- The paper introduces an attribute-conditional framework to evaluate diversity in T2I models by aligning human judgments with controlled attribute variations.
- It details a systematic methodology employing LLM-generated prompt sets and structured human annotation to reduce ambiguity in diversity assessment.
- Results reveal significant performance differences among T2I models, highlighting the potential of LLM-based autoraters as promising scalable evaluators.
Benchmarking Attribute-Conditional Diversity in Text-to-Image Generative Models
Introduction
Quantifying and comparing diversity in outputs from text-to-image (T2I) generative models remains technically challenging and methodologically ambiguous. Existing diversity metrics often conflate diversity with unrelated generation properties and are deployed without clear definitions for the attributes or concepts of interest, undermining their interpretability. This paper provides a rigorous and explicitly attribute-conditional framework for evaluating diversity in T2I models, demonstrating that meaningful assessment requires specification of both the semantic concept and the axis of variation. The authors introduce a systematic methodology and benchmark grounded in human judgments, which is employed to dissect model comparisons and the correspondence of automated metrics to human intuition.
A central premise is that diversity in T2I generation must be referenced to a concrete axis of variation associated with a semantic concept. Formally, for a given set of images X={x1,...,xn} corresponding to concept cj and attribute aj,k with finite set of attribute values Vj,k, diversity is defined as the coverage of the possible values v∈Vj,k within the generated image set. A "perfectly diverse" set includes one image for each possible attribute value, which is generally intractable due to the exponential growth of combinations across multiple attributes and the presence of continuous-valued factors.
Instead, the framework targets a tractable notion: diversity per salient attribute, using carefully selected concept–attribute pairs. To systematically curate relevant attributes, the pipeline leverages LLMs (Gemini 1.5 M), which enumerate plausible variation aspects for a suite of common visual concepts, yielding a list of 86 concept–attribute pairs such as (apple, color), (tree, species), and (coffee cup, material).
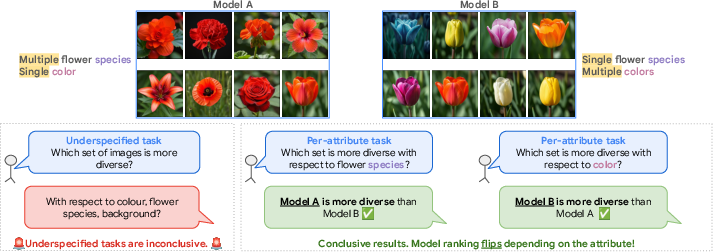
Figure 1: Evaluating diversity requires specifying both the concept being assessed and the factor of variation to reduce ambiguity in the annotation process.
This explicit conditioning removes annotator ambiguity and prevents the conflation of diversity with other factors, such as concept mixing or low-level image variability.
Human Evaluation Protocol: Prompt Set and Annotation Template
The evaluation proceeds in three phases:
- Prompt Set Construction: Using LLMs, a prompt set is sampled that covers a balanced range of natural concepts across food, nature, and human-made objects. Each concept is paired with an empirically salient attribute of variation.
- Image Generation: For each concept–attribute pair, multiple T2I models are queried to generate samples. Images are arranged into sets to be compared side-by-side.
- Annotation Template: Human annotators perform comparative judgments on paired sets for the specified concept and attribute, structured into a two-stage process: first, counting the number of unique attribute values in each set ("count"), then deciding which set is more diverse ("comparison"). This template is empirically validated with a handcrafted "golden set" containing known property distributions.
The importance of explicit attribute specification is quantitatively demonstrated: when the attribute is not stated, annotator agreement and accuracy collapse to near chance (∼30%), but providing the attribute of interest sharply increases accuracy (to 82.5% for sets of size 4; 53.3% for sets of size 8). Inclusion of the counting task further boosts reliability (up to 77.9% for larger sets).

Figure 2: Krippendorff's alpha-reliability evidences high agreement between annotators for the attribute-guided protocol.



Figure 3: Screenshot of the annotation interface for the "No aspect" (no attribute specified) condition.
Analysis of the count distributions confirms that the protocol guides annotators to focus sharply on the intended axis of variation, and deviations correspond to substantive perceptual ambiguities (e.g., visually similar chair types despite underlying prompt variation).
Comprehensive Model Comparison: Human-Annotated Benchmark
With the full prompt set and validated annotation protocol, the authors evaluate five prominent T2I models: Imagen 3, Flux 1.1, DALLE3, Muse 2.2, and Imagen 2.5. For each prompt pair, 20 samples per model are generated, arranged into sets, and all (25) model pairs are compared for a total of 24,591 annotations.
Statistical aggregation (mode across raters, then across set comparisons) and two-sided Binomial testing determine the significance and directionality of performance. Inter-annotator reliability is uniformly strong (α > 0.8). Key results:
- Imagen 3 and Flux 1.1 are significantly better (p<0.05) or not worse than all other models on attribute diversity.
- Imagen 2.5 and Muse 2.2 are never significantly better than other models.
- DALLE3 is significantly better than Imagen 2.5 in this benchmark.
These results reflect substantive progress in attribute-conditioned diversity among recent models and validate the discriminative power of the benchmark.
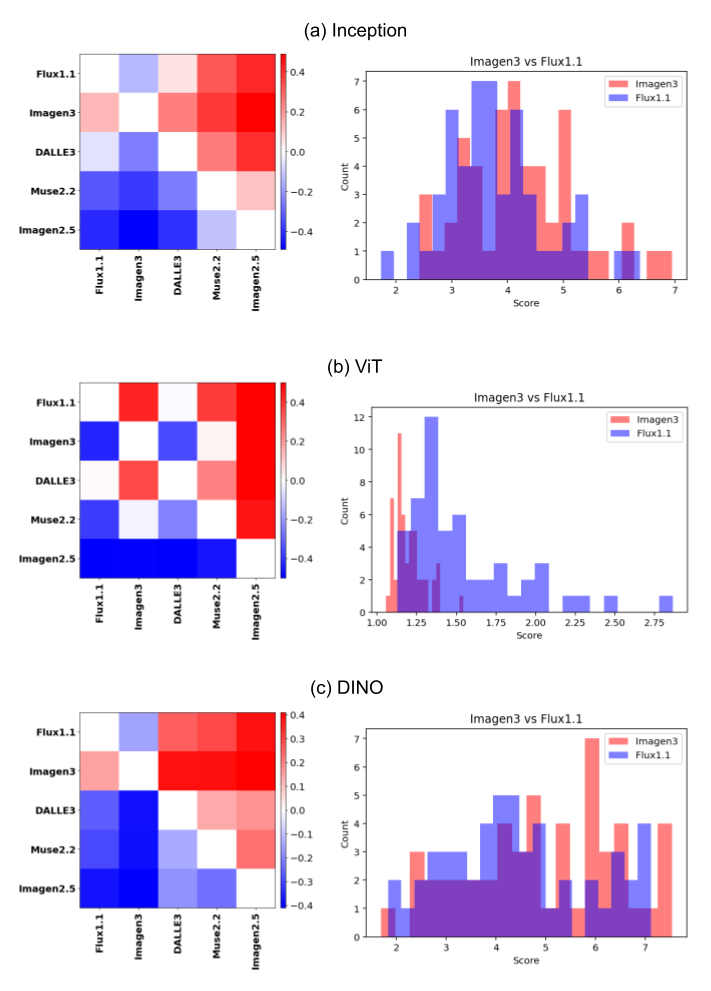
Figure 4: Model ranking using automated evaluation: win rate matrices and score distributions for Flux1.1 and Imagen3 using image embeddings.
Automated Metrics: Vendi Score and Embedding Dependency
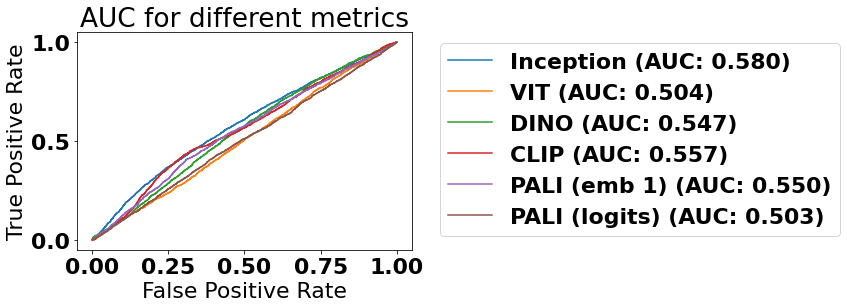
Given the impracticality of scaling human annotation, the paper evaluates the alignment of automated metrics, particularly the Vendi Score (reference-free, based on entropy of the similarity kernel over feature embeddings [Friedman & Dieng, 2022]), to the human benchmark. The approach tests multiple embedding spaces, including:
- Vision-only models (ImageNet Inception, ViT, DINOv2)
- Multimodal models (PALI, CLIP) with and without text conditioning
Results show:
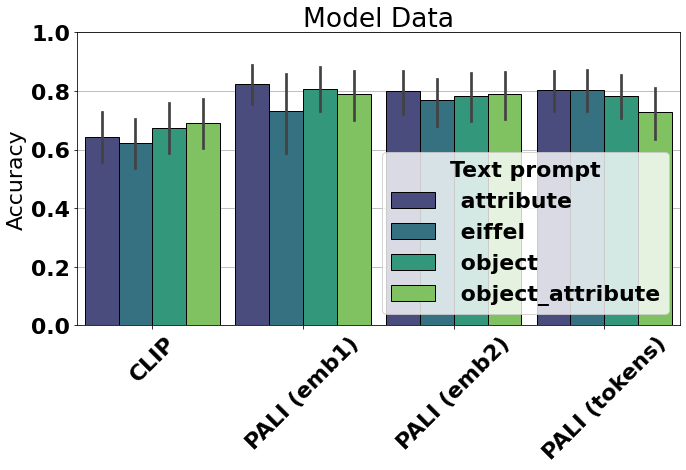
Figure 6: On the ``diverse'' golden set, the best automated metrics approach—but do not match—human discrimination.
Advances in Automated Evaluation: LLM-Based Autoraters
The benchmark is further extended by deploying the Gemini vision-LLM in a structured autorater role, with tailored instructions mirroring the human annotation protocol. Gemini v2.5 Flash achieves higher accuracy than human raters on the golden set; this strongly suggests that LLM-based autoraters conditioned on explicit tasks can serve as scalable, robust proxies for diversity judgments, surpassing current classical embedding-based methods.
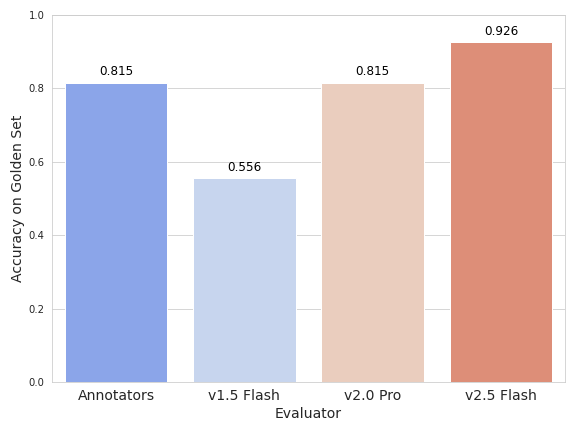
Figure 7: Gemini v2.5 Flash accuracy surpasses human annotators on the controlled diversity comparison task.
Critical Observations and Trade-offs
No evidence is found for a diversity–fidelity trade-off among strong models—all considered T2I models are equivalent on state-of-the-art text-to-image alignment metrics (Gecko), yet they are sharply distinguished on diversity. Thus, higher diversity is not simply attained at the cost of prompt alignment or fidelity in this context.
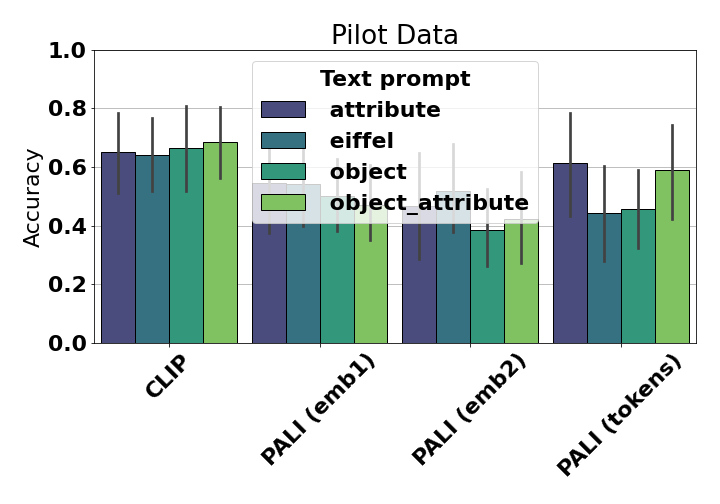
Evaluation of combined object–attribute or attribute-only prompts in multimodal embeddings reveals that more "specific" conditioning does not reliably yield higher metric-human alignment. This suggests that effective diversity assessment tools must tightly control both prompt content and embedding model selection.
Limitations include the reliance on hand-engineered prompt sets, potential cultural bias in attribute salience or annotation, and the continued challenge in distinguishing visually subtle or semantically nuanced diversity.
Implications and Future Directions
Practically, this framework enables precise benchmarking and targeted diagnosis of T2I model shortcomings in generating attribute-level diversity. The curated prompt set, publicly released with diverse annotations, constitutes a critical resource for both evaluating future diffusion/generative architectures and for further research into discrimination-aware and demographically balanced diversity metrics.
Theoretically, the methodology underscores the necessity to specify evaluation axes and concretizes the gap between vision-based unsupervised metrics and human perception for diversity. The promise of LLM-based autoraters indicates a pathway towards robust, domain-adaptable "human-aligned" evaluation frameworks, yet open research remains in embedding model selection and prompt engineering for optimal alignment.
Further work will refine the creation of more challenging, demographically targeted prompt sets, enable on-the-fly LLM generation of attribute axes for rare concepts, and drive the formalization of axiomatic properties for diversity metrics in direct correspondence with human perception.
Conclusion
This paper introduces a principled, attribute-conditional benchmarking protocol for diversity in T2I models, offering a validated human-centric ground-truth and demonstrating its necessity for meaningful model comparison. Human annotation accuracy is drastically improved by explicit attribute conditioning, and the authors provide strong empirical evidence that prominent models diverge sharply in attribute-specific diversity despite similar fidelity. Automated metrics approach, but do not yet match, human discrimination—though LLM-based autoraters represent a promising advance. This benchmark defines a new standard for future T2I diversity assessment and metric development.