One Small Step in Latent, One Giant Leap for Pixels: Fast Latent Upscale Adapter for Your Diffusion Models
Abstract: Diffusion models struggle to scale beyond their training resolutions, as direct high-resolution sampling is slow and costly, while post-hoc image super-resolution (ISR) introduces artifacts and additional latency by operating after decoding. We present the Latent Upscaler Adapter (LUA), a lightweight module that performs super-resolution directly on the generator's latent code before the final VAE decoding step. LUA integrates as a drop-in component, requiring no modifications to the base model or additional diffusion stages, and enables high-resolution synthesis through a single feed-forward pass in latent space. A shared Swin-style backbone with scale-specific pixel-shuffle heads supports 2x and 4x factors and remains compatible with image-space SR baselines, achieving comparable perceptual quality with nearly 3x lower decoding and upscaling time (adding only +0.42 s for 1024 px generation from 512 px, compared to 1.87 s for pixel-space SR using the same SwinIR architecture). Furthermore, LUA shows strong generalization across the latent spaces of different VAEs, making it easy to deploy without retraining from scratch for each new decoder. Extensive experiments demonstrate that LUA closely matches the fidelity of native high-resolution generation while offering a practical and efficient path to scalable, high-fidelity image synthesis in modern diffusion pipelines.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
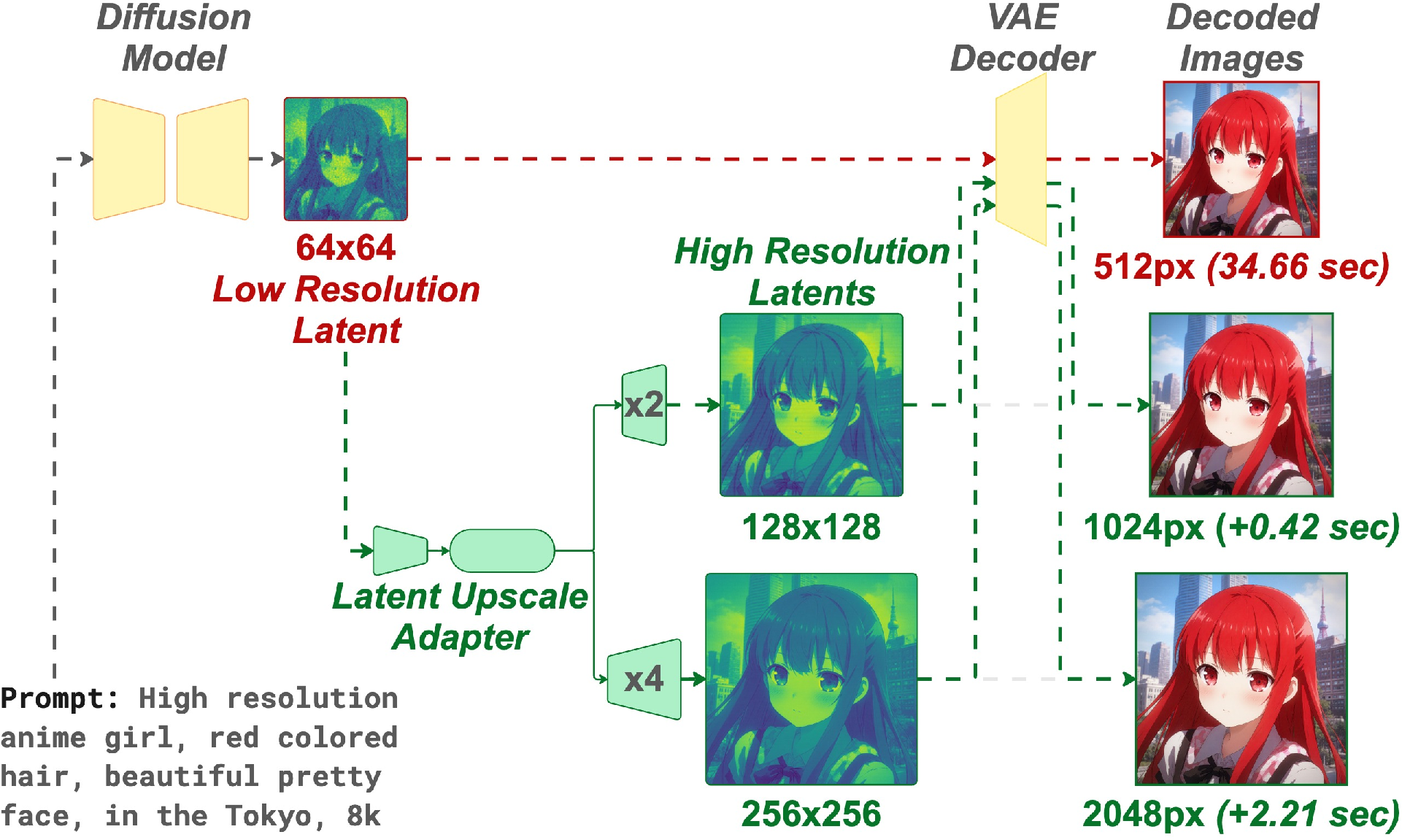
This paper shows a faster, simpler way to make high‑resolution images with AI image generators (diffusion models). Instead of sharpening the final picture after it’s made, the authors “zoom in” on the model’s hidden blueprint (called the latent) before it becomes a picture. Their small add‑on tool is called the Latent Upscaler Adapter (LUA). It plugs into existing models, needs no retraining of the big model, and lets you get 2× or 4× bigger images in one quick step.
What questions were the researchers asking?
They focused on three practical questions:
- Can a small “latent upscaler” make high‑quality large images faster than common methods?
- Can one upscaler handle both 2× and 4× zoom without training a separate model for each?
- Can the same upscaler work across different popular image generators with only tiny tweaks?
How did they do it?
Here’s the idea in everyday terms.
The key idea: Zoom in before the final photo
Most diffusion models work in two steps:
- They design a compressed “secret code” (the latent) of the image.
- A decoder then turns that code into the final picture.
Regular super‑resolution sharpens the final picture (pixel space). That’s slow and can add weird artifacts. Instead, LUA enlarges the hidden code first (latent space), then decodes once to get the big image. Think of it like enlarging a detailed blueprint before printing it, instead of stretching the printed photo afterward.
Why this is faster: the hidden code is much smaller than the final image. If the decoder expands each latent “step” into 8 pixels in the final image, then working in latent space touches about 1/64 as many positions as working on the full picture. Fewer positions = less compute = faster.
What LUA looks like inside
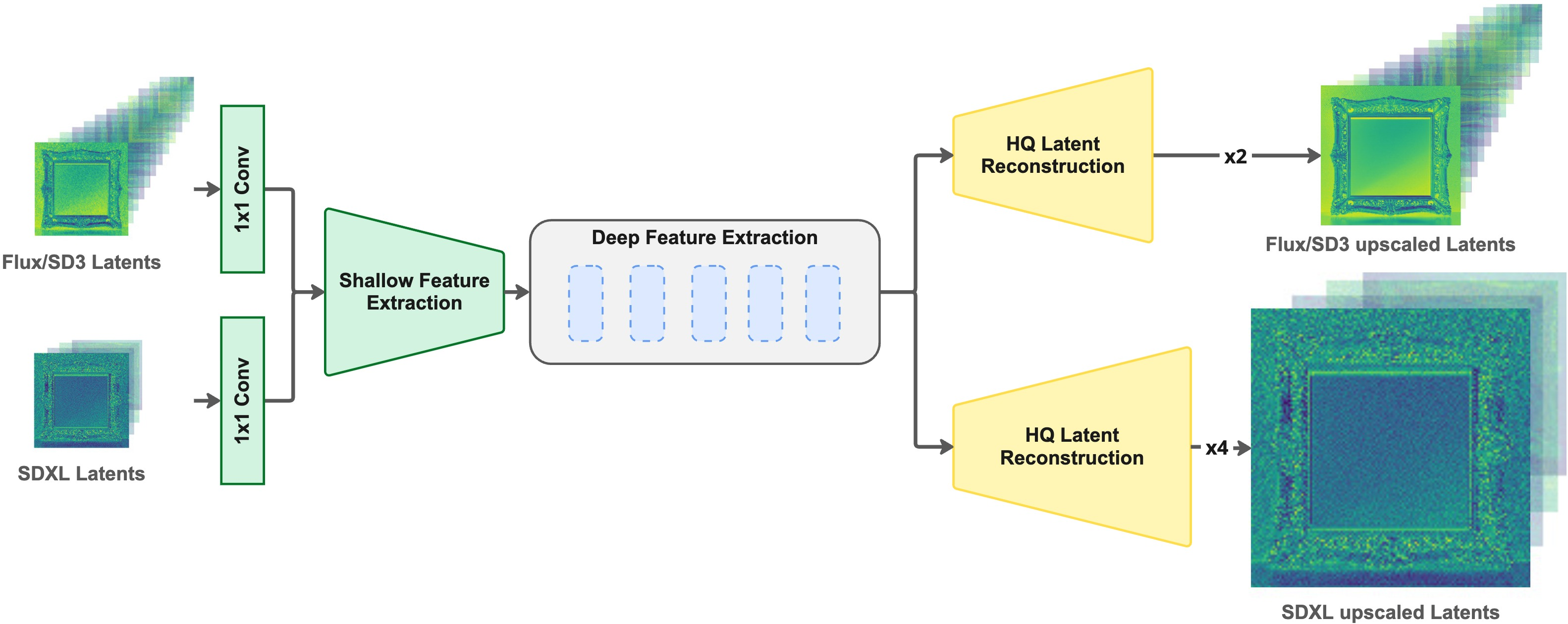
LUA is a small neural network that:
- Reads the low‑resolution latent (the “blueprint”).
- Produces a bigger latent (2× or 4× wider and taller).
- Lets the normal decoder turn it into the final high‑res image.
It uses a “Swin” transformer backbone (a vision model good at image detail) and has two tiny “heads” so it can do 2× or 4× upscaling. You pick which head to use at run time. It’s a drop‑in part: you don’t change the big generator or decoder.
How they trained LUA (simple version)
Training needs to keep both the hidden code and the final picture looking right. They used a three‑step plan:
- Match shapes and textures in the latent itself. This keeps the upscaled blueprint realistic and not blurry.
- Check both latent and image together: make sure the decoded picture looks right at a small scale and preserves fine edges.
- Final touch‑ups in the image domain to sharpen edges and remove small artifacts, still without any extra diffusion steps.
This gentle curriculum keeps the upscaled latent “on the right track” so the decoder makes clean, detailed images.
Will it work with different models?
Yes. They tried it with SDXL, SD3, and FLUX—well‑known diffusion systems that use different latent formats. LUA needed only a small change to its first layer (to match channel count) and a brief fine‑tune. The rest stayed the same.
What did they find?
Below are the key takeaways from many tests on a large image dataset. They measured both quality (using standard scores like FID/KID/CLIP) and speed (wall‑clock time).
- It’s fast.
- Making a 1024‑pixel image from a 512‑pixel base: LUA added about +0.42 seconds, while a popular pixel‑space upscaler (SwinIR) added about +1.87 seconds on the same GPU—around 3× slower.
- At larger sizes (2048 and 4096 pixels), LUA stayed the fastest among compared methods.
- It looks good.
- At 2048 and 4096 pixels, LUA had the best quality among “single‑pass” methods (you decode once) and beat the popular pixel‑space upscaler at both quality and speed.
- It approached the quality of multi‑stage pipelines (which run diffusion a second time for refinement) but was far faster because it avoided that extra diffusion step.
- It’s flexible.
- One shared backbone plus two small heads handled both 2× and 4× upscaling.
- The same LUA design worked across SDXL, SD3, and FLUX with minimal changes.
- Small caveat at 1024 pixels:
- At 1024 pixels, LUA was the fastest, and local details were strong, but overall quality scores were close to or slightly below the best baselines. This is mainly because the starting latent is quite small there, so there’s less fine detail to recover.
Why is this important?
- Faster and cheaper: You get big, sharp images without running a slow extra diffusion stage or doing heavy pixel‑level super‑resolution. That saves time, memory, and money.
- Simpler pipelines: It’s a plug‑in between the generator and decoder. No need to retrain the whole model or add complex steps.
- Broadly usable: Works across multiple popular image models with minimal tuning.
- Better user experience: Fewer artifacts like halos, over‑sharpening, or texture drift; more stable details like eyelashes, fabric textures, or fine edges.
Final thoughts and future impact
LUA is a practical way to scale image generation to high resolutions: upscale the hidden blueprint, decode once, and you’re done. This can help:
- Creative tools and image editors produce high‑res results quickly.
- Photo‑realistic applications (design, ads, media) keep details clean without slowing down.
- Future extensions to video, where speed and consistency across frames matter even more.
One limitation: If the base generation has a mistake, LUA will upscale that mistake too. A next step could add light “fix‑ups” in latent space while upscaling, or extend the method to video with smooth, time‑aware consistency.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several important questions and limitations unresolved that future work could address:
- Manifold adherence: There is no theoretical or empirical guarantee that the upscaled latent stays on the decoder’s valid latent manifold. Quantify manifold deviation (e.g., via encoder–decoder cycle-consistency, decoder Jacobian sensitivity, reconstruction residuals) and identify conditions under which reliably decodes without artifacts.
- Training–inference distribution shift: LUA is trained on latents obtained by encoding real HR/LR images, but deployed on generator-produced latents. Measure and mitigate the gap between encoded latents and generated latents (e.g., train with generated latents, adversarial/domain-adaptive objectives, or mixture distributions).
- Cross-VAE transfer at true “minimal” adaptation: The paper claims minimal fine-tuning but uses 500k pairs for SDXL/SD3. Systematically study sample efficiency (how few pairs suffice), adaptation time, and what statistics must be aligned (channel scaling, normalization, latent whitening), aiming for zero-shot or few-shot transfer.
- Decoder/latent stride variability: LUA is evaluated with stride VAEs. Test robustness across decoders with different strides (e.g., , ), quantized/variational priors, rectified-flow decoders, and different latent widths, and determine what architectural changes are needed beyond the first convolution.
- Arbitrary-scale and aspect-ratio support: LUA currently supports only discrete factors (, ). Investigate continuous/arbitrary scaling and non-uniform aspect ratios (e.g., , panoramic formats), including coordinate-based heads or meta-scaling modules, and quantify fidelity/speed trade-offs.
- Performance ceiling at low base resolutions: At , LUA trails strongest baselines, attributed to small input latents (e.g., ). Explore ways to enrich base latents (e.g., generator-side latent HR heads, multi-scale latent features, lightweight refinement before upscaling) and quantify gains.
- Failure mode taxonomy and detection: Provide a systematic analysis of cases where LUA amplifies base artifacts, introduces ringing/grids, or loses global coherence. Develop automatic artifact detectors and uncertainty-aware gating to decide when to invoke refinement or fall back to pixel-space SR.
- Semantic preservation beyond CLIP: CLIP scores may miss fine semantic drift. Evaluate text–image alignment with stronger metrics (e.g., TIFA, captioning consistency, concept detection/segmentation alignment) and analyze prompt types that degrade under latent upscaling.
- Human perceptual studies: Add user studies/A-B tests to validate perceived sharpness, naturalness, and artifact rates compared to pixel-space SR and multi-stage diffusion at 2K/4K.
- Baseline breadth and fairness: Comparisons use SwinIR for pixel SR; diffusion SR methods like SUPIR, SeeSR, StableSR, DiffBIR are not included. Benchmark against state-of-the-art pixel/diffusion SR under matched runtime/compute budgets.
- Hardware and memory profiling: Runtimes are on high-end GPUs (H100/L40S). Characterize memory footprint, throughput, and latency on consumer GPUs, mobile/edge devices, and under mixed precision/quantization to assess practical deployability.
- Extremely high resolutions (>4K): Evaluate upscaling to 8K/16K with tiling or hierarchical latent upscaling, measuring global coherence, seam handling, and memory constraints.
- Generalization across domains: Training/evaluation use OpenImages photos. Test on diverse domains (artwork, anime, medical, satellite, typography-heavy text) to measure domain robustness and needed adaptations.
- Integration with editing/inpainting pipelines: Assess LUA in image-to-image tasks (inpainting, local edits, depth/semantic-map conditioning), including how latent upscaling interacts with cross-attention and masking.
- Video extension: Design and evaluate temporal-consistent latent upscaling (e.g., recurrent/transformer temporal modules, latent flow priors), measuring flicker, motion coherence, and speed.
- Loss design and stability: Pixel-only training failed to converge with a frozen decoder. Explore alternative stable image-domain supervision (e.g., perceptual losses with surrogate decoders, decoder-aware normalization, score-matching in latent space), and provide principled guidance for loss weighting beyond grid search.
- Noise/texture calibration: Stage III reduces residual noise/grids heuristically. Develop principled strategies to calibrate high-frequency latent energy (e.g., decoder response modeling, spectrum-aware regularization, noise-shaping) and quantify effects on perceived texture vs. artifacts.
- Resource efficiency of multi-scale training: Joint multi-head training reduces storage, but training cost still scales with large datasets (3.8M pairs). Study curriculum/sample-efficient strategies (active sampling, synthetic augmentations, distillation from strong SR) to cut data/compute needs.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that leverage the paper’s Latent Upscaler Adapter (LUA) to deliver high‑resolution outputs with lower latency and cost, along with sector tags, potential tools/workflows, and feasibility notes.
- High‑resolution outputs in diffusion services (software, media/creative)
- Use case: Add 2K/4K image export to existing text‑to‑image platforms without retraining or second diffusion stage.
- Tools/workflows: “LUA Adapter” microservice or SDK; pipeline = generator → LUA (×2/×4) → VAE decode; integration as a node in Automatic1111/ComfyUI/Diffusers.
- Value: Comparable high‑resolution fidelity with reduced wall‑clock time (e.g., 3.52 s vs 6.29 s at 2K), lower GPU cost per image.
- Assumptions: Access to latent tensors and the model’s VAE decoder; minor first‑layer channel adaptation; licensing permits model modification.
- Cost and throughput optimization for content platforms (software, finance)
- Use case: Reduce compute cost per generated image and increase throughput for stock imagery, banners, and thumbnails at 2K/4K.
- Tools/workflows: Batch generation using a single decode at target resolution; A/B performance dashboards to track latency and FID/KID/pFID.
- Value: Lower hardware utilization (operate in latent space ≈ 1/64 spatial positions vs pixel SR at stride 8), faster delivery, reduced cloud spend.
- Assumptions: Stable access to GPUs; cost models account for reduced time/memory; quality monitoring to avoid upscaling artifacts from base samples.
- Print‑quality creative production (media/creative, retail/e‑commerce)
- Use case: Posters, packaging, product photos, signage at 2K/4K from 1K base generations while preserving semantics and reducing halos/ringing.
- Tools/workflows: Plug‑in for Adobe/Blender/Substance pipelines; LUA head selection (×2, ×4) plus a single decode for export.
- Value: Cleaner edges and microstructure than pixel SR; fewer artifacts than direct high‑res sampling; shorter render times.
- Assumptions: Access to rendering pipeline latents; content QA to catch base sample errors that LUA will faithfully upscale.
- Game and VFX asset creation (gaming/VFX)
- Use case: Upscale concept art and textures to 2K/4K for look‑dev and prototyping without multi‑stage diffusion.
- Tools/workflows: LUA integrated post‑generator, pre‑decode; texture libraries updated via latent upscaling.
- Value: Faster iteration cycles; avoids seams and noise typical of image‑space SR; reduced latency versus progressive HR pipelines.
- Assumptions: Texture consistency from the base generation; asset review pipeline accepts single‑decode outputs.
- On‑device generative apps (mobile/edge software)
- Use case: Mobile apps generate high‑resolution posters/cards with lower memory traffic by upscaling in latent space then decoding once.
- Tools/workflows: WebGPU / Metal integration; lightweight LUA heads for ×2/×4; AMP for mixed precision.
- Value: Reduced memory and compute; feasible 2K exports on prosumer devices.
- Assumptions: Device access to model latents and a compact VAE decoder; careful memory management.
- EdTech content authoring (education)
- Use case: High‑resolution diagrams/illustrations for digital textbooks created from 1K bases without training new HR models.
- Tools/workflows: Prompt‑to‑image plus LUA; quality assurance via patch metrics (pFID/pKID).
- Value: Faster course material production; lower artifact risk compared to pixel SR.
- Assumptions: Non‑photorealistic styles may need light fine‑tuning; ensure copyright‑safe model usage.
- Vision research and dataset synthesis (academia)
- Use case: Rapid generation of high‑resolution synthetic datasets for detection/segmentation pretraining and benchmarking latent SR baselines.
- Tools/workflows: OpenImages‑like tiling; latent/pixel‑space metrics; ablation scripts for multi‑head vs per‑scale models.
- Value: Faster data creation; reproducible cross‑VAE transfer (SDXL/SD3/FLUX) by swapping the first conv and brief fine‑tuning.
- Assumptions: Academic licenses; transparent reporting of curriculum and loss weights; evaluation on downstream tasks.
- Sustainability‑oriented deployments (policy, infrastructure ops)
- Use case: Adopt latent SR to cut energy use of generative services; report savings in compute‑hours and emissions.
- Tools/workflows: Energy dashboards; procurement guidelines favoring single‑decode pipelines over re‑diffusion/multi‑stage HR.
- Value: Lower power draw and carbon footprint per image; clearer sustainability KPIs.
- Assumptions: Measurement methodology for energy and emissions; organization buy‑in to change pipelines.
- Product imagery at scale (retail/e‑commerce)
- Use case: Automated catalog imagery pipelines upscale base shots to 2K/4K for listings and ads.
- Tools/workflows: LUA microservice behind an image generation API; nightly batch jobs; artifact filters for base samples.
- Value: Reduced runtime and costs; consistent detail preservation; fewer SR‑induced halos.
- Assumptions: Base samples meet quality bar; governance for synthetic content use.
- Social media and creator tools (daily life)
- Use case: Creators upscale generative images to print or high‑dpi web assets with fewer artifacts than pixel SR.
- Tools/workflows: “Upscale (latent)” button in consumer apps; preset ×2/×4 with one decode.
- Value: Better texture stability; quick export to high‑res formats.
- Assumptions: App exposes latent stage; lightweight on‑device or cloud decoder available.
Long‑Term Applications
These uses require further research, scaling, validation, or ecosystem development before broad deployment.
- Arbitrary‑scale latent upscaling (software, media/creative)
- Use case: Continuous upscale factors (e.g., ×1.5, ×3) beyond discrete ×2/×4 via improved implicit heads or hybrid designs.
- Tools/workflows: Coordinate‑aware latent upsamplers; scale‑conditional training.
- Dependencies: New architecture/training to match high‑frequency latent microstructure at arbitrary scales; robust benchmarks for detail fidelity.
- Joint latent refinement and upscaling with uncertainty gating (software, research)
- Use case: Correct base latent artifacts while upscaling, only invoking refinement when needed.
- Tools/workflows: Adapter with artifact detectors, consistency modules, and gated refinement.
- Dependencies: Reliable artifact detection in latent space; stability without adding full diffusion passes; tuning to avoid semantic drift.
- High‑resolution video generation with temporal consistency (media/creative, streaming)
- Use case: 4K video upscaling from latent sequences without double diffusion, maintaining cross‑frame coherence.
- Tools/workflows: Recurrent/temporal attention in LUA; sequence‑aware losses; streaming decode.
- Dependencies: New temporal training curriculum; performance targets for real‑time or near‑real‑time; memory constraints per frame.
- Domain‑specific HR synthesis (healthcare, remote sensing, scientific imaging)
- Use case: Upscaling specialized generative outputs (e.g., educational medical visuals, satellite maps) with domain‑aware loss functions.
- Tools/workflows: Domain VAEs, edge‑aware/structure‑preserving losses; compliance audits.
- Dependencies: Rigorous validation; regulatory constraints for medical/safety‑critical imagery; preventing misinterpretation of synthetic images.
- Robotics and simulation textures (robotics, XR)
- Use case: Generate high‑resolution textures/material maps for sim environments quickly from concept assets.
- Tools/workflows: LUA in asset pipelines; semantic map‑to‑image tasks upscaled in latent space.
- Dependencies: Structural fidelity in maps (depth/segmentation) preserved through upscaling; domain fine‑tuning.
- Watermark‑aware, provenance‑preserving upscaling (policy, media integrity)
- Use case: Maintain or embed provenance signals (C2PA) during latent upscaling to support content authenticity.
- Tools/workflows: Watermark‑aware loss terms; verification hooks; compliance reporting.
- Dependencies: Access to watermark protocols; standards alignment; adversarial robustness against removal.
- Edge/embedded deployments (IoT, AR/VR)
- Use case: On‑device 2K/4K generation for AR overlays or kiosk signage using latent SR to fit compute budgets.
- Tools/workflows: Quantized LUA heads; compact VAE decoders; hardware‑specific kernels.
- Dependencies: Memory‑safe implementations; model compression; thermal/power constraints.
- “LUA‑as‑a‑Service” and ecosystem standardization (software, cloud, finance)
- Use case: Managed Latent SR APIs with SLAs, usage‑based billing, and compatibility layers across model families.
- Tools/workflows: Versioned adapters per VAE; automatic first‑layer channel adaptation; DevEx SDKs.
- Dependencies: Broad model ecosystem buy‑in; licensing for decoder access; support for closed‑source models that may not expose latents.
- Real‑time interactive editing at high resolution (creative tools)
- Use case: Live brush‑level edits with latent upscaling for immediate 2K/4K previews.
- Tools/workflows: Editor plugins; incremental latent updates; partial decode strategies.
- Dependencies: Efficient partial decoding; latency targets for interactivity; GPU scheduling.
- Sustainability governance and reporting frameworks (policy)
- Use case: Standardize energy metrics and procurement policies favoring single‑decode latent pipelines over multi‑stage HR.
- Tools/workflows: Auditable energy reports; carbon accounting integrations; policy templates.
- Dependencies: Accepted measurement standards; organizational commitment; alignment with regulatory bodies.
Cross‑cutting Assumptions and Dependencies
- Access to the model’s latent and VAE decoder is required; closed platforms may not expose these interfaces.
- Cross‑VAE generalization currently needs a first‑layer channel change and brief fine‑tuning; drastically different latent distributions may require more adaptation.
- Quality depends on the base generation; LUA preserves and amplifies existing semantics and artifacts.
- Training and deployment rely on GPU availability; further optimization (quantization, kernel fusion) may be needed for edge devices.
- Legal/licensing constraints must be respected for model modification and commercial redistribution.
- For domain‑critical areas (e.g., healthcare), rigorous validation and clear user communication are essential to avoid misuse or misinterpretation of synthetic imagery.
Glossary
- Adam: A stochastic optimization algorithm commonly used for training deep neural networks. "We train the three stages (Sec.~\ref{Multi-stage-train}) with Adam (lr , weight decay $0$)"
- Aliasing: Distortion that occurs when high-frequency detail is sampled at too low a resolution. "bicubic blurs/aliases"
- AMP: Automatic Mixed Precision; accelerates training/inference by using lower-precision floats where safe. "with AMP and batch size~1."
- Arbitrary-scale super-resolution: SR that supports continuous zoom factors rather than fixed multiples like ×2 or ×4. "Arbitrary-scale methods (LIIF, LTE, CiaoSR) predict continuous coordinates from learned features"
- Bicubic downsampling: Reducing image resolution using bicubic interpolation. "HR/LR pairs are made by bicubic downsampling at the target scale (, )."
- Bicubic resizing: Changing spatial resolution via bicubic interpolation, often causing smoothing. "Bicubic resizing or naïve latent interpolation departs from the manifold of valid latents"
- CLIP: A text–image alignment metric based on Contrastive Language–Image Pretraining. "We evaluate LUA across backbones and resolutions using FID/KID/CLIP"
- Conditioning: Auxiliary input (e.g., text) that guides generation. "Given text condition and noise , a pretrained generator produces a latent "
- Consistency methods: Techniques that reduce diffusion steps by enforcing consistency across model outputs. "step-reduction by distillation/consistency methods"
- Cross-VAE generalization: The ability of a model to operate across different VAEs with minimal changes. "We demonstrate cross-VAE generalization: the same backbone operates across SD3~\cite{esser2024scaling}, SDXL~\cite{podell2023sdxlimprovinglatentdiffusion}, and FLUX~\cite{batifol2025flux} by changing only the first layer"
- Decoder stride: The spatial upsampling factor of a decoder, mapping latent to image resolution. "VAE decoders typically expand spatial dimensions by stride "
- Diffusion stage: A full denoising process in diffusion pipelines. "without an extra diffusion stage"
- Downsampling operator: A function that reduces image size, often denoted with a down-arrow symbol. "Here denotes bicubic downsampling"
- Edge-aware gradient localization loss (EAGLE): A loss that sharpens edges and reduces staircase artifacts. "where $\mathcal{L}_{\mathrm{EAGLE}^{x}$ is an edge-aware gradient localization loss that enforces crisp boundaries and reduces staircase artifacts"
- EMA: Exponential Moving Average of model parameters to stabilize training. "EMA $0.999$"
- Feed-forward operator: A deterministic mapping applied once without iterative refinement. "All generative stochasticity resides in ; is a feed-forward operator"
- FFT magnitude: The absolute value of the Fourier transform used to align frequency spectra. "channel-wise 2D FFT magnitude"
- FID: Fréchet Inception Distance; a metric for image distribution similarity. "We evaluate LUA across backbones and resolutions using FID/KID/CLIP"
- Fine-tuning: Additional training on a pretrained model to adapt to a new task or domain. "high-resolution fine-tuning can reduce such artifacts"
- Gaussian blur: A smoothing filter characterized by a Gaussian kernel. " is a Gaussian blur with "
- Grad-clip: Gradient clipping to prevent exploding gradients. "grad-clip $0.4$"
- Guidance: In diffusion, parameters/methods that steer generation toward desired outputs. "Samplers, steps, guidance, and prompts are held constant where applicable"
- KID: Kernel Inception Distance; an alternative to FID for measuring image quality. "We evaluate LUA across backbones and resolutions using FID/KID/CLIP"
- Latent Diffusion Model (LDM): A diffusion model that operates in a compressed latent representation rather than pixel space. "Latent Diffusion Models (LDMs), which shift computation into compact latent representations"
- Latent manifold: The set of valid latent codes that decode to realistic images. "departs from the manifold of valid latents, producing unnatural textures after decoding"
- Latent microstructure: Fine-scale patterns in latent codes that decode into detailed textures. "Preserving latent microstructure via a single upscaling stage"
- Latent space super-resolution: Upscaling performed on latent representations prior to decoding. "Latent-space upsampling instead enlarges the latent representation prior to decoding"
- Latent Upscaler Adapter (LUA): A lightweight module that upsamples latents before VAE decoding. "We present the Latent Upscaler Adapter (LUA), a lightweight module that performs super-resolution directly on the generatorâs latent code before the final VAE decoding step."
- Laplacian-variance map: A measure of local high-frequency energy used to assess image sharpness/noise. "Laplacian-variance maps (darker\,{=}\,less noise)"
- Multi-stage inference: Pipelines that require multiple sequential generation or refinement phases. "These pipelines require multi-stage inference"
- MultiStepLR: A learning-rate scheduler that decays at predefined step milestones. "MultiStepLR (milestones $62.5$k/$93.75$k/$112.5$k, )"
- Patch metrics (pFID/pKID): Evaluation on cropped patches to better capture fine detail. "we also report patch metrics (pFID/pKID) on random crops"
- Pixel-shuffle: An operation that rearranges channels into higher spatial resolution for upscaling. "scale-specific pixel-shuffle heads support and factors"
- Pixel-space super-resolution (SR): Upscaling applied to decoded images rather than latents. "Pixel-space super-resolution (SR) applies an external SR model to the decoded image."
- Reference-based re-diffusion: Generating a low-res reference, upsampling it, then running a second guided diffusion. "reference-based methods, such as DemoFusion-style pipelines~\cite{du2024demofusion} and LSRNA~\cite{jeong2025latent}, first generate a low-resolution reference, upsample it, and then run a second diffusion stage"
- Receptive field: The spatial extent over which a unit in a network aggregates information. "receptive-field expansions via adaptive/dilated or sparse convolutions"
- Residual connections: Skip connections that help training deeper networks and preserve information. "encoderâdecoder with residual connections"
- Semantic drift: Unintended changes in content semantics during transformation or upscaling. "encourages oversmoothing, semantic drift, and a computational cost that grows quadratically with output size"
- Single-decode synthesis: Producing the final high-resolution image with one decoder pass. "yields single-decode synthesis without an extra diffusion stage"
- Swin Transformer: A hierarchical transformer with shifted windows for vision tasks. "We adopt a Swin Transformer restoration backbone in the spirit of SwinIR"
- SwinIR: A Swin Transformer-based model for image restoration and super-resolution. "LUA employs a shared SwinIR-style backbone with lightweight, scale-specific pixel-shuffle heads"
- Tiling/blending: Splitting and merging images during generation to handle high resolutions. "tiling/blending in MultiDiffusion~\cite{bar2023multidiffusion} preserves locality but risks seams"
- VAE (Variational Autoencoder): A generative model with an encoder–decoder that maps between images and latents. "A frozen VAE decoder with spatial stride (typically ) maps to an RGB image"
- Windowed self-attention: Self-attention restricted to local windows to balance context and efficiency. "Windowed self-attention provides long-range context while preserving locality"
Collections
Sign up for free to add this paper to one or more collections.

