- The paper introduces Q-Doc, a multi-level benchmark that systematically evaluates DIQA capabilities in MLLMs by decomposing tasks into coarse, middle, and fine levels.
- It leverages real-world document images with varied distortions and applies Chain-of-Thought prompting to enhance both global quality scoring and localized distortion detection.
- Experiments reveal fragmented model performance across quality metrics, underscoring the need for unified, reasoning-aware pretraining for robust document understanding.
Q-Doc: Advancing Document Image Quality Assessment with a Multi-Level Benchmark for Multi-modal LLMs
Introduction
The proliferation of Multi-modal LLMs (MLLMs) has enabled compelling progress in vision-language tasks, but their effectiveness in low-level vision, specifically Document Image Quality Assessment (DIQA), remains insufficiently studied. The paper "Q-Doc: Benchmarking Document Image Quality Assessment Capabilities in Multi-modal LLMs" (2511.11410) introduces Q-Doc, a multi-tiered benchmarking protocol designed to systematically probe DIQA abilities of MLLMs at coarse, middle, and fine granularity. It leverages real-world mobile-captured document images with diverse visual distortions, aiming to illuminate the limitations and strengths of modern MLLMs in perceptual and text-centric scenarios fundamental for OCR and document understanding pipelines.

Figure 1: Q-Doc evaluates MLLMs across three hierarchical tasks: coarse-level quality scoring, middle-level distortion classification, and fine-level severity estimation, utilizing real-world distorted document images.
Benchmark Design and Methodology
Three-Level Hierarchical Evaluation
Q-Doc decomposes DIQA evaluation into three explicit subtasks:
- Coarse-Level Quality Scoring: Models assign global quality scores to document images, with predictions mapped to a five-point scale and correlation assessed via SRCC and PLCC against human annotations.
- Middle-Level Distortion Classification: Models must identify present distortion types from candidates including insufficient brightness, motion blur, and defocus, both in single-distortion (single-label) and multi-distortion (multi-label) scenarios. Strict exact-match criteria and inverse-frequency balanced accuracy mitigate class imbalance.
- Fine-Level Distortion Severity Estimation: Each distortion type is assessed for severity (good/middle/poor) using stratified prompts and disaggregated evaluation per distortion.
Chain-of-Thought (CoT) prompting is systematically applied to all subtasks to foster stepwise reasoning about document clarity, textual readability, and visual artifacts, consistently improving performance and interpretability.

Figure 2: Chain-of-Thought prompting enhances model reasoning by connecting text legibility with document quality before outputting a judgment.
Dataset Construction
The benchmark utilizes 4,260 document images spanning modern forms, historical letters, and receipts, sourced from SmartDoc-QA. This corpus comprises both single and compound distortions representative of real-world mobile capture, with fine-grained annotations for distortion type and severity.
Experimental Results
Six representative MLLMs were evaluated under zero-shot settings: Co-Instruct, Llama-3.2-11B-Vision-Instruct, mPLUG-Owl3-7B-241101, GLM-4V-9B, DeepSeek-VL2, and GPT-4o-241120. Results span coarse-level correlation, middle-level classification, and fine-level severity estimation.
Coarse-Level: Quality Scoring
DeepSeek-VL2 and mPLUG-Owl3 demonstrated strong correlation (SRCC, PLCC) with annotation, while GPT-4o underperformed despite its commercial provenance. Application of CoT to DeepSeek-VL2 resulted in the highest correlation scores, underscoring the utility of guided reasoning for global quality assessment.
Middle-Level: Distortion Recognition
Balanced accuracy was markedly higher for single-distortion compared to multi-distortion classification, with GPT-4o achieving top scores. DeepSeek-VL2 with CoT delivered robust, consistent performance across both tasks. The strict matching metric for multi-label classification amplified the challenge, revealing substantial deficiencies in precise distortion recognition among most models.
Fine-Level: Severity Estimation
Accuracy for severity assessment was variable, with GPT-4o excelling on single-distortion and DeepSeek-VL2 outperforming on multi-distortion images. Notably, DeepSeek-VL2 and its CoT-enhanced variant showed higher accuracy on multi-distortion samples, reflecting the benchmark’s design to ensure uniform gradability and annotation consistency in this setting.
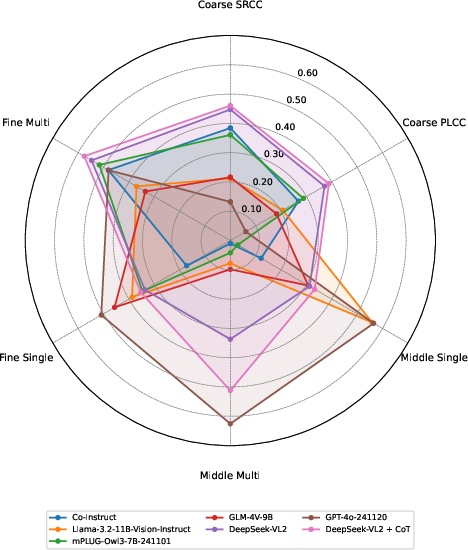
Figure 3: Radar chart visualizing MLLM performance across six metrics encompassing coarse, middle, and fine-level evaluation accuracy.
Model Capability Insights
Analysis reveals fragmented strengths: no model achieves consistently high performance across all evaluation levels. Llama-3.2-11B-Vision-Instruct excels at middle-level classification but lags on coarse and fine metrics; mPLUG-Owl3 inversely demonstrates the opposite trend. DeepSeek-VL2 exhibits uniquely balanced capability, likely attributable to its Mixture-of-Experts architecture facilitating both global and local reasoning. Model architecture and training regime strongly influence quality perception profiles, with CoT prompting universally beneficial for multi-step, fine-grained assessment.
Implications and Future Directions
Q-Doc sets forth a rigorous diagnostic regime for evaluating DIQA in MLLMs, revealing persistent gaps in distortion identification, severity quantification, and overall quality consistency. The observed advantages of CoT prompting suggest future MLLM architectures should integrate reasoning-aware mechanisms natively. The highlighted architectural biases and fragmented perception underscore the necessity for more unified, quality-centric model pretraining, particularly in document-oriented and low-level vision domains. Practically, robust DIQA in MLLMs remains essential for advancing OCR, information retrieval, and end-to-end document understanding in mobile and real-world contexts.
Anticipated developments entail:
- Architectural innovations to harmonize cross-level perception (granular to global).
- Augmented training with explicit quality-centric and document-centric pretext tasks.
- Enhanced multimodal reasoning leveraging CoT or similar protocols for layered perception.
Conclusion
Q-Doc introduces a systematic, multi-level benchmark for DIQA evaluation in MLLMs, comprising granular subtask decomposition and real-world distortion scenarios. Empirical results indicate prominent limitations and fragmented capabilities in existing models, while Chain-of-Thought prompting demonstrably enhances diagnostic reliability. This benchmark offers a foundation for both theoretical analysis and practical advancement towards more quality-aware, document-specialized multimodal AI systems.