserving visual quality"
- Outpainting: Extending an image beyond its original boundaries in a visually coherent manner. "natively supports inpainting, outpainting, image blending, synthesis of variations of an input image, and text-guided image editing."
- Parquet files: Columnar storage files optimized for efficient analytics and large-scale data pipelines. "stored in Parquet files."
- Perceptual hash: A hash function that maps visual content to similar fingerprints, enabling near-duplicate detection. "an image perceptual hash is calculated for each image."
- PySceneDetect: A tool for automatic shot detection and video scene segmentation. "using the PySceneDetect tool, which detects shot changes."
- Q-Align: A multimodal quality assessment model that scores technical and aesthetic aspects of visual data. "The Q-Align model offers an alternative assessment of technical and aesthetic aspects."
- Quantization (text encoder quantization): Compressing model weights/activations to lower precision to reduce memory and speed up inference. "text encoder quantization"
- RANSAC: Random Sample Consensus; a robust estimation algorithm used to fit models (e.g., fundamental matrix) despite outliers. "Applied RANSAC algorithm to estimate fundamental matrix and Euclidean transformation"
- RLHF: Reinforcement Learning from Human Feedback; using human preference signals to fine-tune model behavior. "We also introduce our RLHF post-training adversarial method based on comparing generated images with those from the SFT dataset."
- SAM 2: A segmentation model used to generate masks for complexity filtering. "the SAM 2 model generates segmentation masks"
- Self-Supervised Fine-Tuning (SFT): Fine-tuning using automatically generated targets or consistency objectives without explicit human labels. "self-supervised fine-tuning (SFT)"
- Side-by-side (SBS) evaluation: Human comparative assessment where outputs are directly compared in pairs. "human side-by-side (SBS) evaluations"
- Sobel filter: An edge-detection operator used to quantify visual complexity via gradient magnitude. "complemented by a Sobel filter for detailed edge analysis."
- Spatio-temporal attention: Attention mechanism over both spatial and temporal dimensions for video modeling. "overcomes the quadratic complexity of standard spatio-temporal attention"
- Supervised Fine-Tuning (SFT): Fine-tuning on curated, labeled high-quality examples to align outputs with human preferences. "A high-quality Supervised Fine-Tuning (SFT) dataset was meticulously curated"
- TSCD (Trajectory Segmented Consistency Distillation): A distillation method that enforces consistency across segmented sampling trajectories to accelerate generation. "Trajectory Segmented Consistency Distillation (TSCD)"
- VAE (Variational Autoencoder): A probabilistic autoencoder that learns latent representations via variational inference, used for encoder/decoder optimization. "variational autoencoder (VAE) optimization"
- VBench: A benchmark suite for evaluating video generation models across multiple axes of quality and consistency. "VBench benchmarks"
- VideoMAE: A masked autoencoding framework for video pretraining, used here to predict motion and dynamic scores. "based on VideoMAE architecture was trained to predict scores for camera movement"
- VLM (Video LLM): A multimodal model that understands and classifies video content using language supervision. "using a video LLM (VLM)"
- YOLOv8: A modern object detection model used to detect and classify objects in images and video frames. "The YOLOv8 model, trained on OpenImagesV7, detects and classifies objects present in the image."
Collections
Sign up for free to add this paper to one or more collections.