A Bayesian Perspective on Evidence for Evolving Dark Energy
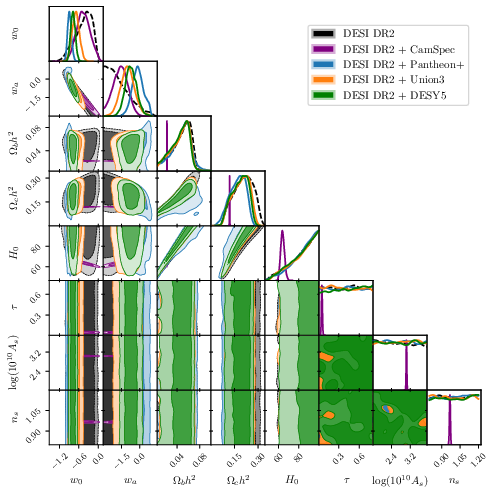
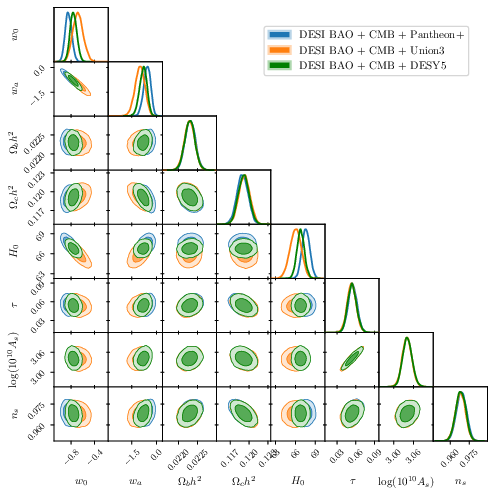
Abstract: The DESI collaboration reports a significant preference for a dynamic dark energy model ($w_0w_a$CDM) over the cosmological constant ($Λ$CDM) when their data are combined with other frontier cosmological probes. We present a direct Bayesian model comparison using nested sampling to compute the Bayesian evidence, revealing a contrasting conclusion: for the key combination of the DESI DR2 BAO and the Planck CMB data, we find the Bayesian evidence modestly favours $Λ$CDM (log-Bayes factor $\ln B = -0.57{\scriptstyle\pm0.26}$), in contrast to the collaboration's 3.1$σ$ frequentist significance in favoring $w_0w_a$CDM. Extending this analysis to also combine with the DES-Y5 supernova catalogue, our Bayesian analysis reaches a significance of $3.07{\scriptstyle\pm0.10}\,σ$ in favour of $w_0w_a$CDM. By performing a comprehensive tension analysis, employing five complementary metrics, we pinpoint the origin: a significant ($\approx 2.95σ$), low-dimensional tension between DESI DR2 and DES-Y5 that is present only within the $Λ$CDM framework. The $w_0w_a$CDM model is preferred precisely because its additional parameters act to resolve this specific dataset conflict. The convergence of our findings with independent geometric analyses suggests that the preference for dynamic dark energy is primarily driven by the resolution of inter-dataset tensions, warranting a cautious interpretation of its statistical significance.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “A Bayesian Perspective on Evidence for Evolving Dark Energy”
1. What is this paper about?
This paper asks: Does dark energy change over time, or is it a constant? Dark energy is a mysterious “push” making the universe expand faster. The standard model of the universe, called ΛCDM (lambda-CDM), treats dark energy as a constant. A newer idea, often written as w0waCDM, lets dark energy change with time using two extra “knobs” (parameters) called w0 and wa.
A recent big survey (DESI) suggested there’s strong evidence that dark energy might be changing. This paper double‑checks that claim using a different statistical approach and finds a more cautious answer.
2. What questions are they asking?
The authors focus on three plain‑English questions:
- When we combine today’s best space data sets, which model does the data prefer: constant dark energy (ΛCDM) or changing dark energy (w0waCDM)?
- Do different ways of judging evidence (two “referees” called frequentist and Bayesian) agree?
- If some data prefer changing dark energy, is that because the universe truly behaves that way, or because certain data sets don’t quite agree with each other and the extra “knobs” in the changing model smooth over that disagreement?
3. How did they study it?
They compared models using several types of sky measurements:
- BAO (Baryon Acoustic Oscillations) from DESI: Think of ancient ripples in the distribution of galaxies—like “sound waves” frozen in space—that act as a giant ruler for distances.
- CMB (Cosmic Microwave Background) from Planck: The universe’s baby picture, a faint glow left from shortly after the Big Bang.
- Type Ia supernovae from several catalogs (Pantheon+, Union3, DES‑Y5): Exploding stars used as “standard candles” to measure how fast the universe expands.
They used a Bayesian method to compare models:
- Frequentist vs. Bayesian: Two fair ways to judge evidence. A frequentist test asks, “How surprising are the data if this model is true?” A Bayesian test asks, “How much would you bet on each model, given both the data and how flexible the model is?”
- Occam’s razor (Bayesian version): If two models fit the data similarly well, prefer the simpler one with fewer knobs. The “changing dark energy” model has more knobs, so it must earn its complexity.
- “Bayesian evidence” and “Bayes factor”: Think of these like betting odds. If the odds favor one model, it’s preferred. They compute these odds with a technique called nested sampling, which is like carefully searching a landscape of possibilities to find where the data fit best, while counting how much model flexibility you needed to get there.
They also did a “tension analysis”:
- Tension means two data sets pull the answer in different directions—like two witnesses telling slightly different stories. If adding extra knobs fixes the disagreement, the model might look “better,” but it could be solving the disagreement rather than revealing new physics.
4. What did they find, and why does it matter?
Key results, in simple terms:
- DESI BAO + CMB: Using the Bayesian approach, the simpler constant‑dark‑energy model (ΛCDM) is slightly preferred. This disagrees with the frequentist result, which reported a roughly “3 sigma” preference for changing dark energy. (“Sigma” is a way to measure surprise; 3 sigma is notable but not a discovery.)
- Adding supernova data depends on which catalog you use:
- With Pantheon+, the Bayesian test favors ΛCDM (constant dark energy).
- With DES‑Y5, the Bayesian test prefers changing dark energy, and the preference gets strong when combined with DESI + CMB.
- Why the difference? The authors show that DESI and DES‑Y5 don’t fully agree with each other if you assume ΛCDM. The extra knobs in the changing‑dark‑energy model help “soak up” that disagreement, making it look better. In other words, the model wins because it patches a mismatch between those two data sets, not because every data set independently shouts “dark energy is changing!”
Why this matters:
- If the preference for changing dark energy mainly comes from a disagreement between data sets, we should be careful before calling it evidence of new physics.
- The Bayesian method’s built‑in simplicity penalty is doing its job: it only rewards the more complicated model when it truly earns it.
5. What’s the big picture?
This paper urges caution. Claims that dark energy is changing may be influenced by how certain data sets (especially DESI BAO and the DES‑Y5 supernovae) fit together under the standard model. The more flexible model can hide that mismatch, which can look like a “signal” for evolving dark energy.
Implications:
- We should double‑check supernova catalogs and how different data are combined.
- Different statistical “referees” can disagree, so it’s wise to look at both and understand why.
- Before announcing new physics, make sure the evidence isn’t mostly driven by data tension. Future surveys and careful cross‑checks will be key to settling this question.
Knowledge Gaps
The paper leaves several concrete gaps and unresolved questions that future work can address:
- Quantify the robustness of the reported Bayes factors to prior choices, including systematic sweeps over the , priors (ranges, shapes, reparameterizations), the boundary, and the neutrino mass lower bound (0 vs 0.06 eV), and report how these choices change for each dataset combination.
- Localize the low-dimensional DESI–DES-Y5 tension to specific parameters and observables by identifying which combinations (e.g., at particular redshifts, , , , , or directions) drive the conflict, and which redshift bins in DES-Y5 and DESI contribute most strongly.
- Perform targeted systematics tests on DES-Y5 that could generate the observed tension: reprocess with alternative light-curve fitters and calibration pipelines, vary selection cuts, host-mass step treatments, color law and dust models, Malmquist corrections, and redshift-dependent standardization, and propagate these variants into the Bayesian evidence and tension metrics.
- Assess cross-covariances and shared systematics between probes (Planck CMB, DESI BAO, and SNe) rather than assuming independence in likelihood products; construct and use joint covariance models or nuisance-parameter linking to see how correlated systematics affect Bayes factors and tension diagnostics.
- Replace or augment the compressed 13-component DESI BAO data vector with the full-shape likelihood and alternative summary statistics to test whether compression-induced information loss or approximations bias the evidence and tension conclusions.
- Validate nested sampling evidence estimates across samplers and settings by cross-checking with MultiNest, Dynesty, UltraNest, and dynamic nested sampling, and by varying PolyChord hyperparameters (live points, slice sampling settings, stopping criteria) to ensure numerical stability of and tension metrics.
- Calibrate the frequentist test statistics used by DESI via Monte Carlo pseudo-experiments tailored to the actual likelihoods and parameter boundaries (including non-Gaussianities and constrained parameter spaces), and compare simulation-based p-values against asymptotic formulae to quantify any breakdowns.
- Provide a simulation-based mapping between Bayes factors and “sigma” levels (beyond the Sellke bound) for the specific cosmological likelihoods considered, or standardize reporting in terms of odds/Bayes factors without sigma conversion to avoid miscalibration.
- Explore alternative model extensions that could also alleviate the DESI–DES-Y5 tension and compare their Bayesian evidences: CDM (constant ), curvature (), varying , early dark energy, free , interacting dark energy, modified gravity, or flexible models beyond CPL, and determine which specific physical extensions best resolve the conflict.
- Test sensitivity to the choice of CMB likelihood and data subsets by repeating the analysis with Planck Plik/Commander, including/excluding CMB lensing, and adding ACT/SPT constraints, and quantify the impact on Bayes factors and tension metrics.
- Harmonize supernova catalogs (Pantheon+, Union3, DES-Y5) under a common calibration and standardization framework to isolate catalog-driven differences, and perform leave-one-subsample-out analyses within DES-Y5 to identify internal contributors to tension.
- Investigate whether the wavenumber-dependent modeling and reconstruction systematics in DESI BAO (e.g., non-linear corrections, bias modeling, reconstruction choices) could produce shifts that mimic CDM preferences when combined with DES-Y5.
- Decompose the reported “low-dimensional” tension using the Bayesian dimensionality metric into interpretable physical directions (e.g., sound horizon scale, absolute SN magnitude, late-time expansion rate), and verify the dimension count and its stability across prior choices and samplers.
- Quantify the Occam penalty versus fit improvement by reporting Kullback–Leibler divergences and information gains for each dataset combination, clarifying whether CDM’s preference with DES-Y5 is dominated by tension diffusion or genuine likelihood improvement.
- Provide posterior predictive checks and residual diagnostics for each dataset under both CDM and CDM to assess model adequacy beyond parameter-level tension metrics.
- Justify and calibrate the “look-elsewhere” threshold (2.88σ) used to flag significant tensions within the unimpeded framework, and test the sensitivity of tension classifications to this choice on synthetic datasets.
- Report the impact of including DESI RSD (growth-rate, ) alongside BAO distances on the Bayesian model comparison, as growth information can break degeneracies relevant to .
- Examine the role of absolute distance calibration in SNe (e.g., Cepheid/TRGB anchors and priors) on the combined evidence with CMB+BAO, explicitly testing how different priors or anchors move the DESI–DES-Y5 tension.
- Evaluate whether the preferred values inferred with DES-Y5 correspond to theoretically viable dark energy models (e.g., thawing/freezing quintessence, avoidance of extreme phantom regimes), and incorporate physics-informed priors to test robustness.
- Replicate the frequentist analysis with the authors’ own pipeline to isolate the origin of the DESI collaboration’s higher significances (e.g., test statistic definition, nuisance profiling, boundary effects), enabling a like-for-like comparison with the Bayesian workflow.
Practical Applications
Immediate Applications
The following bullet points summarize practical, deployable applications that leverage this paper’s findings, methods, and tools, organized by sector where relevant. Each item includes key assumptions or dependencies.
- Cosmology research workflows (academia; software)
- Adopt a dual-framework reporting standard for model comparison results that includes both Bayesian evidence (log-Bayes factor, betting odds) and frequentist significances, especially for claims of “new physics.”
- Integrate nested sampling (PolyChord via Cobaya) and tension diagnostics from the unimpeded framework into standard cosmology pipelines to routinely quantify dataset compatibility (evidence ratio R, suspiciousness S, dimensionality d_G).
- Replace asymptotic significance translations with Monte Carlo pseudo-experiments when data vectors are small or approximations may fail, as highlighted for the DESI DR2 compressed BAO vector.
- Dependencies: Access to DESI/Planck/SN likelihoods; computational resources for nested sampling; community buy-in for dual reporting; careful prior specification (e.g., neutrino mass bounds affect evidence).
- Data-integration QA for multi-probe cosmology (academia; software)
- Build a “tension dashboard” for probe combinations (BAO+CMB+SN) that flags low-dimensional conflicts like the DESI DR2–DES-Y5 tension under ΛCDM and monitors how extended models diffuse tensions.
- Use dashboard outputs to decide which catalogues to include (e.g., prefer Pantheon+/Union3 when tensions persist) and to trigger systematic audits of specific data products (e.g., SN standardization and calibration).
- Dependencies: Availability of the unimpeded software/database; access to probe likelihoods; domain expertise to interpret tension diagnostics; governance to act on flagged tensions.
- Reinterpretation and communication of evolving dark energy claims (academia; policy)
- Update public statements and internal memos to reflect that DESI+Planck evidence modestly favors ΛCDM under Bayesian analysis, and that preferences for CDM are driven by specific inter-dataset tensions (primarily DES-Y5).
- Adopt “betting odds” language for Bayes factors and avoid over-reliance on single-catalogue-driven significances.
- Dependencies: Institutional acceptance of Bayesian communication standards; training in evidence-based phrasing; coordination with collaborations and journals.
- Peer review and journal policy enhancements (policy; academia)
- Encourage or require submissions to report Bayes factors alongside frequentist significances, include sensitivity analyses to priors, and validate asymptotic approximations with pseudo-experiments where feasible.
- Dependencies: Editorial policy changes; reviewer expertise; computational budget for validation runs.
- Ready-to-use software assets (software; academia)
- Immediate adoption of unimpeded public nested-sampling databases and scripts for model comparison and tension analysis; use anesthetic for posterior visualization and Cobaya for likelihood orchestration.
- Share reproducible analysis artifacts (chains, priors, configuration files) to standardize cross-group comparisons.
- Dependencies: Familiarity with Python ecosystems; containerization for portability; storage for chain databases.
- Cross-domain data-fusion QA pilots (healthcare, finance, robotics, energy; software)
- Apply tension metrics (e.g., suspiciousness, evidence ratio) to integrated datasets in other sectors to detect when added model flexibility merely absorbs inter-source conflicts rather than improving truthfulness.
- Healthcare: Combine EHR, trial outcomes, and registries; flag low-dimensional tensions that point to calibration or cohort biases.
- Finance: Fuse macro indicators and alternative data; identify conflicts where complex models improve fit by masking incompatible signals.
- Robotics and autonomous systems: Sensor fusion pipelines that distinguish true multimodal synergy from conflicts that extra parameters “paper over.”
- Energy forecasting: Integrate grid, weather, and market signals; detect source-level inconsistencies before ensemble modeling.
- Dependencies: Domain-specific likelihood modeling; access to high-quality data; translation of cosmology metrics to sector-specific inference; stakeholder training.
- A/B testing and product analytics (software; industry)
- Use Bayesian evidence and odds rather than only p-values to compare feature variants; report tension-like diagnostics when multiple user segments or data sources disagree at low dimension.
- Dependencies: Instrumentation to collect segment-level data; Bayesian tooling (PyMC/Stan bridging, or nested sampling when evidence is needed); cultural shift to odds-based decision-making.
Long-Term Applications
The following items require further research, development, scaling, or institutional changes before broad deployment.
- Standardized, cross-disciplinary framework for dataset tension diagnostics (software; academia; policy)
- Generalize the unimpeded evidence framework beyond cosmology into a domain-agnostic library (“TensionLab”) with APIs for PyMC/Stan, standardized metrics (R, S, d_G), and reporting templates.
- Dependencies: Methodological extensions to diverse likelihoods; benchmarking datasets; sustained maintainership and funding.
- Cloud/HPC evidence-as-a-service (software; industry; academia)
- Build managed services that run nested sampling at scale for evidence and tension analysis, with reproducibility primitives (versioned priors, chains, and configurations) and dashboards.
- Dependencies: HPC/cloud integration; cost control; secure handling of proprietary datasets; optimization of nested sampling for large parameter spaces.
- Survey and experiment design optimized for tension resolution (academia; policy)
- Use low-dimensional tension diagnostics to target calibration, selection functions, and instrument design that specifically reduce conflicts (e.g., SN photometric calibration improvements that mitigate DESI–SN tensions).
- Pre-register analysis frameworks that include both Bayesian evidence and tension metrics to prevent model extensions that simply absorb specific conflicts.
- Dependencies: Collaboration-wide planning; calibration infrastructure; incentives for pre-registration and open analysis.
- Formalized dual-framework standards for “extraordinary evidence” claims (policy; academia)
- Establish guidelines requiring concurrent Bayesian evidence thresholds (e.g., minimum odds) and frequentist significance, plus validated asymptotics, before making claims of new physics or major effects.
- Dependencies: Consensus on thresholds; community enforcement; education and training.
- Tension-aware machine learning and meta-analysis (software; healthcare; finance)
- Develop ML algorithms and meta-analytic workflows that incorporate evidence and tension metrics to avoid overfitting to conflicting sources and to prioritize data cleaning or reweighting.
- Dependencies: Algorithmic research; integration into existing MLOps stacks; high-quality labels and provenance metadata.
- Education and training programs (academia; policy)
- Build curricula and workshops that teach evidence-based model comparison, tension diagnostics, and the pitfalls of asymptotic significance in small or compressed datasets, using this paper as a case study.
- Dependencies: Course development resources; faculty training; uptake in graduate programs and professional development.
- Regulatory and risk governance adaptation (policy; finance; healthcare)
- Incorporate tension diagnostics into regulatory guidance for meta-analyses, risk models, and safety-critical decision systems to ensure extended models aren’t preferred solely because they resolve specific dataset conflicts.
- Dependencies: Regulator engagement; pilots demonstrating benefit; legal and compliance alignment.
Each long-term application presumes continued tool maturation, broader community adoption, and robust domain-specific validation. In all cases, the feasibility depends on transparent priors, accessible data, reproducible chains, sufficient compute, and governance structures willing to act when tensions—not true signals—drive model preferences.
Glossary
- asymptotic formulae: Large-sample approximations used to translate test statistics into significances. "it is reasonable to question not the frequentist framework per se, but the applicability of asymptotic formulae in this instance."
- BAO: Baryon Acoustic Oscillations; a standard ruler from early-Universe sound waves used to constrain cosmology. "We analyse DESI DR2 BAO data~\cite{desi2025,BAOData}"
- Bayes factor: The ratio of Bayesian evidences for two models, quantifying how the data compare them. "Following Trotta~\cite{2008ConPh..49...71T}, we convert Bayes factors to Gaussian significance via (i) Bayes factor to -value"
- Bayesian dimensionality metric: A measure of the effective dimensionality of the parameter subspace that is constrained by the data. "which the Bayesian dimensionality metric diagnoses as a highly localised, low-dimensional conflict ()."
- Bayesian evidence: The marginal likelihood of the data under a model, integrating the likelihood over the prior. "We compute Bayesian evidence "
- Bayesian model comparison: Evaluating and ranking models by their Bayesian evidences or Bayes factors. "we present a direct Bayesian model comparison"
- Bayesian Occam's razor: The automatic penalization of overly complex models via prior-volume integration in the evidence. "(Bayesian Occam's razor)"
- CAMB: A cosmology code that computes theoretical predictions like CMB anisotropies for parameter inference. "and CAMB~\cite{Lewis:1999bs}"
- CamSpec likelihood: A Planck CMB likelihood function for temperature and polarization power spectra. "Planck 2018 CMB (CamSpec likelihood~\cite{CamSpec2021})"
- CMB: Cosmic Microwave Background; relic radiation used as a precise cosmological probe. "for the key combination of the DESI DR2 BAO and the Planck CMB data,"
- Cobaya: A software framework for Bayesian analysis and sampling in cosmology. "via Cobaya~\cite{Torrado2021Cobaya,cobayaascl}"
- compressed data vector: A reduced summary of a dataset with fewer components preserving key information. "a 13-component compressed data vector"
- degrees of freedom: The number of independent parameters in a model that can vary to fit data. "precisely because its additional degrees of freedom are effective at resolving this specific conflict"
- DESI DR2: The second data release of the Dark Energy Spectroscopic Instrument, providing BAO measurements. "The DESI DR2 data release~\cite{desi2025} reports up to 4.2 preference"
- DES-Y5: The Dark Energy Survey Year 5 Type Ia supernova catalogue. "the DES-Y5 supernova catalogue~\citep{descollaboration2025darkenergysurveycosmology}"
- evidence ratio: A metric comparing evidences to assess dataset consistency or tension. "This is the only pairwise combination to yield a negative evidence ratio ()"
- frequentist hypothesis test: A statistical test using data-derived test statistics (e.g., likelihood ratios) to assess models. "based on a frequentist hypothesis test derived from a likelihood ratio based test statistic."
- frequentist significance: The sigma-level translation of a p-value indicating strength of evidence against a null. "3.1 frequentist significance in favoring CDM."
- Gaussian significance: The equivalent number of standard deviations corresponding to a given p-value. "we convert Bayes factors to Gaussian significance via (i)"
- geometric analysis: A methodology assessing BAO data consistency using geometric constructs rather than full likelihoods. "finds independent support from the geometric analysis of Efstathiou~\cite{Efstathiou2025BAO}"
- inverse normal cumulative distribution function: The quantile function mapping probabilities to z-scores in a standard normal. "where is the inverse normal cumulative distribution function."
- likelihood ratio: The ratio of likelihoods under competing models, used as a test statistic. "likelihood ratio based test statistic."
- log-Bayes factor: The natural logarithm of the Bayes factor, commonly reported for model comparison. "log-Bayes factor "
- look-elsewhere threshold: A significance threshold accounting for multiple comparisons across parameter space. "exceeding our look-elsewhere threshold."
- Monte Carlo pseudo-experiments: Simulated datasets used to validate statistical approximations and calibrate significances. "by means of extensive Monte Carlo pseudo-experiments"
- nested sampling: A Monte Carlo algorithm for efficiently computing Bayesian evidence and exploring posteriors. "using nested sampling to compute the Bayesian evidence"
- Pantheon+: A compilation of Type Ia supernovae used for cosmological parameter inference. "Pairwise combinations with Pantheon+ data strengthen the Bayesian evidence for CDM"
- posterior: The probability distribution over parameters given the data and prior. "Posterior comparisons in CDM"
- priors: Probability distributions encoding parameter beliefs before observing the data. "we adopt DESI's priors (, with )"
- suspiciousness: A tension metric quantifying direct likelihood-level conflict between datasets. "A strongly negative suspiciousness () confirms a direct likelihood conflict"
- tension analysis: A systematic evaluation of the consistency between datasets using multiple complementary metrics. "By performing a comprehensive tension analysis, employing five complementary metrics,"
- Union3: A Type Ia supernova compilation used as an alternative to Pantheon+ and DES-Y5. "Union3 (orange)"
- unimpeded evidence framework: A suite of tools and metrics for Bayesian model comparison and tension diagnostics. "using the suite of metrics provided by the unimpeded evidence framework~\cite{UnimpededPaper,UnimpededSoftware}"
- w0waCDM (CDM): A cosmological model with a time-varying dark energy equation of state parameterized by and . "the CDM model is preferred precisely because its additional parameters act to resolve this specific dataset conflict."
- LambdaCDM (CDM): The standard cosmological model with a cosmological constant and cold dark matter. "Negative favours CDM"
Collections
Sign up for free to add this paper to one or more collections.

